CascadeFormer: Depth-Tapered Transformers Motivated by Gradient Fan-in Asymmetry
Pith reviewed 2026-06-26 05:20 UTC · model grok-4.3
The pith
Depth-tapered Transformers match uniform perplexity while cutting latency 8.6 percent by aligning width to decaying gradient fan-in.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
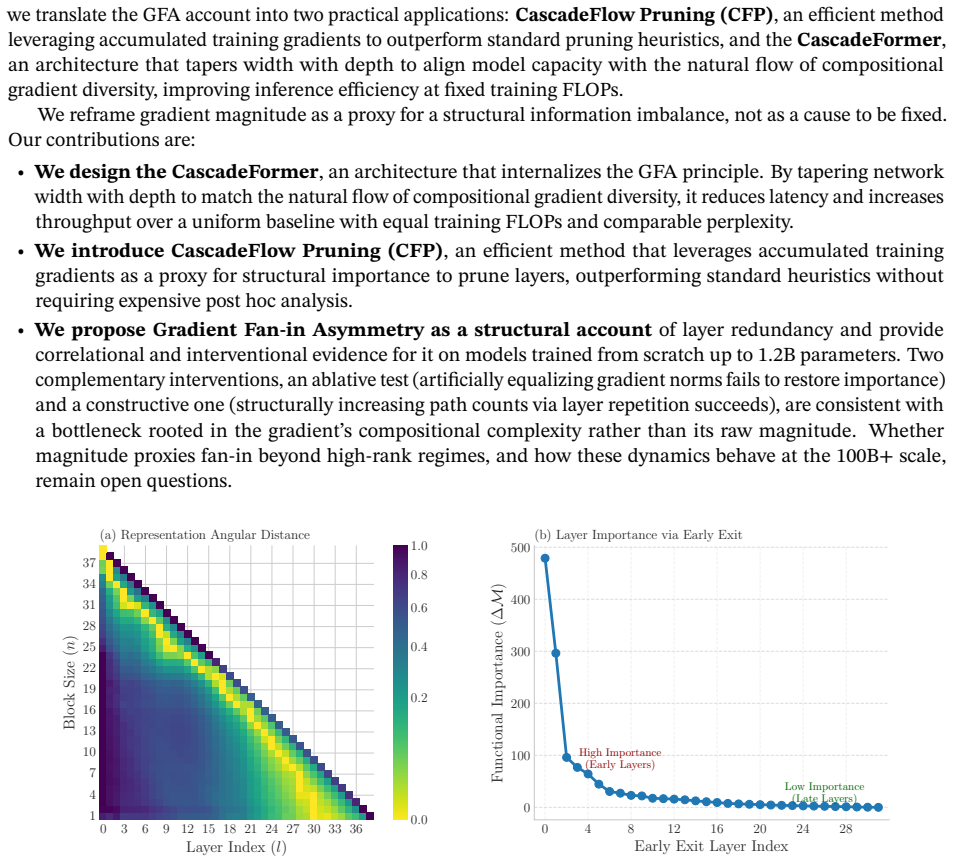
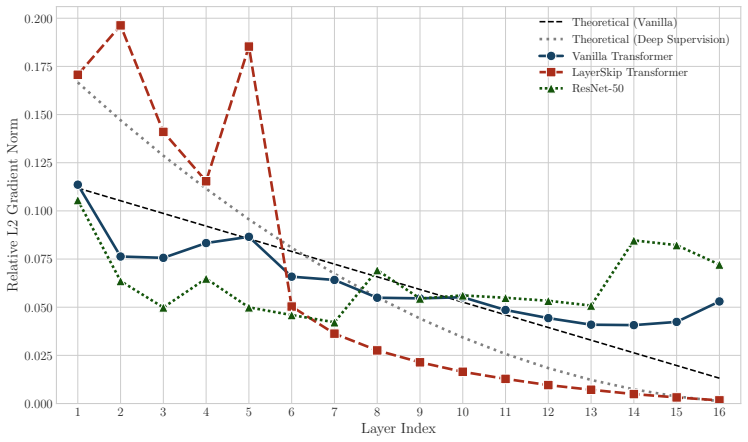
In Pre-LayerNorm residual stacks the gradient at a layer is the sum of an identity path and all downstream functional paths, so gradient fan-in decays linearly with depth (quadratically under deep supervision) and yields richer gradients for early layers than for late ones; tapering width to match this asymmetry preserves functional capacity at lower compute cost.
What carries the argument
Gradient Fan-in Asymmetry: the linear decay of per-layer gradient fan-in caused by accumulating residual paths in Pre-LayerNorm stacks.
If this is right
- Tapered-width models achieve the same perplexity with fewer total parameters in the later layers.
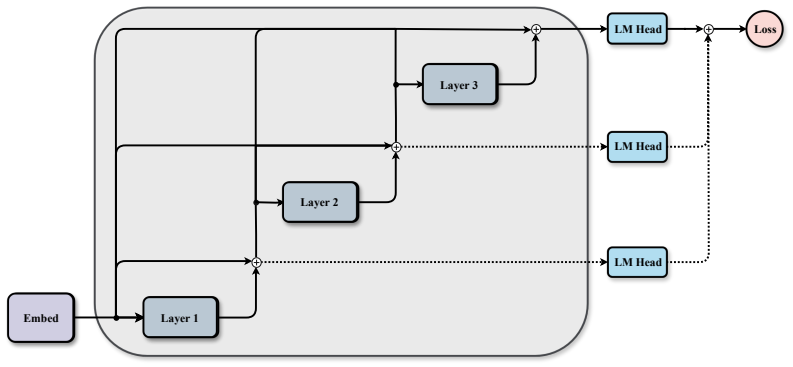
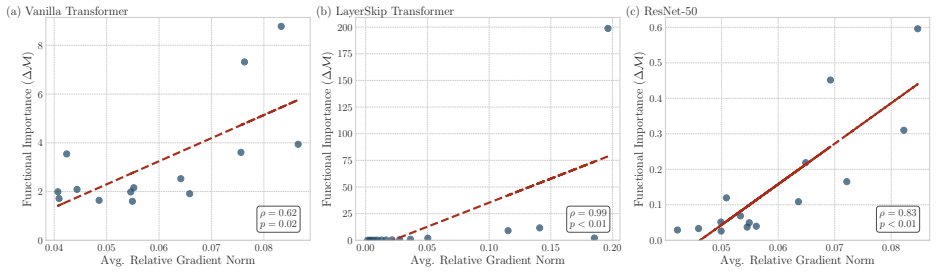
- Accumulated-gradient pruning removes layers without post-hoc analysis and outperforms magnitude or random baselines on both perplexity and rank stability.
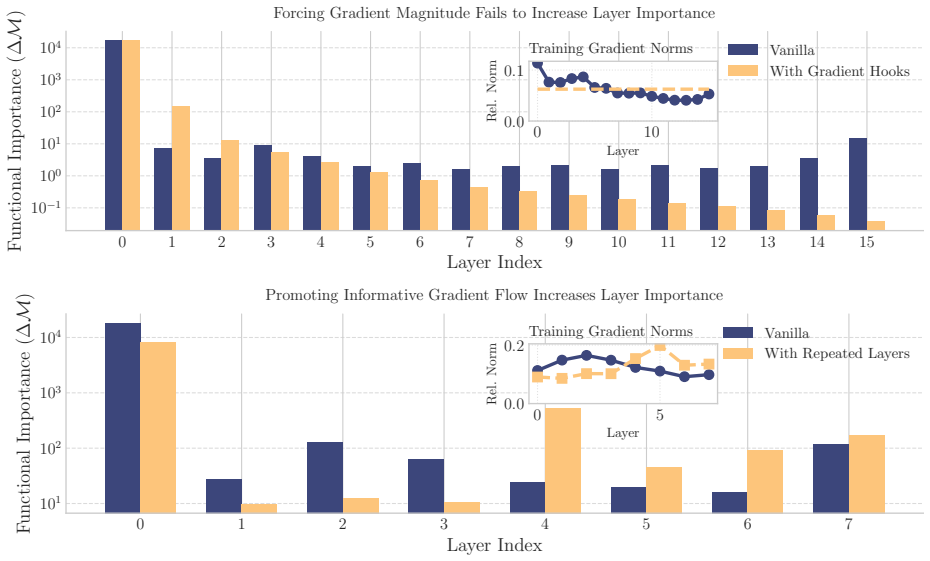
- Equalizing per-layer gradient norms does not restore late-layer value, while increasing downstream path counts via shared repetition does.
- The same fan-in decay pattern appears in both Transformers and ResNets trained from scratch.
Where Pith is reading between the lines
- The tapering schedule could be derived directly from the closed-form fan-in formula rather than hand-tuned.
- At 100 B+ scale the relative importance of fan-in versus other optimization effects may shift, offering a natural test of whether the linear decay remains dominant.
- Similar width tapering may improve efficiency in non-Transformer residual stacks whose gradient accumulation follows the same identity-plus-downstream structure.
Load-bearing premise
The linear decay of gradient fan-in with depth is the main structural reason later layers add less value, rather than a side effect of optimization or data statistics, and that width tapering preserves capacity without further training changes.
What would settle it
A controlled experiment that equalizes gradient fan-in across depths by adding artificial downstream paths yet still finds late layers underperform would falsify the claim that fan-in asymmetry is the primary bottleneck.
Figures
read the original abstract
Deep Transformers are composed of uniformly stacked residual blocks, yet their deepest layers often add little value. We present two efficiency methods that exploit this asymmetry. CascadeFormer tapers width with depth to match the uneven information flow across layers, achieving comparable perplexity to a uniform baseline at the same training budget while reducing latency by 8.6% and increasing throughput by 9.4%. CascadeFlow Pruning removes layers using accumulated training gradients, with no post hoc analysis. It outperforms standard heuristics on perplexity and rank-stability and stays competitive on downstream accuracy. To motivate these methods, we propose Gradient Fan-in Asymmetry (GFA) as a structural account of why deeper layers contribute less. In Pre-LayerNorm residual stacks, the gradient at a layer is the sum of an identity path and all downstream functional paths, producing a gradient fan-in that decays linearly with depth (and quadratically under deep supervision), yielding richer gradients for early layers and sparser ones for later layers. We provide correlational and interventional evidence for GFA on models trained from scratch up to 1.2B parameters. Across Transformers and ResNets, accumulated training gradients follow the theoretical fan-in and are associated with post hoc layer importance. Two interventions point to structure rather than magnitude as the bottleneck: equalizing per-layer gradient norms does not restore late-layer value, while increasing downstream path counts via parameter-shared repetition restores and elevates it. Whether gradient magnitude proxies fan-in beyond high-rank regimes, and how these dynamics behave at the 100B+ scale, remain open questions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Gradient Fan-in Asymmetry (GFA) as a structural explanation for reduced contribution of deeper layers in Pre-LayerNorm residual Transformers: the gradient at layer l is the sum of an identity path plus all downstream functional paths, yielding linear decay in fan-in (quadratic under deep supervision). It proposes two applications: CascadeFormer, which tapers width with depth to align with this asymmetry, and CascadeFlow Pruning, which removes layers using accumulated training gradients. On models up to 1.2B parameters, CascadeFormer matches uniform-baseline perplexity at fixed training budget while cutting latency 8.6% and raising throughput 9.4%; pruning outperforms standard heuristics on perplexity and rank stability. Evidence combines correlational matches between theoretical fan-in and measured gradients with two interventions (norm equalization vs. path-count increase via shared repetition).
Significance. If the central claim holds, the work supplies a parameter-free, derivation-driven motivation for non-uniform depth scaling that directly improves practical efficiency metrics without extra training cost. Strengths include the direct derivation from residual additive structure, the dual correlational-plus-interventional tests that separate structure from magnitude, and the explicit efficiency numbers at 1.2B scale. These elements could influence architecture search and pruning pipelines if the GFA-to-taper mapping generalizes.
major comments (2)
- [§5] §5 (Experiments on CascadeFormer): the claim of 'comparable perplexity' at identical training budget rests on point estimates without reported standard deviations, multiple random seeds, or statistical tests; this directly affects whether the 8.6% latency / 9.4% throughput gains can be treated as reliable rather than within-run variance.
- [§4.1] §4.1 (CascadeFormer width schedule): the linear width taper is motivated by the GFA derivation, yet the manuscript does not report an ablation that varies the taper slope while holding total parameter count fixed; without this, it remains open whether the observed efficiency stems from the specific GFA-derived schedule or from any monotonic reduction in late-layer width.
minor comments (3)
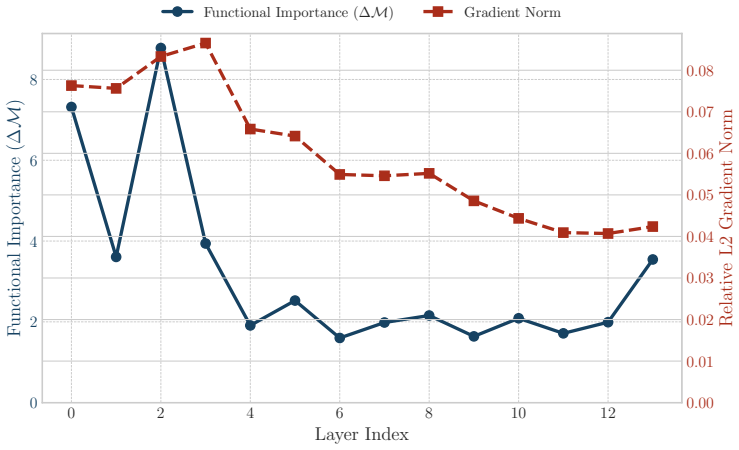
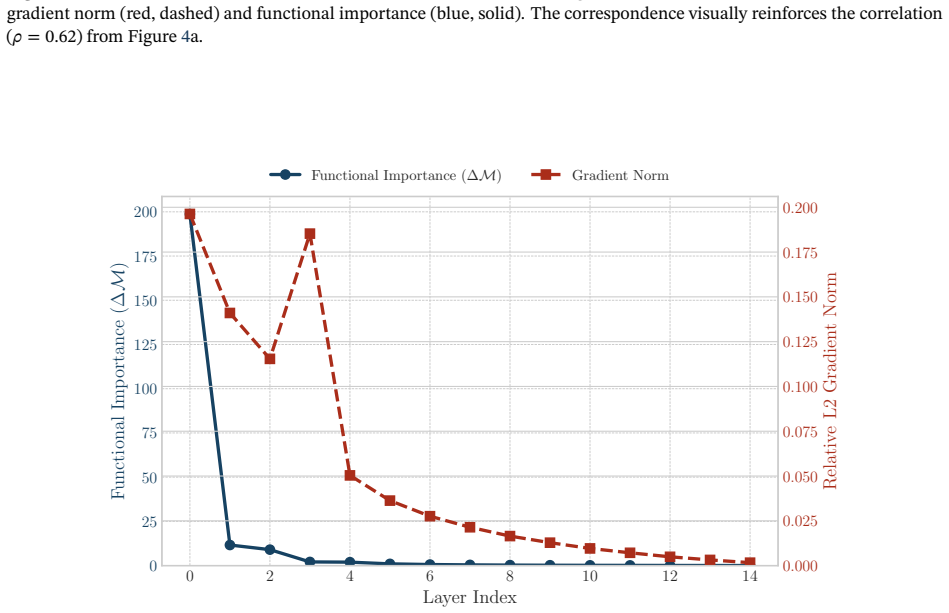
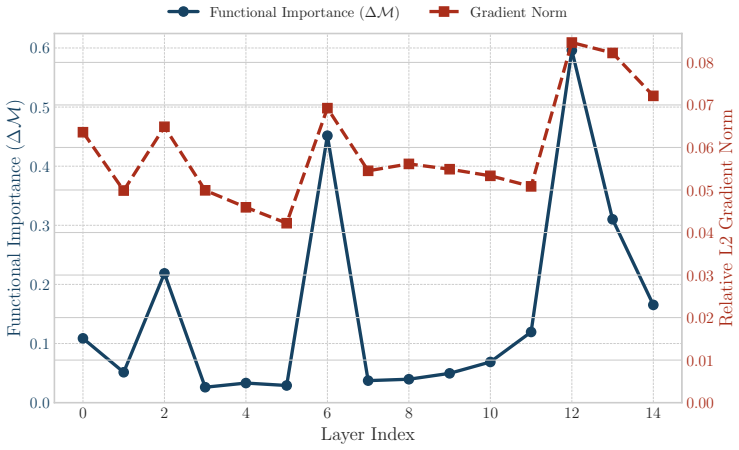
- [Figure 3] Figure 3 caption and axis labels should explicitly state whether the plotted 'accumulated gradient' is the L2 norm of the gradient vector or its mean absolute value; the distinction matters for comparing to the theoretical fan-in formula.
- [Eq. (3)] The notation for downstream path count in Eq. (3) uses an implicit summation index that is not restated in the surrounding text; adding an explicit definition would improve readability.
- [§4.2] The pruning section references 'standard heuristics' but does not cite the specific methods (e.g., magnitude pruning, movement pruning) used as baselines; adding those citations would clarify the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical rigor and ablation requirements. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5] §5 (Experiments on CascadeFormer): the claim of 'comparable perplexity' at identical training budget rests on point estimates without reported standard deviations, multiple random seeds, or statistical tests; this directly affects whether the 8.6% latency / 9.4% throughput gains can be treated as reliable rather than within-run variance.
Authors: We agree that single-run point estimates limit the reliability of the claims. In the revised manuscript we will rerun the 1.2B-scale CascadeFormer experiments with at least three random seeds, report means and standard deviations for perplexity and efficiency metrics, and include statistical tests comparing against the uniform baseline. revision: yes
-
Referee: [§4.1] §4.1 (CascadeFormer width schedule): the linear width taper is motivated by the GFA derivation, yet the manuscript does not report an ablation that varies the taper slope while holding total parameter count fixed; without this, it remains open whether the observed efficiency stems from the specific GFA-derived schedule or from any monotonic reduction in late-layer width.
Authors: The GFA derivation supplies an explicit linear functional form for the width schedule. We nevertheless acknowledge that an explicit ablation isolating this form from other monotonic tapers would strengthen the causal link. We will add such an ablation (fixed total parameters, varied slopes) to the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives Gradient Fan-in Asymmetry directly from the additive structure of Pre-LayerNorm residual connections, where the gradient at each layer is the sum of an identity path plus all downstream functional paths. This produces the stated linear decay with depth as a mathematical consequence of the architecture itself, without reference to fitted parameters, self-citations, or the target tapering method. Correlational checks (accumulated gradients tracking the derived fan-in) and interventional tests (norm equalization vs. path-count repetition) are presented as independent evidence rather than tautological restatements. CascadeFormer applies the derived asymmetry to width tapering but does not redefine or fit the fan-in quantity to the outcome metrics. No load-bearing steps reduce to self-definition, renaming, or author-specific uniqueness claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In Pre-LayerNorm residual stacks, the gradient at a layer is the sum of an identity path and all downstream functional paths, producing linear decay with depth.
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://papers.nips.cc/paper/2020/hash/1...
2020
-
[2]
Tianyi Chen, Tianyu Ding, Badal Yadav, Ilya Zharkov, and Luming Liang. 2023. https://doi.org/10.48550/arXiv.2310.18356 LoRAShear : Efficient Large Language Model Structured Pruning and Knowledge Recovery . arXiv preprint. ArXiv:2310.18356 [cs]
-
[3]
Xiaodong Chen, Yuxuan Hu, Jing Zhang, Yanling Wang, Cuiping Li, and Hong Chen. 2025. https://doi.org/10.48550/arXiv.2403.19135 Streamlining Redundant Layers to Compress Large Language Models . arXiv preprint. ArXiv:2403.19135 [cs]
-
[4]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. https://doi.org/10.1109/CVPR.2009.5206848 ImageNet : A large-scale hierarchical image database . In 2009 IEEE Conference on Computer Vision and Pattern Recognition , pages 248--255. ISSN: 1063-6919
-
[5]
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. 2024. https://doi.org/10.18653/v1/2024.acl-long.681 LayerSkip : Enabling Early Exit Inference and Self - Speculative Decoding . In Proceedings of the 62nd Annual ...
-
[6]
Angela Fan, Edouard Grave, and Armand Joulin. 2020. https://openreview.net/forum?id=SylO2yStDr Reducing transformer depth on demand with structured dropout . In International Conference on Learning Representations
2020
-
[7]
Elias Frantar and Dan Alistarh. 2023. https://doi.org/10.48550/arXiv.2301.00774 SparseGPT : Massive Language Models Can Be Accurately Pruned in One - Shot . arXiv preprint. ArXiv:2301.00774 [cs]
-
[8]
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Dan Roberts. 2024. https://openreview.net/forum The Unreasonable Ineffectiveness of the Deeper Layers
2024
-
[9]
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, and Daniel A. Roberts. 2025. https://doi.org/10.48550/arXiv.2403.17887 The Unreasonable Ineffectiveness of the Deeper Layers . arXiv preprint. ArXiv:2403.17887 [cs]
-
[10]
Song Han, Huizi Mao, and William J. Dally. 2016. https://doi.org/10.48550/arXiv.1510.00149 Deep Compression : Compressing Deep Neural Networks with Pruning , Trained Quantization and Huffman Coding . arXiv preprint. ArXiv:1510.00149 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1510.00149 2016
-
[11]
Song Han, Jeff Pool, John Tran, and William J. Dally. 2015. https://doi.org/10.48550/arXiv.1506.02626 Learning both Weights and Connections for Efficient Neural Networks . arXiv preprint. ArXiv:1506.02626 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1506.02626 2015
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016 a . https://doi.org/10.1109/CVPR.2016.90 Deep Residual Learning for Image Recognition . In 2016 IEEE Conference on Computer Vision and Pattern Recognition ( CVPR ) , pages 770--778, Las Vegas, NV, USA. IEEE
-
[13]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016 b . https://arxiv.org/abs/1603.05027 Identity mappings in deep residual networks . Preprint, arXiv:1603.05027
Pith/arXiv arXiv 2016
-
[14]
Shwai He, Guoheng Sun, Zheyu Shen, and Ang Li. 2024. https://doi.org/10.48550/arXiv.2406.15786 What Matters in Transformers ? Not All Attention is Needed . arXiv preprint. ArXiv:2406.15786 [cs]
-
[15]
Jiachen Jiang, Jinxin Zhou, and Zhihui Zhu. 2025. https://openreview.net/forum?id=vVxeFSR4fU Tracing representation progression: Analyzing and enhancing layer-wise similarity . In The Thirteenth International Conference on Learning Representations
2025
-
[16]
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, and Hyoung-Kyu Song. 2024. https://doi.org/10.48550/arXiv.2402.02834 Shortened LLaMA : Depth Pruning for Large Language Models with Comparison of Retraining Methods . arXiv preprint. ArXiv:2402.02834 [cs]
-
[17]
Namhoon Lee, Thalaiyasingam Ajanthan, and Philip H. S. Torr. 2019. https://doi.org/10.48550/arXiv.1810.02340 SNIP : Single -shot Network Pruning based on Connection Sensitivity . arXiv preprint. ArXiv:1810.02340 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.02340 2019
-
[18]
Pengxiang Li, Lu Yin, and Shiwei Liu. 2024. https://openreview.net/forum?id=BChpQU64RG Mix- LN : Unleashing the Power of Deeper Layers by Combining Pre - LN and Post - LN
2024
-
[19]
Pengxiang Li, Lu Yin, and Shiwei Liu. 2025. https://doi.org/10.48550/arXiv.2412.13795 Mix- LN : Unleashing the Power of Deeper Layers by Combining Pre - LN and Post - LN . arXiv preprint. ArXiv:2412.13795 [cs]
-
[20]
Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Haotang Deng, and Qi Ju. 2020. https://arxiv.org/abs/2004.02178 Fastbert: a self-distilling bert with adaptive inference time . Preprint, arXiv:2004.02178
arXiv 2020
-
[21]
Ilya Loshchilov and Frank Hutter. 2018. https://openreview.net/forum?id=Bkg6RiCqY7 Decoupled Weight Decay Regularization
2018
-
[22]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. https://doi.org/10.48550/arXiv.2305.11627 LLM - Pruner : On the Structural Pruning of Large Language Models . arXiv preprint. ArXiv:2305.11627 [cs]
-
[23]
Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and weipeng chen. 2025. https://openreview.net/forum?id=JMNht3SmcG Short GPT : Layers in large language models are more redundant than you expect
2025
-
[24]
Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. 2017. https://doi.org/10.48550/arXiv.1611.06440 Pruning Convolutional Neural Networks for Resource Efficient Inference . arXiv preprint. ArXiv:1611.06440 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1611.06440 2017
-
[25]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, and 21 others. 2024. https://arxiv.org/abs/2501.00656 2 olmo 2 furious . Preprint,...
Pith/arXiv arXiv 2024
-
[26]
Language Models are Unsupervised Multitask Learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language Models are Unsupervised Multitask Learners
-
[27]
International Journal of Computer Vision , author =
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2020. https://doi.org/10.1007/s11263-019-01228-7 Grad- CAM : Visual Explanations from Deep Networks via Gradient -based Localization . International Journal of Computer Vision, 128(2):336--359. ArXiv:1610.02391 [cs]
-
[28]
Sam Shleifer, Jason Weston, and Myle Ott. 2021. https://doi.org/10.48550/arXiv.2110.09456 NormFormer : Improved Transformer Pretraining with Extra Normalization . arXiv preprint. ArXiv:2110.09456 [cs]
-
[29]
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. 2017. https://doi.org/10.48550/arXiv.1706.03825 SmoothGrad : removing noise by adding noise . arXiv preprint. ArXiv:1706.03825 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03825 2017
-
[30]
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, and 17 others. 2024. https://doi.org/10.18653/v1/2024.acl-long.840 Dolma: a...
-
[31]
SLEB : Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Jiwon Song, Kyungseok Oh, Taesu Kim, Hyungjun Kim, Yulhwa Kim, and Jae-Joon Kim. SLEB : Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
-
[32]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2024. https://doi.org/10.48550/arXiv.2306.11695 A Simple and Effective Pruning Approach for Large Language Models . arXiv preprint. ArXiv:2306.11695 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.11695 2024
-
[33]
Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu. 2025. https://doi.org/10.48550/arXiv.2502.05795 The Curse of Depth in Large Language Models . arXiv preprint. ArXiv:2502.05795 [cs]
-
[34]
Sho Takase, Shun Kiyono, Sosuke Kobayashi, and Jun Suzuki. 2023. https://doi.org/10.48550/arXiv.2206.00330 B2T Connection : Serving Stability and Performance in Deep Transformers . arXiv preprint. ArXiv:2206.00330 [cs]
-
[35]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. https://doi.org/10.48550/arXiv.2302.13971 LLaMA : Open and Efficient Foundation Language Models . arXiv preprint. ArXiv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[36]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html Attention is All you Need . In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc
2017
-
[37]
Andreas Veit, Michael Wilber, and Serge Belongie. 2016. https://arxiv.org/abs/1605.06431 Residual networks behave like ensembles of relatively shallow networks . Preprint, arXiv:1605.06431
Pith/arXiv arXiv 2016
-
[38]
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. 2022. https://doi.org/10.48550/arXiv.2203.00555 DeepNet : Scaling Transformers to 1,000 Layers . arXiv preprint. ArXiv:2203.00555 [cs]
-
[39]
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. 2024. https://doi.org/10.48550/arXiv.2310.06694 Sheared LLaMA : Accelerating Language Model Pre -training via Structured Pruning . arXiv preprint. ArXiv:2310.06694 [cs]
-
[40]
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. 2020. https://arxiv.org/abs/2004.12993 Deebert: Dynamic early exiting for accelerating bert inference . Preprint, arXiv:2004.12993
arXiv 2020
-
[41]
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. 2020. https://proceedings.mlr.press/v119/xiong20b.html On Layer Normalization in the Transformer Architecture . In Proceedings of the 37th International Conference on Machine Learning , pages 10524--10533. PMLR. ISSN: 2640-3498
2020
-
[42]
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, Ruoming Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. 2021. https://doi.org/10.48550/arXiv.2105.04663 GSPMD : General and Scalable Parallelization for ML Computation Graphs . arXiv prepr...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2105.04663 2021
-
[43]
Yifei Yang, Zouying Cao, and Hai Zhao. 2024. https://doi.org/10.48550/arXiv.2402.11187 LaCo : Large Language Model Pruning via Layer Collapse . arXiv preprint. ArXiv:2402.11187 [cs]
-
[44]
Ziqing Yang, Yiming Cui, Xin Yao, and Shijin Wang. 2023. https://doi.org/10.18653/v1/2023.acl-long.156 Gradient-based intra-attention pruning on pre-trained language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2775--2790, Toronto, Canada. Association for Computational L...
-
[45]
Anhao Zhao, Fanghua Ye, Yingqi Fan, Junlong Tong, Zhiwei Fei, Hui Su, and Xiaoyu Shen. 2025. https://doi.org/10.48550/arXiv.2506.04179 SkipGPT : Dynamic Layer Pruning Reinvented with Token Awareness and Module Decoupling . arXiv preprint. ArXiv:2506.04179 [cs]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.