EchoStyle: Unlocking High-Fidelity Video Stylization with Reverse Data Synthesis
Pith reviewed 2026-06-25 20:58 UTC · model grok-4.3
The pith
EchoStyle achieves high-fidelity text-driven stylization for videos of arbitrary length by training on a reverse-synthesized dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
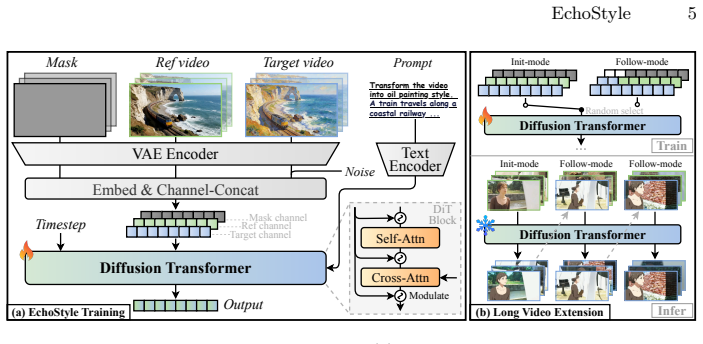
EchoStyle demonstrates that high-quality stylization of videos with arbitrary lengths is achievable using a video-to-video architecture re-fusing content and text style, trained on the V-Style20k dataset generated by an automatic reverse-synthesis pipeline, and employing init-follow-mode with sliding-window inference, resulting in performance comparable to closed-source solutions without style drift or motion distortion.
What carries the argument
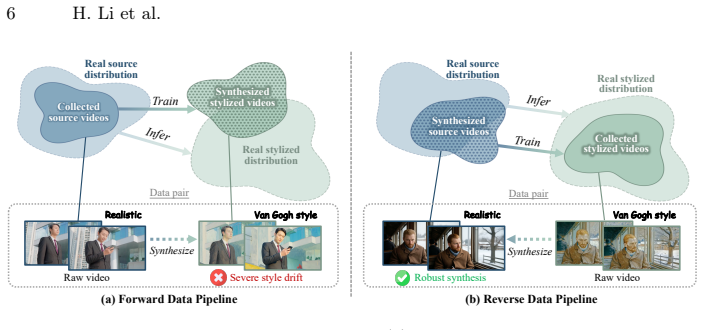
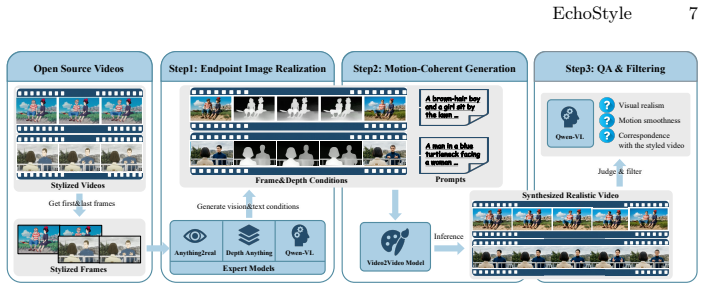
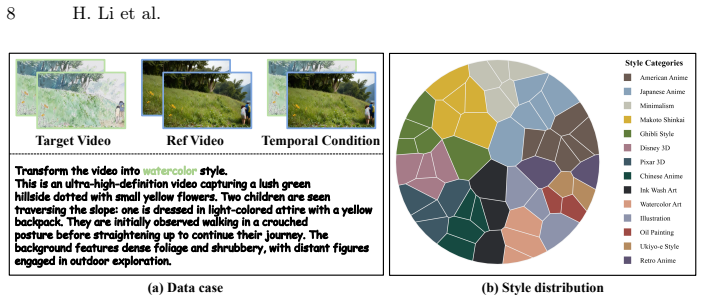
The automatic reverse-synthesis pipeline used to establish the V-Style20k dataset of 20k video pairs.
If this is right
- Text prompts can effectively guide video stylization without relying on reference images.
- Long videos can be processed consistently via sliding-window inference without accumulating errors.
- The method applies to a wide range of artistic styles with minimal content leakage.
- Results reach quality levels matching proprietary closed-source systems.
Where Pith is reading between the lines
- The reverse synthesis technique may be applicable to creating datasets for other video processing tasks such as enhancement or editing.
- Open implementations like this could reduce dependence on closed-source tools for content creation.
- If the dataset generalizes well, it might support fine-tuning for specific user styles beyond the training set.
Load-bearing premise
The automatic reverse-synthesis pipeline generates 20k high-quality video pairs without introducing artifacts, content-style mismatches, or biases that cause style drift and motion distortion.
What would settle it
Running the model on extended real videos outside the synthetic dataset and checking for visible style inconsistencies or motion artifacts over time.
Figures








read the original abstract
While image stylization has been studied extensively, video stylization remains a critical and largely unsolved challenge in the field of intelligent content creation. Existing methods, usually utilizing a reference image as the style prior, suffer from content leakage, data scarcity and limited adaptability to long videos, leading to suboptimal results with severe style drift and motion distortion. For these issues, we present EchoStyle, a scalable text-driven framework to achieve high-quality stylization of videos with arbitrary lengths. To start with, we construct a video-to-video architecture to appropriately re-fuse the video content and the text style. To address data scarcity, we pioneer an automatic reverse-synthesis pipeline to establish V-Style20k, a large-scale stylization dataset of 20k high-quality video pairs. To facilitate long video stylization, we devise an init-follow-mode mechanism along with a sliding-window inference strategy. Extensive experiments demonstrate EchoStyle's excellent performance across a wide range of artistic styles, even comparable to leading closed-source solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EchoStyle, a text-driven video stylization framework built on a video-to-video architecture. It constructs the V-Style20k dataset of 20k video pairs via an automatic reverse-synthesis pipeline to address data scarcity, and introduces an init-follow-mode mechanism plus sliding-window inference to support arbitrary-length videos. The central claim is that this yields high-fidelity stylization results across artistic styles, comparable to leading closed-source solutions, while mitigating content leakage, style drift, and motion distortion.
Significance. If the performance claims and data quality hold after proper validation, the work would offer a practical, scalable approach to long-video stylization that directly tackles data scarcity, a persistent bottleneck in the field. The reverse-synthesis idea for dataset creation and the inference strategy for length generalization are potentially reusable contributions.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the assertion of 'excellent performance' and comparability to closed-source systems rests on unspecified experiments; no quantitative metrics (FID, LPIPS, user-study scores), ablation tables, or error analysis are reported to support the claim that the method outperforms prior video stylization baselines or avoids the stated failure modes.
- [§3] §3 (Methods), reverse-synthesis pipeline for V-Style20k: the central claim that the automatically generated 20k pairs enable high-quality training without inheriting artifacts or mismatches is load-bearing, yet no controlled validation (e.g., FID/LPIPS against real stylization pairs, human preference against ground-truth, or bias analysis) is provided to confirm the synthetic distribution matches the target distribution.
- [§3.2, §4] §3.2 and §4: the init-follow-mode and sliding-window inference are presented as solutions for long-video consistency, but no ablation isolating their contribution (e.g., with vs. without the mode on sequences >30 s) or quantitative temporal-consistency metrics (e.g., optical-flow warping error) are shown.
minor comments (2)
- [§3.1] Notation for the video-to-video architecture (e.g., how content and style features are fused) is introduced without an accompanying diagram or equation reference, making the re-fusion step difficult to follow.
- The manuscript does not state whether the V-Style20k dataset or trained model weights will be released, which limits reproducibility of the reported results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that strengthening the quantitative support for our claims will improve the manuscript and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the assertion of 'excellent performance' and comparability to closed-source systems rests on unspecified experiments; no quantitative metrics (FID, LPIPS, user-study scores), ablation tables, or error analysis are reported to support the claim that the method outperforms prior video stylization baselines or avoids the stated failure modes.
Authors: We acknowledge that the current manuscript relies primarily on qualitative demonstrations. In the revision we will add FID, LPIPS, and user-study scores to §4, together with ablation tables and error analysis comparing against prior baselines. revision: yes
-
Referee: [§3] §3 (Methods), reverse-synthesis pipeline for V-Style20k: the central claim that the automatically generated 20k pairs enable high-quality training without inheriting artifacts or mismatches is load-bearing, yet no controlled validation (e.g., FID/LPIPS against real stylization pairs, human preference against ground-truth, or bias analysis) is provided to confirm the synthetic distribution matches the target distribution.
Authors: We agree that explicit validation of V-Style20k is necessary. We will include FID/LPIPS comparisons against real stylization pairs, human preference studies, and bias analysis in the revised §3. revision: yes
-
Referee: [§3.2, §4] §3.2 and §4: the init-follow-mode and sliding-window inference are presented as solutions for long-video consistency, but no ablation isolating their contribution (e.g., with vs. without the mode on sequences >30 s) or quantitative temporal-consistency metrics (e.g., optical-flow warping error) are shown.
Authors: We will add ablations isolating the init-follow-mode on sequences longer than 30 s and report optical-flow warping error as a quantitative temporal-consistency metric in the revised §4. revision: yes
Circularity Check
No circularity: claims rest on external dataset construction and empirical results
full rationale
The paper presents an empirical ML framework whose central performance claims depend on the quality of an externally generated V-Style20k dataset produced by a reverse-synthesis pipeline and on subsequent training plus inference strategies. No equations, fitted parameters, or self-referential definitions are described that would make any reported stylization result equivalent to its inputs by construction. The dataset generation step occurs prior to and independently of model training, with no indication that the pipeline re-uses the trained model or that performance metrics are computed on data whose labels are defined by the model itself. Self-citations, if present, are not load-bearing for the core claims. This is the standard non-circular case for a data-driven video stylization paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2309.16609 (2023)
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2311.15127 (2023)
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
Pith/arXiv arXiv 2023
-
[3]
ACM Transactions on Graphics (TOG)43(6), 1–11 (2024)
Chefer,H., Zada, S., Paiss, R., Ephrat,A., Tov, O.,Rubinstein,M., Wolf,L., Dekel, T., Michaeli, T., Mosseri, I.: Still-moving: Customized video generation without customized video data. ACM Transactions on Graphics (TOG)43(6), 1–11 (2024)
2024
-
[4]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., et al.: A survey on in-context learning. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 1107–1128 (2024)
2024
-
[5]
In: European Conference on Computer Vision
Frenkel, Y., Vinker, Y., Shamir, A., Cohen-Or, D.: Implicit style-content separation using b-lora. In: European Conference on Computer Vision. pp. 181–198. Springer (2024)
2024
-
[6]
In: Asian Conference on Computer Vision
Gao,C.,Gu,D.,Zhang,F.,Yu,Y.:Reconet:Real-timecoherentvideostyletransfer network. In: Asian Conference on Computer Vision. pp. 637–653. Springer (2018)
2018
-
[7]
In: IEEE Transactions on Pattern Analysis and Machine Intelligence
Gao, J., Sun, Y., Liu, Y., Tang, Y., Zeng, Y., Qi, D., Chen, K., Zhao, C.: Styleshot: A snapshot on any style. In: IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE (2025)
2025
-
[8]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., Li, X., Li, Y., Lin, S., Lin, Z., Liu, J., Liu, S., Nie, X., Qing, Z., Ren, Y., Sun, L., Tian, Z., Wang, R., Wang, S., Wei, G., Wu, G., Wu, J., Xia, R., Xiao, F., Xiao, X., Yan, J., Yang, C., Yang, J., Yang, R., Yang, T., Yang, Y., Ye, Z., Zeng, X., Zeng, Y., Zhan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.09113 2025
-
[9]
In: International Conference on Learning Rep- resentations (2024)
Geyer, M., Bar-Tal, O., Bagon, S., Dekel, T.: Tokenflow: Consistent diffusion fea- tures for consistent video editing. In: International Conference on Learning Rep- resentations (2024)
2024
-
[10]
In: British Machine Vision Conference (2017)
Ghiasi, G., Lee, H., Kudlur, M., Dumoulin, V., Shlens, J.: Exploring the structure of a real-time, arbitrary neural artistic stylization network. In: British Machine Vision Conference (2017)
2017
-
[11]
arXiv preprint arXiv:2404.15275 (2024)
He, X., Liu, Q., Qian, S., Wang, X., Hu, T., Cao, K., Yan, K., Zhang, J.: Id- animator: Zero-shot identity-preserving human video generation. arXiv preprint arXiv:2404.15275 (2024)
arXiv 2024
-
[12]
In: International Conference on Learning Representations
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: International Conference on Learning Representations. vol. 1, p. 3 (2022)
2022
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8153–8163 (2024) 16 H. Li et al
2024
-
[14]
In: Proceedings of the IEEE International Conference on Computer Vision
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 1501–1510 (2017)
2017
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: Vace: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17191–17202 (2025)
2025
-
[17]
arXiv preprint arXiv:1312.6114 (2013)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
Pith/arXiv arXiv 2013
-
[18]
In: Ad- vances in Neural Information Processing Systems
Kong, Z., Gao, F., Zhang, Y., Kang, Z., Wei, X., Cai, X., Chen, G., Luo, W.: Let them talk: Audio-driven multi-person conversational video generation. In: Ad- vances in Neural Information Processing Systems. vol. 38, pp. 70990–71013 (2026)
2026
-
[19]
Transactions on Machine Learning Research (2024)
Ku, M., Wei, C., Ren, W., Yang, H., Chen, W.: Anyv2v: A tuning-free framework for any video-to-video editing tasks. Transactions on Machine Learning Research (2024)
2024
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Kwon, G., Ye, J.C.: Clipstyler: Image style transfer with a single text condition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 18062–18071 (2022)
2022
-
[21]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Li, H., Wang, Y., Huang, T., Huang, H., Wang, H., Chu, X.: Ld-rps: Zero-shot unified image restoration via latent diffusion recurrent posterior sampling. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13684–13694 (2025)
2025
-
[22]
In: International Conference on Learning Representations (2023)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: International Conference on Learning Representations (2023)
2023
-
[23]
ACM Transactions on Graphics (2024)
Liu, G., Xia, M., Zhang, Y., Chen, H., Xing, J., Wang, Y., Wang, X., Yang, Y., Shan, Y.: Stylecrafter: Enhancing stylized text-to-video generation with style adapter. ACM Transactions on Graphics (2024)
2024
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition
Liu, S., Zhang, Y., Li, W., Lin, Z., Jia, J.: Video-p2p: Video editing with cross- attention control. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition. pp. 8599–8608 (2024)
2024
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Z.S., Wang, L.W., Siu, W.C., Kalogeiton, V.: Name your style: text-guided artistic style transfer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3530–3534 (2023)
2023
-
[26]
Mehraban,S.,Adeli,V.,Rommann,J.,Taati,B.,Truskovskyi,K.:Pickstyle:Video- to-videostyletransferwithcontext-styleadapters.arXivpreprintarXiv:2510.07546 (2025)
arXiv 2025
-
[27]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[28]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Qi, T., Fang, S., Wu, Y., Xie, H., Liu, J., Chen, L., He, Q., Zhang, Y.: Deadiff: An efficient stylization diffusion model with disentangled representations. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8693–8702 (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) EchoStyle 17
2022
-
[30]
Computer Graphics Forum42(4), e14891 (2023)
Shekhar, S., Reimann, M., Hilscher, M., Semmo, A., Döllner, J., Trapp, M.: Inter- active control over temporal consistency while stylizing video streams. Computer Graphics Forum42(4), e14891 (2023)
2023
-
[31]
arXiv preprint arXiv:2404.01292 (2024)
Somepalli, G., Gupta, A., Gupta, K., Palta, S., Goldblum, M., Geiping, J., Shri- vastava, A., Goldstein, T.: Measuring style similarity in diffusion models. arXiv preprint arXiv:2404.01292 (2024)
arXiv 2024
-
[32]
In: IEEE Transactions on Pattern Analysis and Machine Intelligence
Song, Q., Lin, M., Zhan, W., Yan, S., Cao, L., Ji, R.: Univst: A unified framework for training-free localized video style transfer. In: IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Suresh, A.P., Jain, S., Noinongyao, P., Ganguly, A., Watchareeruetai, U., Sama- coits, A.: Fastclipstyler: Optimisation-free text-based image style transfer using style representations. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 7316–7325 (2024)
2024
-
[34]
arXiv preprint arXiv:2312.11805 (2023)
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
Pith/arXiv arXiv 2023
-
[35]
arXiv preprint arXiv:2512.16776 (2025)
Team, K., Chen, J., Ci, Y., Du, X., Feng, Z., Gai, K., Guo, S., Han, F., He, J., He, K., et al.: Kling-omni technical report. arXiv preprint arXiv:2512.16776 (2025)
Pith/arXiv arXiv 2025
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tu, S., Xing, Z., Han, X., Cheng, Z.Q., Dai, Q., Luo, C., Wu, Z.: Stableanimator: High-quality identity-preserving human image animation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21096–21106 (2025)
2025
-
[37]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2404.02733 (2024)
Wang, H., Spinelli, M., Wang, Q., Bai, X., Qin, Z., Chen, A.: Instantstyle: Free lunch towards style-preserving in text-to-image generation. arXiv preprint arXiv:2404.02733 (2024)
arXiv 2024
-
[39]
Wang, J., Sheng, H., Cai, S., Zhang, W., Yan, C., Feng, Y., Deng, B., Ye, J.: Echoshot:Multi-shotportraitvideogeneration.In:AdvancesinNeuralInformation Processing Systems. vol. 38, pp. 22058–22090 (2026)
2026
-
[40]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[41]
arXiv preprint arXiv:2508.02324 (2025)
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
Pith/arXiv arXiv 2025
-
[42]
In: International Conference on Learning Representations (2026)
Xu,J.,Mei,Y.,Zhang,K.,Patel,V.M.:Freevis:Training-freevideostylizationwith inconsistent references. In: International Conference on Learning Representations (2026)
2026
-
[43]
In: International Conference on Learning Representations (2026)
Yang, Y., Sheng, H., Cai, S., Lin, J., Wang, J., Deng, B., Lu, J., Wang, H., Ye, J.: Echomotion: Unified human video and motion generation via dual-modality diffusion transformer. In: International Conference on Learning Representations (2026)
2026
-
[44]
arXiv preprint arXiv:2308.06721 (2023)
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
Pith/arXiv arXiv 2023
-
[45]
In: International Conference on Learning Representations (2026)
Ye, Z., He, X., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, Q., Luo, W.: Unic: Unified in-context video editing. In: International Conference on Learning Representations (2026)
2026
-
[46]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Ye, Z., Huang, H., Wang, X., Wan, P., Zhang, D., Luo, W.: Stylemaster: Stylize your video with artistic generation and translation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 2630–2640 (2025) 18 H. Li et al
2025
-
[47]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ye, Z., Liu, Q., Wei, C., Zhang, Y., Wang, X., Wan, P., Gai, K., Luo, W.: Visual- aware cot: Achieving high-fidelity visual consistency in unified models. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9116–9126 (June 2026)
2026
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[49]
arXiv preprint arXiv:2601.20175 (2026)
Zhang, S., Yang, X., Zi, B., Huang, H., Zhang, C., Li, X.: Telestyle: Content- preserving style transfer in images and videos. arXiv preprint arXiv:2601.20175 (2026)
arXiv 2026
-
[50]
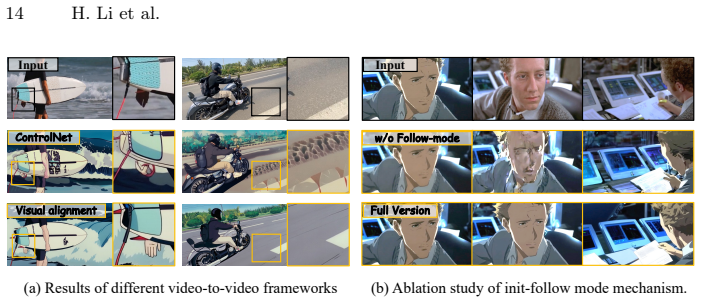
Zhong, Z., Ji, Y., Kong, Z., Liu, Y., Wang, J., Feng, J., Liu, L., Wang, X., Li, Y., She, Y., et al.: Anytalker: Scaling multi-person talking video generation with interactivity refinement. arXiv preprint arXiv:2511.23475 (2025) EchoStyle 19 A Experimental Discussions Ablation of Video-to-Video Framework.To evaluate the impact of different architectural d...
arXiv 2025
-
[51]
Color Tone (Hue tendency, saturation, contrast)
-
[52]
Compositional Features (Lines, spatial layout)
-
[53]
Texture & Details (Brushstrokes, lighting, material feel)
-
[54]
Core Elements (Presence of iconic visual symbols of the style). [Output Constraints - STRICT] - If the Left image is closer to the style, output ONLY: Left - If the Right image is closer to the style, output ONLY: Right - Strictly prohibited: Any explanations, reasons, or extra punctuation. C Supplementary Visual Results In this section, we provide supple...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.