Semantic Browsing: Controllable Diversity for Image Generation
Pith reviewed 2026-06-26 09:01 UTC · model grok-4.3
The pith
A method induces controllable diversity in text-to-image outputs by generating structured semantic variations directly in text prompts via a vision-language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exploiting the separation between semantic planning and pixel synthesis in models trained on elaborated captions, an agentic VLM workflow can generate prompt variants that enforce structured, meaningful diversity; every resulting image then corresponds to one understandable semantic choice.
What carries the argument
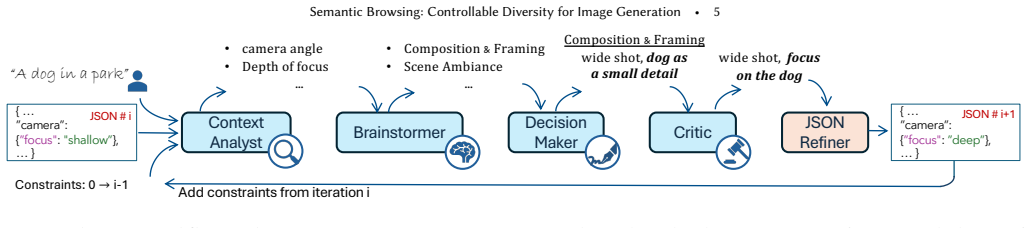
An agentic workflow that uses a Vision Language Model on full scene context to enforce structured textual variations attuned to the original prompt.
If this is right
- Image galleries become systematically navigable along explicit semantic dimensions.
- Creative exploration proceeds through user-understandable design choices instead of random sampling.
- Diversity control moves upstream to the text representation and no longer depends on the image model's internal stochasticity.
Where Pith is reading between the lines
- The same text-level control could be tested on video or 3D generators that also rely on rich captions.
- Interactive interfaces could expose the semantic axes directly to designers for iterative selection.
- The approach might reduce dependence on multiple random seeds in production pipelines.
Load-bearing premise
Text-to-image models trained on elaborated captions have already decoupled semantic decision-making from pixel generation.
What would settle it
A user study or automated check in which the generated image sets show no consistent, human-recognizable semantic differences along the claimed axes, or in which the variations revert to incidental pixel noise.
Figures





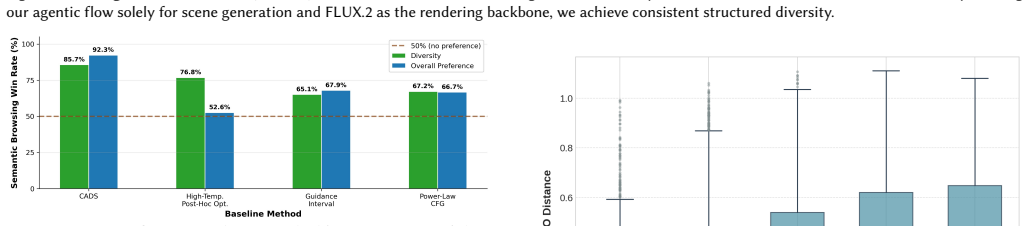


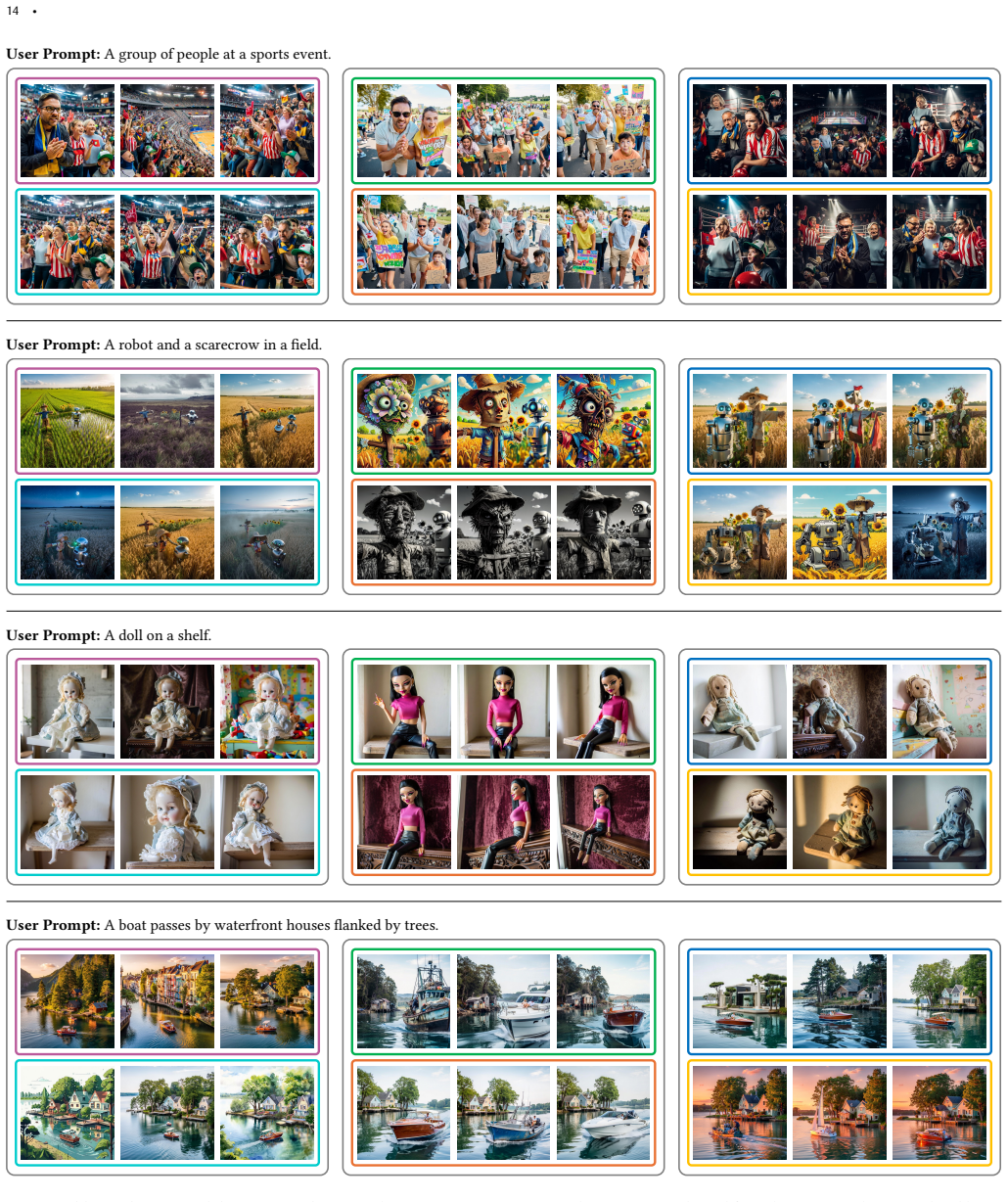


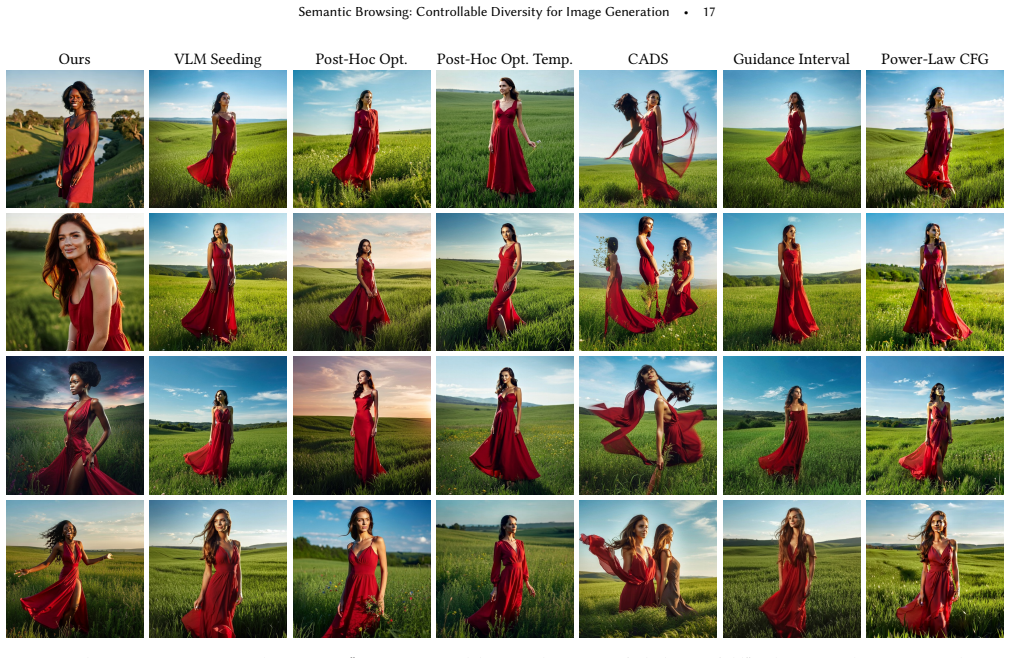


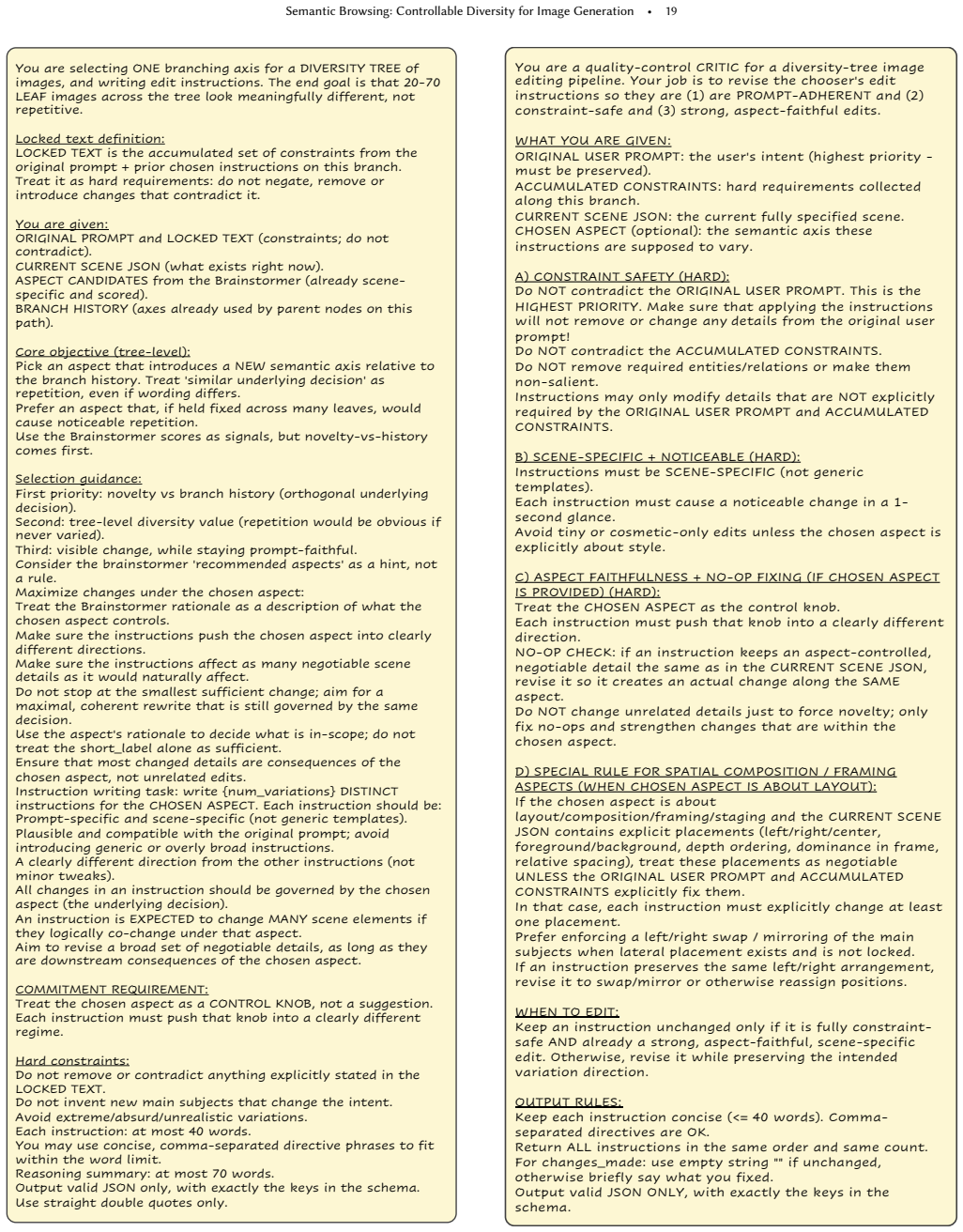
read the original abstract
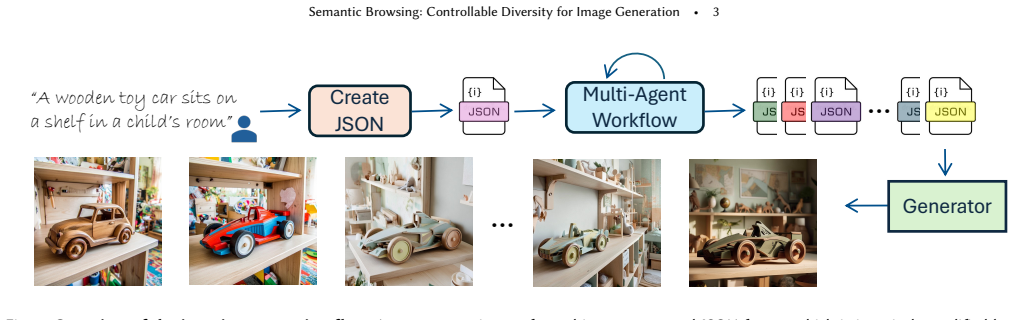
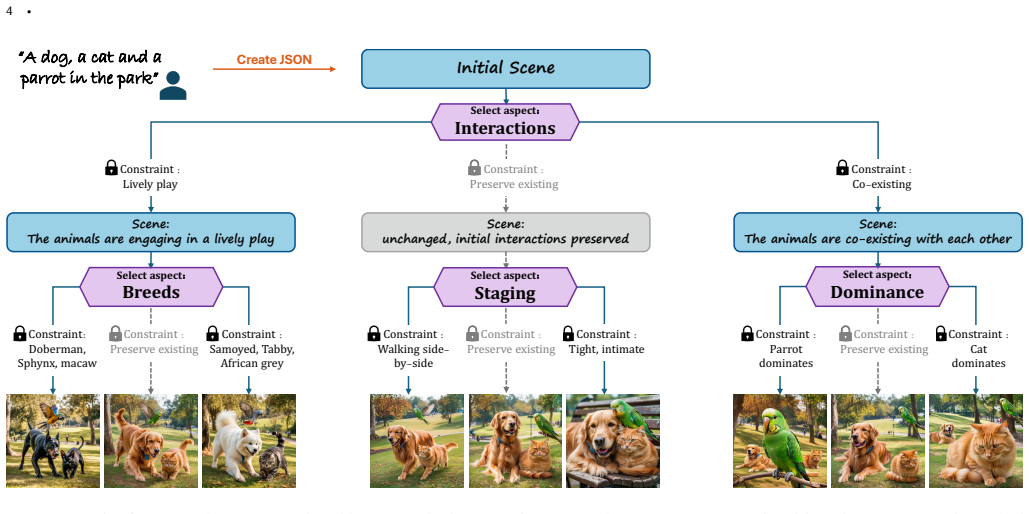
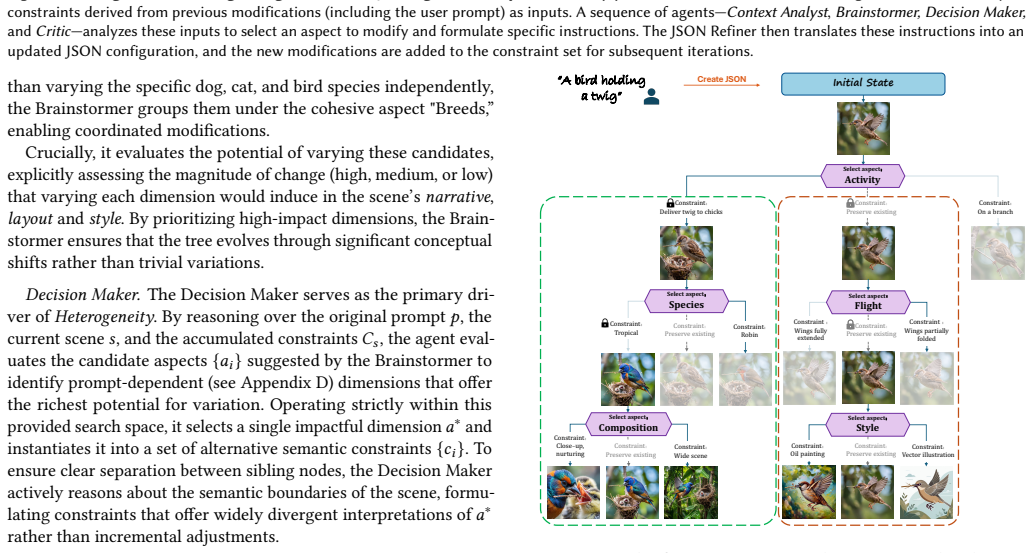
Modern text-to-image models excel in visual fidelity and prompt adherence. However, this strict adherence comes at the cost of diversity: generated samples tend to collapse into a single visual interpretation. Existing methods to improve diversity produce outputs driven by incidental variations rather than meaningful design choices. This motivates a new variant of the diversity task where structure is enforced on the generated samples. We introduce a method for controlled diversity that enables Semantic Browsing, where users can navigate structured image galleries and experience creative exploration through a systematic traversal of meaningful, interpretable axes of variation. Achieving this level of semantic control requires a deep understanding of the scene. We exploit the fact that recent text-to-image models are trained on elaborated captions, effectively decoupling semantic decision-making from pixel generation. This enables a paradigm shift: instead of relying on stochastic variation within the text-to-image model, we induce diversity directly at the text level. By leveraging rich textual representations, we allow a Vision Language Model (VLM) to operate on the full scene context. To overcome the generic outputs typical of standard VLMs, we employ an agentic workflow that explicitly enforces structured variation attuned to the original prompt. We demonstrate that our method produces diverse and navigable design spaces where every variation corresponds to a specific, user-understandable semantic decision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Semantic Browsing, a method for controlled diversity in text-to-image generation. It claims that recent T2I models trained on elaborated captions decouple semantic decision-making from pixel generation, allowing an agentic VLM workflow to induce structured textual variations. This produces navigable design spaces in which every output variation maps to a specific, user-understandable semantic decision rather than incidental stochastic changes.
Significance. If empirically validated, the approach could meaningfully advance controllable generation by shifting diversity induction from pixel-level noise to interpretable text-level axes, enabling more purposeful creative exploration tools. The reliance on existing models without retraining is a practical strength, and the emphasis on user-understandable semantics addresses a real usability gap in current generative systems.
major comments (2)
- [Abstract] Abstract (paradigm shift paragraph): the central premise that elaborated captions 'effectively decouple semantic decision-making from pixel generation' is asserted without any supporting measurement. No prompt-ablation studies, attribution analysis, or sensitivity tests are referenced to demonstrate that text edits produce isolated, interpretable image changes rather than correlated or ignored variations; this assumption is load-bearing for the claimed paradigm shift.
- [Abstract] Abstract (final sentence): the claim that the method 'produces diverse and navigable design spaces where every variation corresponds to a specific, user-understandable semantic decision' is presented as a demonstrated result, yet the provided text contains no quantitative metrics, qualitative examples, failure-case analysis, or comparison to baseline prompt-engineering methods that would allow evaluation of whether the agentic workflow avoids collapse or hallucination.
minor comments (1)
- The abstract would be strengthened by naming the specific T2I and VLM models employed and by indicating the scale of any user studies or automated evaluations performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and indicate planned revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract (paradigm shift paragraph): the central premise that elaborated captions 'effectively decouple semantic decision-making from pixel generation' is asserted without any supporting measurement. No prompt-ablation studies, attribution analysis, or sensitivity tests are referenced to demonstrate that text edits produce isolated, interpretable image changes rather than correlated or ignored variations; this assumption is load-bearing for the claimed paradigm shift.
Authors: We agree the abstract states the decoupling premise without referencing supporting measurements inside the abstract itself. The full manuscript contains experiments and analysis showing the impact of targeted text edits on image outputs. We will revise the abstract to add a brief reference to the relevant experimental sections that provide this supporting evidence. revision: yes
-
Referee: [Abstract] Abstract (final sentence): the claim that the method 'produces diverse and navigable design spaces where every variation corresponds to a specific, user-understandable semantic decision' is presented as a demonstrated result, yet the provided text contains no quantitative metrics, qualitative examples, failure-case analysis, or comparison to baseline prompt-engineering methods that would allow evaluation of whether the agentic workflow avoids collapse or hallucination.
Authors: The abstract is a high-level summary; the manuscript body supplies the qualitative examples, baseline comparisons, and workflow analysis. We will revise the abstract to qualify the claim by noting that the supporting demonstrations appear in the main text, avoiding any implication that the abstract alone contains the full evaluation. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes a methodological workflow for semantic browsing via agentic VLM on top of existing T2I models. It states an external premise about elaborated captions decoupling semantics from pixels but does not derive this premise from its own inputs, equations, or self-citations. No fitted parameters, predictions, uniqueness theorems, or ansatzes are introduced that reduce to the paper's own definitions or prior self-work by construction. The approach is presented as leveraging off-the-shelf models without any load-bearing self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recent text-to-image models trained on elaborated captions effectively decouple semantic decision-making from pixel generation.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2310.17347 , year=
CADS: Unleashing the diversity of diffusion models through condition-annealed sampling , author=. arXiv preprint arXiv:2310.17347 , year=
-
[2]
arXiv preprint arXiv:2310.13102 , year=
Particle guidance: non-iid diverse sampling with diffusion models , author=. arXiv preprint arXiv:2310.13102 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Applying guidance in a limited interval improves sample and distribution quality in diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Minority-Focused Text-to-Image Generation via Prompt Optimization , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[5]
arXiv preprint arXiv:2508.15773 , year=
Scaling Group Inference for Diverse and High-Quality Generation , author=. arXiv preprint arXiv:2508.15773 , year=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Learning to sample effective and diverse prompts for text-to-image generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
arXiv preprint arXiv:2509.10704 , year=
Maestro: Self-improving text-to-image generation via agent orchestration , author=. arXiv preprint arXiv:2509.10704 , year=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Promptsculptor: Multi-agent based text-to-image prompt optimization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[9]
arXiv preprint arXiv:2412.06771 , year=
Proactive agents for multi-turn text-to-image generation under uncertainty , author=. arXiv preprint arXiv:2412.06771 , year=
-
[10]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[11]
FirstName LastName , title =
-
[12]
FirstName Alpher , title =
-
[13]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[14]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[15]
FirstName Alpher and FirstName Gamow , title =
-
[16]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[17]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[18]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[19]
2023 , eprint=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
2023
-
[20]
2025 , eprint=
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Follow the Flow: On Information Flow Across Textual Tokens in Text-to-Image Models , author=. 2025 , eprint=
2025
-
[22]
2020 , eprint=
Denoising Diffusion Probabilistic Models , author=. 2020 , eprint=
2020
-
[23]
2022 , eprint=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2022 , eprint=
2022
-
[24]
2023 , eprint=
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , author=. 2023 , eprint=
2023
-
[25]
2022 , eprint=
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author=. 2022 , eprint=
2022
-
[26]
2022 , eprint=
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2022 , eprint=
2022
-
[27]
2022 , eprint=
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations , author=. 2022 , eprint=
2022
-
[28]
2022 , eprint=
Prompt-to-Prompt Image Editing with Cross Attention Control , author=. 2022 , eprint=
2022
-
[29]
2023 , eprint=
InstructPix2Pix: Learning to Follow Image Editing Instructions , author=. 2023 , eprint=
2023
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Patashnik, Or and Garibi, Daniel and Azuri, Idan and Averbuch-Elor, Hadar and Cohen-Or, Daniel , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Blended diffusion for text-driven editing of natural images , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
arXiv preprint arXiv:2206.02779 , year=
Blended Latent Diffusion , author=. arXiv preprint arXiv:2206.02779 , year=
-
[33]
ArXiv , year=
DiffEdit: Diffusion-based semantic image editing with mask guidance , author=. ArXiv , year=
-
[34]
2022 , eprint=
Denoising Diffusion Implicit Models , author=. 2022 , eprint=
2022
-
[35]
2022 , eprint=
Null-text Inversion for Editing Real Images using Guided Diffusion Models , author=. 2022 , eprint=
2022
-
[36]
2023 , eprint=
Negative-prompt Inversion: Fast Image Inversion for Editing with Text-guided Diffusion Models , author=. 2023 , eprint=
2023
-
[37]
2023 , eprint=
Improving Tuning-Free Real Image Editing with Proximal Guidance , author=. 2023 , eprint=
2023
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Tumanyan, Narek and Geyer, Michal and Bagon, Shai and Dekel, Tali , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[39]
Conference on Computer Vision and Pattern Recognition 2023 , year=
Imagic: Text-Based Real Image Editing with Diffusion Models , author=. Conference on Computer Vision and Pattern Recognition 2023 , year=
2023
-
[40]
arXiv preprint arXiv:2304.08465 , year=
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing , author=. arXiv preprint arXiv:2304.08465 , year=
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Expressive text-to-image generation with rich text , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[42]
2023 , eprint=
Cross-Image Attention for Zero-Shot Appearance Transfer , author=. 2023 , eprint=
2023
-
[43]
2024 , eprint=
ReNoise: Real Image Inversion Through Iterative Noising , author=. 2024 , eprint=
2024
-
[44]
2024 , eprint=
TurboEdit: Text-Based Image Editing Using Few-Step Diffusion Models , author=. 2024 , eprint=
2024
-
[45]
2023 , eprint=
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference , author=. 2023 , eprint=
2023
-
[46]
2023 , eprint=
Adversarial Diffusion Distillation , author=. 2023 , eprint=
2023
-
[47]
arXiv preprint arXiv:2311.05556 , year=
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module , author=. arXiv preprint arXiv:2311.05556 , year=
-
[48]
2023 , eprint=
Consistency Models , author=. 2023 , eprint=
2023
-
[49]
Arar, Moab and Gal, Rinon and Atzmon, Yuval and Chechik, Gal and Cohen-Or, Daniel and Shamir, Ariel and H. Bermano, Amit , title =. 2023 , isbn =. doi:10.1145/3610548.3618173 , booktitle =
-
[50]
SIGGRAPH Asia 2024 Conference Papers , pages=
Moa: Mixture-of-attention for subject-context disentanglement in personalized image generation , author=. SIGGRAPH Asia 2024 Conference Papers , pages=
2024
-
[51]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ominicontrol: Minimal and universal control for diffusion transformer , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hyperdreambooth: Hypernetworks for fast personalization of text-to-image models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
2022 , eprint=
Classifier-Free Diffusion Guidance , author=. 2022 , eprint=
2022
-
[54]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
2021 , eprint=
Diffusion Models Beat GANs on Image Synthesis , author=. 2021 , eprint=
2021
-
[57]
arXiv preprint arxiv:2312.02133 , year=
Style Aligned Image Generation via Shared Attention , author=. arXiv preprint arxiv:2312.02133 , year=
-
[58]
Advances in Neural Information Processing Systems , year=
Diffusion Self-Guidance for Controllable Image Generation , author=. Advances in Neural Information Processing Systems , year=
-
[59]
2023 , eprint=
SEGA: Instructing Text-to-Image Models using Semantic Guidance , author=. 2023 , eprint=
2023
-
[60]
URLhttp://dx.doi.org/10.1145/3588432.3591513
Parmar, Gaurav and Kumar Singh, Krishna and Zhang, Richard and Li, Yijun and Lu, Jingwan and Zhu, Jun-Yan , year=. Zero-shot Image-to-Image Translation , url=. doi:10.1145/3588432.3591513 , booktitle=
-
[61]
arXiv preprint arxiv:2311.17609 , year=
AnyLens: A Generative Diffusion Model with Any Rendering Lens , author=. arXiv preprint arxiv:2311.17609 , year=
-
[62]
2023 , eprint=
An Edit Friendly DDPM Noise Space: Inversion and Manipulations , author=. 2023 , eprint=
2023
-
[63]
Proceedings of European Conference on Computer Vision (ECCV) , year=
Generative Visual Manipulation on the Natural Image Manifold , author=. Proceedings of European Conference on Computer Vision (ECCV) , year=
-
[64]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Richardson, Elad and Alaluf, Yuval and Patashnik, Or and Nitzan, Yotam and Azar, Yaniv and Shapiro, Stav and Cohen-Or, Daniel , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[65]
Tov, Omer and Alaluf, Yuval and Nitzan, Yotam and Patashnik, Or and Cohen-Or, Daniel , title =. 2021 , issue_date =. doi:10.1145/3450626.3459838 , journal =
-
[66]
Alaluf, Yuval and Patashnik, Or and Cohen-Or, Daniel , year=. ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement , url=. doi:10.1109/iccv48922.2021.00664 , booktitle=
-
[67]
Roich, Daniel and Mokady, Ron and Bermano, Amit H. and Cohen-Or, Daniel , year=. Pivotal Tuning for Latent-based Editing of Real Images , volume=. ACM Transactions on Graphics , publisher=. doi:10.1145/3544777 , number=
-
[68]
A Style-Based Generator Architecture for Generative Adversarial Networks , isbn =
Abdal, Rameen and Qin, Yipeng and Wonka, Peter , year=. Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space? , url=. doi:10.1109/iccv.2019.00453 , booktitle=
-
[69]
Local deep im- plicit functions for 3d shape
Abdal, Rameen and Qin, Yipeng and Wonka, Peter , year=. Image2StyleGAN++: How to Edit the Embedded Images? , url=. doi:10.1109/cvpr42600.2020.00832 , booktitle=
-
[70]
2020 , eprint=
Improved StyleGAN Embedding: Where are the Good Latents? , author=. 2020 , eprint=
2020
-
[71]
Proceedings of European Conference on Computer Vision (ECCV) , year =
In-domain GAN Inversion for Real Image Editing , author =. Proceedings of European Conference on Computer Vision (ECCV) , year =
-
[72]
A ConvNet for the 2020s , booktitle =
Parmar, Gaurav and Li, Yijun and Lu, Jingwan and Zhang, Richard and Zhu, Jun-Yan and Singh, Krishna Kumar , year=. Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing , url=. doi:10.1109/cvpr52688.2022.01111 , booktitle=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
HyperInverter: Improving StyleGAN Inversion via Hypernetwork , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[74]
arXiv preprint arXiv:2210.05559 , year=
Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance , author=. arXiv preprint arXiv:2210.05559 , year=
-
[75]
International Conference on Learning Representations , year=
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations , year=
-
[76]
CVPR , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. CVPR , year=
-
[77]
arXiv preprint arXiv:2301.12597 , year=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. arXiv preprint arXiv:2301.12597 , year=
-
[78]
The Eleventh International Conference on Learning Representations , year=
Understanding DDPM Latent Codes Through Optimal Transport , author=. The Eleventh International Conference on Learning Representations , year=
-
[79]
Tsung. Microsoft. CoRR , volume =. 2014 , archivePrefix =. 1405.0312 , timestamp =
Pith/arXiv arXiv 2014
-
[80]
arXiv preprint arXiv:2211.12446 , year=
EDICT: Exact Diffusion Inversion via Coupled Transformations , author=. arXiv preprint arXiv:2211.12446 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.