Graph it first! Enabling Reasoning on Long-form Egocentric Videos through Scene Graphs
Pith reviewed 2026-07-03 23:07 UTC · model grok-4.3
The pith
Converting long egocentric videos into text scene graphs lets MLLMs reason over full sequences within token limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
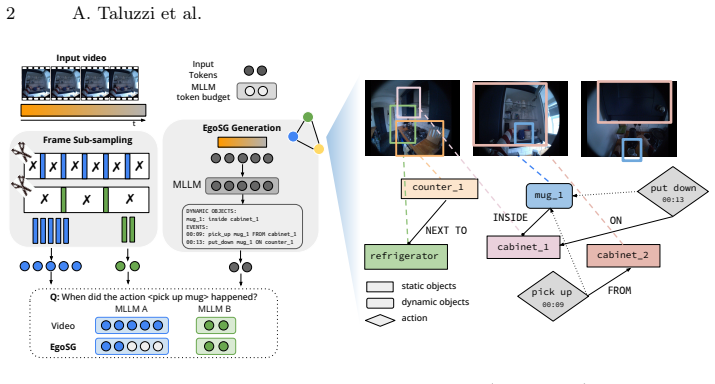
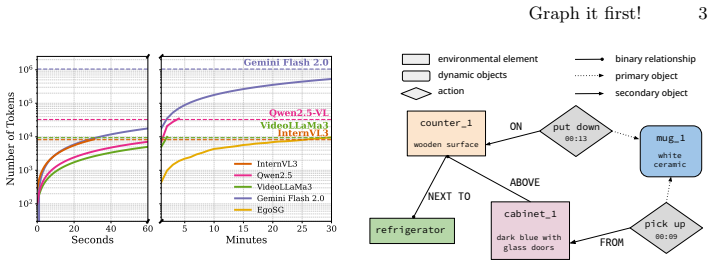
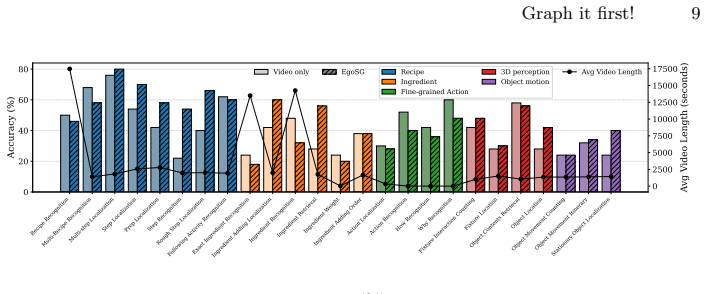
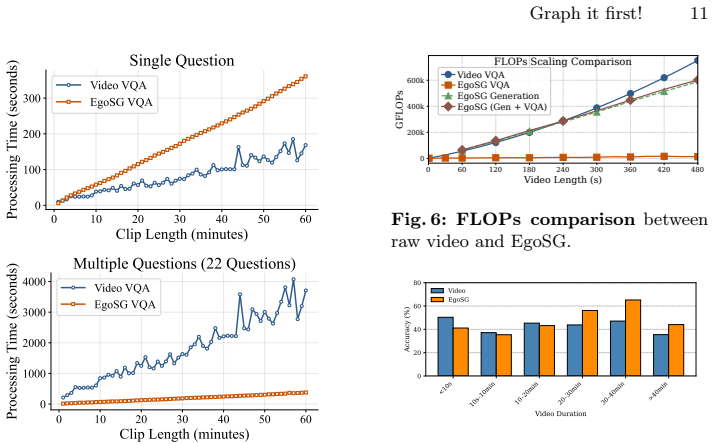
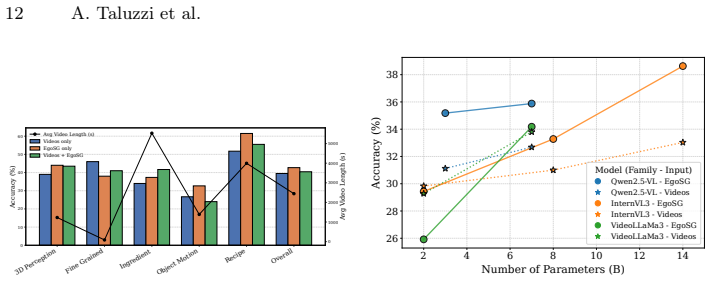
Representing videos as Egocentric Scene Graphs produces a temporally grounded symbolic text form that preserves semantic richness, reduces input length, and lets MLLMs perform fine-grained reasoning over complete long sequences inside their token budgets, yielding state-of-the-art results on HD-EPIC VQA.
What carries the argument
Egocentric Scene Graphs (EgoSGs): temporally grounded, structured text representations that capture objects, attributes, spatial relations, and interactions over time.
If this is right
- MLLMs can answer questions about entire long videos without subsampling frames.
- Structured text inputs replace raw video for tasks that need temporal continuity.
- Performance gains appear on benchmarks that test fine-grained state changes and interactions.
- The approach works across multiple MLLM architectures without retraining the models.
Where Pith is reading between the lines
- The same early conversion to symbolic graphs could apply to other long multimodal sequences such as audio or multi-view video.
- Hybrid systems might combine graph construction with selective video frame retrieval when the graph alone is ambiguous.
- If graph construction can be made more robust, it opens a route to parameter-efficient video AI that moves from pixels to symbols before the language model stage.
Load-bearing premise
The scene graphs must retain every piece of information needed for fine-grained temporal reasoning and the language models must interpret the text graphs without further loss.
What would settle it
Run the same VQA questions on videos where a critical state change or interaction is deliberately omitted from the generated scene graph but visible in the raw video; if graph-based answers become incorrect while a video baseline still succeeds, the central claim fails.
Figures





read the original abstract
Existing multi-modal large language models (MLLMs) face significant challenges in processing long video sequences due to strict input token limitations. As a result, current video understanding approaches, especially in egocentric settings characterized by complex dynamics, frequent state changes, and moving cameras, are forced to massively subsample frames. This leads to severe loss of temporal and contextual information, constraining their ability to perform fine-grained video reasoning. In this work, we introduce a framework for egocentric video question answering (VQA) that overcomes these input constraints through Egocentric Scene Graphs (EgoSGs), i.e., temporally grounded, structured representations that capture objects, attributes, spatial relations, and interactions over time. By representing videos as compact, text-based scene graphs, our method preserves the essential visual and temporal information of the original video in a symbolic form that drastically reduces input length while maintaining semantic richness. Crucially, this enables MLLMs to reason efficiently over entire video sequences within their token budget. On HD-EPIC VQA, our method achieves state-of-the-art results, outperforming strong video-based baselines on multiple models and suggesting that structured, temporally grounded representations like EgoSGs can bridge long-form egocentric video understanding and the context limitations of today's MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Egocentric Scene Graphs (EgoSGs) as temporally grounded, text-based structured representations of long egocentric videos that capture objects, attributes, spatial relations, and interactions. It claims these compact representations preserve essential visual and temporal information, drastically reduce input length for MLLMs while maintaining semantic richness, enable full-sequence reasoning within token budgets, and achieve state-of-the-art results on HD-EPIC VQA by outperforming strong video-based baselines on multiple models.
Significance. If the information-preservation claim holds, the approach would be significant for long-form egocentric video understanding, as it offers a way to bypass frame subsampling and token limits in MLLMs through symbolic compression. Evaluation against an external dataset with reported outperformance over baselines is a methodological strength.
major comments (2)
- [Abstract] Abstract: The central assertion that EgoSGs 'preserve the essential visual and temporal information of the original video in a symbolic form' is made without any retention metric, ablation on graph completeness, error analysis on the construction pipeline, or quantitative evidence of retained information. This is load-bearing for both the SOTA claim and the argument that the token-budget advantage is not undermined by informational incompleteness.
- [Abstract] Abstract: The manuscript asserts SOTA results on HD-EPIC VQA but supplies no construction details, ablation studies, or quantitative evidence of retained information, so the support for the claim that structured representations bridge long-form video understanding and MLLM context limits cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for highlighting these points on evidence and support for our claims. We address each comment below and will revise the manuscript to strengthen the presentation of information retention and methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central assertion that EgoSGs 'preserve the essential visual and temporal information of the original video in a symbolic form' is made without any retention metric, ablation on graph completeness, error analysis on the construction pipeline, or quantitative evidence of retained information. This is load-bearing for both the SOTA claim and the argument that the token-budget advantage is not undermined by informational incompleteness.
Authors: We agree this claim would benefit from direct supporting evidence. The current manuscript uses downstream VQA performance as an indirect indicator of preservation, but we will add explicit retention metrics (e.g., event recall between graph and video), an ablation on graph completeness, and error analysis of the construction pipeline in a new subsection of the experiments. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts SOTA results on HD-EPIC VQA but supplies no construction details, ablation studies, or quantitative evidence of retained information, so the support for the claim that structured representations bridge long-form video understanding and MLLM context limits cannot be assessed.
Authors: Construction details appear in Section 3 and ablation studies in Section 4.3, with SOTA results reported against video baselines. To directly address the bridging claim, we will expand the discussion and add quantitative token-budget vs. retention comparisons. We will also move key pipeline details into the abstract for clarity. revision: partial
Circularity Check
No circularity; empirical evaluation on external benchmark is independent
full rationale
The paper introduces EgoSG construction and evaluates the resulting text representations on the external HD-EPIC VQA dataset, reporting outperformance versus video baselines. No equations, fitted parameters, or self-citations are invoked to derive the performance claims; the method's token-reduction benefit and reasoning capability are demonstrated directly through comparison on held-out questions. The derivation chain therefore remains self-contained against external data rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporally grounded scene graphs can capture and preserve the essential semantic, spatial, and interaction information of egocentric videos without substantial loss for downstream reasoning.
invented entities (1)
-
Egocentric Scene Graphs (EgoSGs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716–23736 (2022)
Alayrac,J.B.,Donahue,J.,Luc,P.,Miech,A.,Barr,I.,Hasson,Y.,Lenc,K.,Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716–23736 (2022)
2022
-
[2]
In: Proceedings of the IEEE/CVF international conference on computer vision
Armeni, I., He, Z.Y., Gwak, J., Zamir, A.R., Fischer, M., Malik, J., Savarese, S.: 3d scene graph: A structure for unified semantics, 3d space, and camera. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5664–5673 (2019)
2019
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Arnab, A., Sun, C., Schmid, C.: Unified graph structured models for video under- standing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8117–8126 (2021)
2021
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bärmann, L., Waibel, A.: Where did i leave my keys?-episodic-memory-based ques- tion answering on egocentric videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1560–1568 (2022)
2022
-
[6]
arXiv preprint arXiv:2312.04314 (2023)
Chen, Z., Wu, J., Lei, Z., Zhang, Z., Chen, C.: Gpt4sgg: Synthesizing scene graphs from holistic and region-specific narratives. arXiv preprint arXiv:2312.04314 (2023)
-
[7]
Advances in Neural Information Processing Systems 38, 23475–23537 (2026)
Cho, J.H., Madotto, A., Mavroudi, E., Afouras, T., Nagarajan, T., Maaz, M., Song, Y., Ma, T., Hu, S., Jain, S., et al.: Perceptionlm: Open-access data and models for detailed visual understanding. Advances in Neural Information Processing Systems 38, 23475–23537 (2026)
2026
-
[8]
arXiv preprint arXiv:2502.16427 (2025)
Chu, S., Seo, S., Han, B.: Fine-grained captioning of long videos through scene graph consolidation. arXiv preprint arXiv:2502.16427 (2025)
-
[9]
Deng, A., Cao, T., Chen, Z., Hooi, B.: Words or vision: Do vision-language mod- els have blind faith in text? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3867–3876 (2025)
2025
-
[10]
Dong, X., Zhang, P., Zang, Y., Cao, Y., Wang, B., Ouyang, L., Wei, X., Zhang, S., Duan, H., Cao, M., et al.: Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model. arXiv preprint arXiv:2401.16420 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision Work- shops
Fan, C.: Egovqa-an egocentric video question answering benchmark dataset. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision Work- shops. pp. 0–0 (2019)
2019
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
2025
-
[14]
Google: Gemini 2.0 flash,https://cloud.google.com/vertex-ai/generative- ai/docs/models/gemini/2-0-flash
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18995–19012 (2022) 16 A. Taluzzi et al
2022
-
[16]
Advances in Neural Information Processing Systems36, 72096–72109 (2023)
Huang, S., Dong, L., Wang, W., Hao, Y., Singhal, S., Ma, S., Lv, T., Cui, L., Mo- hammed, O.K., Patra, B., et al.: Language is not all you need: Aligning percep- tion with language models. Advances in Neural Information Processing Systems36, 72096–72109 (2023)
2023
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ji, J., Krishna, R., Fei-Fei, L., Niebles, J.C.: Action genome: Actions as compositions of spatio-temporal scene graphs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10236–10247 (2020)
2020
-
[18]
Advances in Neural Information Processing Systems35, 3343– 3360 (2022)
Jia, B., Lei, T., Zhu, S.C., Huang, S.: Egotaskqa: Understanding human tasks in egocentric videos. Advances in Neural Information Processing Systems35, 3343– 3360 (2022)
2022
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Krishna, R., Stark, M., Li, L.J., Shamma, D., Bernstein, M., Fei-Fei, L.: Image retrieval using scene graphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3668–3678 (2015)
2015
-
[20]
In: International conference on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International conference on machine learning. pp. 12888–12900. PMLR (2022)
2022
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, R., Zhang, S., Lin, D., Chen, K., He, X.: From pixels to graphs: Open- vocabulary scene graph generation with vision-language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 28076– 28086 (2024)
2024
-
[22]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llavanext: Improved reasoning, ocr, and world knowledge (2024)
2024
-
[23]
Llama, H.T.: Llama: open and efficient foundation language models. arXiv preprint arXiv:2407.21783 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12585–12602 (2024)
2024
-
[25]
Advances in Neural Information Pro- cessing Systems36, 46212–46244 (2023)
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Pro- cessing Systems36, 46212–46244 (2023)
2023
-
[26]
In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies
Mao, J., Jiang, W., Wang, X., Feng, Z., Lyu, Y., Liu, H., Zhu, Y.: Dynamic multistep reasoning based on video scene graph for video question answering. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies. pp. 3894–3904 (2022)
2022
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nagarajan, T., Li, Y., Feichtenhofer, C., Grauman, K.: Ego-topo: Environment af- fordances from egocentric video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 163–172 (2020)
2020
-
[28]
OpenAI: GPT-4 Technical Report. Tech. rep., OpenAI (2023),https://cdn. openai.com/papers/gpt-4.pdf
2023
-
[29]
OpenAI: GPT-4V(ision) System Card. Tech. rep., OpenAI (2023),https://cdn. openai.com/papers/GPTV_System_Card.pdf
2023
-
[30]
OpenAI: Hello GPT-4o (2024),https://openai.com/index/hello-gpt-4o/
2024
-
[31]
arXiv preprint arXiv:2504.04550 (2025)
Patel, A., Chitalia, V., Yang, Y.: Advancing egocentric video question answering with multimodal large language models. arXiv preprint arXiv:2504.04550 (2025)
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Peddi, R., Saurabh, S., Shrivastava, A.A., Singla, P., Gogate, V.: Towards unbiased and robust spatio-temporal scene graph generation and anticipation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8648–8657 (2025)
2025
-
[33]
In: International Conference on Learning Representations
Peng,Z.,Wang,W.,Dong,L.,Hao,Y.,Huang,S.,Ma,S.,Ye,Q.,Wei,F.:Grounding multimodal large language models to the world. In: International Conference on Learning Representations. vol. 2024, pp. 51575–51598 (2024) Graph it first! 17
2024
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Perrett, T., Darkhalil, A., Sinha, S., Emara, O., Pollard, S., Parida, K.K., Liu, K., Gatti, P., Bansal, S., Flanagan, K., et al.: Hd-epic: A highly-detailed egocentric video dataset. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23901–23913 (2025)
2025
-
[35]
plizzari et al
Plizzari, C., Goletto, G., Furnari, A., Bansal, S., Ragusa, F., Farinella, G.M., Damen, D., Tommasi, T.: An outlook into the future of egocentric vision: C. plizzari et al. International Journal of Computer Vision132(11), 4880–4936 (2024)
2024
-
[36]
In: ProceedingsoftheComputerVisionandPatternRecognitionConference.pp.24129– 24138 (2025)
Plizzari,C.,Tonioni,A.,Xian,Y.,Kulshrestha,A.,Tombari,F.:Omniadeegotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos. In: ProceedingsoftheComputerVisionandPatternRecognitionConference.pp.24129– 24138 (2025)
2025
-
[37]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rai, N., Chen, H., Ji, J., Desai, R., Kozuka, K., Ishizaka, S., Adeli, E., Niebles, J.C.: Home action genome: Cooperative compositional action understanding. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11184–11193 (2021)
2021
- [38]
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rodin, I., Furnari, A., Min, K., Tripathi, S., Farinella, G.M.: Action scene graphs for long-form understanding of egocentric videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18622–18632 (2024)
2024
-
[40]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team,G.,Georgiev,P.,Lei,V.I.,Burnell,R.,Bai,L.,Gulati,A.,Tanzer,G.,Vincent, D., Pan, Z., Wang, S., et al.: Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Urooj,A.,Kuehne,H.,Wu,B.,Chheu,K.,Bousselham,W.,Gan,C.,Lobo,N.,Shah, M.: Learning situation hyper-graphs for video question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14879–14889 (2023)
2023
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative message passing. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5410–5419 (2017)
2017
-
[44]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Xu, M., Wu, M., Zhao, Y., Li, J.C.L., Ou, W.: Llava-spacesgg: Visual instruct tuning for open-vocabulary scene graph generation with enhanced spatial relations. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 6362–6372. IEEE (2025)
2025
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., Wang, P., Zhou, Z., Xie, B., Wang, Z., et al.: Egolife: Towards egocentric life assistant. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28885–28900 (2025)
2025
-
[46]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al.: Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Proceedings of the 31st ACM international conference on multimedia
Zhao, Y., Fei, H., Cao, Y., Li, B., Zhang, M., Wei, J., Zhang, M., Chua, T.S.: Constructing holistic spatio-temporal scene graph for video semantic role labeling. In: Proceedings of the 31st ACM international conference on multimedia. pp. 5281– 5291 (2023) 18 A. Taluzzi et al
2023
-
[49]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) Graph it first! 19 Table 4: Breakdown of common action prepositions in the generated EgoSGs. The table shows total counts,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
List up to 10 items, describing their location relative to other environment elements, and key visual traits
Environment Elements: Large and medium appliances, built-in storage structures (e.g., cabinets, drawers), work surfaces (e.g., counters, tables), and fixtures (e.g., sinks, wall-mounted switches). List up to 10 items, describing their location relative to other environment elements, and key visual traits
-
[51]
List up to 10 items, describing their initial position relative to environment elements or other known objects, and appearance or label
Dynamic Objects: Movable objects that the user interacts with during this clip and can be manipulated to change their location within the environment. List up to 10 items, describing their initial position relative to environment elements or other known objects, and appearance or label
-
[52]
List up to 15 relevant events
Events and Interactions: Key events and interactions the user performs in this clip, each with a timestamp. List up to 15 relevant events
-
[53]
–- [SCENE GRAPH OUTPUT FORMAT (see Fig
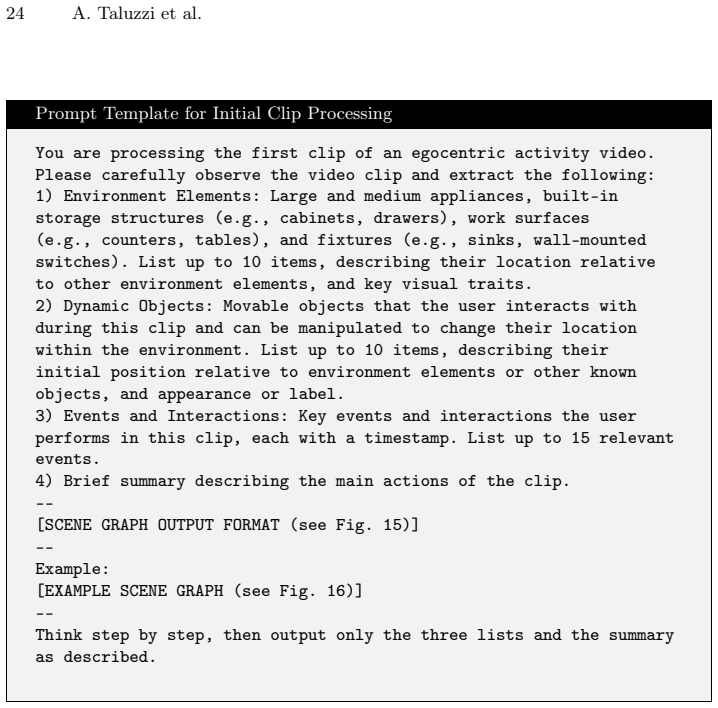
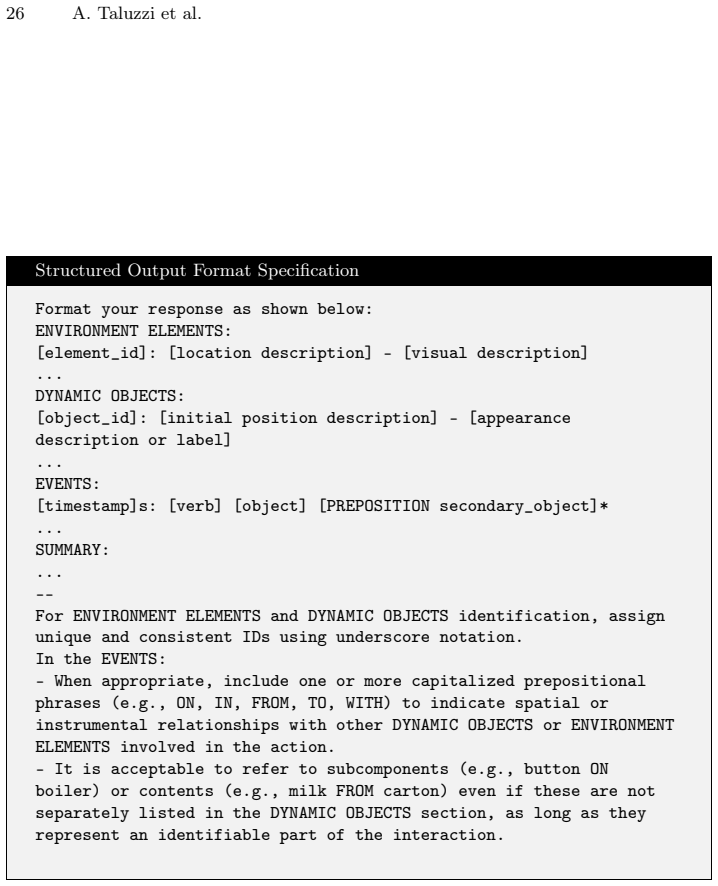
Brief summary describing the main actions of the clip. –- [SCENE GRAPH OUTPUT FORMAT (see Fig. 15)] –- Example: [EXAMPLE SCENE GRAPH (see Fig. 16)] –- Think step by step, then output only the three lists and the summary as described. Fig.13: Prompt template for processing the first clip in an egocentric video sequence.The template establishes the foundati...
-
[54]
NEW Environment Elements that were NOT previously listed. These are large and medium appliances, built-in storage structures (e.g., cabinets, drawers), work surfaces (e.g., counters, tables), and fixtures (e.g., sinks, wall-mounted switches). List up to 10 items, describing their location relative to other stationary objects, and key visual traits. Leave ...
-
[55]
These are movable objects that the user interacts with during this clip and can be manipulated to change their location within the environment
NEW Dynamic Objects that were NOT previously listed. These are movable objects that the user interacts with during this clip and can be manipulated to change their location within the environment. List up to 10 items, describing their initial position relative to environment elements or other known objects, and appearance or label. Leave this section empt...
-
[56]
List up to 15 relevant events
Events and Interactions: Key events and interactions the user performs in this clip, each with a timestamp. List up to 15 relevant events. You may reference IDs from previous Environment Elements and Dynamic Objects where appropriate
-
[57]
Green Tea
Brief summary describing the main actions of the current clip. –- [SCENE GRAPH OUTPUT FORMAT (see Fig. 15)] –- Think step by step, then output only the three lists and the summary as described. Fig.14: Prompt template for processing clips from the second on, using accu- mulated context from all previous clips while managing prompt length through selective...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.