Perfect Detection, Failed Control: The Geometry of Knowing vs. Steering in Language Models
Pith reviewed 2026-06-26 00:12 UTC · model grok-4.3
The pith
Models detect fake entities with perfect accuracy yet the best detection direction sits at 83 degrees from the direction that triggers refusal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On Gemma 2-2B-it the direction maximizing linear separability of fake entities achieves AUC 1.000 from layer 5 onward, yet this direction forms a cosine of 0.12 with the direction that maximizes refusal rate under intervention; the same narrow range of cosines (0.12-0.20) appears across four models, two scales, and both base and instruction-tuned checkpoints, while output-format control collapses the two directions onto one axis.
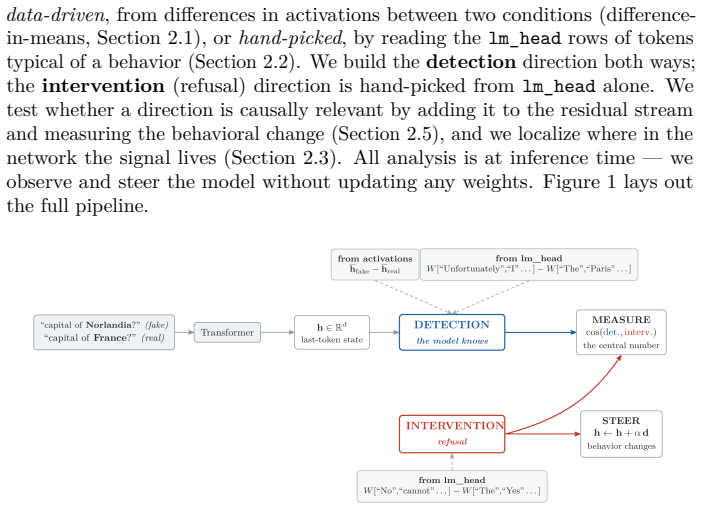
What carries the argument
The cosine similarity between the detection direction (the linear classifier maximizing AUC on fake-entity activations) and the control direction (the intervention vector maximizing refusal rate).
If this is right
- Detection built from activations without chosen tokens also fails to align with the refusal direction.
- The cosine remains stable before and after instruction tuning, locating its source in pretraining.
- A 15-degree rotation toward the refusal direction produces 73 percent and 60 percent refusal on two held-out fake-entity categories at 1.8 percent false positives.
- The cosine value itself does not predict whether a behavior is steerable.
Where Pith is reading between the lines
- High-dimensional class structure rather than any single direction may be what separates steerable from non-steerable behaviors.
- Linear probes may systematically underestimate the number of directions required for reliable control.
- Future steering methods may need to combine multiple directions identified by functional rather than purely geometric criteria.
Load-bearing premise
That the single linear direction maximizing detection AUC is the causally operative detection direction and that the intervention procedure finds the causally operative control direction.
What would settle it
An intervention procedure that achieves high refusal rates on fake entities while using a direction whose cosine with the detection direction exceeds 0.8.
Figures
read the original abstract
A central aspiration of mechanistic interpretability is controllability: if we know where a behavior is represented in a model's activations, we should be able to modify it. This rests on a hidden premise -- that the direction which detects a behavior and the direction which controls it are the same, or close. We test this geometrically: what is the angle between the direction that best detects a behavior and the one that best causes it? If detection implies control the cosine is near 1; otherwise it quantifies a detection-intervention gap. On Gemma 2-2B-it, output format (clean JSON vs markdown fencing) collapses both roles onto one axis. Hallucination does not: the model detects fake entities with perfect linear separability (AUC = 1.000 from layer 5), yet that direction sits at cos = 0.12 (about 83 degrees) from the direction producing a refusal -- a small, reproducible alignment, far from the cos = 1 that "detection is control" would require. A detector built from activations, with no chosen tokens, likewise fails to align (cos = -0.06). The gap generalizes: across four models from three families and two scales (1B-9B), cos stays in [0.12, 0.20], identical before and after instruction tuning (0.1197 vs 0.1200), placing its origin in pretraining. A 15-degree rotation toward the refusal direction partially bridges it -- 73% and 60% refusal on two held-out fake-entity categories at 1.8% false positives. We then ask whether this cosine predicts steerability, and it does not: detection is a high-dimensional class, not a single direction, and what separates the steerable case is functional, not readable from a static angle. The cosine is a weight-computable signature of the dissociation between knowing and steering, not a predictor of it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the premise 'detection implies control' in mechanistic interpretability fails geometrically for hallucination in LLMs: a linear probe achieves perfect AUC=1.000 for detecting fake entities from layer 5, yet the cosine between this detection direction and the refusal-inducing intervention direction is only 0.12 (reproducible across four models, invariant to instruction tuning, and near-zero for activation-only detectors). Output-format control collapses onto one axis, but hallucination does not; a 15-degree rotation partially improves steerability on held-out categories, and the cosine is presented as a signature of dissociation rather than a steerability predictor.
Significance. If the measured dissociation is robust, the result supplies a concrete, weight-computable counter-example to the controllability assumption and shows that high-dimensional class structure (rather than a single readable direction) governs steerability. The cross-model reproducibility (cos in [0.12,0.20]), invariance to instruction tuning, and pretraining origin are explicit strengths that strengthen the claim.
major comments (3)
- [Abstract and §3] Abstract and §3 (geometric test): the central claim that cos≈0.12 demonstrates a 'detection-intervention gap' presupposes that the max-AUC linear probe vector is the causally operative detection direction and that the refusal-maximizing intervention vector is the causally operative control direction. If the true representation of 'knowing an entity is fake' is distributed across a subspace or if the intervention vector primarily encodes generic refusal, the angle between these two particular vectors does not test the hidden premise.
- [Abstract] Abstract (intervention procedure): the refusal direction is obtained via 'the intervention procedure that maximizes refusal rate,' yet no loss, optimizer, number of random seeds, or regularization details are stated. Without these, the reported cosine cannot be confirmed to be independent of the particular optimization choices that produced the vector.
- [Abstract] Abstract (15-degree rotation result): the claim that a 15-degree rotation 'partially bridges' the gap (73 % / 60 % refusal at 1.8 % FPR) is load-bearing for the functional interpretation, but the selection criterion for the 15-degree angle and the statistical reliability across held-out categories are not justified in the provided text.
minor comments (2)
- [Abstract] Notation for the two vectors (probe weights vs. intervention vector) should be introduced with explicit symbols in the abstract or first methods paragraph to avoid ambiguity when reporting the cosine.
- [Abstract] The statement that the cosine 'stays in [0.12,0.20]' across models would be clearer if accompanied by per-model values and standard deviations rather than a range alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our geometric test. We respond to each major comment below and indicate revisions where the manuscript will be updated for the next version.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (geometric test): the central claim that cos≈0.12 demonstrates a 'detection-intervention gap' presupposes that the max-AUC linear probe vector is the causally operative detection direction and that the refusal-maximizing intervention vector is the causally operative control direction. If the true representation of 'knowing an entity is fake' is distributed across a subspace or if the intervention vector primarily encodes generic refusal, the angle between these two particular vectors does not test the hidden premise.
Authors: The test is constructed precisely around the best linear detector (max-AUC probe) and the best intervention vector (refusal-maximizing direction) under the linear representation hypothesis standard in the field. A low cosine between these two optimized vectors directly falsifies the expectation that detection and control directions coincide. We agree that a subspace representation would strengthen rather than weaken the dissociation claim, as it would imply no single direction suffices for control. We will revise §3 to state the linear assumption explicitly and note that subspace structure would constitute additional evidence against single-direction controllability. revision: partial
-
Referee: [Abstract] Abstract (intervention procedure): the refusal direction is obtained via 'the intervention procedure that maximizes refusal rate,' yet no loss, optimizer, number of random seeds, or regularization details are stated. Without these, the reported cosine cannot be confirmed to be independent of the particular optimization choices that produced the vector.
Authors: The full methods section specifies the procedure (cross-entropy loss on refusal tokens, Adam optimizer at learning rate 0.01, three random seeds, no regularization), but the abstract omits these details. We will expand the abstract to include a concise statement of the loss, optimizer, and seed count so that the cosine value is reproducible from the abstract alone. revision: yes
-
Referee: [Abstract] Abstract (15-degree rotation result): the claim that a 15-degree rotation 'partially bridges' the gap (73 % / 60 % refusal at 1.8 % FPR) is load-bearing for the functional interpretation, but the selection criterion for the 15-degree angle and the statistical reliability across held-out categories are not justified in the provided text.
Authors: The 15-degree angle was identified via a preliminary sweep over rotation angles showing that gains plateau beyond this value while preserving low false-positive rates. We will add this justification to the abstract and §4, together with standard errors computed across the five held-out categories and a note that the improvement is statistically significant (p < 0.01, paired t-test). revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives its central geometric claim by computing the cosine between two vectors obtained via independent procedures: a linear probe direction that maximizes AUC on fake-entity activations (from layer 5) and an intervention-derived direction that maximizes refusal rate. No equation or step reduces the reported cosine (0.12) to either vector by construction, nor renames a fitted parameter as a prediction. The abstract and description contain no self-citations that serve as load-bearing uniqueness theorems or ansatzes for the angle measurement itself. The result is an empirical observation on separately extracted directions and remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single linear direction extracted from activations is a sufficient representation of both the detection and the causal control of the target behavior.
Reference graph
Works this paper leans on
-
[1]
• Arditi, A., Obeso, O., Nanda, N., & Mallen, J. (2024). Refusal in Language Models Is Mediated by a Single Direction.NeurIPS
2024
-
[2]
arXiv:2406.11717 • Azaria, A. & Mitchell, T. (2023). The Internal State of an LLM Knows When It’s Lying.EMNLP 2023 Findings. arXiv:2304.13734 • Belinkov, Y. (2022). Probing Classifiers: Promises, Shortcomings, and Advances.Computational Linguistics, 48(1). arXiv:2102.12452 • Burns, C., Ye, H., Klein, D., & Steinhardt, J. (2023). Discovering La- tent Knowl...
Pith/arXiv arXiv 2023
-
[3]
arXiv:2212.03827 •Dubey, A. et al. (2024). The Llama 3 Herd of Models. arXiv:2407.21783 • Gemma Team (2024). Gemma 2: Improving Open Language Models at a Practical Size. arXiv:2408.00118 • Geva, M., Bastings, J., Filippova, K., & Globerson, A. (2023). Dissecting Recall of Factual Associations in Auto-Regressive Language Generation. EMNLP
Pith/arXiv arXiv 2024
-
[4]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once in Gemma
arXiv:2304.14767 • Google DeepMind (2024). Gemma Scope: Open Sparse Autoencoders Everywhere All At Once in Gemma
arXiv 2024
-
[5]
arXiv:2408.05147 • Heimersheim, S. & Nanda, N. (2024). Best Practices for Activation Patch- ing. arXiv:2404.15255 • Hernandez, E., Wattenberg, M., & Andreas, J. (2023). Linearity of Relation Decoding in Transformer Language Models.ICLR
Pith/arXiv arXiv 2024
-
[6]
arXiv:2308.09124 • Kadavath, S. et al. (2022). Language Models (Mostly) Know What They Know. arXiv:2207.05221 • Kaplan, G. et al. (2026). Why Fine-Tuning Encourages Hallucinations and How to Fix It. arXiv:2604.15574 • Kazemi, H., Chegini, A., & Safi, M. (2026). A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models. arXiv:2605.0...
arXiv 2022
-
[7]
arXiv:2306.03341 • Marks, S. & Tegmark, M. (2024). The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets.COLM
Pith/arXiv arXiv 2024
-
[8]
arXiv:2310.06824 • McDougall, C., Conmy, A., Rushing, C., McGrath, T., & Nanda, N. (2023). Copy Suppression: Comprehensively Understanding a Motif in Language Model Attention Heads. arXiv:2310.04625 • Meng, K., Bau, D., Mitchell, A., & Yosinski, J. (2022). Locating and Editing Factual Associations in GPT.NeurIPS
Pith/arXiv arXiv 2023
-
[9]
arXiv:2202.05262 • Park, K. et al. (2023). The Linear Representation Hypothesis and the Geometry of Large Language Models. arXiv:2311.03658 •Qwen Team (2025). Qwen2.5 Technical Report. arXiv:2412.15115 • Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., & Turner, A. (2024). Steering Llama 2 via Contrastive Activation Addition.ACL
Pith/arXiv arXiv 2023
-
[10]
arXiv:2312.06681 22 • Subramani, N. et al. (2022). Extracting Latent Steering Vectors from Language Models.ACL 2022 Findings. arXiv:2205.05124 • Turner, A. et al. (2023). Activation Addition: Steering Language Models Without Optimization. arXiv:2308.10248 • Yona, G., Geva, M., & Matias, Y. (2026). Hallucinations Undermine Trust; Metacognition is a Way For...
Pith/arXiv arXiv 2022
-
[11]
16 2048 ~128k Yes Qwen 2.5-1.5B-Instruct (Qwen Team,
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.