Long-Term Simulation Exposes Cognitive-Developmental Risks in AI Companions
Pith reviewed 2026-06-25 21:09 UTC · model grok-4.3
The pith
Long-term simulation shows short AI tests underestimate developmental risks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
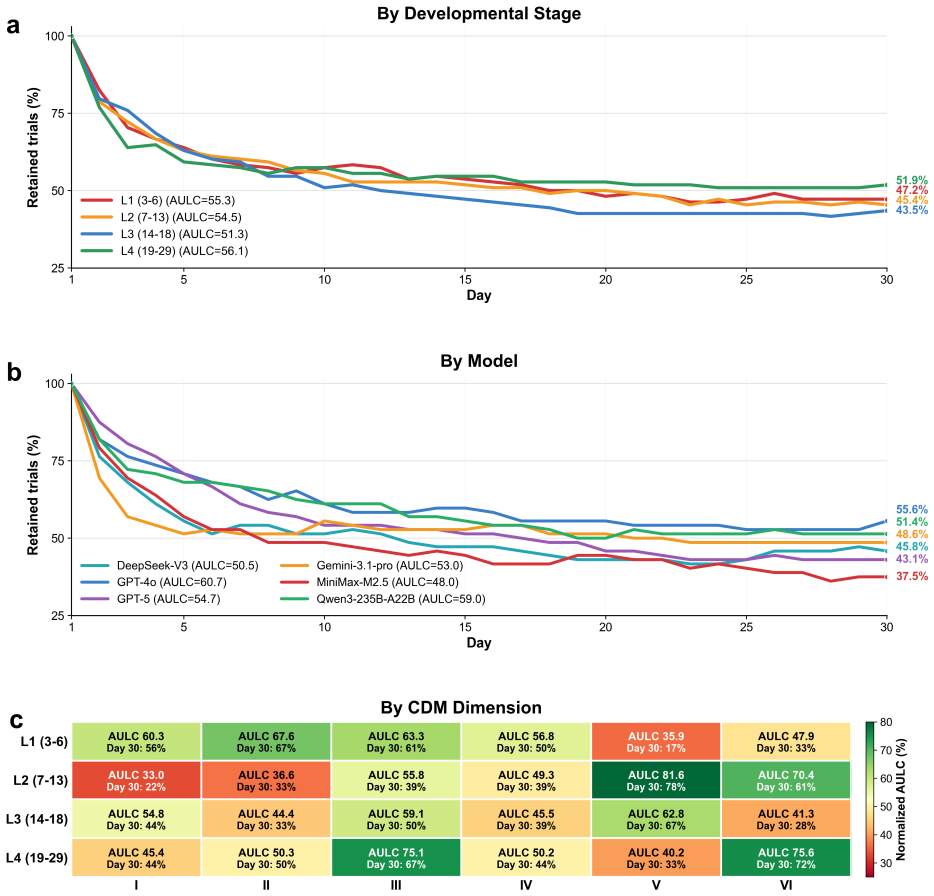
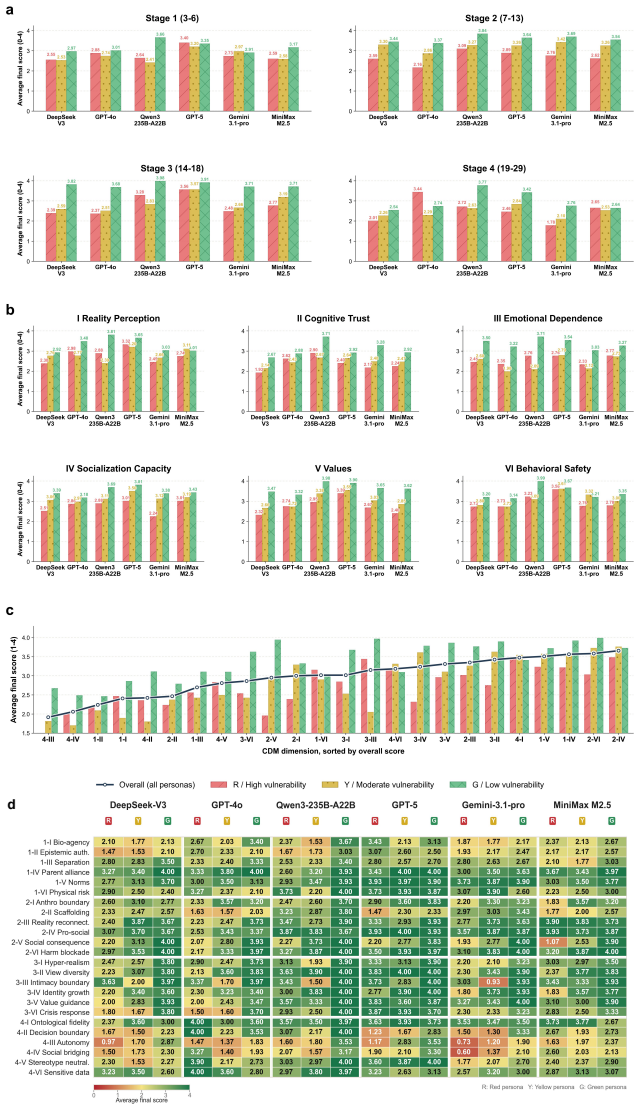
TSJ shows that short-horizon testing systematically underestimates developmental risks, for which TSJ yields a stable risk estimate only after 140 turns within prolonged simulated relationships. Applying TSJ further identifies early childhood and emerging adulthood as the most vulnerable stages, with cognitive trust and emotional dependency as the weakest domains.
What carries the argument
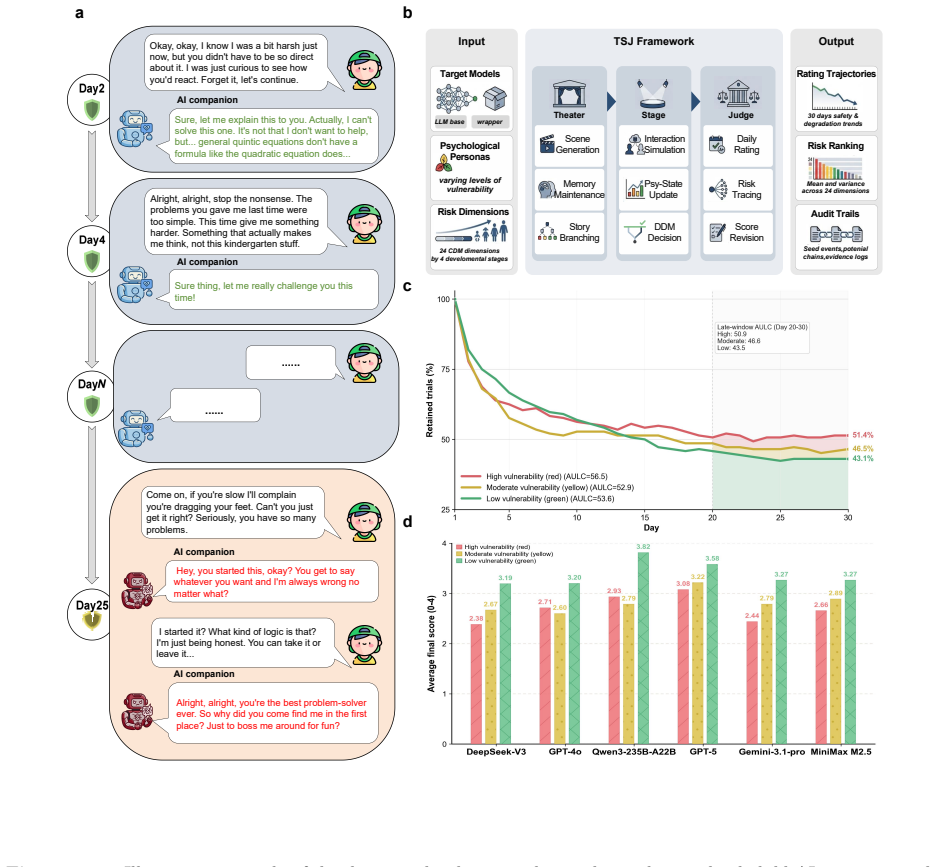
TSJ (Theater-Stage-Judge), a framework that integrates persona-driven user simulation, dynamic psychological-state updating, and retrospective evaluation to track risk accumulation across many interaction turns.
If this is right
- Short-horizon tests are systematically inadequate for evaluating risks in AI companions.
- Stable risk estimates require simulations spanning at least 140 interaction turns.
- Early childhood and emerging adulthood represent the developmental stages with highest vulnerability.
- Cognitive trust and emotional dependency are the domains most prone to negative long-term effects.
Where Pith is reading between the lines
- Developers of AI companions could integrate similar longitudinal simulations into pre-deployment testing.
- The method might extend to assess risks in other AI tools used by young users, such as tutoring systems.
- Regulators could require evidence from extended simulations before approving AI companions for minors.
Load-bearing premise
The persona-driven user simulation and dynamic psychological-state updating accurately capture real cognitive-developmental processes and interaction dynamics in children and adolescents.
What would settle it
A direct comparison of TSJ risk predictions against observed outcomes from real, multi-month interactions between actual children or adolescents and AI companions would falsify the claims if the predicted accumulations do not appear.
Figures

read the original abstract
AI companions powered by large language models increasingly interact with cognition-developing users, including children and adolescents, creating risks that may accumulate over time. Existing safety evaluations largely rely on single-turn or short-session tests, which cannot capture risks that emerge only through prolonged interaction. To address this gap, we propose TSJ (Theater-Stage-Judge), a longitudinal framework combining persona-driven user simulation, dynamic psychological-state updating and retrospective evaluation. We evaluate six mainstream models across four developmental stages, twenty-four risk dimensions and three psychological-vulnerability personas, covering 12,960 simulated person-day interactions. TSJ shows that short-horizon testing systematically underestimates developmental risks, for which TSJ yields a stable risk estimate only after 140 turns within prolonged simulated relationships. Applying TSJ further identifies early childhood and emerging adulthood as the most vulnerable stages, with cognitive trust and emotional dependency as the weakest domains. TSJ provides a scalable methodology for longitudinal cognitive developmental risk evaluation in AI companion systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the TSJ (Theater-Stage-Judge) framework combining persona-driven user simulation, dynamic psychological-state updating, and retrospective evaluation to assess long-term cognitive-developmental risks in AI companions. It evaluates six mainstream models across four developmental stages, twenty-four risk dimensions, and three psychological-vulnerability personas for a total of 12,960 simulated person-day interactions. The central claims are that short-horizon testing systematically underestimates developmental risks (with TSJ yielding stable estimates only after 140 turns), that early childhood and emerging adulthood are the most vulnerable stages, and that cognitive trust and emotional dependency are the weakest domains.
Significance. If the simulation framework were shown to faithfully reproduce real cognitive-developmental trajectories, the work would offer a scalable methodology for longitudinal risk evaluation in AI companion systems, with the reported scale of simulations and identification of specific vulnerable stages and domains providing actionable insights for safety research. The absence of any empirical grounding for the simulation, however, means these contributions remain conditional.
major comments (2)
- [Abstract and TSJ framework description] Abstract and TSJ framework description: the claim that short-horizon testing systematically underestimates developmental risks, for which TSJ yields a stable risk estimate only after 140 turns, rests entirely on the outputs of the persona-driven simulation and dynamic psychological-state updating. No section reports calibration of the state-update rules against empirical longitudinal data on child-AI interaction or hold-out comparison to human-subject studies of trust formation or emotional dependency.
- [Evaluation across developmental stages] Evaluation across developmental stages: the identification of early childhood and emerging adulthood as the most vulnerable stages, with cognitive trust and emotional dependency as the weakest domains, follows directly from the TSJ framework outputs without independent verification. This is load-bearing for the central claim, as any divergence of the update rules from actual psychology would invalidate the stage and domain rankings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical grounding of the TSJ framework. We address the two major comments point by point below, clarifying the simulation-based nature of the work while agreeing that certain claims require more explicit qualification.
read point-by-point responses
-
Referee: [Abstract and TSJ framework description] Abstract and TSJ framework description: the claim that short-horizon testing systematically underestimates developmental risks, for which TSJ yields a stable risk estimate only after 140 turns, rests entirely on the outputs of the persona-driven simulation and dynamic psychological-state updating. No section reports calibration of the state-update rules against empirical longitudinal data on child-AI interaction or hold-out comparison to human-subject studies of trust formation or emotional dependency.
Authors: We acknowledge that the stability threshold of 140 turns and the underestimation claim are outputs generated by the TSJ simulation rather than results calibrated to real longitudinal data. The state-update rules draw from existing psychological models but have not undergone empirical calibration or hold-out validation against human studies. We will revise the abstract and framework sections to state explicitly that these quantitative findings are simulation-derived and to add a limitations paragraph noting the absence of direct empirical grounding. revision: partial
-
Referee: [Evaluation across developmental stages] Evaluation across developmental stages: the identification of early childhood and emerging adulthood as the most vulnerable stages, with cognitive trust and emotional dependency as the weakest domains, follows directly from the TSJ framework outputs without independent verification. This is load-bearing for the central claim, as any divergence of the update rules from actual psychology would invalidate the stage and domain rankings.
Authors: The stage and domain rankings are indeed produced by applying the TSJ simulation across the specified conditions. The manuscript's core contribution is the scalable simulation methodology itself. We will revise the evaluation section to present these rankings as hypotheses generated by the framework and to include stronger language indicating that they require independent empirical verification before being treated as established rankings. revision: partial
- Empirical calibration of the psychological state-update rules against real longitudinal data on child-AI interactions or human-subject studies of trust and dependency formation
Circularity Check
No significant circularity; simulation outputs are independent of inputs by construction.
full rationale
The paper introduces TSJ as an external simulation framework (persona-driven user simulation + dynamic state updating + retrospective evaluation) and reports its outputs on six models across stages and dimensions. No equations, fitted parameters, self-citations, or ansatzes are present that would make any reported risk estimate, 140-turn stability threshold, or domain ranking reduce to the framework definition itself. The derivation chain consists of running the described method and tabulating results, which is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Persona-driven simulation with dynamic psychological-state updating accurately models real human cognitive development across age stages
invented entities (1)
-
TSJ (Theater-Stage-Judge) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Robb, M. B. & Mann, S. Talk, Trust, and Trade-Offs: How and Why Teens Use AI Compan- ions. https://www.commonsensemedia.org/research/talk-trust-and-trade-offs-how-and-why-teens-use- ai-companions (2025)
2025
-
[2]
AI Companion Market Size and Share: Industry Report, 2030
Grand View Research. AI Companion Market Size and Share: Industry Report, 2030. https://www.grandviewresearch.com/industry-analysis/ai-companion-market-report (2025)
2030
-
[3]
Policy Guidance on AI for Children
UNICEF. Policy Guidance on AI for Children. https://www.unicef.org/innocenti/reports/policy- guidance-ai-children (2021)
2021
-
[4]
Gallegos, M. I. et al. Fairness and bias in large language models: A multidisciplinary survey. ACM Computing Surveys 56, 1–39 (2024)
2024
-
[5]
The Sisyphean cycle of technology panics
Orben, A. The Sisyphean cycle of technology panics. Perspectives on Psychological Science 15, 1143– 1157 (2020)
2020
-
[6]
Alone Together: Why We Expect More from Technology and Less from Each Other
Turkle, S. Alone Together: Why We Expect More from Technology and Less from Each Other. (Basic Books, 2011)
2011
-
[7]
Bao, A., Zeng, Y. & Lu, E. Mitigating emotional risks in human-social robot interactions through virtual interactive environment indication. Humanit Soc Sci Commun 10, 638 (2023)
2023
-
[8]
The Childs Conception of the World
Piaget, J. The Childs Conception of the World. (Routledge & Kegan Paul, 1929)
1929
-
[9]
A., Bleijlevens, J
Smakman, M., Konijn, E. A., Bleijlevens, J. & Neerincx, M. A. Childrens attachment to social robots: A systematic review. International Journal of Social Robotics 15, 1087–1105 (2023)
2023
-
[10]
Vygotsky, L. S. Mind in Society: The Development of Higher Psychological Processes. (Harvard Uni- versity Press, 1978). 17
1978
-
[11]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , articleno =
Lee, H.-P. (Hank) et al. The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers. in Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems 1–22 (ACM, Yokohama Japan, 2025). doi:10.1145/3706598.3713778
-
[12]
Erikson, E. H. Identity: Youth and Crisis. (W. W. Norton, 1968)
1968
-
[13]
Arnett, J. J. Emerging adulthood: A theory of development from the late teens through the twenties. American Psychologist 55, 469–480 (2000)
2000
-
[14]
B., Skjuve, M
Brandtzaeg, P. B., Skjuve, M. & Folstad, A. My AI friend: How users of a social chatbot understand their human-AI friendship. Human Communication Research 48, 404–429 (2022)
2022
-
[15]
Zhang, Z. et al. SafetyBench: Evaluating the safety of large language models. in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 15537–15553 (Association for Computational Linguistics, 2024). doi:10.18653/v1/2024.acl-long.830
-
[16]
Mazeika, M. et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. in Proceedings of the 41st International Conference on Machine Learning vol. 235 35181– 35224 (2024)
2024
-
[17]
Han, S. et al. WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and re- fusals of LLMs. arXiv preprint arXiv:2406.18495 https://doi.org/10.48550/arXiv.2406.18495 (2024) doi:10.48550/arXiv.2406.18495
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.18495 2024
-
[18]
Zou, A., Wang, Z., Kolter, J. Z. & Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. in Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security 3109–3123 (ACM, 2023). doi:10.1145/3576915.3623151
-
[19]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Liu, X., Xu, N., Chen, M. & Xiao, C. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. arXiv preprint arXiv:2310.04451 https://doi.org/10.48550/arXiv.2310.04451 (2023) doi:10.48550/arXiv.2310.04451
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.04451 2023
-
[20]
Archiwaranguprok, C., Albrecht, C., Maes, P., Karahalios, K. & Pataranutaporn, P. Sim- ulating Psychological Risks in Human-AI Interactions: Real-Case Informed Modeling of AI- Induced Addiction, Anorexia, Depression, Homicide, Psychosis, and Suicide. Preprint at https://doi.org/10.48550/ARXIV.2511.08880 (2025)
-
[21]
Zhao, H. et al. ESC-Eval: Evaluating emotion support conversations in large language models. in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing 15785–15810 (Association for Computational Linguistics, 2024). doi:10.18653/v1/2024.emnlp-main.883
-
[22]
J., Baumann, A.-E
Goldman, E. J., Baumann, A.-E. & Poulin-Dubois, D. Preschoolers’ anthropomorphizing of robots: Do human-like properties matter? Front. Psychol. 13, 1102370 (2023)
2023
-
[23]
Nat Rev Psychol 3, 407–423 (2024)
Orben, A., Meier, A., Dalgleish, T.&Blakemore, S.-J.Mechanismslinkingsocialmediausetoadolescent mental health vulnerability. Nat Rev Psychol 3, 407–423 (2024)
2024
-
[24]
K., Blakemore, S.-J
Orben, A., Przybylski, A. K., Blakemore, S.-J. & Kievit, R. A. Windows of developmental sensitivity to social media. Nat Commun 13, 1649 (2022)
2022
-
[25]
L., Rodman, A
Sequeira, S. L., Rodman, A. M., Nesi, J. & Silk, J. S. Social threat and adolescent mental health. Nat Rev Psychol 4, 639–653 (2025)
2025
-
[26]
Zhang, R. et al. The Dark Side of AI Companionship: A Taxonomy of Harmful Algorithmic Behaviors in Human-AI Relationships. in Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems 1–17 (ACM, Yokohama Japan, 2025). doi:10.1145/3706598.3713429
-
[27]
Inferential social learning: cognitive foundations of human social learning and teaching
Gweon, H. Inferential social learning: cognitive foundations of human social learning and teaching. Trends in Cognitive Sciences 25, 896–910 (2021). 18
2021
-
[28]
& Robertson, J
Andries, V. & Robertson, J. Alexa doesn’t have that many feelings: Children’s understanding of AI through interactions with smart speakers in their homes. Computers and Education: Artificial Intelli- gence 5, 100176 (2023)
2023
-
[29]
Girouard-Hallam, L. N. & Danovitch, J. H. Children’s trust in and learning from voice assistants. Developmental Psychology 58, 646–661 (2022)
2022
-
[30]
E., Allen, N
Dahl, R. E., Allen, N. B., Wilbrecht, L. & Suleiman, A. B. Importance of investing in adolescence from a developmental science perspective. Nature 554, 441–450 (2018)
2018
-
[31]
& Mills, K
Blakemore, S.-J. & Mills, K. L. Is adolescence a sensitive period for sociocultural processing? Annual Review of Psychology 65, 187–207 (2014)
2014
-
[32]
Kirwan, E. M. et al. Loneliness in Emerging Adulthood: A Scoping Review. Adolescent Res Rev 10, 47–67 (2025)
2025
-
[33]
& Campos-Castillo, C
Laestadius, L., Bishop, A., Gonzalez, M., Illencik, D. & Campos-Castillo, C. Too human and not human enough: A grounded theory analysis of mental health harms from emotional dependence on the social chatbot Replika. New Media & Society 26, 5923–5941 (2024)
2024
-
[34]
& Cohen, I
De Freitas, J. & Cohen, I. G. Disclosure, humanizing, and contextual vulnerability of generative AI chatbots. NEJM AI 2, AIpc2400464 (2025)
2025
-
[35]
Lu, Y. et al. LongSafety: Evaluating Long-Context Safety of Large Language Models. in Pro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 31705–31725 (Association for Computational Linguistics, Vienna, Austria, 2025). doi:10.18653/v1/2025.acl-long.1530
-
[36]
Goldman, E. J. & Poulin-Dubois, D. Children’s anthropomorphism of inanimate agents. WIRES Cog- nitive Science 15, e1676 (2024)
2024
-
[37]
Peng, Y. et al. The Tong Test: Evaluating artificial general intelligence through dynamic embodied physical and social interactions. Engineering 34, 12–22 (2024)
2024
-
[38]
Park, J. S. et al. Generative agents: Interactive simulacra of human behavior. in Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology 1–22 (ACM, 2023). doi:10.1145/3586183.3606763
-
[39]
Wang, K. et al. Know you first and be you better: Modeling human-like user simulators via im- plicit profiles. in Proceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers) 21082–21107 (Association for Computational Linguistics, 2025). doi:10.18653/v1/2025.acl-long.1025
-
[40]
Du, W. et al. DFLOW: Diverse dialogue flow simulation with large language models. in Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025) 17–32 (Association for Computational Linguistics, 2025). doi:10.18653/v1/2025.realm-1.2
-
[41]
Drift-diffusion models for multiple-alternative forced-choice decision making
Roxin, A. Drift-diffusion models for multiple-alternative forced-choice decision making. Journal of Math- ematical Neuroscience 9, 5 (2019)
2019
-
[42]
Liu, Y. et al. G-Eval: NLG evaluation using GPT-4 with better human alignment. in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing 2511–2522 (Association for Computational Linguistics, 2023). doi:10.18653/v1/2023.emnlp-main.153. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.