When Retrieval Metrics Mislead: Measuring Policy Signal in Long-Horizon Tool-Use Agents
Pith reviewed 2026-06-26 08:03 UTC · model grok-4.3
The pith
Exact-match clause recall underestimates downstream policy utility in tool-use agents
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
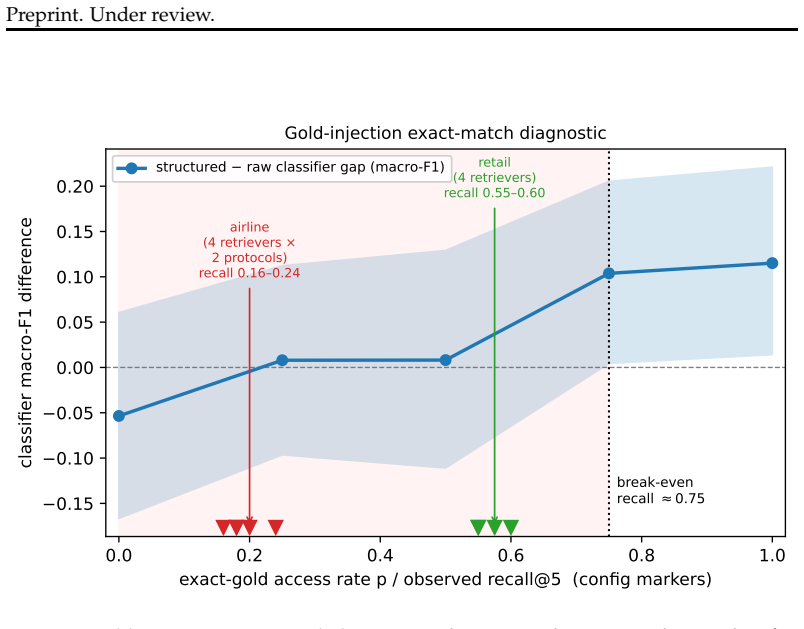
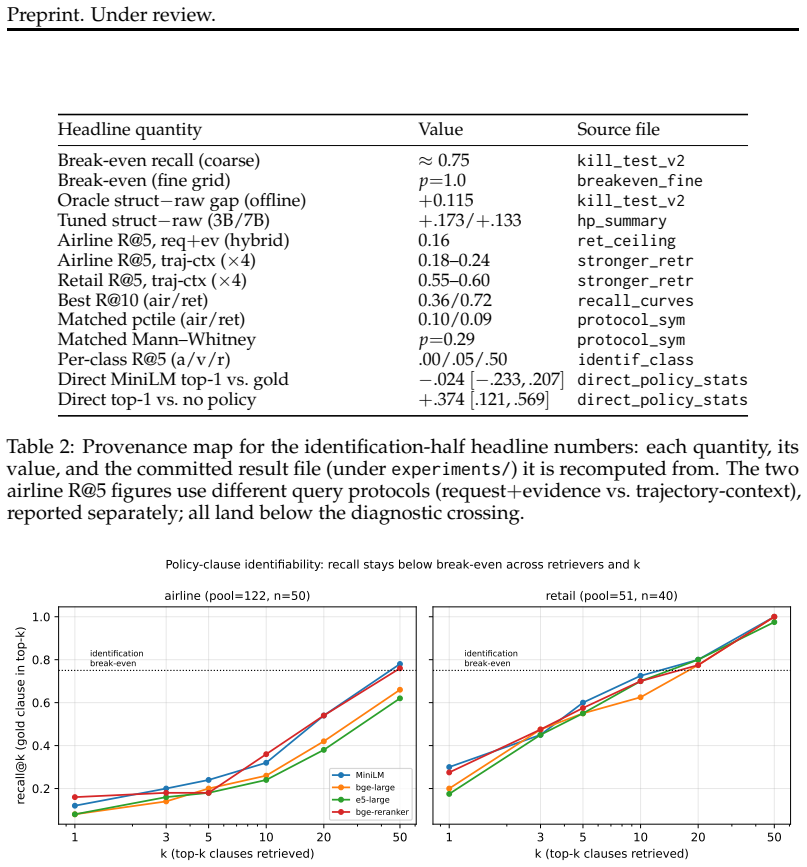
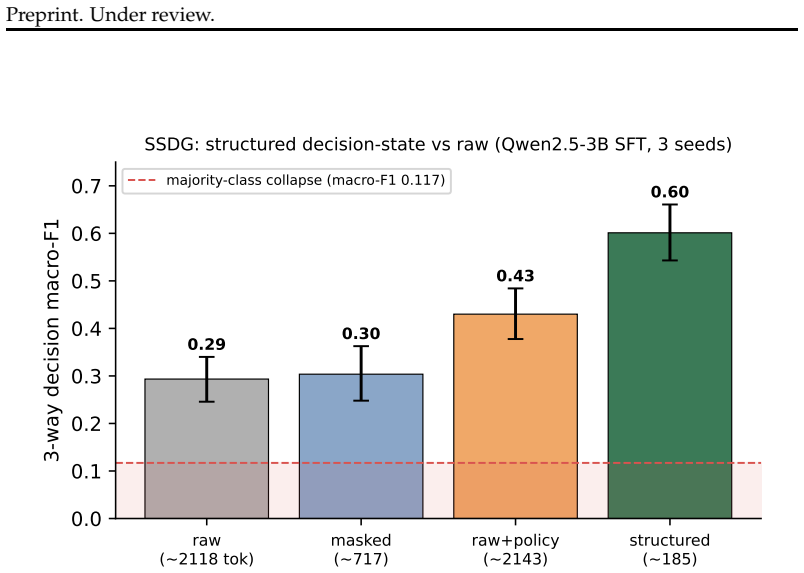
When the benchmark-designated policy clause is replaced by the top-ranked clause retrieved from decision-time context, the primary 3B classifier obtains macro-F1 0.58 with retrieved clauses versus 0.60 with gold clauses (Delta=-0.02). Although the exact governing clause is retrieved at rank 1 for only 7% of states, mismatched-policy and no-policy controls score 0.32 and 0.21. The same qualitative pattern appears with a second retriever and at 7B scale, while varying across fine-tuning configurations.
What carries the argument
Policy classification performance measured by macro-F1 on tau-bench states, comparing gold policy clauses against top-retrieved clauses from decision-time context.
If this is right
- Exact-match recall at rank 1 occurs for only 7% of states yet does not produce a detectable macro-F1 drop.
- Mismatched-policy controls score 0.32 macro-F1, confirming that some policy signal is captured even without exact matches.
- No-policy controls score 0.21, lower than both gold and retrieved conditions.
- The pattern of near-equivalent performance holds across two retrievers and both 3B and 7B classifiers.
Where Pith is reading between the lines
- Retrieval systems for agents could be optimized for semantic or approximate policy matches rather than exact clause identity.
- The finding suggests that structured state representations plus retrieved policies may suffice for classification even when exact recall is low.
- Proxy evaluations of this type could be extended to measure policy signal in other long-horizon decision benchmarks.
Load-bearing premise
The policy classification task performed by the tuned Qwen2.5-3B/7B models on tau-bench states serves as a faithful proxy for the policy signal that would be available to an actual downstream decision model in a long-horizon agent.
What would settle it
Directly measuring long-horizon agent success rates or action accuracy when the decision model receives retrieved clauses versus gold clauses in the full tau-bench loop.
Figures
read the original abstract
Exact-match retrieval recall is often used as a proxy for whether a retriever supplies useful policy context to a downstream decision model. We test this proxy for pre-action policy classification in tau-bench using Qwen2.5-3B/7B classifiers. Under gold-policy conditioning, a compact structured state improves macro-F1 over raw trajectories by 0.13-0.17 after tuning. We then replace the benchmark-designated policy clause with the top-ranked clause retrieved from decision-time context. Although the exact governing clause is retrieved at rank 1 for only 7% of airline states, the primary 3B classifier obtains macro-F1 0.58 with retrieved clauses versus 0.60 with gold clauses (Delta=-0.02, task-cluster 95% CI [-0.23,+0.21]); mismatched-policy and no-policy controls score 0.32 and 0.21. We do not detect a macro-F1 difference between retrieved and gold clauses in this configuration, although the interval remains too wide to establish non-inferiority. The same qualitative pattern appears with a second retriever and at 7B, while varying across fine-tuning configurations. These results indicate that exact-match clause recall can underestimate downstream policy utility in this benchmark setting, motivating evaluation with retrieved policies in the classification loop rather than recall alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that exact-match clause recall underestimates downstream policy utility for pre-action classification in tau-bench. Using tuned Qwen2.5-3B/7B classifiers, macro-F1 reaches 0.58 with top-retrieved clauses versus 0.60 with gold clauses (Delta=-0.02, task-cluster 95% CI [-0.23,+0.21]) despite only 7% rank-1 exact-match recall; mismatched-policy and no-policy controls score 0.32 and 0.21. The same pattern appears with a second retriever and at 7B scale (varying by fine-tuning configuration), leading to the conclusion that evaluation should use retrieved policies inside the classification loop rather than recall alone.
Significance. If the macro-F1 scores serve as a valid proxy, the work identifies a potential disconnect between standard retrieval metrics and actual policy signal in long-horizon agents, which could shift evaluation practices toward end-to-end utility measures. The control conditions and cross-configuration consistency provide some empirical grounding, though the wide CI prevents strong claims of equivalence.
major comments (3)
- [Abstract] Abstract: the central claim that exact-match recall underestimates policy utility rests on the assumption that macro-F1 from the tuned Qwen2.5-3B/7B classifiers is a faithful proxy for the policy signal available to an actual downstream decision model; no direct experiments measuring agent success rate, trajectory length, or error recovery when retrieved clauses are inserted into the real decision loop are reported.
- [Abstract] Abstract: the reported Delta=-0.02 with wide 95% CI [-0.23,+0.21] (explicitly too wide to establish non-inferiority) combined with the absence of full methods, data splits, tuning details, or state counts limits verification of the key empirical result that retrieved and gold clauses produce statistically indistinguishable F1.
- [Abstract] Abstract: the statement that the qualitative pattern 'varies across fine-tuning configurations' is noted without quantification or analysis of which configurations drive the variation, weakening robustness claims for the main finding.
minor comments (2)
- The term 'task-cluster 95% CI' is used without defining the clusters or the clustering procedure.
- No information is supplied on the number of states evaluated, number of runs, or how the 7% rank-1 recall was computed.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments on our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: the central claim that exact-match clause recall underestimates downstream policy utility rests on the assumption that macro-F1 from the tuned Qwen2.5-3B/7B classifiers is a faithful proxy for the policy signal available to an actual downstream decision model; no direct experiments measuring agent success rate, trajectory length, or error recovery when retrieved clauses are inserted into the real decision loop are reported.
Authors: Our study uses the macro-F1 of the tuned classifier as a proxy for the availability of policy signal to a downstream model. The substantial drop in F1 for the mismatched-policy (0.32) and no-policy (0.21) controls indicates that the metric is sensitive to policy correctness. We view direct agent-loop experiments as complementary but beyond the current scope, which focuses on retrieval evaluation. We will add a sentence clarifying the proxy nature and scope in the revised abstract and discussion. revision: partial
-
Referee: the reported Delta=-0.02 with wide 95% CI [-0.23,+0.21] (explicitly too wide to establish non-inferiority) combined with the absence of full methods, data splits, tuning details, or state counts limits verification of the key empirical result that retrieved and gold clauses produce statistically indistinguishable F1.
Authors: The abstract already notes that the CI is too wide to establish non-inferiority. Full details on methods, splits, tuning, and state counts are provided in the main text. To address verifiability concerns, we will append a brief summary of the dataset size and primary hyperparameters to the abstract. revision: yes
-
Referee: the statement that the qualitative pattern 'varies across fine-tuning configurations' is noted without quantification or analysis of which configurations drive the variation, weakening robustness claims for the main finding.
Authors: We concur that quantification is needed. The revision will include a table or text reporting the F1 deltas for each fine-tuning configuration at both 3B and 7B scales, along with a short analysis of observed variation. revision: yes
Circularity Check
No circularity: empirical measurements on independent classification task
full rationale
The paper's central result is an empirical comparison of macro-F1 scores for Qwen2.5 classifiers trained and evaluated on tau-bench states under gold-policy vs. retrieved-policy conditioning. No equations, fitted parameters, or self-citations are used to derive the reported deltas; the F1 values (0.58 vs 0.60) are direct outputs of standard fine-tuning and evaluation on held-out states. The claim that exact-match recall can underestimate policy utility follows from these measurements rather than reducing to them by construction. The proxy assumption (classification F1 as stand-in for downstream agent utility) is an interpretive limitation but does not create a self-referential loop in the reported numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The tau-bench airline task and Qwen2.5 classifiers constitute a representative test of policy utility for long-horizon tool-use agents.
Reference graph
Works this paper leans on
-
[1]
Beyond Token-level Answer Equivalence for Question Answering Evaluation , author=
Tomayto, Tomahto. Beyond Token-level Answer Equivalence for Question Answering Evaluation , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2022
-
[2]
2025 , eprint=
How important is Recall for Measuring Retrieval Quality? , author=. 2025 , eprint=
2025
-
[3]
2024 , eprint=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2024 , eprint=
2024
-
[4]
2024 , eprint=
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities , author=. 2024 , eprint=
2024
-
[5]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[6]
Advances in Neural Information Processing Systems , year=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , year=
-
[7]
2026 , eprint=
The Verifier Tax: Horizon-Dependent Safety-Success Tradeoffs in Tool-Using LLM Agents , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Toward Scalable Verifiable Reward: Proxy State-Based Evaluation for Multi-turn Tool-Calling LLM Agents , author=. 2026 , eprint=
2026
-
[9]
2023 , eprint=
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations , author=. 2023 , eprint=
2023
-
[10]
2026 , note=
When Interventions Don't Transfer: A Cross-Project Postmortem of Reward and Control Failures in Tool-Use and Grounded-Generation Agents , author=. 2026 , note=
2026
-
[11]
Proceedings of EMNLP-IJCNLP , year=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. Proceedings of EMNLP-IJCNLP , year=
-
[12]
2024 , eprint=
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems , author=. 2024 , eprint=
2024
-
[13]
2025 , eprint=
ShieldAgent: Shielding Agents via Verifiable Safety Policy Reasoning , author=. 2025 , eprint=
2025
-
[14]
2026 , eprint=
Solver-Aided Verification of Policy Compliance in Tool-Augmented LLM Agents , author=. 2026 , eprint=
2026
-
[15]
2023 , eprint=
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=. 2023 , eprint=
2023
-
[16]
Knowing What You Know: Calibrating Dialogue Belief State Distributions via Ensembles , author=. Findings of EMNLP , year=. 2010.02586 , archivePrefix=
arXiv 2010
-
[17]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=. 2022 , eprint=
2022
-
[18]
2024 , eprint=
Qwen2.5 Technical Report , author=. 2024 , eprint=
2024
-
[19]
Madhusudhan, Nishanth and others , year=. Do. 2407.16221 , archivePrefix=
-
[20]
2023 , eprint=
Large Language Models Should Ask Clarifying Questions to Increase Confidence in Generated Code , author=. 2023 , eprint=
2023
-
[21]
2026 , eprint=
Not All Skills Help: Measuring and Repairing Agent Knowledge , author=. 2026 , eprint=
2026
-
[22]
2025 , eprint=
Towards Enforcing Company Policy Adherence in Agentic Workflows , author=. 2025 , eprint=
2025
-
[23]
2024 , eprint=
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning , author=. 2024 , eprint=
2024
-
[24]
2025 , eprint=
ARPaCCino: An Agentic-RAG for Policy as Code Compliance , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. 2025 , eprint=
2025
-
[26]
2026 , eprint=
Beyond Similarity: Task-Aligned Retrieval for Language Models , author=. 2026 , eprint=
2026
-
[27]
2025 , eprint=
Retrieval Models Aren't Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models , author=. 2025 , eprint=
2025
-
[28]
2026 , eprint=
Looking Is Not Picking: An Attention-Segment Account of Tool-Selection Failures in LLM Agents , author=. 2026 , eprint=
2026
-
[29]
2025 , eprint=
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
MANTRA: Synthesizing SMT-Validated Compliance Benchmarks for Tool-Using LLM Agents , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.