RAS: Measuring LLM Safety Through Refusal Alignment
Pith reviewed 2026-06-25 20:01 UTC · model grok-4.3
The pith
Refusal directions in a reference model's internal states can score the safety of other LLMs without judging their outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
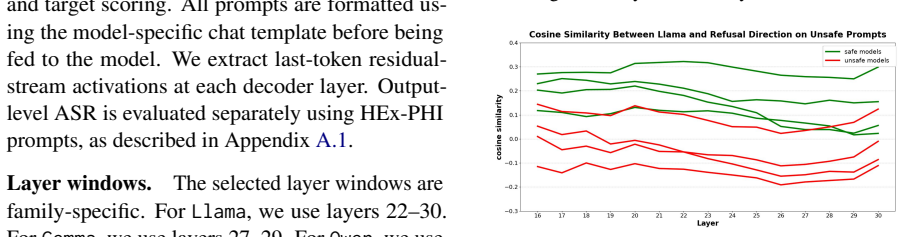
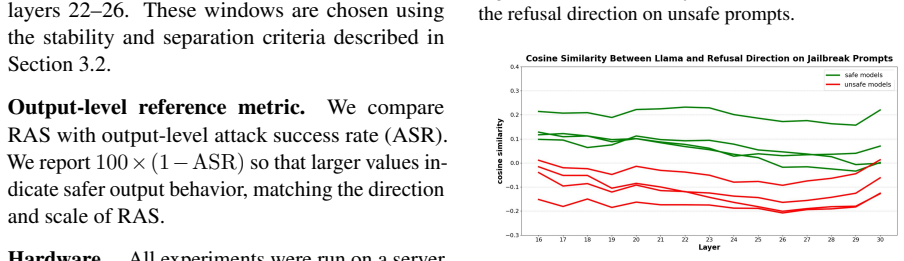
SafeVec extracts layer-wise refusal directions from a safety-aligned reference model, selects stable layer windows where safe and unsafe behaviors separate, and computes a Refusal Alignment Score (RAS) that maps representation-level alignment to a calibrated 0-100 safety score for any target model under unsafe prompts.
What carries the argument
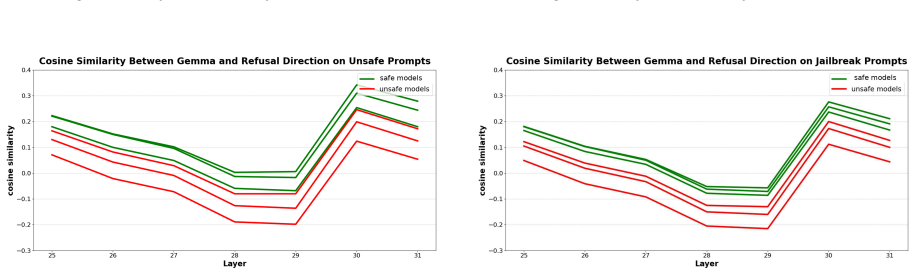
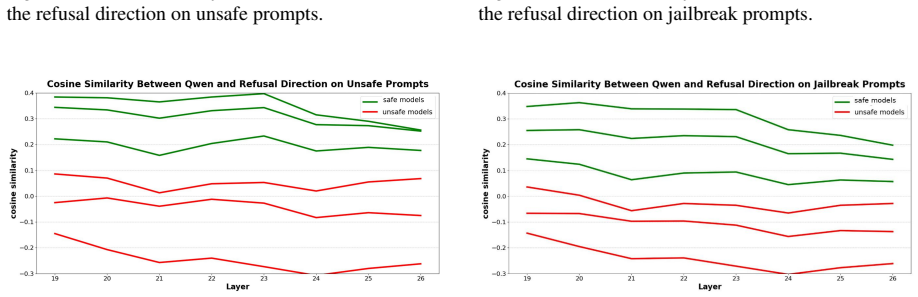
SafeVec procedure that extracts and applies refusal directions from internal representations to quantify alignment via the RAS metric.
If this is right
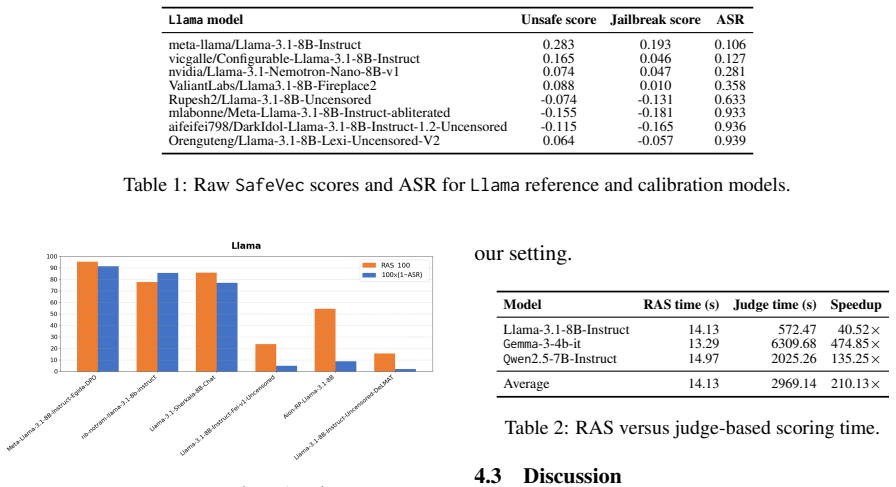
- RAS separates safety-aligned models from uncensored and abliterated variants across Llama, Gemma, and Qwen families.
- RAS values track output-level attack success rates on the tested models.
- RAS evaluation runs substantially faster than judge-based output assessment.
- White-box measurement of representation alignment supplies a compact safety signal without needing generated text.
Where Pith is reading between the lines
- The same refusal-direction extraction could be applied during fine-tuning to monitor safety drift in real time without separate evaluation runs.
- If the directions prove stable enough, a small set of reference models might serve as a shared safety baseline for many downstream families.
- Representation-level scoring opens the possibility of checking safety properties that are hard to elicit through text prompts alone.
Load-bearing premise
Refusal directions taken from one safety-aligned model stay stable across chosen layer windows and transfer as a reliable safety signal to other models and families.
What would settle it
Running RAS on a fresh model family or prompt set where aligned models receive low scores and uncensored models receive high scores, or where RAS no longer tracks measured attack success rates.
Figures


read the original abstract
Safety evaluation of large language models (LLMs) is commonly performed by querying models with unsafe or jailbreak prompts and judging whether their outputs violate a safety policy. Although useful, output-level evaluation is expensive, sensitive to judge choice, and easily tied to fixed question banks. We propose **SafeVec**, a white-box evaluation procedure that measures safety from internal representations rather than generated answers. **SafeVec** first extracts layer-wise refusal directions from a safety-aligned reference model, then selects stable layer windows where safe and unsafe behaviors are separable, and finally scores a target model by measuring whether its hidden states align with these refusal directions under unsafe and jailbreak prompts. The resulting metric, **RAS** (**R**efusal **A**lignment **S**core), maps representation-level refusal alignment to a calibrated 0-100 safety score. Across `Llama`, `Gemma`, and `Qwen` model families, RAS separates aligned models from uncensored and abliterated variants, tracks output-level attack success rate, and is substantially faster than judge-based evaluation. These results suggest that refusal alignment provides a compact and efficient signal for white-box LLM safety evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SafeVec, a white-box procedure for evaluating LLM safety by extracting layer-wise refusal directions from a safety-aligned reference model, selecting stable layer windows where safe and unsafe behaviors are separable, and computing the Refusal Alignment Score (RAS) for target models based on alignment of their hidden states with these directions under unsafe and jailbreak prompts. The resulting RAS maps to a calibrated 0-100 safety score. Experiments across Llama, Gemma, and Qwen families claim that RAS separates aligned models from uncensored and abliterated variants, tracks output-level attack success rate, and is substantially faster than judge-based evaluation.
Significance. If the empirical claims hold, this offers a potentially scalable white-box alternative to output-based safety evaluations that avoids sensitivity to judge choice and fixed prompt banks. The approach extends representation engineering techniques to safety and could provide efficiency gains if the internal signal proves robust and transferable.
major comments (2)
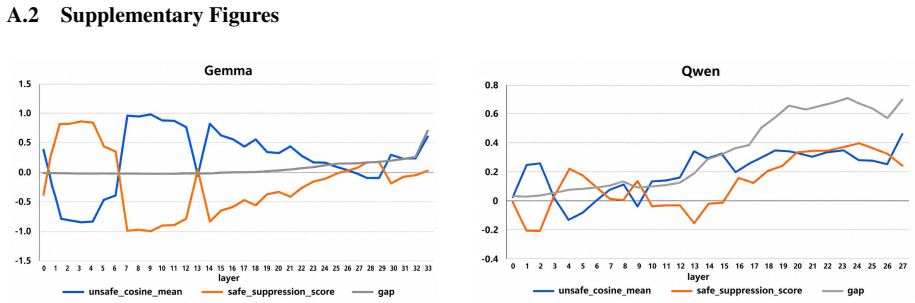
- [Method and experimental results] The transferability of refusal directions extracted from a single reference model to architecturally distinct families (Llama to Gemma and Qwen) is load-bearing for the cross-family separation claim in the abstract. The manuscript selects stable windows on the reference but supplies no quantitative check (e.g., separability metrics or direction cosine similarities computed on target-model residual streams) that the same windows remain informative once the target geometry differs, leaving open whether the observed separation reflects general safety alignment or reference-specific features.
- [Results] The claim that RAS tracks output-level attack success rate requires supporting statistics. No correlation coefficients, confidence intervals, or comparison against simple baselines (e.g., prompt-length or token-probability heuristics) are referenced, making it impossible to assess whether the tracking is substantive or incidental.
minor comments (2)
- [Method] The exact formula for RAS (including any aggregation across the selected layer window, normalization, and calibration to the 0-100 range) should be stated explicitly with an equation.
- Clarify the precise set of unsafe and jailbreak prompts used for both reference extraction and target scoring, and whether they overlap with any evaluation sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on transferability and statistical support. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method and experimental results] The transferability of refusal directions extracted from a single reference model to architecturally distinct families (Llama to Gemma and Qwen) is load-bearing for the cross-family separation claim in the abstract. The manuscript selects stable windows on the reference but supplies no quantitative check (e.g., separability metrics or direction cosine similarities computed on target-model residual streams) that the same windows remain informative once the target geometry differs, leaving open whether the observed separation reflects general safety alignment or reference-specific features.
Authors: We agree that the manuscript would benefit from explicit quantitative validation of window transferability. In the revision we will compute, for each target family, (i) separability metrics (mean projection difference and AUC between safe/unsafe prompts) using the reference-derived directions on target residual streams, and (ii) cosine similarity between the reference refusal directions and the top principal component of the target-model unsafe-minus-safe contrast within the same layer windows. These numbers will be added to Section 4 and the appendix. revision: yes
-
Referee: [Results] The claim that RAS tracks output-level attack success rate requires supporting statistics. No correlation coefficients, confidence intervals, or comparison against simple baselines (e.g., prompt-length or token-probability heuristics) are referenced, making it impossible to assess whether the tracking is substantive or incidental.
Authors: We accept that the current text lacks the requested statistics. The revised manuscript will report Pearson and Spearman correlations (with 95% bootstrap CIs) between RAS and attack success rate across all evaluated models and prompt sets. We will also add two simple baselines—average prompt token length and mean log-probability of refusal-related tokens—and show that RAS yields higher correlation than either baseline. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper defines RAS explicitly as a white-box metric that extracts refusal directions from one fixed safety-aligned reference model, selects stable windows based on separability in that reference, and then computes alignment scores on target models. This construction is a deliberate design choice for efficient evaluation rather than a self-referential loop. No equations or steps reduce the final score to a fitted parameter or reference-specific feature by construction; the separation and correlation claims are presented as empirical observations across Llama/Gemma/Qwen families. No self-citation load-bearing steps or ansatz smuggling are present in the provided text. The method is self-contained against external benchmarks such as output-level ASR.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Refusal directions exist in the layer-wise hidden states of safety-aligned models and can be extracted to form a transferable safety signal
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
SafetyBench: Evaluating the Safety of Large Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
-
[2]
Advances in Neural Information Processing Systems , year =
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[3]
2024 , eprint =
A StrongREJECT for Empty Jailbreaks , author =. 2024 , eprint =
2024
-
[4]
2022 , eprint =
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned , author =. 2022 , eprint =
2022
-
[5]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
Red Teaming Language Models with Language Models , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
2022
-
[6]
2023 , eprint =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
2023
-
[7]
2023 , eprint =
Jailbreaking Black Box Large Language Models in Twenty Queries , author =. 2023 , eprint =
2023
-
[8]
2023 , eprint =
Jailbroken: How Does LLM Safety Training Fail? , author =. 2023 , eprint =
2023
-
[9]
Advances in Neural Information Processing Systems , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[10]
2022 , eprint =
Constitutional AI: Harmlessness from AI Feedback , author =. 2022 , eprint =
2022
-
[11]
2023 , eprint =
Towards Understanding Sycophancy in Language Models , author =. 2023 , eprint =
2023
-
[12]
Findings of the Association for Computational Linguistics: EMNLP 2020 , year =
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2020 , year =
2020
-
[13]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing , year =
StereoSet: Measuring Stereotypical Bias in Pretrained Language Models , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing , year =
-
[14]
Findings of the Association for Computational Linguistics: ACL 2022 , year =
BBQ: A Hand-Built Bias Benchmark for Question Answering , author =. Findings of the Association for Computational Linguistics: ACL 2022 , year =
2022
-
[15]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , year =
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , year =
-
[16]
Advances in Neural Information Processing Systems , year =
Refusal in Language Models Is Mediated by a Single Direction , author =. Advances in Neural Information Processing Systems , year =
-
[17]
2023 , eprint =
Representation Engineering: A Top-Down Approach to AI Transparency , author =. 2023 , eprint =
2023
-
[18]
2022 , eprint =
Discovering Latent Knowledge in Language Models Without Supervision , author =. 2022 , eprint =
2022
-
[19]
2024 , eprint =
Activation Addition: Steering Language Models Without Optimization , author =. 2024 , eprint =
2024
-
[20]
2023 , eprint =
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author =. 2023 , eprint =
2023
-
[21]
International Conference on Learning Representations , year =
Language Models Represent Space and Time , author =. International Conference on Learning Representations , year =
-
[22]
Advances in Neural Information Processing Systems , year =
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. Advances in Neural Information Processing Systems , year =
-
[23]
Advances in Neural Information Processing Systems , year =
Locating and Editing Factual Associations in GPT , author =. Advances in Neural Information Processing Systems , year =
-
[24]
International Conference on Learning Representations , year =
Mass-Editing Memory in a Transformer , author =. International Conference on Learning Representations , year =
-
[25]
2026 IEEE Conference on Artificial Intelligence (CAI) , pages=
Testing Method for Language Model Evaluation: A Case Study on a Localized Question Bank , author=. 2026 IEEE Conference on Artificial Intelligence (CAI) , pages=. 2026 , organization=
2026
-
[26]
Proceedings of the 41st International Conference on Machine Learning , series=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. Proceedings of the 41st International Conference on Machine Learning , series=
-
[27]
International Conference on Learning Representations , volume=
Sorry-bench: Systematically evaluating large language model safety refusal , author=. International Conference on Learning Representations , volume=
-
[28]
The Twelfth International Conference on Learning Representations , year=
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author=. The Twelfth International Conference on Learning Representations , year=
-
[29]
2024 , eprint=
Token Highlighter: Inspecting and Mitigating Jailbreak Prompts for Large Language Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.