CrossPool: Efficient Multi-LLM Serving for Cold MoE Models through KV-Cache and Weight Disaggregation
Pith reviewed 2026-06-25 22:50 UTC · model grok-4.3
The pith
Disaggregating FFN weights and KV-cache into separate GPU pools lets CrossPool serve many cold MoE models with up to 10.4× lower P99 time-between-tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
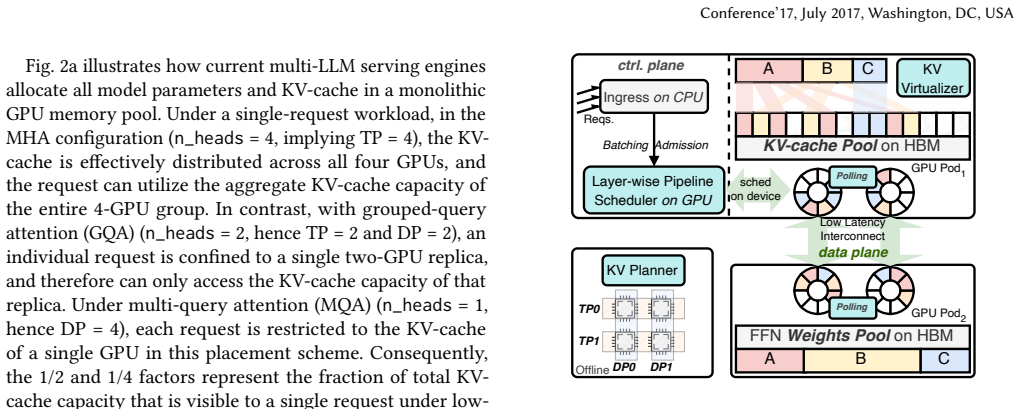
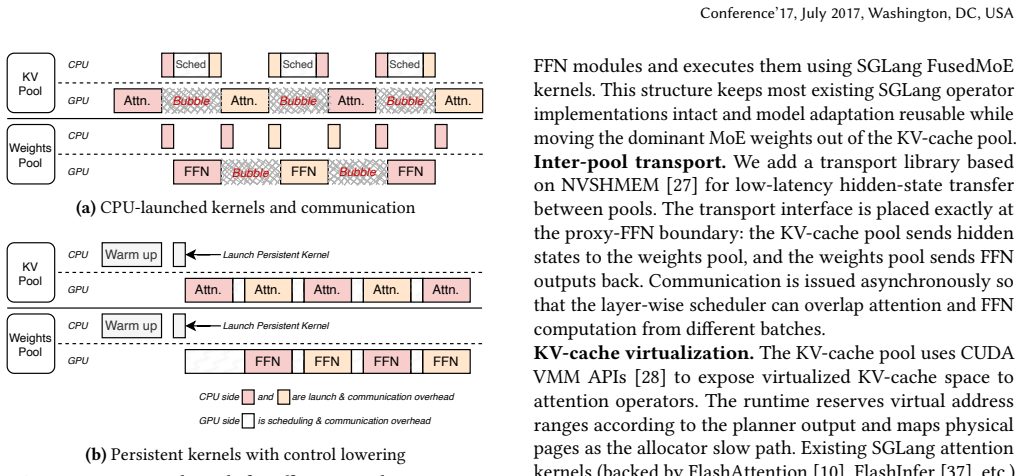
CrossPool is a serving engine that disaggregates FFN weights into a consolidation pool and KV-cache into a dynamic pool for cold MoE models. It uses a KV-cache planner and virtualizer, a layer-wise pipeline scheduler, and persistent kernels with control lowering to achieve high GPU memory utilization and reduce P99 TBT by up to 10.4 times versus state-of-the-art systems.
What carries the argument
The separation of FFN weights and KV-cache into two distinct GPU memory pools, with attention computation localized to the KV-cache pool.
If this is right
- Multiple cold models can share KV-cache capacity without per-model worst-case allocation.
- Bursty long-context requests can be handled without latency violations from memory contention.
- Hidden-state transfers between pools are hidden by the pipeline scheduler.
- CPU-GPU control overhead is reduced through persistent kernels.
- Overall, P99 TBT improves by up to 10.4× over monolithic approaches.
Where Pith is reading between the lines
- The disaggregation technique could apply to dense models if similar memory competition occurs.
- Cloud providers might adopt this to increase tenant density in LLM serving clusters.
- Future hardware with faster inter-pool transfers could amplify the benefits.
Load-bearing premise
That peak KV-cache demands across cold models do not coincide, so aggregate provisioning suffices without missing per-request latency targets.
What would settle it
A workload trace where several cold MoE models simultaneously hit their maximum KV-cache usage, causing the shared pool to exceed capacity and increase P99 TBT beyond baseline levels.
Figures

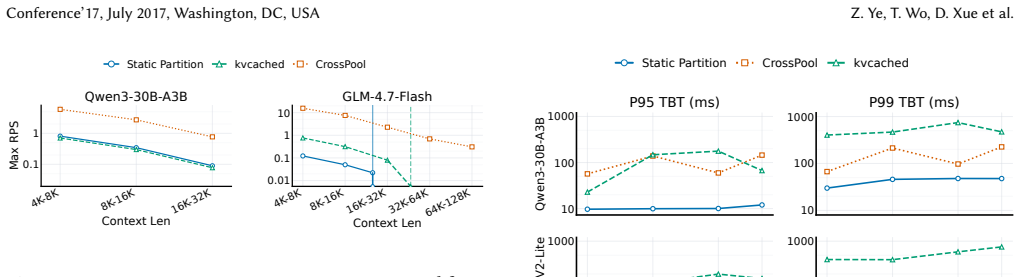
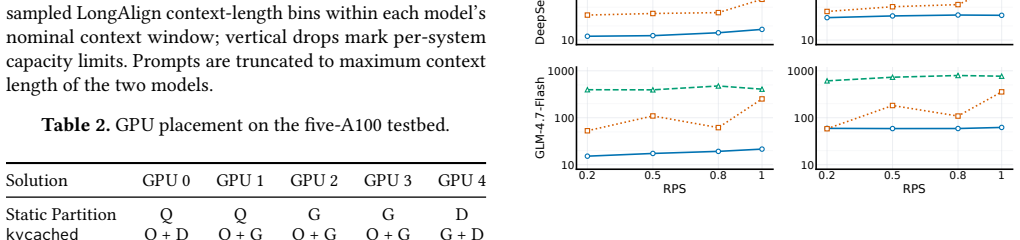
read the original abstract
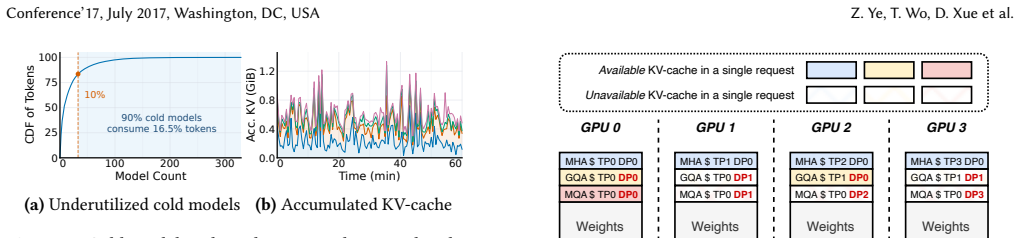
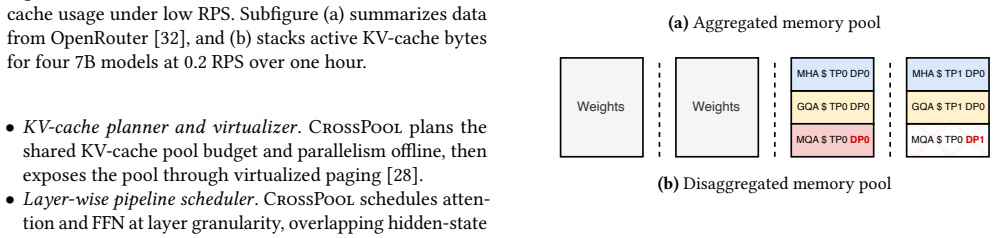
Emerging LLM services increasingly host many sparse MoE models, yet most models receive sparse requests and remain cold. This creates a GPU memory problem: model weights are stable and model-determined, while KV-cache is transient and demand-determined. Because cold models rarely reach peak KV-cache demand at the same time, reserving worst-case KV capacity per model wastes memory; a shared KV-cache pool can instead provision aggregate active demand. However, KV-cache sharing is not sufficient when weights and KV-cache remain in a monolithic GPU memory pool. Static weights compete with dynamic KV-cache, and KV-head-limited attention under cold, low-concurrency traffic exposes only a fraction of replicated KV capacity, leading to low GPU memory utilization and weak long-context support. We present CrossPool, a serving engine for cold MoE models that separates FFN weights and KV-cache into two GPU memory pools: a weights pool that consolidates FFN weights across cold models, and a KV-cache pool that dynamically serves active requests while keeping attention local to KV-cache. CrossPool combines a KV-cache planner and virtualizer, a layer-wise pipeline scheduler that hides hidden-state transfers, and persistent kernels with control lowering to reduce CPU-GPU control overhead. With efficient GPU memory pooling, CrossPool underpins bursty long-context requests and outperforms the state-of-the-art kvcached-based multi-LLM serving system, reducing P99 TBT by up to $10.4\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CrossPool, a serving system for multiple cold MoE LLMs that disaggregates FFN weights into a consolidated weights pool and KV-cache into a dynamic shared pool, augmented by a KV-cache planner/virtualizer, layer-wise pipeline scheduler to hide transfers, and persistent kernels with control lowering. It claims this enables efficient support for bursty long-context requests and delivers up to 10.4× reduction in P99 time-between-tokens versus the state-of-the-art kvcache-based multi-LLM serving system.
Significance. If the empirical gains prove robust, the disaggregation approach could meaningfully improve GPU memory utilization in multi-tenant LLM serving for sparsely accessed models, particularly under variable long-context workloads. The work provides concrete system mechanisms (planner, virtualizer, scheduler, kernels) that address a practical tension between static weights and dynamic KV-cache.
major comments (2)
- [Abstract] Abstract (motivation paragraph): the 10.4× P99 TBT claim and the ability to 'provision only aggregate active demand' rest on the premise that cold models rarely reach peak KV-cache demand simultaneously. No section, figure, or table in the manuscript provides a direct measurement or stress-test of peak-overlap frequency under the evaluated bursty long-context workloads; without this, the shared-pool benefit cannot be distinguished from workload selection effects.
- [Evaluation] The layer-wise pipeline scheduler and persistent kernels are presented as compensating for hidden-state transfers and control overhead, yet the manuscript does not quantify the residual latency when the KV-cache pool itself becomes contended (i.e., when aggregate demand exceeds provisioned capacity). A load-bearing experiment comparing contended vs. non-contended regimes is required to substantiate that the scheduler can still meet per-request latency targets.
minor comments (1)
- Notation for the two pools (weights pool vs. KV-cache pool) and the virtualizer interface should be defined once with consistent symbols rather than repeated descriptive phrases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comments point to gaps in our evaluation that we will address through additional analysis and experiments in the revised manuscript. We respond to each comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (motivation paragraph): the 10.4× P99 TBT claim and the ability to 'provision only aggregate active demand' rest on the premise that cold models rarely reach peak KV-cache demand simultaneously. No section, figure, or table in the manuscript provides a direct measurement or stress-test of peak-overlap frequency under the evaluated bursty long-context workloads; without this, the shared-pool benefit cannot be distinguished from workload selection effects.
Authors: We agree that a direct measurement of peak KV-cache demand overlap would strengthen the motivation for the shared pool. Our evaluated workloads are constructed from real-world traces of bursty long-context requests across multiple cold MoE models, where models are accessed sparsely. However, to directly address this, we will include in the revision a new analysis (e.g., a figure showing cumulative distribution of simultaneous peak demands across models) based on the workload traces used in our experiments. This will quantify the overlap frequency and support the claim that aggregate provisioning suffices. revision: yes
-
Referee: [Evaluation] The layer-wise pipeline scheduler and persistent kernels are presented as compensating for hidden-state transfers and control overhead, yet the manuscript does not quantify the residual latency when the KV-cache pool itself becomes contended (i.e., when aggregate demand exceeds provisioned capacity). A load-bearing experiment comparing contended vs. non-contended regimes is required to substantiate that the scheduler can still meet per-request latency targets.
Authors: The referee correctly identifies that our evaluation focuses on non-contended scenarios where the shared pool provisions aggregate demand. To substantiate the scheduler's effectiveness under contention, we will add experiments in the revised version that deliberately over-subscribe the KV-cache pool (e.g., by increasing request rates until aggregate demand exceeds capacity) and measure the resulting P99 TBT and whether latency targets are maintained. This will demonstrate the limits and robustness of the pipeline scheduler and persistent kernels. revision: yes
Circularity Check
No circularity; empirical system evaluation with no derivations or self-referential predictions
full rationale
The paper describes a serving engine (CrossPool) with memory disaggregation, a planner/virtualizer, scheduler, and kernels, then reports empirical latency gains (e.g., 10.4× P99 TBT) against a baseline. No equations, fitted parameters, or predictions appear; the central claim is an observed outcome of the implementation under stated traffic assumptions. No self-citations are invoked as load-bearing uniqueness theorems. The design is self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cold models rarely reach peak KV-cache demand simultaneously
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, ...
-
[2]
Alibaba Cloud. 2026. Alibaba Cloud Model Studio.https://modelstudio. alibabacloud.com. Accessed: 2026-05-08
2026
-
[3]
anon8231489123. 2023. ShareGPT Vicuna unfiltered. https://huggingface.co/datasets/anon8231489123/ShareGPT_ Vicuna_unfiltered. Accessed: 2026-05-08
2023
-
[4]
Anthropic. 2026. Claude Code.https://claude.com/product/claude- code. Accessed: 2026-05-08
2026
-
[5]
Yushi Bai, Xin Lv, Jiajie Zhang, Yuze He, Ji Qi, Lei Hou, Jie Tang, Yuxiao Dong, and Juanzi Li. 2024. LongAlign: A Recipe for Long Context Alignment of Large Language Models. InEMNLP (Findings) (Findings of ACL). Association for Computational Linguistics, 1376–1395
2024
-
[6]
ByteDance. 2026. Volcano Engine.https://www.volcengine.com. Ac- cessed: 2026-05-08
2026
-
[7]
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang
-
[8]
LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference.CoRRabs/2510.09665 (2025)
arXiv 2025
-
[9]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Tianle Li, et al . 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* Chat- GPT Quality.https://lmsys.org/blog/2023-03-30-vicuna/. Accessed: 2026-05-08
2023
-
[10]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wen- feng Liang. 2024. DeepSeekMoE: Towards Ultimate Expert Specializa- tion in Mixture-of-Experts Language Models. InACL (1). Association for Computational Lingui...
2024
-
[11]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[12]
InNeurIPS
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InNeurIPS
-
[13]
DeepInfra. 2026. DeepInfra.https://deepinfra.com. Accessed: 2026- 05-08
2026
-
[14]
DeepSeek-AI. 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.CoRRabs/2405.04434 (2024). arXiv:2405.04434 doi:10.48550/ARXIV.2405.04434
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434 2024
-
[15]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report.CoRR abs/2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[16]
DeepSeek-AI. 2026. DeepSeek.https://chat.deepseek.com. Accessed: 2026-05-08
2026
-
[17]
DeepSeek-AI. 2026. DeepSeek-V4: Towards Highly Efficient Million- Token Context Intelligence.https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf. Technical Report
2026
-
[18]
Hui Dong and Marvin K Nakayama. 2018. A tutorial on quantile estimation via Monte Carlo. InInternational Conference on Monte Carlo and Quasi-Monte Carlo Methods in Scientific Computing. Springer, 3– 30
2018
-
[19]
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, and Hao Zhang. 2024. MuxServe: Flexible Spatial-Temporal Multiplexing for Multiple LLM Serving. InICML (Proceedings of Machine Learning Research). PMLR / OpenReview.net, 11905–11917
2024
-
[20]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Trans- formers: Scaling to Trillion Parameter Models with Simple and Effi- cient Sparsity.J. Mach. Learn. Res.23 (2022), 120:1–120:39.https: //jmlr.org/papers/v23/21-0998.html 8 Conference’17, July 2017, Washington, DC, USA
2022
-
[21]
Shiwei Gao, Qing Wang, Shaoxun Zeng, Youyou Lu, and Jiwu Shu
-
[22]
InUSENIX ATC
Weaver: Efficient Multi-LLM Serving with Attention Offloading. InUSENIX ATC. USENIX Association, 587–595
-
[23]
Google. 2026. Gemini.https://gemini.google.com. Accessed: 2026-05- 08
2026
-
[24]
StepFun Inc. 2025. Step-3 is Large yet Affordable: Model-system Co- design for Cost-effective Decoding.CoRRabs/2507.19427 (2025)
arXiv 2025
-
[25]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guil- laume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Tev...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.04088 2024
-
[26]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[27]
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InSOSP. ACM, 611–626
-
[28]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. InOSDI. USENIX Association, 155–172
2024
-
[29]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. In9th International Confer- ence on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.https://o...
2021
-
[30]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, and Junchen Jiang. 2024. CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving. InSIGCOMM. ACM, 38–56
2024
-
[31]
NVIDIA. 2025. NVSHMEM: GPU Programming Interface for Scalable Communication.https://docs.nvidia.com/nvshmem. Accessed: 2026- 05-08
2025
-
[32]
NVIDIA. 2026. CUDA Virtual Memory Management (VMM).https:// docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__VA.html. Ac- cessed: 2026-05-08
2026
-
[33]
OpenAI. 2026. ChatGPT.https://chatgpt.com. Accessed: 2026-05-08
2026
-
[34]
OpenAI. 2026. Codex.https://openai.com/codex. Accessed: 2026-05-08
2026
-
[35]
OpenClaw Contributors. 2026. OpenClaw.https://openclaw.ai. Ac- cessed: 2026-05-08
2026
-
[36]
OpenRouter. 2026. OpenRouter.https://openrouter.ai. Accessed: 2026-05-08
2026
-
[37]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation - A KVCache-centric Architecture for Serving LLM Chatbot. InFAST. USENIX Association, 155–170
2025
-
[38]
Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need.CoRRabs/1911.02150 (2019)
Pith/arXiv arXiv 2019
-
[39]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025)
Pith/arXiv arXiv 2025
-
[40]
Yuxing Xiang, Xue Li, Kun Qian, Yufan Yang, Diwen Zhu, Wenyuan Yu, Ennan Zhai, Xuanzhe Liu, Xin Jin, and Jingren Zhou. 2025. Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market. In SOSP. ACM, 1030–1045
2025
-
[41]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. 2025. FlashInfer: Efficient and Cus- tomizable Attention Engine for LLM Inference Serving. InMLSys. OpenReview.net/mlsys.org
2025
-
[42]
Shan Yu, Yifan Qiao, Mingyuan Ma, Yangmin Li, Shuo Yang, Xinyuan Tong, Yang Wang, Zhiqiang Xie, Yuwei An, Shiyi Cao, Ke Bao, Deepak Vij, Xiaoning Ding, Yichen Wang, Qingda Lu, Zhong Wang, Gao Gao, Harry Xu, Junyi Shu, Jiarong Xing, and Ying Sheng. 2026. Chimera: Cost-Efficient Multi-LLM Serving via GPU Memory Ballooning. In USENIX OSDI. USENIX Association
2026
-
[43]
Gonzalez, Clark W
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. 2024. SGLang: Ef- ficient Execution of Structured Language Model Programs. InNeurIPS
2024
-
[44]
Zhipu AI and Tsinghua University. 2024. LongAlign-10k.https:// huggingface.co/datasets/zai-org/LongAlign-10k
2024
-
[45]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. 2025. MegaScale-Infer: Efficient Mixture-of-Experts Model Serving with Disaggregated Expert Parallelism. ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.