Constrained Variable Projection for Structured Problems
Pith reviewed 2026-06-26 06:57 UTC · model grok-4.3
The pith
Interpreting variable projection as a collapsed bilevel problem produces exact reduced gradients and a convergent conditional-gradient algorithm for constrained nonlinear least-squares tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By interpreting variable projection as a collapsed bilevel optimization problem, exact reduced-gradient formulas compatible with automatic differentiation are derived and a conditional-gradient algorithm is proposed for the resulting constrained reduced problem, with convergence guarantees under standard smoothness and compactness assumptions and extensions discussed for structured lower-level variables.
What carries the argument
The collapsed bilevel formulation that eliminates the lower-level least-squares solve to produce an equivalent constrained reduced problem.
If this is right
- The conditional-gradient algorithm converges to a stationary point of the reduced problem under the stated assumptions.
- Exact reduced gradients can be obtained via automatic differentiation without additional derivation.
- The framework extends to cases with structured lower-level variables.
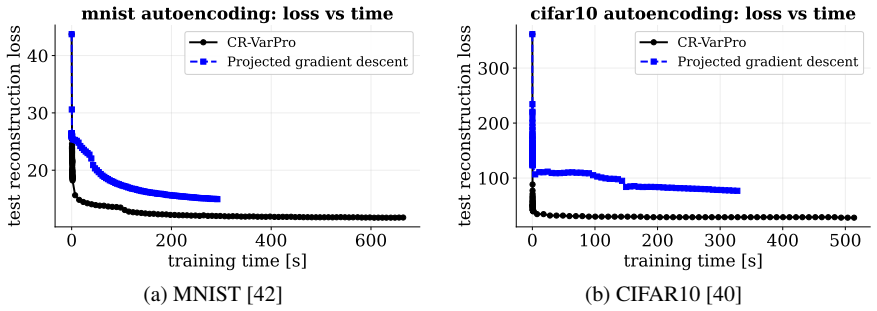
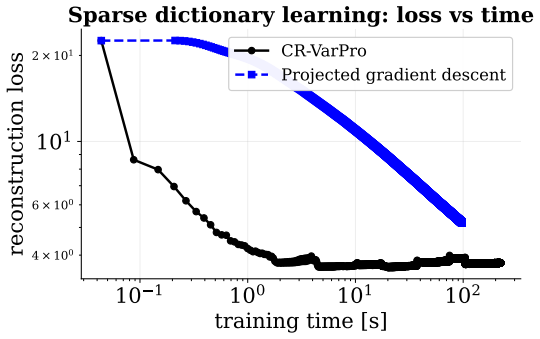
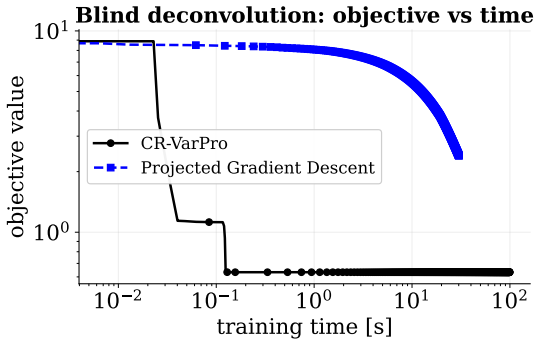
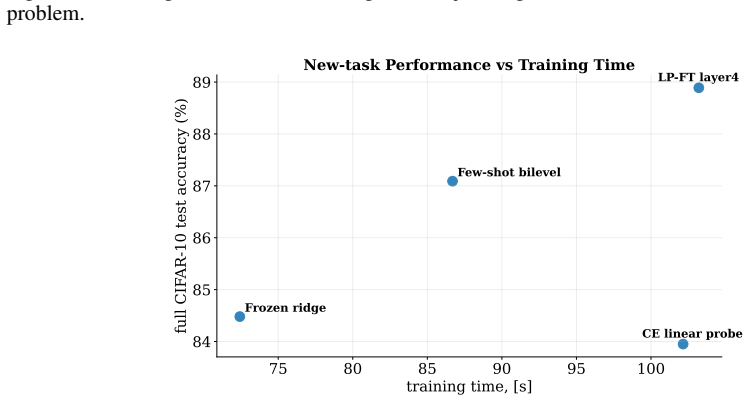
- Wall-clock and data efficiency improve relative to joint optimization on the four reported application domains.
Where Pith is reading between the lines
- The same bilevel collapse could be applied to other separable convex subproblems beyond least squares.
- Implementation inside existing automatic-differentiation libraries becomes straightforward for models that contain linear layers subject to constraints.
- The approach may reduce memory requirements during training when many variables can be eliminated exactly.
Load-bearing premise
The reduced objective is smooth and the feasible set is compact.
What would settle it
A concrete instance satisfying the smoothness and compactness conditions on which the conditional-gradient iterates fail to converge to a stationary point of the reduced problem.
Figures
read the original abstract
Variable projection is a classical technique for separable nonlinear least-squares problems, in which variables that enter linearly are eliminated exactly, yielding a reduced nonlinear problem. By expressing this framework as a particular instance of a broader class of bilevel optimization problems, we develop a constrained variable-projection framework for data-science models, where the remaining variables are subject to convex constraints and the eliminated variables arise from a lower-level least-squares problem. In particular, by interpreting variable projection as a collapsed bilevel optimization problem, we derive exact reduced-gradient formulas compatible with automatic differentiation and propose a conditional-gradient algorithm for the resulting constrained reduced problem. We establish convergence guarantees under standard smoothness and compactness assumptions, and discuss extensions to structured lower-level variables. Numerical experiments on sparse autoencoding, dictionary learning, blind deconvolution, and few-shot learning suggest that the method can improve wall-clock efficiency and data efficiency relative to natural joint-optimization baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that variable projection can be recast as a collapsed bilevel optimization problem, yielding exact reduced-gradient formulas compatible with automatic differentiation. It proposes a conditional-gradient (Frank-Wolfe) algorithm for the resulting constrained reduced problem, establishes convergence under standard smoothness and compactness assumptions on the reduced objective and feasible set, discusses extensions to structured lower-level variables, and reports numerical experiments on sparse autoencoding, dictionary learning, blind deconvolution, and few-shot learning that suggest gains in wall-clock and data efficiency over joint-optimization baselines.
Significance. If the derivations and convergence analysis hold, the work supplies a principled extension of classical variable projection to settings with convex constraints on the nonlinear variables. The bilevel reduction produces exact reduced gradients that integrate with AD, and the convergence result rests explicitly on the usual conditions for Frank-Wolfe methods rather than novel assumptions. The numerical comparisons provide concrete evidence of practical utility for structured data-science problems.
minor comments (2)
- [§3] §3 (or wherever the reduced-gradient derivation appears): the manuscript should explicitly state the precise form of the reduced gradient (e.g., the expression involving the pseudoinverse or adjoint) so that readers can verify compatibility with AD without reconstructing the bilevel collapse.
- [Numerical experiments] Numerical experiments section: the description of post-hoc parameter choices (step-size rules, stopping tolerances, constraint sets) should be expanded so that the reported efficiency gains can be reproduced from the stated protocol.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the recognition of its contributions to extending variable projection via bilevel collapse, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper frames variable projection as a collapsed bilevel problem to derive exact reduced-gradient formulas, then applies a conditional-gradient method with convergence under explicitly stated standard smoothness and compactness assumptions on the reduced objective. These assumptions are the usual Frank-Wolfe conditions and are not derived from or equivalent to the target result. The abstract and reader's summary give no indication of self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central claim to its own inputs. The derivation is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption standard smoothness and compactness assumptions suffice for convergence of the conditional-gradient algorithm on the reduced problem
Reference graph
Works this paper leans on
-
[1]
AGRAWAL, B
A. AGRAWAL, B. AMOS, S. BARRATT, S. BOYD, S. DIAMOND,ANDJ. Z. KOLTER,Differen- tiable convex optimization layers, in Advances in Neural Information Processing Systems, vol. 32, 2019, pp. 9558–9570
2019
-
[2]
ALAIN ANDY
G. ALAIN ANDY. BENGIO,Understanding intermediate layers using linear classifier probes, 2017
2017
-
[3]
AMOS ANDJ
B. AMOS ANDJ. Z. KOLTER,OptNet: Differentiable optimization as a layer in neural networks, in Proceedings of the 34th International Conference on Machine Learning, vol. 70 of Proceedings of Machine Learning Research, PMLR, 2017, pp. 136–145
2017
-
[4]
J. F. BARD,Practical Bilevel Optimization: Algorithms and Applications, vol. 30 of Nonconvex Optimization and Its Applications, Springer, Boston, MA, 1998,https://doi.org/10.1007/ 978-1-4757-2836-1
1998
-
[5]
Y. BENGIO, L. YAO, G. ALAIN,ANDP. VINCENT,Generalized denoising auto-encoders as gen- erative models, 2013,https://arxiv.org/abs/1305.6663
Pith/arXiv arXiv 2013
-
[6]
D. P. BERTSEKAS,Convex optimization algorithms, Athena Scientific, Belmont, 2015
2015
-
[7]
BLONDEL, Q
M. BLONDEL, Q. BERTHET, M. CUTURI, R. FROSTIG, S. HOYER, F. LLINARES-L ´OPEZ, F. PE- DREGOSA,ANDJ.-P. VERT,Efficient and modular implicit differentiation, in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 5230–5242
2022
-
[8]
I. M. BOMZE, F. RINALDI,ANDD. ZEFFIRO,Active set complexity of the away-step Frank–Wolfe algorithm, SIAM Journal on Optimization, 30 (2020), pp. 2470–2500,https://doi.org/10. 1137/19M1309419
2020
-
[9]
I. M. BOMZE, F. RINALDI,ANDD. ZEFFIRO,Frank–Wolfe and friends: a journey into projection- free first-order optimization methods, 4OR, 19 (2021), pp. 313–345,https://doi.org/10. 1007/s10288-021-00493-y
2021
-
[10]
G. BRAUN, A. CARDERERA, C. W. COMBETTES, H. HASSANI, A. KARBASI, A. MOKHTARI, ANDS. POKUTTA,Conditional Gradient Methods: From Core Principles to AI Applications, MOS- SIAM Series on Optimization, Society for Industrial and Applied Mathematics, 2025,https: //doi.org/10.1137/1.9781611978568
-
[11]
J. J. BRUST,Nonlinear least-squares for large-scale machine learning using stochastic jacobian estimates, arXiv preprint arXiv:1412.6980, (2021)
Pith/arXiv arXiv 2021
-
[12]
A. B ¨ARLIGEA, P. HOCHSTAFFL,ANDF. SCHREIER,A generalized variable projection algorithm for least squares problems in atmospheric remote sensing, Mathematics, 11 (2023),https://doi. org/10.3390/math11132839
-
[13]
E. J. CAND `ES, X. LI, Y. MA,ANDJ. WRIGHT,Robust principal component analysis?, Journal of the ACM, 58 (2011), pp. 11:1–11:37,https://doi.org/10.1145/1970392.1970395. 17
-
[14]
CARLINI ANDD
N. CARLINI ANDD. WAGNER,Towards evaluating the robustness of neural networks, in 2017 IEEE Symposium on Security and Privacy, IEEE, 2017, pp. 39–57,https://doi.org/10.1109/ SP.2017.49
2017
-
[15]
G. CHAVENT,Nonlinear least squares for inverse problems, Scientific Computation, Springer, Dor- drecht, Netherlands, 2010 ed., Oct. 2009,https://doi.org/10.1007/978-90-481-2785-6
-
[16]
C. CHEN, D. LI, J. YAN,ANDX. YANG,Modeling dynamic user preference via dictionary learn- ing for sequential recommendation, IEEE Transactions on Knowledge and Data Engineering, 34 (2022), pp. 5446–5458,https://doi.org/10.1109/TKDE.2021.3050407
-
[17]
G. CHEN, P. XUE, M. GAN, J. CHEN, W. GUO,ANDC. P. CHEN,Variable projection algo- rithms: Theoretical insights and a novel approach for problems with large residual, Automatica, 177 (2025), p. 112300,https://doi.org/10.1016/j.automatica.2025.112300
-
[18]
COLSON, P
B. COLSON, P. MARCOTTE,ANDG. SAVARD,An overview of bilevel optimization, Annals of Operations Research, 153 (2007), pp. 235–256,https://doi.org/10.1007/ s10479-007-0176-2
2007
-
[19]
C. W. COMBETTES ANDS. POKUTTA,Complexity of linear minimization and projection on some sets, Operations Research Letters, 49 (2021), pp. 565–571,https://doi.org/10.1016/j.orl. 2021.06.019
-
[20]
S. DEMPE ANDA. B. ZEMKOHO, eds.,Bilevel Optimization: Advances and Next Challenges, vol. 161 of Springer Optimization and Its Applications, Springer, Cham, 2020,https://doi. org/10.1007/978-3-030-52119-6
-
[21]
S. DONG ANDJ. YANG,Numerical approximation of partial differential equations by a variable projection method with artificial neural networks, Computer Methods in Applied Mechanics and Engineering, 398 (2022), p. 115284,https://doi.org/10.1016/j.cma.2022.115284
-
[22]
D. L. DONOHO,Compressed sensing, IEEE Transactions on Information Theory, 52 (2006), pp. 1289–1306,https://doi.org/10.1109/TIT.2006.871582
-
[23]
J. DUCHI, S. SHALEV-SHWARTZ, Y. SINGER,ANDT. CHANDRA,Efficient projections onto the ℓ1-ball for learning in high dimensions, in Proceedings of the 25th International Conference on Machine Learning, 2008, pp. 272–279,https://doi.org/10.1145/1390156.1390191
-
[24]
M. DUS,Grassmannian geometry and global convergence of variable projection for neural net- works, 2026,https://arxiv.org/abs/2601.22897
arXiv 2026
-
[25]
M. I. ESPANOL ANDG. JERONIMO,Local convergence analysis of a variable projection method for regularized separable nonlinear inverse problems, SIAM Journal on Matrix Analysis and Ap- plications, 46 (2025), pp. 858–878,https://doi.org/10.1137/24M1639087
-
[26]
FRANCESCHI, P
L. FRANCESCHI, P. FRASCONI, S. SALZO, R. GRAZZI,ANDM. PONTIL,Bilevel programming for hyperparameter optimization and meta-learning, in Proceedings of the 35th International Con- ference on Machine Learning, vol. 80 of Proceedings of Machine Learning Research, PMLR, 2018, pp. 1568–1577
2018
-
[27]
M. FRANK ANDP. WOLFE,An algorithm for quadratic programming, Nav. Res. Logist. Q., 3 (1956), pp. 95–110,https://doi.org/10.1002/nav.3800030109
-
[28]
GILLIS,Nonnegative Matrix Factorization, vol
N. GILLIS,Nonnegative Matrix Factorization, vol. 2 of Data Science, Society for Industrial and Applied Mathematics, Philadelphia, PA, 2020,https://doi.org/10.1137/1.9781611976410
-
[29]
GOLUB ANDV
G. GOLUB ANDV. PEREYRA,Separable nonlinear least squares: the variable projection method and its applications, Inverse problems, 19 (2003), p. R1,https://doi.org/10.1088/ 0266-5611/19/2/201
2003
-
[30]
G. H. GOLUB ANDR. LEVEQUE,Extensions and uses of the variable projection algorithm for solving nonlinear least squares problems., in Proceedings of the 1979 Army Numerical Analysis and Computers Conference, 1979
1979
-
[31]
G. H. GOLUB ANDV. PEREYRA,The differentiation of pseudo-inverses and nonlinear least squares problems whose variables separate, SIAM Journal on Numerical Analysis, 10 (1973), pp. 413–432,https://doi.org/10.1137/0710036. 18
-
[32]
S. GOULD, B. FERNANDO, A. CHERIAN, P. ANDERSON, R. SANTACRUZ,ANDE. GUO,On dif- ferentiating parameterized argmin and argmax problems with application to bi-level optimization, arXiv preprint arXiv:1607.05447, (2016),https://arxiv.org/abs/1607.05447
Pith/arXiv arXiv 2016
-
[33]
T. HASTIE, R. TIBSHIRANI,ANDM. WAINWRIGHT,Statistical Learning with Sparsity: The Lasso and Generalizations, Chapman and Hall/CRC, Boca Raton, FL, 2015,https://doi.org/ 10.1201/b18401
-
[34]
K. HE, X. ZHANG, S. REN,ANDJ. SUN,Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778, https://doi.org/10.1109/CVPR.2016.90
-
[35]
G. E. HINTON ANDR. R. SALAKHUTDINOV,Reducing the dimensionality of data with neural networks, Science, 313 (2006), pp. 504–507,https://doi.org/10.1126/science.1127647
-
[36]
HUBEN, H
R. HUBEN, H. CUNNINGHAM, L. R. SMITH, A. EWART,ANDL. SHARKEY,Sparse autoen- coders find highly interpretable features in language models, in The Twelfth International Confer- ence on Learning Representations, 2024
2024
-
[37]
JAGGI,Revisiting Frank-Wolfe: Projection-free sparse convex optimization, in Proceedings of the 30th International Conference on Machine Learning, S
M. JAGGI,Revisiting Frank-Wolfe: Projection-free sparse convex optimization, in Proceedings of the 30th International Conference on Machine Learning, S. Dasgupta and D. McAllester, eds., vol. 28 of Proceedings of Machine Learning Research, Atlanta, Georgia, USA, 17–19 Jun 2013, PMLR, pp. 427–435
2013
-
[38]
M. JAGGI,An equivalence between the lasso and support vector machines, in Regularization, Op- timization, Kernels, and Support Vector Machines, J. A. K. Suykens, ed., Taylor & Francis, 2014, pp. 1–26,https://doi.org/10.1201/b17558-4
-
[39]
KAUFMAN,A variable projection method for solving separable nonlinear least squares problems, BIT Numerical Mathematics, 15 (1975), pp
L. KAUFMAN,A variable projection method for solving separable nonlinear least squares problems, BIT Numerical Mathematics, 15 (1975), pp. 49–57,https://doi.org/10.1007/ BF01932995
1975
-
[40]
KRIZHEVSKY ANDG
A. KRIZHEVSKY ANDG. HINTON,Learning multiple layers of features from tiny images, Tech. Report 0, University of Toronto, Toronto, Ontario, 2009
2009
-
[41]
W. H. LAWTON ANDE. A. SYLVESTRE,Elimination of linear parameters in nonlinear regression, Technometrics, 13 (1971), pp. 461–467,https://doi.org/10.2307/1267160
-
[42]
LECUN, C
Y. LECUN, C. CORTES,ANDC. J. BURGES,The mnist database of handwritten digits, (1998)
1998
-
[43]
C. H. LIM ANDS. J. WRIGHT,A box-constrained approach for hard permutation problems, in Proceedings of the 33rd International Conference on Machine Learning, vol. 48 of Proceedings of Machine Learning Research, PMLR, 2016, pp. 2454–2463
2016
-
[44]
Selective review of offline change point detection methods,
I. MARKOVSKY,Recent progress on variable projection methods for structured low-rank ap- proximation, Signal Processing, 96 (2014), p. 406–419,https://doi.org/10.1016/j.sigpro. 2013.09.021
-
[45]
E. NEWMAN, J. CHUNG, M. CHUNG,ANDL. RUTHOTTO,slimtrain—a stochastic approximation method for training separable deep neural networks, SIAM Journal on Scientific Computing, 44 (2022), pp. A2322–A2348,https://doi.org/10.1137/21M1452512
-
[46]
E. NEWMAN, L. RUTHOTTO, J. HART,ANDB.VANBLOEMENWAANDERS,Train like a (var)pro: Efficient training of neural networks with variable projection, SIAM Journal on Mathe- matics of Data Science, 3 (2021), pp. 1041–1066,https://doi.org/10.1137/20M1359511
-
[47]
PETHICK, W
T. PETHICK, W. XIE, K. ANTONAKOPOULOS, Z. ZHU, A. SILVETI-FALLS,ANDV. CEVHER, Training deep learning models with norm-constrained LMOs, in Proceedings of the 42nd Interna- tional Conference on Machine Learning, vol. 267 of Proceedings of Machine Learning Research, PMLR, 2025, pp. 49069–49104
2025
-
[48]
B. RECHT, M. FAZEL,ANDP. A. PARRILO,Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization, SIAM Review, 52 (2010), pp. 471–501,https://doi. org/10.1137/070697835
-
[49]
R. RUBINSTEIN, A. M. BRUCKSTEIN,ANDM. ELAD,Dictionaries for sparse representation modeling, Proceedings of the IEEE, 98 (2010), pp. 1045–1057,https://doi.org/10.1109/ JPROC.2010.2040551. 19
arXiv 2010
-
[50]
D. B. C. SALZER, M. I. ESPA ˜NOL,ANDG. JERONIMO,Variable projection methods for solving regularized separable inverse problems with applications to semi-blind image deblurring, 2026, https://arxiv.org/abs/2601.05224
arXiv 2026
-
[51]
Sequential Monte Carlo samplers
R. TIBSHIRANI,Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society: Series B (Methodological), 58 (1996), pp. 267–288,https://doi.org/10.1111/j. 2517-6161.1996.tb02080.x
work page doi:10.1111/j 1996
-
[52]
M. TSCHANNEN, O. BACHEM,ANDM. LUCIC,Recent advances in autoencoder-based represen- tation learning, 2018,https://arxiv.org/abs/1812.05069
Pith/arXiv arXiv 2018
-
[53]
K. USEVICH ANDI. MARKOVSKY,Variable projection for affinely structured low-rank approx- imation in weighted 2-norms, Journal of Computational and Applied Mathematics, 272 (2014), pp. 430–448,https://doi.org/10.1016/j.cam.2013.04.034
-
[54]
K. USEVICH ANDI. MARKOVSKY,Variable projection methods for approximate (greatest) com- mon divisor computations, Theoretical Computer Science, 681 (2017), pp. 176–198,https: //doi.org/10.1016/j.tcs.2017.03.028. Symbolic Numeric Computation
-
[55]
T.VANLEEUWEN ANDA. Y. ARAVKIN,Variable projection for nonsmooth problems, SIAM Journal on Scientific Computing, 43 (2021), pp. S249–S268,https://doi.org/10.1137/ 20M1348650
2021
-
[56]
H.-L. XU, G.-Y. CHEN, S.-Q. CHENG, M. GAN,ANDJ. CHEN,Variable projection algorithms with sparse constraint for separable nonlinear models, Control Theory and Technology, 22 (2024), pp. 135–146,https://doi.org/10.1007/s11768-023-00194-3
-
[57]
ZANGRANDO, S
E. ZANGRANDO, S. VENTURINI, F. RINALDI,ANDF. TUDISCO,dEBORA: Efficient bilevel optimization-based low-rank adaptation, in International Conference on Learning Representations, 2025. 20
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.