Multi-Agent Goal Recognition with Team- and Goal-Conditioned Reinforcement Learning and Factorized Branch-and-Bound
Pith reviewed 2026-06-25 18:58 UTC · model grok-4.3
The pith
MAGR-BB matches exhaustive search top hypothesis in multi-agent goal recognition while evaluating orders of magnitude fewer options.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
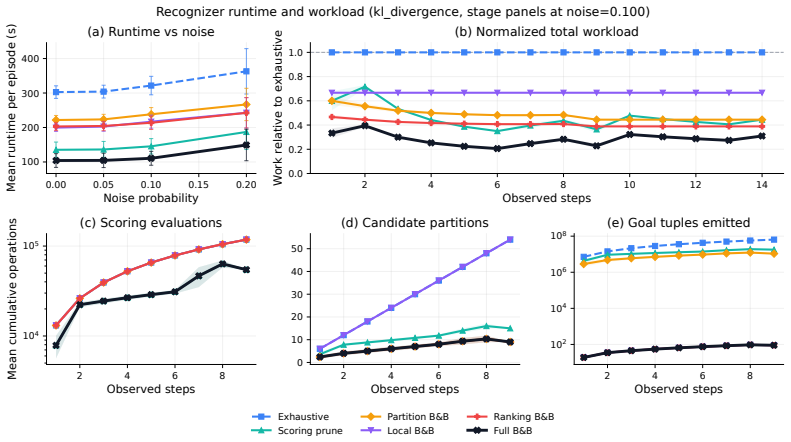
MAGR-BB addresses multi-agent goal recognition by using a shared team- and goal-conditioned policy as the scoring model inside a factorized branch-and-bound search, returning the same top-ranked hypothesis as exhaustive search throughout the trajectory on a controlled multi-agent Blocksworld benchmark while cutting hypothesis materialization by orders of magnitude and reducing cumulative recognition runtime substantially.
What carries the argument
factorized branch-and-bound search guided by a shared team- and goal-conditioned reinforcement learning policy used as the scoring model
Load-bearing premise
A single shared team- and goal-conditioned RL policy supplies accurate enough and consistent enough scores to guarantee the identical top-ranked hypothesis as exhaustive enumeration across every timestep of the chosen benchmark trajectories.
What would settle it
A multi-agent Blocksworld trajectory where the top-ranked team-goal hypothesis returned by MAGR-BB differs from the one returned by exhaustive enumeration at any point along the sequence.
Figures
read the original abstract
Multi-agent goal recognition asks an observer to jointly infer which agents act together and what each team is trying to achieve, so the hypothesis space grows combinatorially with the number of team partitions and goals per team. Real applications such as drone surveillance and collaborative robotics expose only the agents' trajectory, which forces the observer to rank team-goal hypotheses from behavior alone. Multi-Agent Goal Recognition with Branch-and-Bound (MAGR-BB) addresses this setting with a shared team- and goal-conditioned policy used as the scoring model inside a factorized branch-and-bound search. On a controlled multi-agent Blocksworld benchmark, MAGR-BB returns the same top-ranked hypothesis as exhaustive search throughout the trajectory while cutting hypothesis materialization by orders of magnitude and reducing cumulative recognition runtime substantially.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MAGR-BB, a method for multi-agent goal recognition that employs a shared team- and goal-conditioned reinforcement learning policy as the scoring model inside a factorized branch-and-bound search. The central empirical claim, evaluated on a controlled multi-agent Blocksworld benchmark, is that MAGR-BB recovers the identical top-ranked hypothesis as exhaustive search at every step along the trajectory while materializing orders of magnitude fewer hypotheses and substantially reducing cumulative recognition runtime.
Significance. If the reported equivalence to exhaustive enumeration holds on the evaluated instances, the work demonstrates a practical way to address the combinatorial explosion in joint team-partition and goal hypotheses for goal recognition from trajectories alone. The combination of RL-based scoring with factorized search is technically interesting and could support applications such as surveillance or collaborative robotics, provided the approach generalizes beyond the specific benchmark.
minor comments (2)
- The abstract asserts equivalence and efficiency gains but does not report the number of benchmark instances evaluated, any measures of statistical significance, error rates, or ablation results on the RL policy; these details are needed to substantiate the central empirical claim even if present in later sections.
- Clarify how the factorized branch-and-bound avoids materializing full hypotheses during pruning and whether the RL policy is trained on the same distribution of team-goal combinations used at test time.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of MAGR-BB and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper trains a shared team- and goal-conditioned RL policy separately and deploys it as a scoring function inside a factorized branch-and-bound search. The central empirical claim is that this combination recovers the identical top-ranked hypothesis as exhaustive enumeration on the reported Blocksworld instances while materializing far fewer hypotheses. No equation or step reduces the reported outcome to a definitional identity, a fitted parameter renamed as a prediction, or a self-citation chain that forces the result by construction. The equivalence to exhaustive search is presented as an experimental observation on controlled benchmarks rather than a logical necessity derived from the method's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Allen, James F
Kautz, Henry A. and Allen, James F. , booktitle =. Generalized plan recognition , year =
-
[2]
, booktitle =
Geib, Christopher W. , booktitle =. Problems with Intent Recognition for Elder Care , year =
-
[3]
Automated Planning: Theory & Practice , year =
Nau, Dana and Ghallab, Malik and Traverso, Paolo , publisher =. Automated Planning: Theory & Practice , year =
-
[6]
Proceedings of the 21st International Joint Conference on Artificial Intelligence , title =
Ram\'. Proceedings of the 21st International Joint Conference on Artificial Intelligence , title =. 2009 , address =
2009
-
[7]
and Dang, Viet Dung and Jennings, Nicholas R
Rahwan, Talal and Ramchurn, Sarvapali D. and Dang, Viet Dung and Jennings, Nicholas R. , booktitle =. Near-optimal anytime coalition structure generation , year =
-
[11]
Action-Model Based Multi-agent Plan Recognition , year =
Zhuo, Hankz and Yang, Qiang and Kambhampati, Subbarao , booktitle =. Action-Model Based Multi-agent Plan Recognition , year =
-
[12]
Sturtevant, N. R. , journal =. Benchmarks for Grid-Based Pathfinding , year =. doi:10.1109/tciaig.2012.2197681 , publisher =
-
[13]
A Concise Introduction to Models and Methods for Automated Planning: Synthesis Lectures on Artificial Intelligence and Machine Learning , year =
Geffner, Hector and Bonet, Blai , publisher =. A Concise Introduction to Models and Methods for Automated Planning: Synthesis Lectures on Artificial Intelligence and Machine Learning , year =
-
[14]
, publisher =
Sukthankar, Gita and Geib, Christopher and Bui, Hung Hai and Pynadath, David and Goldman, Robert P. , publisher =. Plan, Activity, and Intent Recognition: Theory and Practice , year =
-
[17]
Proceedings of the 26th Annual International Conference on Machine Learning , title =
Bengio, Yoshua and Louradour, J. Proceedings of the 26th Annual International Conference on Machine Learning , title =. 2009 , pages =
2009
-
[18]
Asynchronous Methods for Deep Reinforcement Learning , booktitle =
Mnih, Volodymyr and Badia, Adri. Asynchronous Methods for Deep Reinforcement Learning , booktitle =. 2016 , editor =
2016
-
[19]
Proximal Policy Optimization Algorithms
Schulman, John and Wolski, Filip and Dhariwal, Prafulla and Radford, Alec and Klimov, Oleg , title =. 2017 , copyright =. doi:10.48550/ARXIV.1707.06347 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[20]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , year =
Lowe, Ryan and Wu, Yi and Tamar, Aviv and Harb, Jean and Abbeel, Pieter and Mordatch, Igor , booktitle =. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , year =
-
[21]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , publisher =. Reinforcement Learning: An Introduction , year =
-
[23]
New Goal Recognition Algorithms Using Attack Graphs , year =
Mirsky, Reuth and Shalom, Ya'ar and Majadly, Ahmad and Gal, Kobi and Puzis, Rami and Felner, Ariel , pages =. New Goal Recognition Algorithms Using Attack Graphs , year =. Cyber Security Cryptography and Machine Learning , doi =
-
[26]
and Swaminathan, Chittaranjan S
Rudenko, Andrey and Kucner, Tomasz P. and Swaminathan, Chittaranjan S. and Chadalavada, Ravi T. and Arras, Kai O. and Lilienthal, Achim J. , journal =. 2020 , number =. doi:10.1109/LRA.2020.2965416 , groups =
-
[29]
and Brewitt, Cillian and Wilhelm, John and Gyevnar, Balint and Eiras, Francisco and Dobre, Mihai and Ramamoorthy, Subramanian , booktitle =
Albrecht, Stefano V. and Brewitt, Cillian and Wilhelm, John and Gyevnar, Balint and Eiras, Francisco and Dobre, Mihai and Ramamoorthy, Subramanian , booktitle =. Interpretable Goal-based Prediction and Planning for Autonomous Driving , year =
-
[30]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning , year =
Li, Quanyi and Peng, Zhenghao and Feng, Lan and Zhang, Qihang and Xue, Zhenghai and Zhou, Bolei , journal =. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning , year =
-
[32]
Universal Value Function Approximators , year =
Schaul, Tom and Horgan, Dan and Gregor, Karol and Silver, David , booktitle =. Universal Value Function Approximators , year =
-
[33]
Goal-Conditioned Reinforcement Learning: Problems and Solutions , year =
Liu, Minghuan and Zhu, Menghui and Zhang, Weinan , booktitle =. Goal-Conditioned Reinforcement Learning: Problems and Solutions , year =
-
[37]
Albrecht and Filippos Christianos and Lukas Sch\"afer , publisher =
Stefano V. Albrecht and Filippos Christianos and Lukas Sch\"afer , publisher =. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches , year =
-
[38]
and Kaiser, Lukasz and Polosukhin, Illia , booktitle =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , booktitle =. Attention Is All You Need , year =
-
[40]
Meng Feng and Viraj Parimi and Brian Williams , title =. 2025 , archiveprefix =. 2502.17813 , groups =
arXiv 2025
-
[42]
and Iocchi, L
Farinelli, A. and Iocchi, L. and Nardi, D. , journal =. Multirobot Systems: A Classification Focused on Coordination , year =
-
[44]
Mohamed Abdelkader, Samet G \"u ler, Hassan Jaleel, and Jeff S. Shamma. Aerial swarms: Recent applications and challenges. Current Robotics Reports, 2 0 (3): 0 309--320, 2021. ISSN 2662-4087. doi:10.1007/s43154-021-00063-4. URL https://doi.org/10.1007/s43154-021-00063-4
-
[45]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Stefano V. Albrecht, Cillian Brewitt, John Wilhelm, Balint Gyevnar, Francisco Eiras, Mihai Dobre, and Subramanian Ramamoorthy. Interpretable goal-based prediction and planning for autonomous driving. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1043--1049. IEEE, May 2021. doi:10.1109/icra48506.2021.9560849
-
[46]
Albrecht, Filippos Christianos, and Lukas Sch\"afer
Stefano V. Albrecht, Filippos Christianos, and Lukas Sch\"afer. Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024. URL https://www.marl-book.com
2024
-
[47]
Goal recognition as reinforcement learning
Leonardo Amado, Reuth Mirsky, and Felipe Meneguzzi. Goal recognition as reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, 36 0 (9): 0 9644--9651, Jun. 2022. doi:10.1609/aaai.v36i9.21198. URL https://ojs.aaai.org/index.php/AAAI/article/view/21198
-
[48]
A survey on model-free goal recognition
Leonardo Amado, Sveta Paster Shainkopf, Ramon Fraga Pereira, Reuth Mirsky, and Felipe Meneguzzi. A survey on model-free goal recognition. In Kate Larson, editor, Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24 , pages 7923--7931. International Joint Conferences on Artificial Intelligence Organization, 8 ...
-
[49]
Multi-agent plan recognition as planning (maprap)
Chris Argenta and Jon Doyle. Multi-agent plan recognition as planning (maprap). In Proceedings of the 8th International Conference on Agents and Artificial Intelligence - Volume 2: ICAART,, pages 141--148. INSTICC, SciTePress, 2016. ISBN 978-989-758-172-4. doi:10.5220/0005707701410148
-
[50]
Chris Argenta and Jon Doyle. Probabilistic multi-agent plan recognition as planning (p-maprap): Recognizing teams, goals, and plans from action sequences. In Proceedings of the 9th International Conference on Agents and Artificial Intelligence - Volume 2: ICAART,, pages 575--582. INSTICC, SciTePress, 2017. ISBN 978-989-758-220-2. doi:10.5220/0006197505750582
-
[51]
Multi-agent plan recognition: Formalization and algorithms
Bikramjit Banerjee, Landon Kraemer, and Jeremy Lyle. Multi-agent plan recognition: Formalization and algorithms. Proceedings of the AAAI Conference on Artificial Intelligence, 24 0 (1): 0 1059--1064, Jul. 2010. doi:10.1609/aaai.v24i1.7746. URL https://ojs.aaai.org/index.php/AAAI/article/view/7746
-
[52]
Yoshua Bengio, J \'e r \^o me Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, pages 41--48. ACM, 2009. doi:10.1145/1553374.1553380
-
[53]
Goal recognition as a deep learning task: The grnet approach
Mattia Chiari, Alfonso Emilio Gerevini, Francesco Percassi, Luca Putelli, Ivan Serina, and Matteo Olivato. Goal recognition as a deep learning task: The grnet approach. Proceedings of the International Conference on Automated Planning and Scheduling, 33 0 (1): 0 560--568, July 2023. ISSN 2334-0835. doi:10.1609/icaps.v33i1.27237
-
[54]
Multi-agent intention recognition and progression
Michael Dann, Yuan Yao, Natasha Alechina, Brian Logan, Felipe Meneguzzi, and John Thangarajah. Multi-agent intention recognition and progression. In Edith Elkind, editor, Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23 , pages 91--99. International Joint Conferences on Artificial Intelligence Organizati...
-
[55]
Prediction of intent in robotics and multi-agent systems
Yiannis Demiris. Prediction of intent in robotics and multi-agent systems. Cognitive Processing, 8 0 (3): 0 151--158, May 2007. ISSN 1612-4790. doi:10.1007/s10339-007-0168-9
-
[56]
Real-time online goal recognition in continuous domains via deep reinforcement learning
Zihao Fang, Dejun Chen, Yunxiu Zeng, Tao Wang, and Kai Xu. Real-time online goal recognition in continuous domains via deep reinforcement learning. Entropy, 25 0 (10): 0 1415, October 2023. ISSN 1099-4300. doi:10.3390/e25101415
-
[57]
A. Farinelli, L. Iocchi, and D. Nardi. Multirobot systems: A classification focused on coordination. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 34 0 (5): 0 2015--2028, 2004. doi:10.1109/TSMCB.2004.832155
-
[58]
A Concise Introduction to Models and Methods for Automated Planning: Synthesis Lectures on Artificial Intelligence and Machine Learning
Hector Geffner and Blai Bonet. A Concise Introduction to Models and Methods for Automated Planning: Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers, 1st edition, 2013. ISBN 1608459691
2013
-
[59]
Christopher W. Geib and Robert P. Goldman. A probabilistic plan recognition algorithm based on plan tree grammars. Artificial Intelligence, 173 0 (11): 0 1101--1132, 2009. ISSN 0004-3702. doi:https://doi.org/10.1016/j.artint.2009.01.003. URL https://www.sciencedirect.com/science/article/pii/S0004370209000459
-
[60]
Kautz and James F
Henry A. Kautz and James F. Allen. Generalized plan recognition. In Proceedings of the Fifth AAAI National Conference on Artificial Intelligence, AAAI'86, pages 32--37. AAAI Press, 1986
1986
-
[61]
E. L. Lawler and D. E. Wood. Branch-and-bound methods: A survey. Operations Research, 14 0 (4): 0 699--719, 1966. ISSN 0030364X, 15265463. doi:10.1287/opre.14.4.699. URL http://www.jstor.org/stable/168733
-
[62]
Goal-conditioned reinforcement learning: Problems and solutions
Minghuan Liu, Menghui Zhu, and Weinan Zhang. Goal-conditioned reinforcement learning: Problems and solutions. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-2022, pages 5502--5511. International Joint Conferences on Artificial Intelligence Organization, July 2022. doi:10.24963/ijcai.2022/770
-
[63]
Multi-agent actor-critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30, pages 6379--6390. Curran Associates, Inc., ...
2017
-
[64]
A survey on goal recognition as planning
Felipe Meneguzzi and Ramon Fraga Pereira. A survey on goal recognition as planning. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21 , pages 4524--4532. International Joint Conferences on Artificial Intelligence Organization, 8 2021. doi:10.24963/ijcai.2021/616. URL https://doi.org/1...
-
[65]
New Goal Recognition Algorithms Using Attack Graphs, pages 260--278
Reuth Mirsky, Ya'ar Shalom, Ahmad Majadly, Kobi Gal, Rami Puzis, and Ariel Felner. New Goal Recognition Algorithms Using Attack Graphs, pages 260--278. Springer International Publishing, 2019. ISBN 9783030209513. doi:10.1007/978-3-030-20951-3_23
-
[66]
Reuth Mirsky, Sarah Keren, and Christopher W. Geib. Introduction to Symbolic Plan and Goal Recognition. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers, 2021. doi:10.2200/S01062ED1V01Y202012AIM047. URL https://doi.org/10.2200/S01062ED1V01Y202012AIM047
-
[67]
Automated Planning: Theory & Practice
Dana Nau, Malik Ghallab, and Paolo Traverso. Automated Planning: Theory & Practice. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2004. ISBN 1558608567
2004
-
[68]
Landmark-based approaches for goal recognition as planning
Ramon Fraga Pereira, Nir Oren, and Felipe Meneguzzi. Landmark-based approaches for goal recognition as planning. Artificial Intelligence, 279: 0 103217, February 2020. ISSN 0004-3702. doi:10.1016/j.artint.2019.103217
-
[69]
Ramchurn, Viet Dung Dang, and Nicholas R
Talal Rahwan, Sarvapali D. Ramchurn, Viet Dung Dang, and Nicholas R. Jennings. Near-optimal anytime coalition structure generation. In Proceedings of the 20th International Joint Conference on Artificial Intelligence, IJCAI'07, pages 2365--2371, San Francisco, CA, USA, 2007. Morgan Kaufmann Publishers Inc
2007
-
[70]
Probabilistic plan recognition using off-the-shelf classical planners
Miguel Ram \'i rez and Hector Geffner. Probabilistic plan recognition using off-the-shelf classical planners. Proceedings of the AAAI Conference on Artificial Intelligence, 24 0 (1): 0 1121--1126, Jul. 2010. doi:10.1609/aaai.v24i1.7745. URL https://ojs.aaai.org/index.php/AAAI/article/view/7745
-
[71]
Plan recognition as planning
Miquel Ram\' rez and Hector Geffner. Plan recognition as planning. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, IJCAI'09, pages 1778--1783, San Francisco, CA, USA, 2009. Morgan Kaufmann Publishers Inc
2009
-
[72]
Universal value function approximators
Tom Schaul, Dan Horgan, Karol Gregor, and David Silver. Universal value function approximators. In Francis Bach and David Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 1312--1320. PMLR, 2015. URL https://proceedings.mlr.press/v37/schaul15.html
2015
-
[73]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
2017
-
[74]
Combining gaze and ai planning for online human intention recognition
Ronal Singh, Tim Miller, Joshua Newn, Eduardo Velloso, Frank Vetere, and Liz Sonenberg. Combining gaze and ai planning for online human intention recognition. Artificial Intelligence, 284: 0 103275, 2020. ISSN 0004-3702. doi:https://doi.org/10.1016/j.artint.2020.103275. URL https://www.sciencedirect.com/science/article/pii/S0004370218307628
-
[75]
Blocks World revisited , journal =
John Slaney and Sylvie Thi\' e baux. Blocks W orld revisited. Artificial Intelligence, 125 0 (1--2): 0 119--153, 2001. ISSN 0004-3702. doi:10.1016/S0004-3702(00)00079-5
-
[76]
Gita Sukthankar, Christopher Geib, Hung Hai Bui, David Pynadath, and Robert P. Goldman. Plan, Activity, and Intent Recognition: Theory and Practice. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1st edition, 2014. ISBN 0123985323
2014
-
[77]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30, pages 5998--6008. Curran Associates, I...
2017
-
[78]
Action-model based multi-agent plan recognition
Hankz Zhuo, Qiang Yang, and Subbarao Kambhampati. Action-model based multi-agent plan recognition. In F. Pereira, C.J. Burges, L. Bottou, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012. URL https://proceedings.neurips.cc/paper_files/paper/2012/file/a597e50502f5ff68e3e25b9114205d4a-...
2012
-
[79]
Recognizing multi-agent plans when action models and team plans are both incomplete
Hankz Hankui Zhuo. Recognizing multi-agent plans when action models and team plans are both incomplete. ACM Trans. Intell. Syst. Technol., 10 0 (3), may 2019. ISSN 2157-6904. doi:10.1145/3319403. URL https://doi.org/10.1145/3319403
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.