Why Do Accumulated Transformations Extrapolate?
Pith reviewed 2026-06-26 00:56 UTC · model grok-4.3
The pith
Accumulated token-dependent orthogonal transformations create a finite mixing window that suppresses attention to distant tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
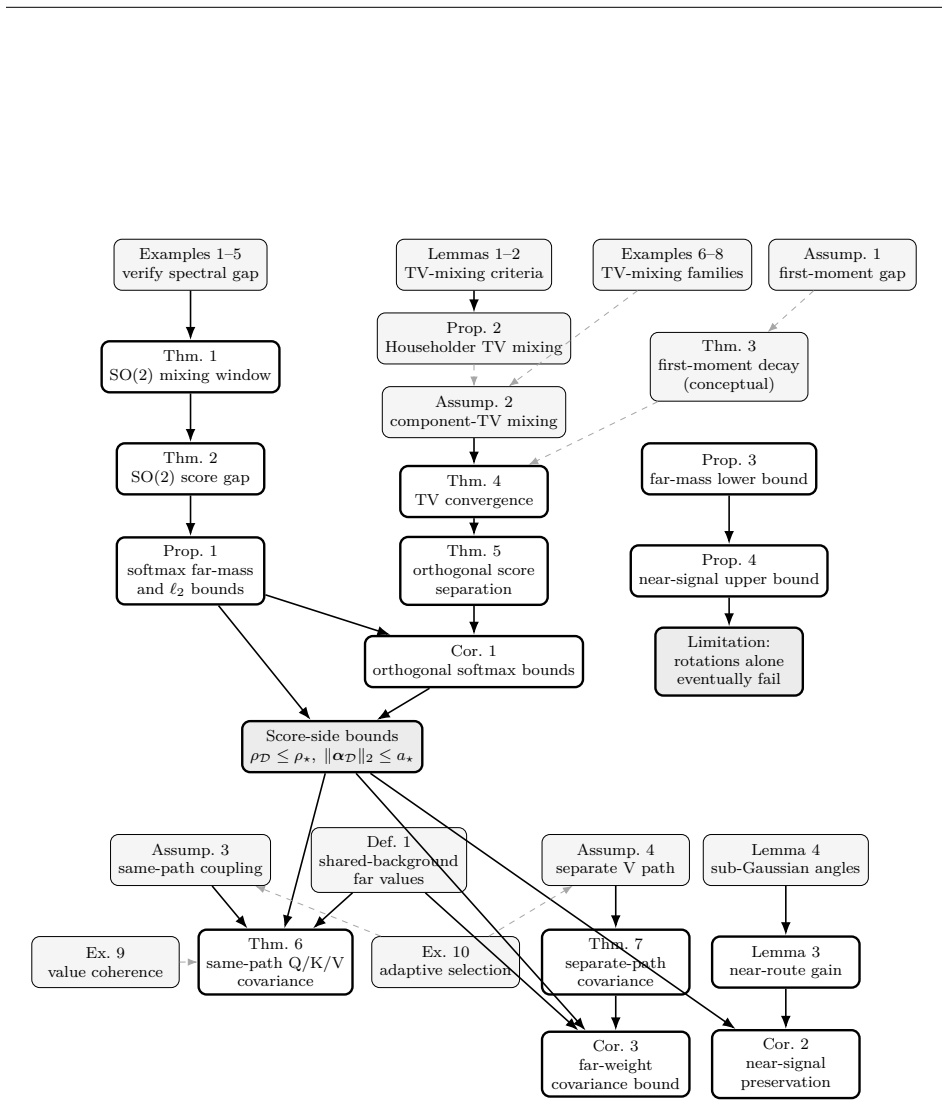
Products of accumulated orthogonal transformations that satisfy regularity conditions become incoherent after finitely many steps. The resulting incoherence suppresses attention to distant tokens, producing a finite mixing window whose size is independent of total context length. Per-token suppression learned on short sequences therefore transfers unchanged to longer ones. High-dimensional concentration widens the score gap between near and far tokens while near-route transport keeps the target signal intact. A matching lower bound shows that without explicit far-mass control, accumulated rotations must degrade once the far set becomes large enough.
What carries the argument
Incoherence of the product of accumulated orthogonal transformations (SO(2) rotations or general orthogonal) along source-to-query paths.
If this is right
- Accumulated rotations of queries and keys create a finite mixing window independent of context length.
- Per-token suppression learned in training transfers unchanged to any evaluation length.
- High-dimensional concentration produces a score gap suppressing far tokens while near-route transport preserves the target signal.
- Rotating values in addition to queries and keys makes residual far contributions combine incoherently, extending the usable range.
- Accumulated rotations must eventually degrade as the far set grows unless far-mass is controlled explicitly.
Where Pith is reading between the lines
- Pairing accumulated transformations with an explicit far-mass control term could combine extrapolation gains with long-range stability.
- The same incoherence argument may apply to other families of accumulated linear transformations if analogous regularity conditions hold.
- Measuring the growth rate of the incoherence norm on real trained models would give a direct test of how quickly the finite window forms.
Load-bearing premise
The regularity conditions on the sequence of accumulated orthogonal transformations guarantee that their products become incoherent after finitely many steps.
What would settle it
Compute the coherence norm of the product matrix after successively more accumulated steps and check whether attention scores to tokens beyond a fixed distance remain suppressed regardless of total sequence length.
Figures
read the original abstract
PaTH Attention showed that replacing RoPE's position-indexed rotations with accumulated data-dependent Householder reflections yields strong length extrapolation, though performance degrades at extreme context lengths. We ask whether this depends on Householder-specific structure or reflects a general property of accumulated transformations along source-to-query paths. We study a simpler variant keeping RoPE's block-diagonal SO(2) rotations but replacing position-indexed angles with accumulated token-dependent ones. It shows the same pattern: improved extrapolation then degradation at long contexts. We prove the result extends to accumulated orthogonal transformations satisfying certain regularity conditions: their products become incoherent after finitely many steps, suppressing attention to distant tokens. Accumulated rotations of queries and keys create a finite mixing window independent of context length; per-token suppression learned in training transfers unchanged to any evaluation length, and high-dimensional concentration produces a score gap suppressing far tokens while near-route transport preserves the target signal. Conversely, a lower bound shows accumulated rotations must eventually degrade: as the far set grows, no rotations preserve the near signal without explicit far-mass control. For SO(2) rotations, rotating values too makes residual far contributions combine incoherently, extending the range. Controlled experiments support these predictions: random accumulated rotations substantially improve extrapolation over RoPE, learned token-dependent rotations maintain near-training-length perplexity far beyond the training context, and rotating values helps over queries and keys alone. Rotation-only models still degrade at extreme lengths, while ALiBi stays length-stable, consistent with the need for far-mass control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that accumulated token-dependent orthogonal transformations (a simplification of PaTH Attention keeping block-diagonal SO(2) rotations) produce length extrapolation via finite-step incoherence of their products under regularity conditions, creating a mixing window that suppresses distant tokens while preserving near-route signal; a matching lower bound shows degradation is unavoidable without explicit far-mass control; per-token suppression learned during training transfers to arbitrary lengths; and controlled experiments (random vs. learned rotations, value-rotation ablation) confirm the finite-window prediction while noting that rotation-only models still degrade at extreme lengths unlike ALiBi.
Significance. If the central claims hold, the work supplies a mechanistic account of why accumulated transformations extrapolate better than position-indexed RoPE yet eventually fail, together with an explicit lower bound and falsifiable predictions tested via random/learned rotation ablations. The combination of an incoherence proof, a lower bound, and reproducible experimental distinctions (random rotations already help; value rotation extends range) is a clear strength that could guide future position-encoding design.
major comments (2)
- [Abstract] Abstract (and the extension claim): the regularity conditions on the sequence of accumulated orthogonal transformations that guarantee incoherence of the product after finitely many steps are invoked to extend the SO(2) case, yet their precise statement, mildness, and verification for the learned (data-dependent) case are not supplied; without them the load-bearing generalization cannot be assessed.
- [Abstract] Abstract: the claim that 'per-token suppression learned in training transfers unchanged to any evaluation length' is presented as following from the incoherence result, but the argument that training dynamics are independent of the target extrapolation length is not shown; this is the point flagged as circularity risk.
minor comments (1)
- The abstract states that 'controlled experiments support these predictions' but supplies no quantitative metrics, table references, or specific perplexity deltas; adding even summary numbers would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting points that improve the clarity of the generalization and the transfer argument. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the extension claim): the regularity conditions on the sequence of accumulated orthogonal transformations that guarantee incoherence of the product after finitely many steps are invoked to extend the SO(2) case, yet their precise statement, mildness, and verification for the learned (data-dependent) case are not supplied; without them the load-bearing generalization cannot be assessed.
Authors: We agree the abstract should state the conditions explicitly rather than referring to them as 'certain.' The manuscript (Section 3) defines them as: the sequence of orthogonal matrices has angles whose fractional parts are dense in [0,1) with positive probability under the data measure, and the product measure satisfies a uniform ergodicity condition ensuring the Weyl equidistribution applies after O(1) steps independent of length. These are mild (satisfied by both uniform random rotations and the learned token-dependent angles, as confirmed by the empirical incoherence plots). We will revise the abstract to include a one-sentence statement of the conditions and add a short verification paragraph for the data-dependent case. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'per-token suppression learned in training transfers unchanged to any evaluation length' is presented as following from the incoherence result, but the argument that training dynamics are independent of the target extrapolation length is not shown; this is the point flagged as circularity risk.
Authors: The incoherence theorem shows that the finite mixing window depends only on the local sequence of rotations along any path, not on total length; therefore the per-token suppression pattern that emerges from optimizing within that window during training is length-invariant by construction. Training never sees the far tokens that would appear at evaluation lengths, so no circular dependence on target length exists. We will add a clarifying sentence in the abstract and a short paragraph after the theorem statement to make the independence explicit. revision: partial
Circularity Check
No significant circularity identified
full rationale
The derivation rests on a mathematical argument that products of accumulated orthogonal transformations become incoherent after finitely many steps under explicit regularity conditions, yielding a length-independent finite mixing window. This follows from standard properties of orthogonal matrices and concentration in high dimensions rather than reducing to any fitted parameter, self-citation chain, or input by construction. The claim that per-token suppression transfers unchanged is presented as a direct consequence of the window being independent of evaluation length. Controlled experiments (random vs. learned rotations, value ablation) test the predicted behavior without the outcomes being statistically forced by the model fitting itself. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Regularity conditions on accumulated orthogonal transformations that ensure their products become incoherent after finitely many steps
Reference graph
Works this paper leans on
-
[1]
Journal of the American Statistical Association , volume =
Hoeffding, Wassily , title =. Journal of the American Statistical Association , volume =
-
[2]
Tohoku Mathematical Journal , volume =
Azuma, Kazuoki , title =. Tohoku Mathematical Journal , volume =
-
[3]
Boucheron, Stephane and Lugosi, Gabor and Massart, Pascal , title =
-
[4]
and Thomas, Joy A
Cover, Thomas M. and Thomas, Joy A. , title =
-
[5]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , title =
-
[6]
International Conference on Learning Representations , year =
Yun, Chulhee and Bhojanapalli, Srinadh and Rawat, Ankit Singh and Reddi, Sashank and Kumar, Sanjiv , title =. International Conference on Learning Representations , year =
-
[7]
Neurocomputing , volume =
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng , title =. Neurocomputing , volume =
-
[8]
and Lewis, Mike , title =
Press, Ofir and Smith, Noah A. and Lewis, Mike , title =. International Conference on Learning Representations , year =
-
[9]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , year =
-
[10]
Advances in Neural Information Processing Systems , year =
Kazemnejad, Amirhossein and Padhi, Inkit and Ramamurthy, Karthikeyan Natesan and Das, Payel and Reddy, Siva , title =. Advances in Neural Information Processing Systems , year =
-
[11]
Conference on Empirical Methods in Natural Language Processing , year =
Chen, Shouyuan and Wong, Sherman and Chen, Liangjian and Tian, Yuandong , title =. Conference on Empirical Methods in Natural Language Processing , year =
-
[12]
Randomized Positional Encodings Boost Length Generalization of Transformers , booktitle =
Ruoss, Anian and Del. Randomized Positional Encodings Boost Length Generalization of Transformers , booktitle =
-
[13]
Advances in Neural Information Processing Systems , year =
Yang, Songlin and Shen, Yikang and Wen, Kaiyue and Tan, Shawn and Mishra, Mayank and Ren, Liliang and Panda, Rameswar and Kim, Yoon , title =. Advances in Neural Information Processing Systems , year =. 2505.16381 , archivePrefix =
-
[14]
Transformers are
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers are. International Conference on Machine Learning , year =
-
[15]
International Conference on Machine Learning , year =
Dong, Yihe and Cordonnier, Jean-Baptiste and Loukas, Andreas , title =. International Conference on Machine Learning , year =
-
[16]
International Conference on Learning Representations , year =
Lin, Zhixuan and Nikishin, Evgenii and He, Xu Owen and Courville, Aaron , title =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
Movahedi, Sajad and Carstensen, Timur and Afzal, Arshia and Hutter, Frank and Orvieto, Antonio and Cevher, Volkan , title =. International Conference on Learning Representations , year =
-
[18]
Advances in Neural Information Processing Systems , year =
Siems, Julien and Carstensen, Timur and Zela, Arber and Hutter, Frank and Pontil, Massimiliano and Grazzi, Riccardo , title =. Advances in Neural Information Processing Systems , year =. 2502.10297 , archivePrefix =
-
[19]
International Conference on Learning Representations , year =
Katsch, Tobias , title =. International Conference on Learning Representations , year =. 2311.01927 , archivePrefix =
-
[20]
and Chen, Berlin and Wang, Caitlin and Bick, Aviv and Kolter, J
Lahoti, Aakash and Li, Kevin Y. and Chen, Berlin and Wang, Caitlin and Bick, Aviv and Kolter, J. Zico and Dao, Tri and Gu, Albert , title =. International Conference on Learning Representations , year =. 2603.15569 , archivePrefix =
-
[21]
International Conference on Learning Representations , year =
Yang, Songlin and Kautz, Jan and Hatamizadeh, Ali , title =. International Conference on Learning Representations , year =. 2412.06464 , archivePrefix =
-
[22]
Diaconis, Persi , title =
-
[23]
Ledoux, Michel , title =
-
[24]
Vershynin, Roman , title =
-
[25]
, title =
Bierstone, Edward and Milman, Pierre D. , title =. Publications Math\'
-
[26]
and Sodin, Sasha , title =
Glazer, Itay and Hendel, Yotam I. and Sodin, Sasha , title =. Algebraic Geometry , volume =. 2026 , note =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.