Adversarial Diffusion Across Modalities: A Fusion Survey of Attacks, Defenses, and Evaluation for Text, Vision, and Vision-Language Models
Pith reviewed 2026-06-26 04:33 UTC · model grok-4.3
The pith
Four disconnected adversarial diffusion tracks are fused into one taxonomy, threat model axis, and five-dimension evaluation framework focused on LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
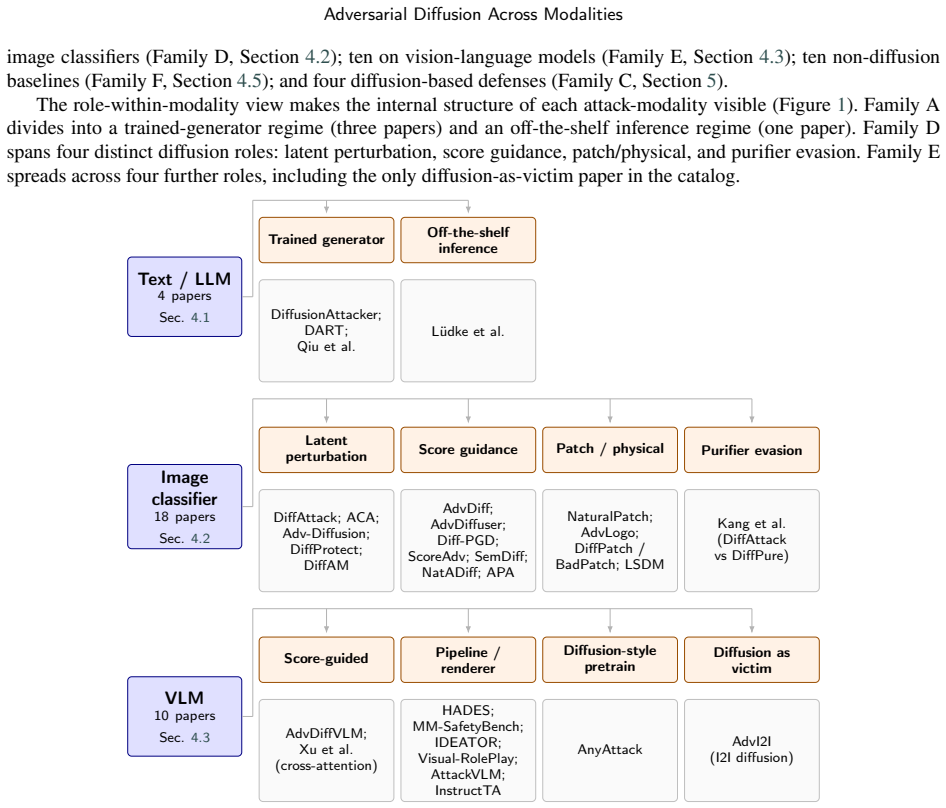
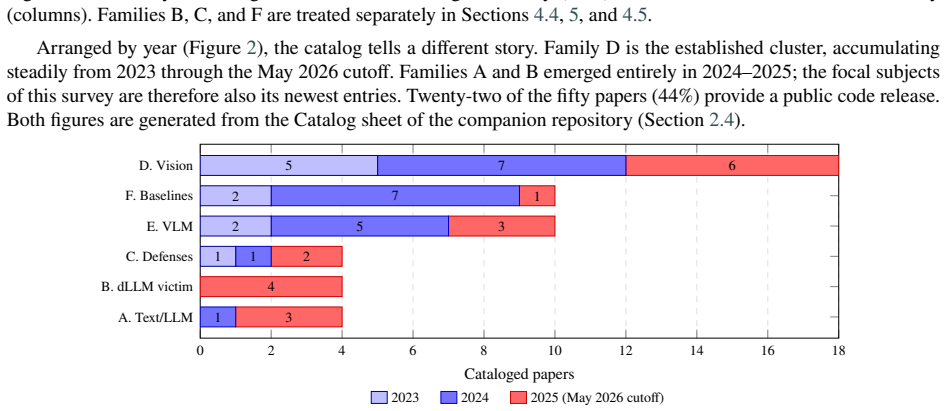
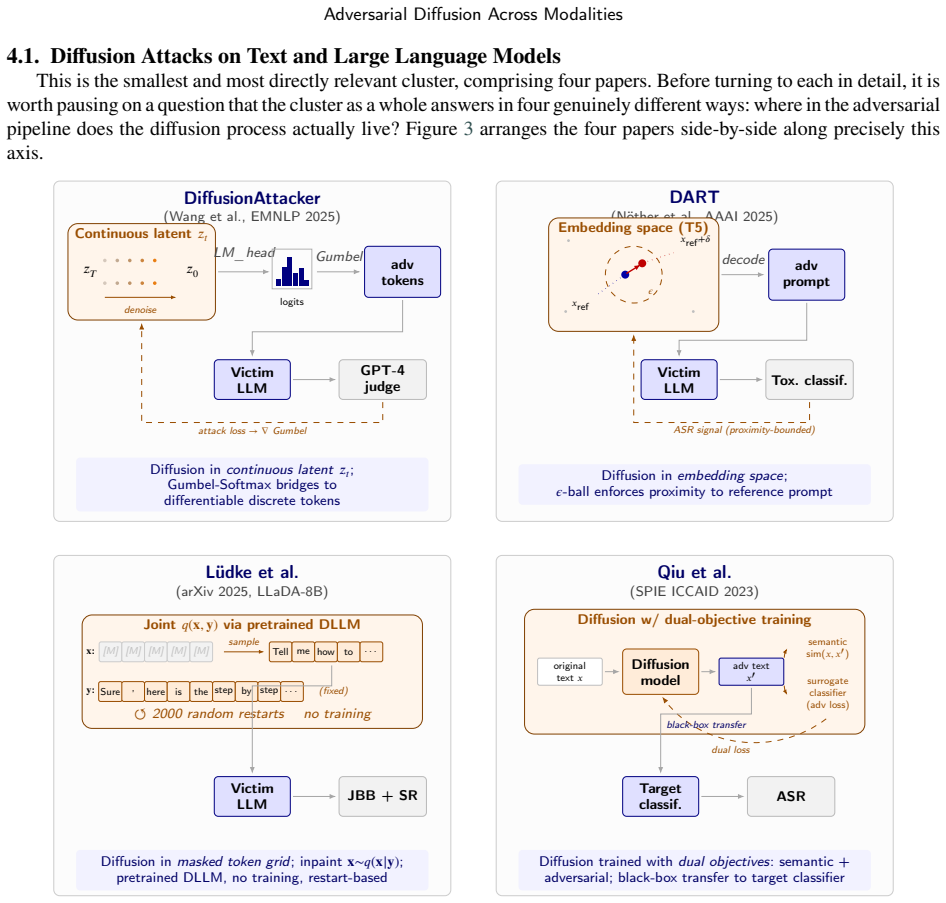
Diffusion models act as a portable generative component that can be slotted into adversarial pipelines in multiple modalities; cataloging fifty papers under a unified six-class taxonomy of diffusion roles, a threat-model axis that records attacker knowledge, query budget and target accessibility, and a five-dimension evaluation framework produces a coherent dual attacker-defender view centered on the LLM slice.
What carries the argument
Six-class taxonomy of diffusion roles in adversarial pipelines, augmented by a threat-model axis and a five-dimension evaluation framework applied uniformly across modalities.
If this is right
- Any new attack must be compared against the ten listed non-diffusion baselines.
- The four diffusion-based defenses form the natural evaluation backdrop for measuring new attacks.
- Five recurring weaknesses in the current LLM-side literature are now identified for targeted follow-up.
- The released catalog and spreadsheet support direct reuse of the taxonomy and criteria.
- A research agenda of open questions and concrete experimental designs follows from the fusion.
Where Pith is reading between the lines
- The unified criteria could be tested by running the same attack recipe on both an image classifier and an LLM to measure cross-modal transferability.
- The narrative review format implies that future work could apply the same taxonomy inside a PRISMA-style systematic review to check coverage.
- Focusing the framework on the LLM slice may surface language-specific vulnerabilities, such as perplexity sensitivity, that image-only studies miss.
- The dual attacker-defender view suggests experiments that pit each diffusion role directly against each of the four defenses to quantify evasion margins.
Load-bearing premise
The four tracks have developed largely disconnected vocabularies, threat models, and benchmarks that can be fused without significant loss of domain-specific detail.
What would settle it
A demonstration that mapping any diffusion role or evaluation dimension from the image-classifier track to the LLM track erases essential threat details that cannot be recovered in the unified taxonomy.
Figures
read the original abstract
Adversarial evaluation of AI systems has matured along four largely disconnected tracks: diffusion-based attacks on text and large language models (LLMs), diffusion-based attacks on image classifiers, jailbreak pipelines against vision-language models, and diffusion-based input purification defenses. Each has developed its own vocabulary, threat models, and benchmarks, with denoising diffusion models emerging as a shared generative mechanism whose recipes are now actively ported between communities. This survey performs an information-fusion exercise at the meta-research level: we integrate these four tracks into a single conceptual framework with a unified taxonomy, evaluation criteria, and research agenda, focusing on the LLM-side slice. We catalog fifty published papers across four scope areas (text/LLM, image classifier, vision-language model, defense), plus four diffusion-LLM-as-victim entries and ten non-diffusion baselines against which any new attack must be compared. We propose a six-class taxonomy of diffusion roles in adversarial pipelines, augmented by a threat-model axis recording attacker knowledge, query budget, and target accessibility, and apply a five-dimension framework (attack success rate, transferability, query budget, perplexity, defense-evasion) uniformly across modalities. The review adopts a dual attacker-defender perspective: alongside the attack catalog we cover four diffusion-based defenses that form the natural evaluation backdrop for new attacks. Our critical analysis identifies five recurring weaknesses of the current LLM-side literature, and we close with a research agenda of open questions and concrete experimental designs. The companion catalog and spreadsheet are released with the paper. We are explicit that this is a narrative review with quality assessment, not a PRISMA-compliant systematic review, and discuss the implications for replication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a narrative survey cataloging fifty papers on adversarial diffusion models across four tracks—diffusion-based attacks on text/LLMs, diffusion-based attacks on image classifiers, jailbreak pipelines on vision-language models, and diffusion-based input purification defenses—plus four diffusion-LLM-as-victim entries and ten non-diffusion baselines. It asserts that these tracks developed largely disconnected vocabularies, threat models, and benchmarks, and contributes a six-class taxonomy of diffusion roles, a threat-model axis (attacker knowledge, query budget, target accessibility), a uniform five-dimension evaluation framework (attack success rate, transferability, query budget, perplexity, defense-evasion), a dual attacker-defender perspective covering four defenses, identification of five recurring LLM-side weaknesses, and a research agenda, while releasing a companion catalog and spreadsheet. The work explicitly positions itself as a narrative review rather than PRISMA-compliant.
Significance. If the catalog is accurate and the fusion premise holds, the unified taxonomy and five-dimension framework could provide a useful meta-research lens for cross-modal adversarial work involving diffusion models, with the released catalog and spreadsheet offering concrete value for reproducibility and follow-on studies. The dual perspective and explicit discussion of narrative-review limitations are constructive.
major comments (2)
- [Abstract] Abstract: the central claim that the four tracks 'have developed largely disconnected vocabularies, threat models, and benchmarks' is asserted without any quantification of cross-citations, shared formalisms, or overlap analysis; because the paper's contribution is precisely the meta-level fusion, this premise is load-bearing and requires substantiation (e.g., a table or subsection counting cross-track citations among the 50 papers) to establish that unification is non-redundant.
- [Abstract] Abstract and opening sections: no search strategy, inclusion/exclusion criteria, or date range is described for selecting the fifty papers (or the additional four and ten entries), even though the text acknowledges the narrative-review nature; this directly affects the reliability of the catalog and the claim of a 'single conceptual framework' that integrates the space without significant loss of domain-specific detail.
minor comments (1)
- [Abstract] The abstract states the work 'focuses on the LLM-side slice' while covering all four tracks; a brief clarification in the introduction on how modality-specific details are preserved versus abstracted in the unified taxonomy would improve readability.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract and framing. We address each point below and will incorporate revisions to improve transparency and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four tracks 'have developed largely disconnected vocabularies, threat models, and benchmarks' is asserted without any quantification of cross-citations, shared formalisms, or overlap analysis; because the paper's contribution is precisely the meta-level fusion, this premise is load-bearing and requires substantiation (e.g., a table or subsection counting cross-track citations among the 50 papers) to establish that unification is non-redundant.
Authors: We agree the claim would be stronger with explicit support. In revision we will add a short subsection (and accompanying table) that reports our observed citation patterns across the 50 papers, including counts of cross-track references and shared formalisms where they exist. This analysis draws directly from the papers already catalogued; while we will not perform a full bibliometric study, the added table will quantify the limited overlap that motivated the fusion exercise. revision: yes
-
Referee: [Abstract] Abstract and opening sections: no search strategy, inclusion/exclusion criteria, or date range is described for selecting the fifty papers (or the additional four and ten entries), even though the text acknowledges the narrative-review nature; this directly affects the reliability of the catalog and the claim of a 'single conceptual framework' that integrates the space without significant loss of domain-specific detail.
Authors: We accept the point on transparency. Although the manuscript already states it is a narrative rather than PRISMA review, we will expand the opening section to describe the practical selection process used: approximate date range (papers up to mid-2024), relevance criteria for each of the four tracks, and how the additional baseline entries were chosen. This addition will clarify scope without converting the review into a systematic one. revision: yes
Circularity Check
No circularity: narrative survey with no derivations or self-referential claims
full rationale
The paper is a narrative review cataloging 50+ existing works into a proposed taxonomy and evaluation framework. No equations, predictions, fitted parameters, or derivations appear. The premise of 'largely disconnected tracks' is an empirical observation about the literature rather than a self-defined or self-cited load-bearing step that reduces to the paper's own inputs. The contribution is organizational; the taxonomy is not claimed to be mathematically forced or derived from prior author work. This matches the default expectation of no significant circularity for survey-style papers without quantitative modeling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al., 2023. GPT-4 technical report. doi:10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[2]
Austin,J.,Johnson,D.,Ho,J.,Tarlow,D.,vandenBerg,R.,2021. Structureddenoisingdiffusionmodelsindiscretestate-spaces,in:Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2107.03006
-
[3]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Chao, P., Debenedetti, E., Robey, A., Andriushchenko, M., Croce, F., Sehwag, V., Dobriban, E., Flammarion, N., Pappas, G.J., Tramèr, F., Hassani, H., Wong, E., 2024. JailbreakBench: An open robustness benchmark for jailbreaking large language models. arXiv preprint arXiv:2404.01318 doi:10.48550/arXiv.2404.01318
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.01318 2024
-
[4]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao,P.,Robey,A.,Dobriban,E.,Hassani,H.,Pappas,G.J.,Wong,E.,2023. Jailbreakingblackboxlargelanguagemodelsintwentyqueries. arXiv preprint arXiv:2310.08419 doi:10.48550/arXiv.2310.08419
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08419 2023
-
[5]
Diffusion models for imperceptible and transferable adversarial attack
Chen, J., Chen, H., Chen, K., Zhang, Y., Zou, Z., Shi, Z., 2024. Diffusion models for imperceptible and transferable adversarial attack. IEEE Transactions on Pattern Analysis and Machine Intelligence doi:10.1109/TPAMI.2024.3372023
-
[6]
Chen,X.,Gao,X.,Zhao,J.,Ye,K.,Xu,C.Z.,2023a.AdvDiffuser:Naturaladversarialexamplesynthesiswithdiffusionmodels,in:Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
-
[7]
Natural adversarial patch generation method based on latent diffusion model
Chen, X., Liu, F., Jiang, D., Yan, K., 2023b. Natural adversarial patch generation method based on latent diffusion model. arXiv preprint arXiv:2312.16401 doi:10.48550/arXiv.2312.16401
-
[8]
Content-based unrestricted adversarial attack, in: Advances in Neural Information Processing Systems
Chen, Z., Li, B., Wu, S., Ding, S., Zhang, W., 2023c. Content-based unrestricted adversarial attack, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2305.10665
-
[9]
NatADiff: Adversarial boundary guidance for natural adversarial diffusion
Collins, M., Vice, J., French, T., Mian, A., 2025. NatADiff: Adversarial boundary guidance for natural adversarial diffusion. arXiv preprint arXiv:2505.20934 doi:10.48550/arXiv.2505.20934
-
[10]
Risk taxonomy, mitigation, and assessment benchmarks of large language model systems
Cui, T., Wang, Y., Fu, C., Xiao, Y., Li, S., Deng, X., Liu, Y., Zhang, Q., Qiu, Z., Li, P., Tan, Z., Xiong, J., Kong, X., Wen, Z., Xu, K., Li, Q., 2024. Risk taxonomy, mitigation, and assessment benchmarks of large language model systems. arXiv preprint arXiv:2401.05778 doi:10.48550/arXiv.2401.05778
-
[11]
Dai, X., Liang, K., Xiao, B., 2024. AdvDiff: Generating unrestricted adversarial examples using diffusion models, in: European Conference on Computer Vision (ECCV). doi:10.48550/arXiv.2307.12499
-
[12]
Dai, Z., Liu, S., He, R., Wu, J., Lu, N., Fan, W., Li, Q., Tang, K., 2025. SemDiff: Generating natural unrestricted adversarial examples via semantic attributes optimization in diffusion models. arXiv preprint arXiv:2504.11923 doi:10.48550/arXiv.2504.11923
-
[13]
ImageNet:Alarge-scalehierarchicalimagedatabase,in:Proceedingsofthe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Deng,J.,Dong,W.,Socher,R.,Li,L.J.,Li,K.,Fei-Fei,L.,2009. ImageNet:Alarge-scalehierarchicalimagedatabase,in:Proceedingsofthe IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2009
-
[14]
Diffusion Models Beat GANs on Image Synthesis
Dhariwal, P., Nichol, A.Q., 2021. Diffusion models beat GANs on image synthesis, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2105.05233
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2105.05233 2021
-
[15]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Ganguli, D., Lovitt, L., Kernion, J., Askell, A., Bai, Y., Kadavath, S., Mann, B., Perez, E., Schiefer, N., Ndousse, K., et al., 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned, in: arXiv preprint arXiv:2209.07858. doi:10.48550/arXiv.2209.07858
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.07858 2022
-
[16]
Gehman, S., Gururangan, S., Sap, M., Choi, Y., Smith, N.A., 2020. RealToxicityPrompts: Evaluating neural toxic degeneration in language models, in: Findings of the Association for Computational Linguistics: EMNLP. doi:10.18653/v1/2020.findings-emnlp.301
-
[17]
Gietz,H.,Kalita,J.,2024. MaskPure:Improvingdefenseagainsttextadversarieswithstochasticpurification,in:NaturalLanguageProcessing and Information Systems (NLDB). doi:10.1007/978-3-031-70239-6_26
-
[18]
Gong, Y., Ran, D., Liu, J., Wang, C., Cong, T., Wang, A., Duan, S., Wang, X., 2025. FigStep: Jailbreaking large vision-language models via typographic visual prompts, in: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.48550/arXiv.2311.05608
-
[19]
Guo, Q., Pang, S., Jia, X., Liu, Y., Guo, Q., 2024. Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models. IEEE Transactions on Information Forensics and Security doi:10.1109/TIFS.2024.3518072
-
[20]
Denoising Diffusion Probabilistic Models
Ho, J., Jain, A., Abbeel, P., 2020. Denoising diffusion probabilistic models, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2006.11239
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2006.11239 2020
-
[21]
ScoreAdv: Score-based targeted generation of natural adversarial examples via diffusion models
Huang, C., Tang, H., 2025. ScoreAdv: Score-based targeted generation of natural adversarial examples via diffusion models. arXiv preprint arXiv:2507.06078 doi:10.48550/arXiv.2507.06078
-
[22]
Huang, X., Ruan, W., Huang, W., Jin, G., Dong, Y., Wu, C., Bensalem, S., Mu, R., Qi, Y., Zhao, X., Cai, K., Zhang, Y., Wu, S., Xu, P., Wu, D., Freitas, A., Mustafa, M.A., 2024. A survey of safety and trustworthiness of large language models through the lens of verification and validation. Artificial Intelligence Review doi:10.1007/s10462-024-10884-2
-
[23]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan,H.,Upasani,K.,Chi,J.,Rungta,R.,Iyer,K.,Mao,Y.,Tontchev,M.,Hu,Q.,Fuller,B.,Testuggine,D.,Khabsa,M.,2023. Llamaguard: LLM-based input-output safeguard for human-AI conversations. arXiv preprint arXiv:2312.06674 doi:10.48550/arXiv.2312.06674
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.06674 2023
-
[24]
Redteaminglargelanguagemodels:Acomprehensivereviewandcriticalanalysis
Jabbar,M.S.,Al-Azani,S.,Alotaibi,A.,Ahmed,M.,2025. Redteaminglargelanguagemodels:Acomprehensivereviewandcriticalanalysis. Preprint submitted to Elsevier
2025
-
[25]
Enhancing diffusion-based unrestricted adversarial attacks via adversary preferences alignment
Jiang, K., Chen, Z., Guo, H., Li, J., Fu, J., Guo, P., Tang, H., Li, B., Zhang, W., 2025. Enhancing diffusion-based unrestricted adversarial attacks via adversary preferences alignment. arXiv preprint arXiv:2506.01511 doi:10.48550/arXiv.2506.01511
-
[26]
Jin, D., Jin, Z., Zhou, J.T., Szolovits, P., 2020. Is BERT really robust? a strong baseline for natural language attack on text classification and entailment (TextFooler). Proceedings of the AAAI Conference on Artificial Intelligence doi:10.1609/aaai.v34i05.6311. A. Alotaibi and M. Ahmed:Preprint submitted to ElsevierPage 28 of 30 Adversarial Diffusion Ac...
-
[27]
Kang, M., Song, D., Li, B., 2024. DiffAttack: Evasion attacks against diffusion-based adversarial purification, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2311.16124
-
[28]
The measurement of observer agreement for categorical data
Landis, J.R., Koch, G.G., 1977. The measurement of observer agreement for categorical data. Biometrics 33, 159–174
1977
-
[29]
Li,L.,Song,D.,Qiu,X.,2023. Textadversarialpurificationasdefenseagainstadversarialattacks,in:Proceedingsofthe61stAnnualMeeting of the Association for Computational Linguistics (ACL), pp. 338–350. doi:10.18653/v1/2023.acl-long.20
-
[30]
DiffAttack-X: An effective transferable adversarial attack based on diffusion models
Li, L., Zhang, X., Wang, J., et al., 2025a. DiffAttack-X: An effective transferable adversarial attack based on diffusion models. Applied Intelligence 55, 1062. doi:10.1007/s10489-025-06957-6
-
[31]
Li,Y.,Guo,H.,Zhou,K.,Zhao,W.X.,Wen,J.R.,2024. Imagesareachilles’heelofalignment:Exploitingvisualvulnerabilitiesforjailbreaking multimodal large language models, in: European Conference on Computer Vision (ECCV). doi:10.48550/arXiv.2403.09792
-
[32]
Li, Z., Nie, Z., Zhou, Z., Liu, Y., Zhang, Y., Cheng, Y., Wen, Q., Wang, K., Guo, Y., Zhang, J., 2026. DiffuGuard: How intrinsic safety is lostandfoundindiffusionlargelanguagemodels,in:InternationalConferenceonLearningRepresentations(ICLR). doi:10.48550/arXiv. 2509.24296
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[33]
Li, Z., Zhou, H., Rei, M., Specia, L., 2025b. DiffuseDef: Improved robustness to adversarial attacks via iterative denoising, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). doi:10.48550/arXiv.2407.00248
-
[34]
Againsttheachilles’ heel: A survey on red teaming for generative models
Lin,L.,Mu,H.,Zhai,Z.,Wang,M.,Wang,Y.,Wang,R.,Gao,J.,Zhang,Y.,Che,W.,Baldwin,T.,Han,X.,Li,H.,2025. Againsttheachilles’ heel: A survey on red teaming for generative models. Journal of Artificial Intelligence Research doi:10.48550/arXiv.2404.00629
-
[35]
Microsoft COCO: Common objects in context, in: European Conference on Computer Vision (ECCV)
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L., 2014. Microsoft COCO: Common objects in context, in: European Conference on Computer Vision (ECCV)
2014
-
[36]
Liu,D.,Wang,X.,Peng,C.,Wang,N.,Hu,R.,Gao,X.,2024a. Adv-diffusion:Imperceptibleadversarialfaceidentityattackvialatentdiffusion model, in: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.1609/aaai.v38i4.28067
-
[37]
DiffProtect: Generate adversarial examples with diffusion models for facial privacy protection
Liu, J., Lau, C.P., Chellappa, R., 2023. DiffProtect: Generate adversarial examples with diffusion models for facial privacy protection. arXiv preprint arXiv:2305.13625 doi:10.48550/arXiv.2305.13625
-
[38]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Liu, X., Xu, N., Chen, M., Xiao, C., 2024b. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models, in: International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2310.04451
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.04451
-
[39]
Liu,X.,Zhu,Y.,Gu,J.,Lan,Y.,Yang,C.,Qiao,Y.,2024c. MM-SafetyBench:Abenchmarkforsafetyevaluationofmultimodallargelanguage models, in: European Conference on Computer Vision (ECCV). doi:10.48550/arXiv.2311.17600
-
[40]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Liu, Y., Deng, G., Xu, Z., Li, Y., Zheng, Y., Zhang, Y., Zhao, L., Zhang, T., Wang, K., Liu, Y., 2024d. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860 doi:10.48550/arXiv.2305.13860
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.13860
-
[41]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Lou, A., Meng, C., Ermon, S., 2024. Discrete diffusion modeling by estimating the ratios of the data distribution (SEDD), in: International Conference on Machine Learning (ICML). doi:10.48550/arXiv.2310.16834
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.16834 2024
-
[42]
DiffusionLLMsarenaturaladversariesforanyLLM
Lüdke,D.,Wollschläger,T.,Ungermann,P.,Günnemann,S.,Schwinn,L.,2025. DiffusionLLMsarenaturaladversariesforanyLLM. arXiv preprint arXiv:2511.00203 doi:10.48550/arXiv.2511.00203
-
[43]
Ma,S.,Luo,W.,Wang,Y.,Liu,X.,Chen,M.,Li,B.,Xiao,C.,2024. Visual-roleplay:Universaljailbreakattackonmultimodallargelanguage models via role-playing image character. arXiv preprint arXiv:2405.20773 doi:10.48550/arXiv.2405.20773
-
[44]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika,M.,Phan,L.,Yin,X.,Zou,A.,Wang,Z.,Mu,N.,Sakhaee,E.,Li,N.,Basart,S.,Li,B.,Forsyth,D.,Hendrycks,D.,2024.HarmBench: Astandardizedevaluationframeworkforautomatedredteamingandrobustrefusal,in:InternationalConferenceonMachineLearning(ICML). doi:10.48550/arXiv.2402.04249
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.04249 2024
-
[45]
FLIRT:Feedbackloopin-context red teaming
Mehrabi,N.,Goyal,P.,Dupuy,C.,Hu,Q.,Ghosh,S.,Zemel,R.,Chang,K.W.,Galstyan,A.,Gupta,R.,2023. FLIRT:Feedbackloopin-context red teaming. arXiv preprint arXiv:2308.04265
arXiv 2023
-
[46]
AdvLogo: Adversarial patch attack against object detectors based on diffusion models
Miao, B., Li, C., Zhu, Y., Sun, W., Wang, Z., Wang, X., Xie, C., 2024. AdvLogo: Adversarial patch attack against object detectors based on diffusion models. arXiv preprint arXiv:2409.07002 doi:10.48550/arXiv.2409.07002
-
[47]
Nichol, A.Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., Sutskever, I., Chen, M., 2022. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models, in: International Conference on Machine Learning (ICML). doi:10.48550/ arXiv.2112.10741
Pith/arXiv arXiv 2022
-
[48]
Large Language Diffusion Models
Nie,S.,Zhu,F.,You,Z.,Zhang,X.,Ou,J.,Hu,J.,Zhou,J.,Lin,Y.,Wen,J.R.,Li,C.,2025. Largelanguagediffusionmodels(LLaDA). arXiv preprint arXiv:2502.09992 doi:10.48550/arXiv.2502.09992
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[49]
Diffusion models for adversarial purification, in: Proceedings of the 39th International Conference on Machine Learning (ICML)
Nie, W., Guo, B., Huang, Y., Xiao, C., Vahdat, A., Anandkumar, A., 2022. Diffusion models for adversarial purification, in: Proceedings of the 39th International Conference on Machine Learning (ICML)
2022
-
[50]
Nöther,J.,Singla,A.,Radanović,G.,2025. Text-diffusionred-teamingoflargelanguagemodels:Unveilingharmfulbehaviorswithproximity constraints, in: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.48550/arXiv.2501.08246
-
[51]
The 18 PRISMA 2020 statement: An updated guideline for reporting systematic reviews
Page,M.J.,McKenzie,J.E.,Bossuyt,P.M.,Boutron,I.,Hoffmann,T.C.,Mulrow,C.D.,Shamseer,L.,Tetzlaff,J.M.,Akl,E.A.,Brennan,S.E., et al., 2021. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372. doi:10.1136/bmj.n71
-
[52]
AdvPrompter: Fast adaptive adversarial prompting for LLMs
Paulus, A., Zharmagambetov, A., Guo, C., Amos, B., Tian, Y., 2024. AdvPrompter: Fast adaptive adversarial prompting for LLMs. arXiv preprint arXiv:2404.16873 doi:10.48550/arXiv.2404.16873
-
[53]
Red Teaming Language Models with Language Models
Perez,E.,Huang,S.,Song,F.,Cai,T.,Ring,R.,Aslanides,J.,Glaese,A.,McAleese,N.,Irving,G.,2022. Redteaminglanguagemodelswith language models. arXiv preprint arXiv:2202.03286 doi:10.48550/arXiv.2202.03286
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2202.03286 2022
-
[54]
Qi,X.,Huang,K.,Panda,A.,Henderson,P.,Wang,M.,Mittal,P.,2024. Visualadversarialexamplesjailbreakalignedlargelanguagemodels, in: Proceedings of the AAAI Conference on Artificial Intelligence. doi:10.48550/arXiv.2306.13213
-
[55]
DiffusionmodelforadversarialattackagainstNLPmodels,in:ProceedingsoftheSPIEVol.13105(ICCAID 2023)
Qiu,S.,Gou,M.,Liang,T.,2024. DiffusionmodelforadversarialattackagainstNLPmodels,in:ProceedingsoftheSPIEVol.13105(ICCAID 2023). doi:10.1117/12.3026312
-
[56]
Gradient-based jailbreak images for multimodal fusion models
Rando, J., Korevaar, H., Brinkman, E., Evtimov, I., Tramèr, F., 2024. Gradient-based jailbreak images for multimodal fusion models. arXiv preprint arXiv:2410.03489 doi:10.48550/arXiv.2410.03489. A. Alotaibi and M. Ahmed:Preprint submitted to ElsevierPage 29 of 30 Adversarial Diffusion Across Modalities
-
[57]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Robey, A., Wong, E., Hassani, H., Pappas, G.J., 2023. SmoothLLM: Defending large language models against jailbreaking attacks, in: arXiv preprint arXiv:2310.03684. doi:10.48550/arXiv.2310.03684
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.03684 2023
-
[58]
High-Resolution Image Synthesis with Latent Diffusion Models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B., 2022. High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.48550/arXiv.2112.10752
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.10752 2022
-
[59]
Shayegani, E., Dong, Y., Abu-Ghazaleh, N., 2024. Jailbreak in pieces: Compositional adversarial attacks on multi-modal language models, in: International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2307.14539
-
[60]
Simplified and generalized masked diffusion for discrete data (MDLM)
Shi, J., Han, K., Wang, Z., Doucet, A., Titsias, M., 2024. Simplified and generalized masked diffusion for discrete data (MDLM). arXiv preprint arXiv:2406.04329 doi:10.48550/arXiv.2406.04329
-
[61]
Denoising Diffusion Implicit Models
Song,J.,Meng,C.,Ermon,S.,2021a. Denoisingdiffusionimplicitmodels,in:InternationalConferenceonLearningRepresentations(ICLR). doi:10.48550/arXiv.2010.02502
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.02502 2010
-
[62]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B., 2021b. Score-based generative modeling through stochastic differential equations, in: International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2011.13456
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2011.13456 2011
-
[63]
Sun, Y., Yu, L., Xie, H., Li, J., Zhang, Y., 2024. DiffAM: Diffusion-based adversarial makeup transfer for facial privacy protection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.48550/arXiv.2405.09882
-
[64]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al., 2023. LLaMA 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 doi:10.48550/arXiv.2307.09288
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[65]
DiffusionAttacker: Diffusion-driven prompt manipulation for LLM jailbreak
Wang, H., Li, H., Zhu, J., Wang, X., Pan, C., Huang, M., Sha, L., 2024a. DiffusionAttacker: Diffusion-driven prompt manipulation for LLM jailbreak. arXiv preprint arXiv:2412.17522 doi:10.48550/arXiv.2412.17522
-
[66]
Wang, R., Li, J., Wang, Y., Wang, B., Wang, X., Teng, Y., Wang, Y., Ma, X., Jiang, Y.G., 2025a. IDEATOR: Jailbreaking and benchmarking large vision-language models using themselves, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). doi:10.48550/arXiv.2411.00827
-
[67]
Wang, R., Ma, X., Zhou, H., Ji, C., Ye, G., Jiang, Y.G., 2024b. White-box multimodal jailbreaks against large vision-language models, in: Proceedings of the 32nd ACM International Conference on Multimedia (MM). doi:10.48550/arXiv.2405.17894
-
[68]
Latent-space diffusion models for stealthy and transferable adversarial attacks on object detection
Wang, W., Qi, H., Huang, Z., Yin, B., et al., 2025b. Latent-space diffusion models for stealthy and transferable adversarial attacks on object detection. Neurocomputing 656, 131456. doi:10.1016/j.neucom.2025.131456
-
[69]
InstructTA:Instruction-tunedtargetedattackforlargevision-languagemodels
Wang,X.,Ji,Z.,Ma,P.,Li,Z.,Wang,S.,2023. InstructTA:Instruction-tunedtargetedattackforlargevision-languagemodels. arXivpreprint arXiv:2312.01886 doi:10.48550/arXiv.2312.01886
-
[70]
BadPatch:Diffusion-basedgenerationofphysicaladversarialpatches
Wang,Z.,Ma,X.,Jiang,Y.G.,2024c. BadPatch:Diffusion-basedgenerationofphysicaladversarialpatches. arXivpreprintarXiv:2412.01440 doi:10.48550/arXiv.2412.01440
-
[71]
Jailbroken: How Does LLM Safety Training Fail?
Wei, A., Haghtalab, N., Steinhardt, J., 2023. Jailbroken: How does LLM safety training fail?, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2307.02483
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.02483 2023
-
[72]
Wen, Z., Qu, J., Chen, Z., Lu, X., Liu, D., Liu, Z., Wu, R., Yang, Y., Jin, X., Xu, H., Liu, X., Li, W., Lu, C., Shao, J., He, C., Zhang, L., 2026. The devil behind the mask: An emergent safety vulnerability of diffusion LLMs, in: International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2507.11097
-
[73]
Xu,W.,Chen,K.,Gao,Z.,Wei,Z.,Chen,J.,Jiang,Y.G.,2024.Highlytransferablediffusion-basedunrestrictedadversarialattackonpre-trained vision-languagemodels,in:Proceedingsofthe32ndACMInternationalConferenceonMultimedia(MM).doi:10.1145/3664647.3681538
-
[74]
Xue, H., Araujo, A., Hu, B., Chen, Y., 2023. Diff-PGD: Diffusion-based adversarial sample generation for improved stealthiness and controllability, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2305.16494
-
[75]
Yamabe, S., Sakuma, J., 2026. Toward safer diffusion language models: Discovery and mitigation of priming vulnerability, in: International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2510.00565
-
[76]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Yi, S., Liu, Y., Sun, Z., Cong, T., He, X., Song, J., Xu, K., Li, Q., 2024. Jailbreak attacks and defenses against large language models: A survey. arXiv preprint arXiv:2407.04295 doi:10.48550/arXiv.2407.04295
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.04295 2024
-
[77]
Ying, Z., Liu, A., Zhang, T., Yu, Z., Liang, S., Liu, X., Tao, D., 2024. Jailbreak vision language models via bi-modal adversarial prompt, in: Advances in Neural Information Processing Systems. doi:10.48550/arXiv.2406.04031
-
[78]
Zeng, Y., Cao, Y., Cao, B., Chang, Y., Chen, J., Lin, L., 2025. AdvI2I: Adversarial image attack on image-to-image diffusion models, in: International Conference on Machine Learning (ICML). doi:10.48550/arXiv.2410.21471
-
[79]
Zhang,J.,Ye,J.,Ma,X.,Li,Y.,Yang,Y.,Chen,Y.,Sang,J.,Yeung,D.Y.,2025a. AnyAttack:Towardslarge-scaleself-supervisedadversarial attacks on vision-language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.48550/arXiv.2410.05346
-
[80]
Zhang, Y., Xie, F., Zhou, Z., Li, Z., Chen, H., Wang, K., Guo, Y., 2025b. Jailbreaking large language diffusion models: Revealing hidden safety flaws in diffusion-based text generation. arXiv preprint arXiv:2507.19227 doi:10.48550/arXiv.2507.19227
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.