RECALL: Recovery Experience Collection for Active Lifelong Learning in Vision-Language-Action Models
Pith reviewed 2026-06-26 08:12 UTC · model grok-4.3
The pith
Active uncertainty-guided data collection improves fine-tuning efficiency for vision-language-action models but requires methods to avoid forgetting earlier skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an active, uncertainty-guided paradigm for collecting recovery experiences in vision-language-action models enables more efficient adaptation than passive imitation learning, but requires continual learning methods such as replay-based data mixing or elastic weight consolidation to mitigate catastrophic forgetting of prior behaviors.
What carries the argument
Uncertainty-guided selection of states for recovery demonstrations, combined with replay-based data mixing or elastic weight consolidation to balance new learning against retention in autoregressive VLA policies.
If this is right
- Uncertainty-guided collection requires fewer demonstrations to achieve equivalent fine-tuning gains than passive collection after failures.
- Training exclusively on the new recovery data produces measurable drops in performance on tasks learned earlier.
- Replay-based mixing of old demonstrations with new recovery data preserves prior behaviors while allowing adaptation.
- Elastic weight consolidation offers an alternative way to retain old skills at the cost of slower incorporation of uncertainty-guided data.
- Tradeoffs exist between the rate of adaptation to new recovery data and the degree of retention of previously learned behaviors.
Where Pith is reading between the lines
- The same uncertainty signal could be used to decide when a deployed robot should request human intervention rather than continuing to act.
- The approach might generalize to other large policy classes where data collection cost is the main bottleneck.
- Better calibration of uncertainty could reduce the risk that recovery data over-represents rare failure modes.
- Longer-horizon tasks might require uncertainty estimates that account for future states rather than only the immediate one.
Load-bearing premise
Uncertainty estimates from the vision-language-action policy accurately identify states where new demonstrations will improve performance without introducing bias into the collected recovery data.
What would settle it
If experiments that replace uncertainty-guided state selection with random or failure-triggered collection show no reduction in the number of demonstrations needed to reach the same performance level, the efficiency advantage claim would be falsified.
Figures
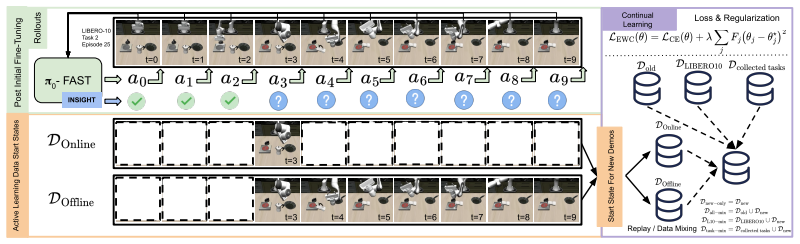
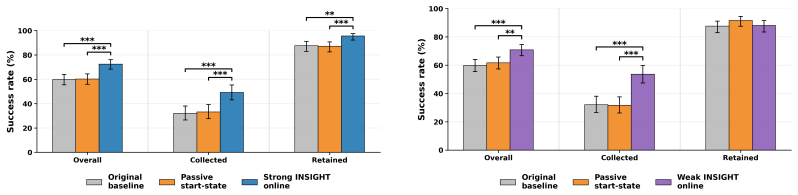

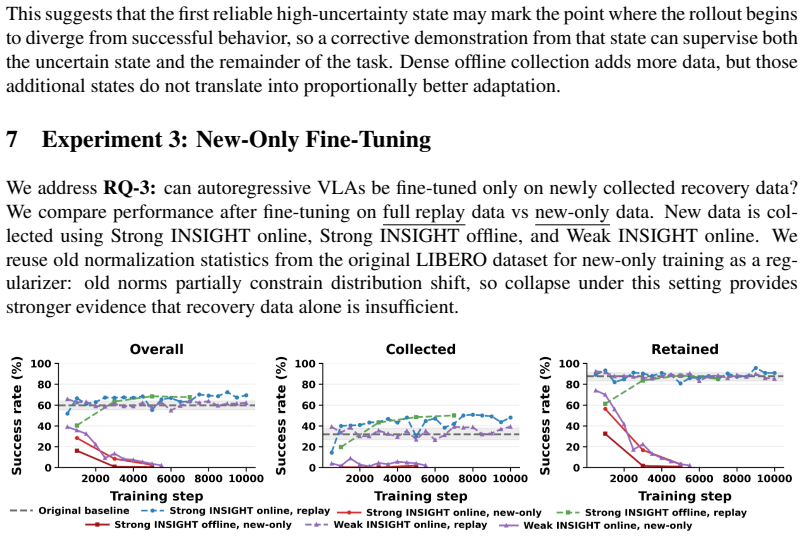
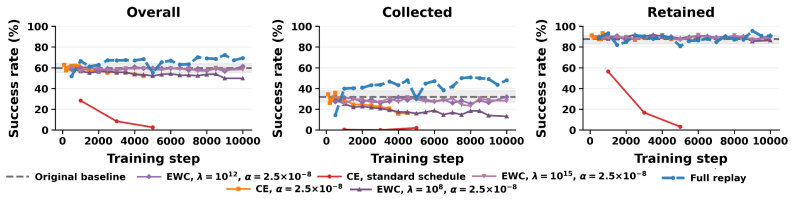

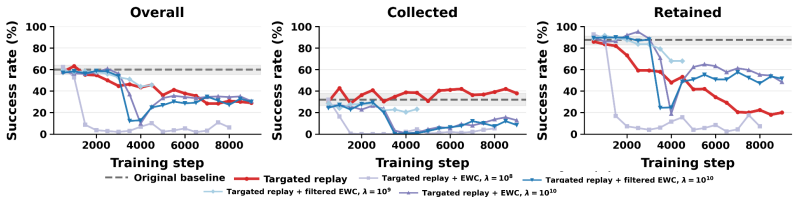
read the original abstract
Vision-Language-Action (VLA) models are commonly fine-tuned through passive imitation learning, where additional demonstrations are collected for tasks where the policy performs poorly. This approach incurs several downsides: it requires the robot to fail before data collection is triggered, provides little guidance about which states require supervision, and wastes demonstrator effort on redundant parts of the task where the policy already performs well. In this paper, we propose an active, continual learning paradigm for VLAs. We demonstrate that active, uncertainty-guided data collection leads to more efficient fine-tuning than when using passively-collected demonstrations. However, we also find that fine-tuning only on actively-collected recovery data leads to catastrophic forgetting. We evaluate techniques for continual learning, including replay-based data mixing and elastic weight consolidation, and identify tradeoffs between plasticity to uncertainty-guided recovery data and retention of previously learned behaviors. Overall, our work contributes an empirical study of active continual learning for autoregressive VLAs, establishing that uncertainty-guided recovery demonstrations can improve adaptation efficiency while also revealing open challenges when targeted new data is incorporated into large robot policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RECALL, an active continual learning approach for Vision-Language-Action (VLA) models. It argues that passive imitation learning requires failures before data collection and wastes effort on well-learned states; instead, uncertainty-guided active collection of recovery demonstrations improves fine-tuning efficiency. The work also reports that fine-tuning solely on such recovery data induces catastrophic forgetting and evaluates mitigation via replay-based mixing and elastic weight consolidation, identifying plasticity-retention tradeoffs in an empirical study of autoregressive VLAs.
Significance. If the empirical claims hold with proper quantification and validation, the work would be a useful empirical contribution to lifelong robot learning by showing how targeted active recovery data can reduce demonstrator effort compared with passive collection and by surfacing concrete tradeoffs when incorporating such data into large VLAs. The paper does not claim new theoretical results, parameter-free derivations, or machine-checked proofs.
major comments (3)
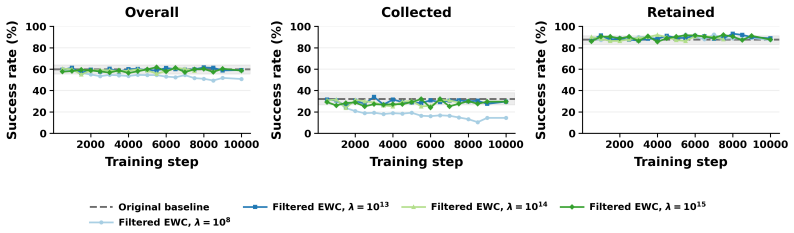
- [Abstract] Abstract: the headline claim that 'active, uncertainty-guided data collection leads to more efficient fine-tuning' is presented without any quantitative metrics, baselines, error bars, dataset sizes, or statistical controls. This is load-bearing for the central empirical result; the abstract states an outcome but supplies no numbers that would allow verification of the efficiency advantage.
- [Method] Method (uncertainty estimator): the paper does not define or ablate the uncertainty signal used to select recovery states (token entropy, predictive variance, ensemble disagreement, etc.) nor demonstrate that states flagged by this signal causally produce net performance gains rather than distribution shift or bias. This link is required for the weakest assumption identified in the stress-test note and remains unaddressed in the provided text.
- [Experiments] Experiments: no tables or figures are referenced that report success rates, sample efficiency curves, or forgetting metrics with controls for the passive vs. active comparison; without these, the reported tradeoffs between plasticity and retention cannot be assessed.
minor comments (1)
- [Abstract] The abstract uses the term 'catastrophic forgetting' without a precise operational definition or reference to the metric employed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'active, uncertainty-guided data collection leads to more efficient fine-tuning' is presented without any quantitative metrics, baselines, error bars, dataset sizes, or statistical controls. This is load-bearing for the central empirical result; the abstract states an outcome but supplies no numbers that would allow verification of the efficiency advantage.
Authors: We agree that the abstract would be strengthened by including quantitative support for the efficiency claim. The experimental results in the paper quantify the gains from active collection relative to passive baselines. We will revise the abstract to incorporate these key metrics, baselines, error bars, and dataset details to enable verification. revision: yes
-
Referee: [Method] Method (uncertainty estimator): the paper does not define or ablate the uncertainty signal used to select recovery states (token entropy, predictive variance, ensemble disagreement, etc.) nor demonstrate that states flagged by this signal causally produce net performance gains rather than distribution shift or bias. This link is required for the weakest assumption identified in the stress-test note and remains unaddressed in the provided text.
Authors: The current manuscript describes uncertainty-guided selection at a high level but does not provide an explicit definition of the signal or an ablation. We will expand the method section to define the uncertainty estimator in detail and add an ablation comparing it against random selection to demonstrate net gains while controlling for distribution shift. revision: yes
-
Referee: [Experiments] Experiments: no tables or figures are referenced that report success rates, sample efficiency curves, or forgetting metrics with controls for the passive vs. active comparison; without these, the reported tradeoffs between plasticity and retention cannot be assessed.
Authors: The paper contains figures and tables presenting success rates, sample efficiency curves, and forgetting metrics for the passive versus active comparisons. We will add explicit in-text references to these results when discussing the plasticity-retention tradeoffs to improve clarity and verifiability. revision: partial
Circularity Check
No circularity: empirical study with independent experimental comparisons
full rationale
The paper is an empirical study of active vs. passive data collection for VLA fine-tuning. It reports experimental outcomes on efficiency and forgetting without any equations, parameter fits presented as predictions, self-definitional constructs, or load-bearing self-citations. The central claim rests on direct comparisons of collection strategies and continual-learning techniques, which are externally falsifiable via the described robot evaluations and do not reduce to the inputs by construction. No derivation chain exists that could exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Man- junath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
Pith/arXiv arXiv 2023
-
[2]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[3]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, S. Bohez, K. Bousmalis, A. Brohan, T. Buschmann, A. Byravan, S. Cabi, K. Caluwaerts, F. Casarini, O. Chang, J. E. Chen, X. Chen, H.-T. L. Chi- ang, K. Choromanski, D. D’Ambrosio, S. Dasari, T. Davchev, C. Devin, N. D. Palo, ...
Pith/arXiv arXiv 2025
-
[4]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models, 2025. URL https://arxiv.org/abs/2501.09747
Pith/arXiv arXiv 2025
-
[5]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[6]
U. B. Karli, Z. Shangguan, and T. FItzgerald. Insight: Inference-time sequence introspection for generating help triggers in vision-language-action models, 2025. URLhttps://arxiv. org/abs/2510.01389
Pith/arXiv arXiv 2025
-
[7]
Ross and D
S. Ross and D. Bagnell. Efficient reductions for imitation learning. In Y . W. Teh and M. Titterington, editors,Proceedings of the Thirteenth International Conference on Artifi- cial Intelligence and Statistics, volume 9 ofProceedings of Machine Learning Research, pages 661–668, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010. PMLR. URLhttps: //procee...
2010
-
[8]
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), page 8077–8083. IEEE Press, 2019. doi:10.1109/ICRA.2019.8793698. URLhttps://doi.org/10.1109/ICRA.2019.8793698
-
[9]
Y . Cui, D. Isele, S. Niekum, and K. Fujimura. Uncertainty-aware data aggregation for deep imitation learning, 2019. URLhttps://arxiv.org/abs/1905.02780
Pith/arXiv arXiv 2019
-
[10]
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer. Ensembledagger: A bayesian ap- proach to safe imitation learning, 2019. URLhttps://arxiv.org/abs/1807.08364
Pith/arXiv arXiv 2019
-
[11]
M. Zhao, R. Simmons, H. Admoni, A. Ramdas, and A. Bajcsy. Conformalized interactive imitation learning: Handling expert shift and intermittent feedback, 2025. URLhttps:// arxiv.org/abs/2410.08852
arXiv 2025
-
[12]
C. Wang and Y . Wang. Uncertainty-driven data aggregation for imitation learning in au- tonomous vehicles.Information, 15(6), 2024. ISSN 2078-2489. doi:10.3390/info15060336. URLhttps://www.mdpi.com/2078-2489/15/6/336
-
[13]
S.-W. Lee, X. Kang, and Y .-L. Kuo. Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation, 2025. URLhttps://arxiv.org/abs/2410.14868
arXiv 2025
-
[14]
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles, 2017. URLhttps://arxiv.org/abs/1612.01474
Pith/arXiv arXiv 2017
-
[15]
Gal and Z
Y . Gal and Z. Ghahramani. Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning. In M. F. Balcan and K. Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1050–1059, New York, New York, USA, 20–22 Jun 2016. PMLR. URLhttps...
2016
-
[16]
A. N. Angelopoulos and S. Bates. A gentle introduction to conformal prediction and distribution-free uncertainty quantification, 2022. URLhttps://arxiv.org/abs/2107. 07511
2022
-
[17]
A. Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. Takayama, F. Xia, J. Varley, Z. Xu, D. Sadigh, A. Zeng, and A. Majumdar. Robots that ask for help: Uncertainty alignment for large language model planners. InProceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[18]
M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. volume 24 ofPsychology of Learning and Motivation, pages 109–165. Academic Press, 1989. doi:https://doi.org/10.1016/S0079-7421(08)60536-8. URL https://www.sciencedirect.com/science/article/pii/S0079742108605368
-
[19]
Y . Luo, Z. Yang, F. Meng, Y . Li, J. Zhou, and Y . Zhang. An empirical study of catas- trophic forgetting in large language models during continual fine-tuning, 2025. URLhttps: //arxiv.org/abs/2308.08747. 10
Pith/arXiv arXiv 2025
-
[20]
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert. icarl: Incremental classifier and representation learning, 2017. URLhttps://arxiv.org/abs/1611.07725
Pith/arXiv arXiv 2017
-
[21]
Lopez-Paz and M
D. Lopez-Paz and M. A. Ranzato. Gradient episodic memory for continual learning. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar- nett, editors,Advances in Neural Information Processing Systems, volume 30. Curran As- sociates, Inc., 2017. URLhttps://proceedings.neurips.cc/paper_files/paper/ 2017/file/f87522788a2b...
2017
-
[22]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Mi- lan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, Mar. 2017. ISSN 1091-6490. doi: 10.1073/pnas.1...
-
[23]
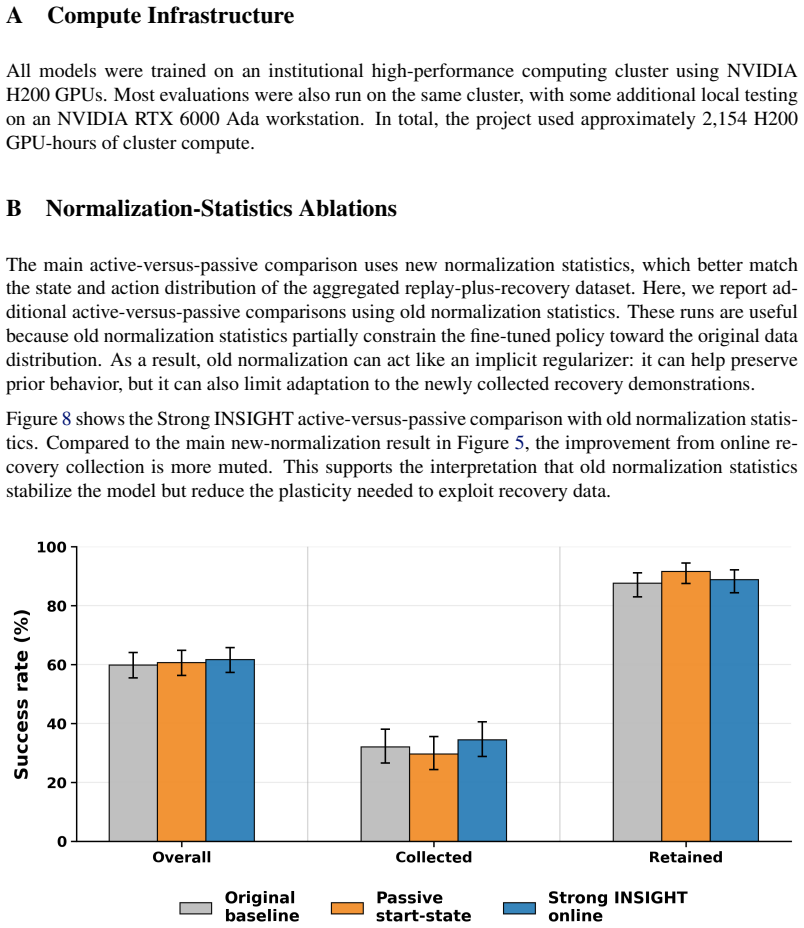
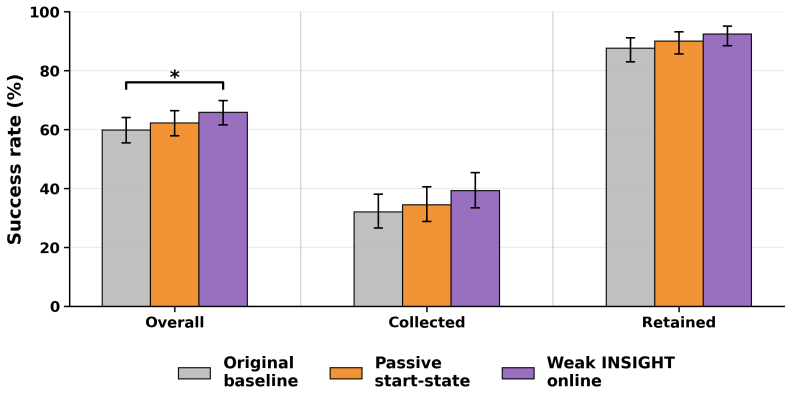
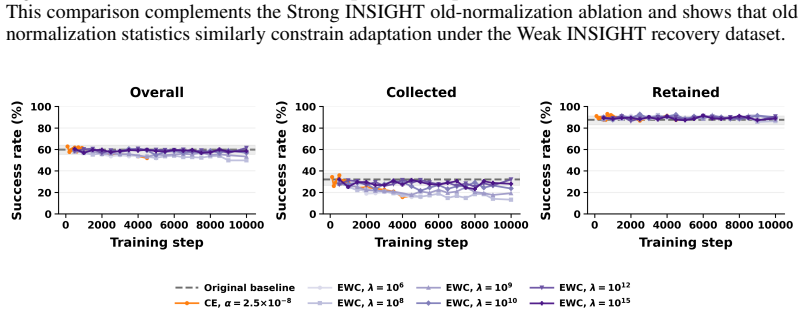
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URLhttps://arxiv.org/abs/2306. 03310. 11 A Compute Infrastructure All models were trained on an institutional high-performance computing cluster using NVIDIA H200 GPUs. Most evaluations were also run on the same clus...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.