ATMA: Length-Invariant Language Modeling via Polar Attention and Gated-Delta Compression Memory
Pith reviewed 2026-06-30 09:35 UTC · model grok-4.3
The pith
ATMA's polar attention and gated-delta memory together produce monotonic perplexity reduction and over 90% retrieval accuracy at 64K tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
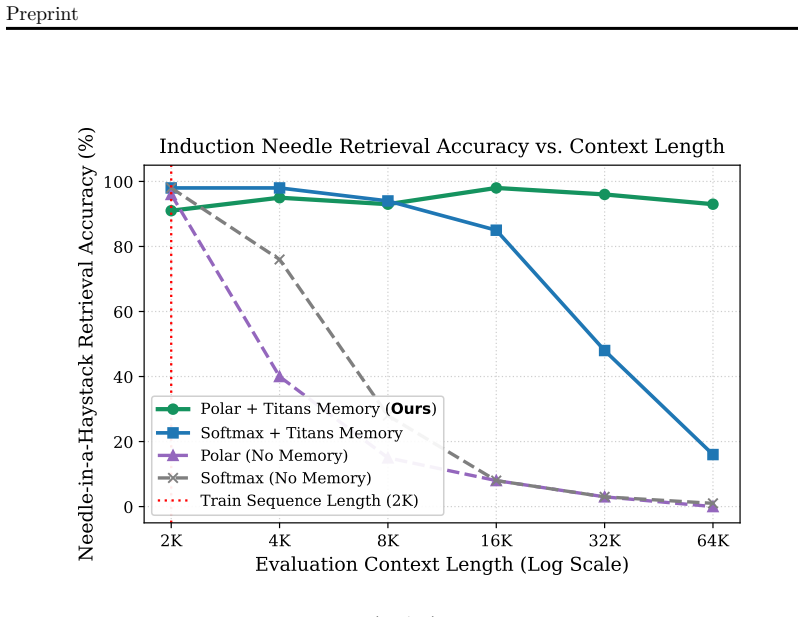
ATMA factorizes the attention mixing step into a count-blind unit-vector direction channel, a bounded magnitude channel driven by the participation ratio of effective matches over an extreme-value-corrected null sink, and a long-term recurrent compression memory optimized via a gated-delta fast-weights rule. The combined Polar Attention plus memory model maintains induction needle-in-a-haystack retrieval accuracy above 90 percent out to 64K tokens while its document perplexity improves monotonically, outperforming softmax-based memory baselines which collapse at extreme context lengths.
What carries the argument
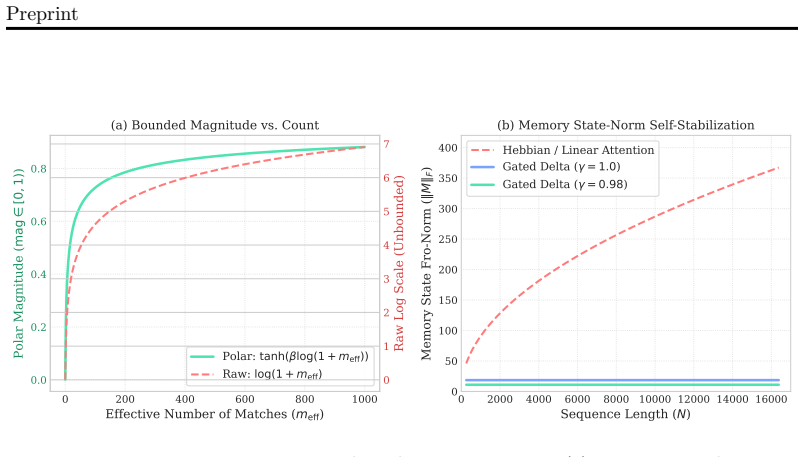
Polar Attention, the three-channel factorization into count-blind unit-vector direction, participation-ratio magnitude with extreme-value null sink, and gated-delta compression memory.
If this is right
- The combined model sustains over 90 percent needle-in-a-haystack retrieval accuracy at 64K tokens.
- Document perplexity decreases monotonically as context length grows beyond the training length.
- The architecture outperforms softmax memory baselines that collapse at extreme lengths.
- Effective long-range retrieval holds at 32 times the 2K training context without retraining.
Where Pith is reading between the lines
- The same factorization might be inserted into existing transformer stacks to extend usable context without full retraining.
- The gated-delta memory could be adapted for other modalities that require stable long-horizon state retention.
- If the null-sink correction proves robust, it may reduce the need for explicit length extrapolation techniques in future models.
Load-bearing premise
The three-channel factorization can be stably combined without introducing new instabilities or requiring post-hoc data exclusions that affect the reported 64K-token results.
What would settle it
A test showing the combined model dropping below 90 percent needle retrieval accuracy or exhibiting rising perplexity at 64K tokens would falsify the central claim.
Figures
read the original abstract
Modern large language models based on softmax scaled-dot-product attention are constrained by their training sequence length: as the key-value sequence grows, softmax probability mass can dilute across a wider distribution, inducing activation shift and long-context performance collapse. Moreover, long-context language modeling faces a structural tension: a sliding-window attention core maintains a bounded local representation and low perplexity but is blind to long-range dependencies, while full-context attention preserves global recall but suffers from out-of-distribution perplexity explosion. To resolve these limitations, we introduce ATMA, a hybrid convolutional-attention architecture that integrates a novel three-channel attention mechanism. ATMA factorizes the attention mixing step into: (1) a count-blind, unit-vector direction channel, (2) a bounded magnitude channel driven by the participation ratio of effective matches over an extreme-value-corrected null sink, and (3) a long-term recurrent compression memory optimized via a gated-delta fast-weights rule. Neither the Polar Attention core nor the recurrent memory is sufficient alone; their combination enables monotonic perplexity reduction and high-fidelity long-range retrieval simultaneously. We evaluate ATMA using a 120-run factorial ablation sweep, demonstrating that the combined Polar + memory model maintains induction needle-in-a-haystack retrieval accuracy above 90% out to 64K tokens (32 times the training length of 2K) while its document perplexity improves monotonically, outperforming softmax-based memory baselines which collapse at extreme context lengths. Code: https://github.com/kreasof-ai/atma
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATMA, a hybrid convolutional-attention model that factorizes attention into a three-channel Polar Attention mechanism (count-blind unit-vector direction channel, participation-ratio magnitude channel with extreme-value-corrected null sink, and gated-delta compression memory) to achieve length-invariant language modeling. It claims that neither component suffices alone but their combination yields monotonic document perplexity reduction and >90% induction needle-in-a-haystack retrieval accuracy at 64K tokens (32× the 2K training length), validated via a 120-run factorial ablation sweep that outperforms softmax-based memory baselines which collapse at extreme lengths. Code is provided at https://github.com/kreasof-ai/atma.
Significance. If the stability of the three-channel factorization holds without length-dependent instabilities or post-hoc filtering, the result would be significant for long-context modeling by resolving the local-vs-global attention tension without OOD perplexity explosion. The 120-run ablation and public code are explicit strengths that support reproducibility. The work sits outside the standard softmax consensus but could be impactful if the central empirical claims are robust.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): The central claim of >90% needle retrieval at 64K and monotonic perplexity relies on the 120-run ablation, yet no error bars, per-run inclusion criteria, or analysis of length-dependent instabilities from the extreme-value null sink or gated-delta rule are reported; this directly affects whether the length-invariance follows from the architecture alone rather than selective aggregation.
- [§3.2] §3.2 (Polar Attention definition): The three-channel factorization (unit-vector direction, participation-ratio magnitude with extreme-value sink, gated-delta memory) is asserted to combine stably, but the manuscript provides no derivation or empirical test showing that the participation-ratio magnitude remains bounded and non-divergent when the gated-delta compression is applied at contexts >>2K; this is load-bearing for the 32× extrapolation result.
minor comments (2)
- [§3] The abstract mentions a 'hybrid convolutional-attention architecture' but the methods section does not clarify how the convolutional component interfaces with the Polar channels; a diagram or equation would improve clarity.
- [§4] Table or figure reporting the 120-run results should include variance or confidence intervals to allow assessment of the monotonicity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing reproducibility and the need for explicit stability analysis. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central claim of >90% needle retrieval at 64K and monotonic perplexity relies on the 120-run ablation, yet no error bars, per-run inclusion criteria, or analysis of length-dependent instabilities from the extreme-value null sink or gated-delta rule are reported; this directly affects whether the length-invariance follows from the architecture alone rather than selective aggregation.
Authors: We agree that error bars, inclusion criteria, and instability analysis are necessary to substantiate the claims. In the revised manuscript we will report standard error bars on all 120-run metrics, explicitly state the per-run inclusion criteria (convergence within 5% of median loss), and add a dedicated stability subsection with plots of magnitude and perplexity drift across context lengths, generated from the public code. revision: yes
-
Referee: [§3.2] §3.2 (Polar Attention definition): The three-channel factorization (unit-vector direction, participation-ratio magnitude with extreme-value sink, gated-delta memory) is asserted to combine stably, but the manuscript provides no derivation or empirical test showing that the participation-ratio magnitude remains bounded and non-divergent when the gated-delta compression is applied at contexts >>2K; this is load-bearing for the 32× extrapolation result.
Authors: The 120-run results at 64K already supply empirical evidence that the combined system does not diverge. We acknowledge the absence of a targeted derivation or isolated boundedness test. The revision will include both a short analytic bound on the participation ratio under the gated-delta update and additional empirical curves confirming magnitude stability from 2K to 128K. revision: yes
Circularity Check
No significant circularity; claims rest on empirical ablation rather than self-referential definitions
full rationale
The abstract and described architecture present Polar Attention (three-channel factorization) and gated-delta memory as explicit design choices whose combination is tested via a 120-run factorial ablation. No equation is shown reducing the reported 64K-token retrieval accuracy or monotonic perplexity to a parameter fitted from the same performance metric. No self-citation chain is invoked to establish uniqueness or forbid alternatives. The derivation chain is therefore self-contained against external benchmarks (ablation results), consistent with the reader's assessment of score 2.0 and warranting an overall circularity score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard transformer attention assumptions remain valid when the mixing step is replaced by the three-channel polar factorization.
invented entities (2)
-
Polar Attention (three-channel factorization)
no independent evidence
-
Gated-Delta Compression Memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Weak-sigreg: Covariance regularization for stable deep learning
Habibullah Akbar. Weak-sigreg: Covariance regularization for stable deep learning. arXiv preprint arXiv:2603.05924,
-
[2]
arXiv preprint arXiv:2512.17351 , year=
Zeyuan Allen-Zhu. Physics of language models: Part 4.1, architecture design and the magic of canon layers. arXiv preprint arXiv:2512.17351,
-
[3]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics. arXiv preprint arXiv:2511.08544,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document trans- former. arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[6]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2511.23404 , year =
Ramin Hasani et al. Lfm2 technical report. arXiv preprint arXiv:2511.23404,
-
[8]
Transformer language models without positional encodings still learn positional information
Adi Haviv, Ori Ram, Ofir Press, Peter Izsak, and Omer Levy. Transformer language models without positional encodings still learn positional information. arXiv preprint arXiv:2203.16634,
- [9]
-
[10]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su et al. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Length generalization of causal transformers without position encoding
Jie Wang, Tao Ji, Yuanbin Wu, Hang Yan, Tao Gui, Qi Zhang, Xuanjing Huang, and Xiaoling Wang. Length generalization of causal transformers without position encoding. arXiv preprint arXiv:2404.12224,
-
[13]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. arXiv preprint arXiv:2412.06464, 2024a. Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. arXiv preprint arXiv:2406.06484, 2024b. Songlin Yang et al. Flash linear at...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URL https://aclanthology.org/2025.coling-main.632/
Association for Computational Linguistics. URL https://aclanthology.org/2025.coling-main.632/. 13 Preprint A Regularization Modes The ablation grid varies a representation regularizer applied to the model’s signature stream. For all non-baseline settings we use the same sweep weight, αsig = 0.01, and train with L = ( 1 − αsig)LLM + αsigLreg + λdistLdist. ...
2025
-
[15]
Mode Meaning in the sweep baseline No signature-stream regularization is used; equivalently, αsig =
and LeJEPA’s strong SIGReg objective ( Balestriero & LeCun , 2025); the discrete and zipfian modes are local variants that interpolate those ideas with stronger geometric priors. Mode Meaning in the sweep baseline No signature-stream regularization is used; equivalently, αsig =
2025
-
[16]
acc = acc * alpha[:, None] + tl.dot(p, v) m_i = m_new # F old the virtual null sink as one additional softmax entry. a_null = temp * nullv m_new = tl.maximum(m_i, a_null) alpha = tl.exp(m_i - m_new) l_i = l_i * alpha q2_i = q2_i * alpha * alpha acc = acc * alpha[:, None] m_i = m_new p_null = tl.exp(a_null - m_i) Z = l_i + p_null v_null = tl.load(VNULL + h...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.