UniDrive: A Unified Vision-Language and Grounding Framework for Interpretable Risk Understanding in Autonomous Driving
Pith reviewed 2026-06-26 00:28 UTC · model grok-4.3
The pith
A dual-branch model fuses multi-frame temporal reasoning with high-resolution spatial details to produce grounded risk descriptions for driving scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
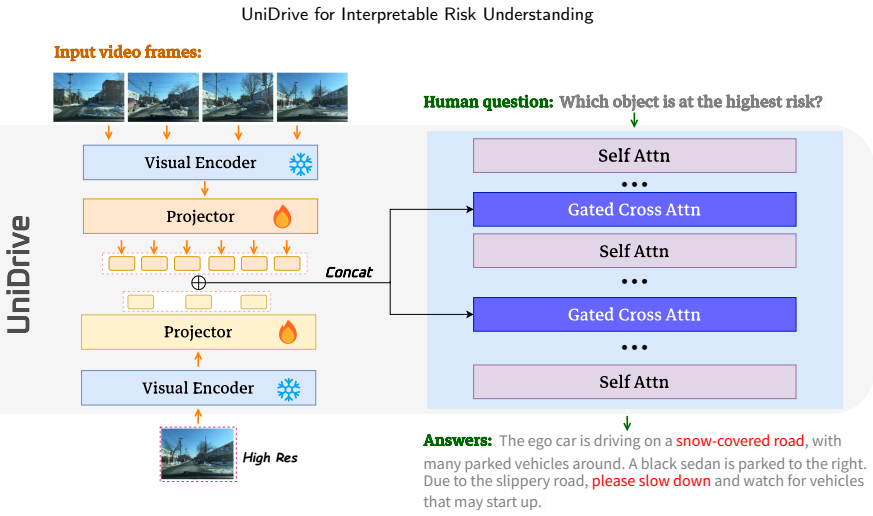
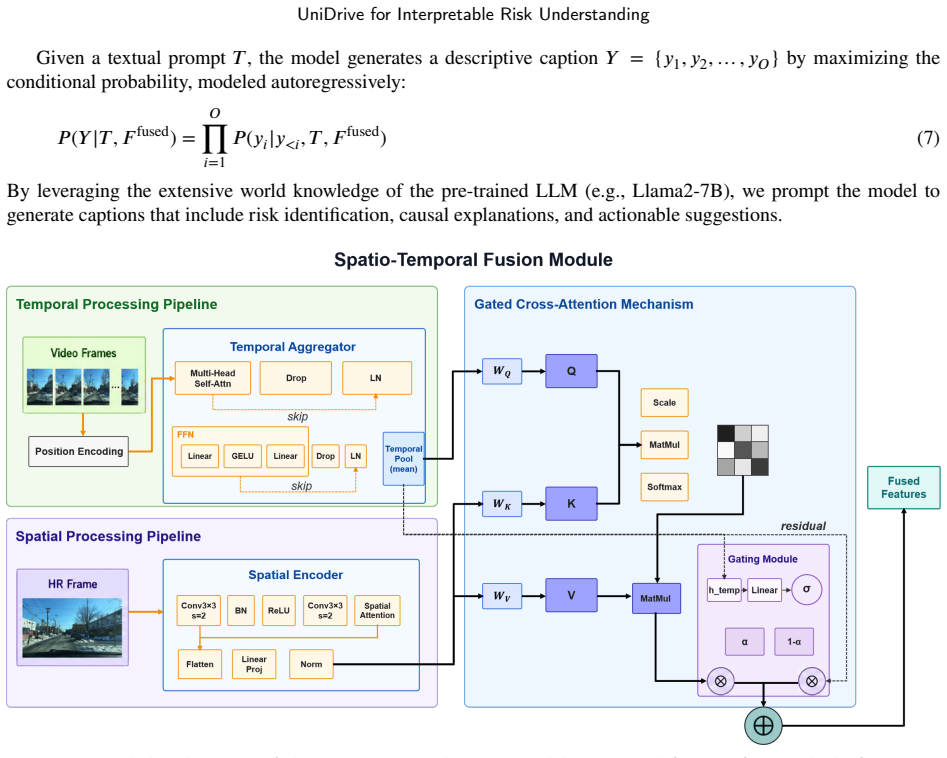
UniDrive combines a temporal reasoning branch that models scene dynamics from multi-frame visual input with a high-resolution perception branch that preserves fine-grained spatial details from the latest frame. The two branches are integrated through a gated cross-attention fusion module, enabling dynamic context to be aligned with precise spatial evidence. Based on the fused representation, UniDrive jointly generates natural-language risk descriptions and grounded bounding-box outputs for risk objects.
What carries the argument
The gated cross-attention fusion module that aligns temporal dynamics from multi-frame input with fine-grained spatial evidence from the latest high-resolution frame.
If this is right
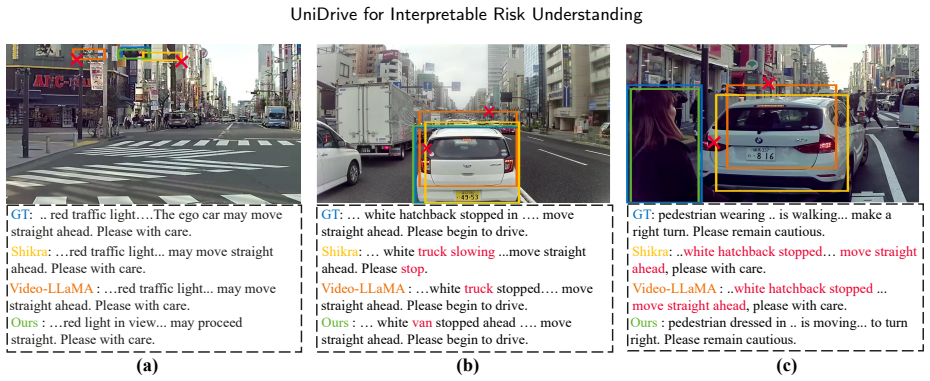
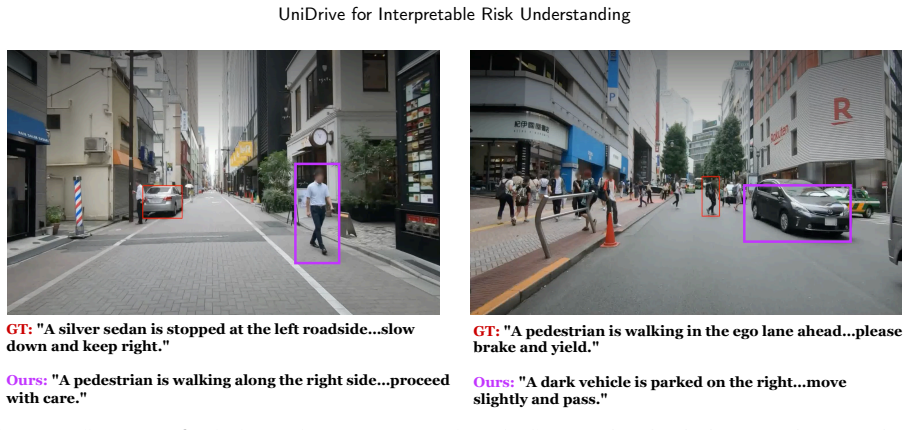
- The model produces both natural-language risk descriptions and accurate bounding boxes for hazard objects on the same fused representation.
- Performance advantages appear in small-object localization and zero-shot transfer to datasets such as NuScenes and BDD100K.
- Human raters judge the outputs as more interpretable and trustworthy than those from image-only or video-only baselines.
- The approach is presented as a stronger foundation for safety-oriented autonomous driving systems that require both temporal context and spatial precision.
Where Pith is reading between the lines
- If the fusion mechanism scales to longer video sequences, it could support risk prediction several seconds ahead rather than only describing the current frame.
- The same dual-branch pattern might transfer to other domains that need both motion understanding and fine localization, such as robotic manipulation or surveillance.
- Replacing the language head with a planning module could turn the grounded risk outputs into direct inputs for trajectory generation.
Load-bearing premise
The gated cross-attention fusion module successfully aligns temporal dynamics from multi-frame input with fine-grained spatial evidence from the latest high-resolution frame without loss of critical hazard information.
What would settle it
An ablation experiment on the DRAMA-Reasoning validation set in which the high-resolution branch or the gated fusion is removed and small-object grounding performance falls below the full UniDrive model would falsify the necessity of the dual-branch design.
Figures
read the original abstract
Recent multimodal large language models (MLLMs) have shown strong potential for autonomous driving scene understanding, yet existing methods still face a fundamental trade-off between temporal reasoning and spatial precision. Models that rely on single-frame or low-resolution inputs often miss small, distant, or partially occluded hazards, while language-centric driving models frequently provide limited grounded evidence for their explanations. To address this gap, we propose UniDrive, a unified visual-language and grounding framework for interpretable risk understanding in autonomous driving. UniDrive combines a temporal reasoning branch that models scene dynamics from multi-frame visual input with a high-resolution perception branch that preserves fine-grained spatial details from the latest frame. The two branches are integrated through a gated cross-attention fusion module, enabling dynamic context to be aligned with precise spatial evidence. Based on the fused representation, UniDrive jointly generates natural-language risk descriptions and grounded bounding-box outputs for risk objects. Experiments on the DRAMA-Reasoning benchmark show that UniDrive outperforms representative image-based and video-based baselines in both captioning and risk-object grounding. In particular, UniDrive achieves the best overall performance on the validation split and demonstrates clear advantages in small-object localization, zero-shot generalization to NuScenes and BDD100K, and human-rated interpretability and trustworthiness. These results suggest that explicitly combining temporal semantics and high-resolution perception provides a stronger foundation for interpretable and safety-oriented autonomous driving systems. The code is available at https://github.com/pixeli99/unidrive-dev.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniDrive, a unified vision-language and grounding framework for interpretable risk understanding in autonomous driving. It integrates a temporal reasoning branch modeling scene dynamics from multi-frame visual input with a high-resolution perception branch preserving fine-grained spatial details from the latest frame; these are fused via a gated cross-attention module to jointly generate natural-language risk descriptions and grounded bounding-box outputs for risk objects. Experiments on the DRAMA-Reasoning benchmark are reported to show outperformance over image-based and video-based baselines in captioning and risk-object grounding, with advantages in small-object localization, zero-shot generalization to NuScenes and BDD100K, and human-rated interpretability and trustworthiness.
Significance. If the empirical results hold, the work addresses a key limitation in current MLLMs for autonomous driving by explicitly trading off temporal semantics against spatial precision, potentially yielding more trustworthy and safety-oriented systems. The joint language-plus-grounding output and public code release are strengths that support both practical adoption and reproducibility.
major comments (1)
- [Abstract / Experiments section] Abstract / Experiments section: the central claim of outperformance on DRAMA-Reasoning (including best overall performance on validation, advantages in small-object localization, zero-shot generalization, and human-rated interpretability) is asserted without any quantitative metrics, baseline specifications, statistical tests, or ablation results. This information is load-bearing for the empirical contribution and must be supplied with concrete numbers and controls.
minor comments (2)
- [Method] Clarify the precise architecture of the gated cross-attention fusion module (e.g., how temporal features from the multi-frame branch are aligned with spatial features from the high-resolution branch) with an accompanying diagram or pseudocode.
- [Experiments] Ensure all dataset splits, evaluation metrics (e.g., for captioning and grounding), and human-study protocols are defined with explicit formulas or references in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address the single major comment below by agreeing to strengthen the presentation of empirical results.
read point-by-point responses
-
Referee: [Abstract / Experiments section] Abstract / Experiments section: the central claim of outperformance on DRAMA-Reasoning (including best overall performance on validation, advantages in small-object localization, zero-shot generalization, and human-rated interpretability) is asserted without any quantitative metrics, baseline specifications, statistical tests, or ablation results. This information is load-bearing for the empirical contribution and must be supplied with concrete numbers and controls.
Authors: We agree that the abstract would benefit from explicit quantitative support for the central claims. In the revised version we will update the abstract to report key metrics from the DRAMA-Reasoning validation split (captioning and grounding scores), baseline comparisons, small-object localization gains, zero-shot transfer results on NuScenes and BDD100K, and human evaluation ratings, along with brief references to the corresponding tables. The experiments section already contains the detailed tables with baseline specifications, ablation studies, and statistical controls; we will ensure these are cross-referenced clearly from the abstract and expanded where any requested control is not yet shown. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript presents an empirical architecture proposal (temporal branch + high-resolution branch + gated cross-attention fusion) evaluated on the DRAMA-Reasoning benchmark and zero-shot transfers. No equations, parameter-fitting steps, or derivation chain appear in the provided text; performance claims rest on direct experimental comparisons rather than any self-referential definition, fitted-input-as-prediction, or self-citation load-bearing step. The central result is therefore self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TransportationResearchInterdisciplinaryPerspectives37, 102041
Enhancing safety in automated ports: A virtual reality study of pedestrian–autonomous vehicleinteractionsundertimepressure,visualconstraints,andvaryingvehiclesize. TransportationResearchInterdisciplinaryPerspectives37, 102041. Chen,K.,Zhang,Z.,Zeng,W.,Zhang,R.,Zhu,F.,Zhao,R.,2023. Shikra:UnleashingmultimodalLLM’sreferentialdialoguemagic. arXivpreprint arX...
Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2309.05186
HiLM-D: Towards high-resolution understanding in multimodal large language models for autonomous driving. arXiv preprint arXiv:2309.05186 . Ding,X.,Han,J.,Xu,H.,Zhang,W.,Li,X.,2024. Holisticautonomousdrivingunderstandingbybird’s-eye-viewinjectedmulti-modallargemodels. arXiv preprint arXiv:2404.07165 . Fu, D., Li, X., Wen, L., Dou, M., Cai, P., Shi, B., Qiao, Y.,
arXiv 2024
-
[3]
arXiv preprint arXiv:2307.07162
Drive like a human: Rethinking autonomous driving with large language models. arXiv preprint arXiv:2307.07162 . Huang,S.,Shi,F.,Sun,C.,Zhong,J.,Ning,M.,Yang,Y.,Lu,Y.,Wang,H.,Khajepour,A.,2025. Drivesotif:AdvancingperceptionSOTIFthrough multimodal large language models. arXiv preprint arXiv:2505.07084 . Hwang,J.J.,Xu,R.,Lin,H.,Hung,W.C.,Ji,J.,Choi,K.,Huang...
arXiv 2025
-
[4]
arXiv preprint arXiv:2407.14239
KoMA: Knowledge-driven multi-agent framework for autonomous driving with large language models. arXiv preprint arXiv:2407.14239 . Li, J., Li, J., Yang, G., Yang, L., Chi, H., Yang, L.,
-
[5]
Improvedbaselineswithvisualinstructiontuning,in:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition, pp
Liu,H.,Li,C.,Li,Y.,Lee,Y.J.,2024. Improvedbaselineswithvisualinstructiontuning,in:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition, pp. 26296–26306. Lu,Q.,Wang,X.,Jiang,Y.,Zhao,G.,Ma,M.,Feng,S.,2025. Omnitester:Multimodallargelanguagemodeldrivenscenariotestingforautonomous vehicles. Automotive Innovation 8, 838–852. Ma, Y., Cui,...
2024
-
[6]
arXiv preprint arXiv:2312.04372
LaMPilot: An open benchmark dataset for autonomous driving with language model programs. arXiv preprint arXiv:2312.04372 . Malla,S.,Choi,C.,Dwivedi,I.,Choi,J.H.,Li,J.,2023. DRAMA:Jointrisklocalizationandcaptioningindriving,in:ProceedingsoftheIEEE/CVF Winter Conference on Applications of Computer Vision, pp. 1043–1052. Mao, J., Ye, J., Qian, Y., Pavone, M....
arXiv 2023
-
[7]
arXiv preprint arXiv:2311.10813
A language agent for autonomous driving. arXiv preprint arXiv:2311.10813 . Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.,
-
[8]
arXiv preprint arXiv:2306.14824
KOSMOS-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824 . Shao,H.,Hu,Y.,Wang,L.,Song,G.,Waslander,S.L.,Liu,Y.,Li,H.,2024. Lmdrive:Closed-loopend-to-enddrivingwithlargelanguagemodels, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15120–15130. Shukor, M., Dancette, C., Cord, M.,
Pith/arXiv arXiv 2024
-
[9]
Drivelm: Driving with graph visual question answering, in: Computer Vision – ECCV 2024, pp. 256–274. Tian, X., Gu, J., Li, B., Liu, Y., Hu, C., Wang, Y., Zhan, K., Jia, P., Lang, X., Zhao, H.,
2024
-
[10]
arXiv preprint arXiv:2402.12289
Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289 . Wang, J., Zhao, C., Liu, W., Ma, J., Sun, P.,
-
[11]
arXiv preprint arXiv:2312.09245
Drivemlm: Aligning multi-modal large language models with behavioral planning states for autonomous driving. arXiv preprint arXiv:2312.09245 . Xu, Z., Zhang, Y., Xie, E., Zhao, Z., Guo, Y., Wong, K.Y.K., Li, Z., Zhao, H.,
-
[12]
Ye, Y., Che, Y., Liang, H., Zhang, Y., Xu, P., 2026a
LLM4Drive: A survey of large language models for autonomous driving, in: NeurIPS 2024 Workshop on Open-World Agents. Ye, Y., Che, Y., Liang, H., Zhang, Y., Xu, P., 2026a. Wait or cross? Understanding the influence of behavioral tendency, trust, and risk perception on pedestrian gap-acceptance of automated truck platoons. Transportation Research Part F: Tr...
arXiv 2024
-
[13]
arXiv preprint arXiv:2306.02858
Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858 . Zhang, Y., Ma, Z., Gao, X., Shakiah, S., Gao, Q., Chai, J.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.