Zero-Shot Size Transfer for Neural ODEs on Sparse Random Graphs: Graphon Limits and Adjoint Convergence
Pith reviewed 2026-06-26 05:23 UTC · model grok-4.3
The pith
GNDE solutions on sparse random graphs converge to Graphon-NDE limits at rate O((α_n n)^{-1/2}) with high probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
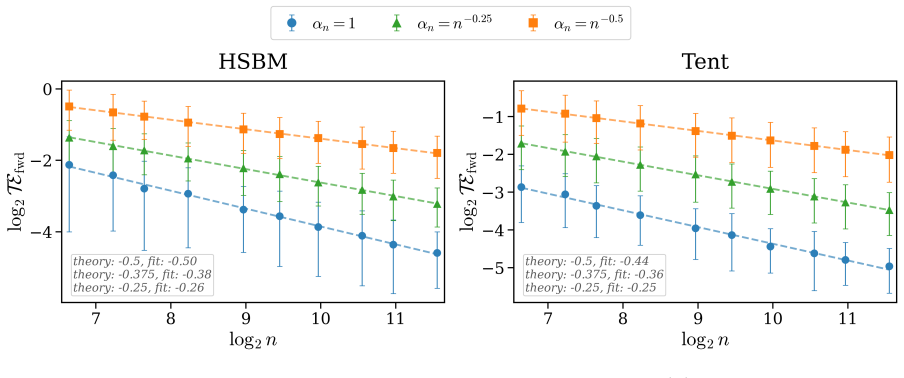
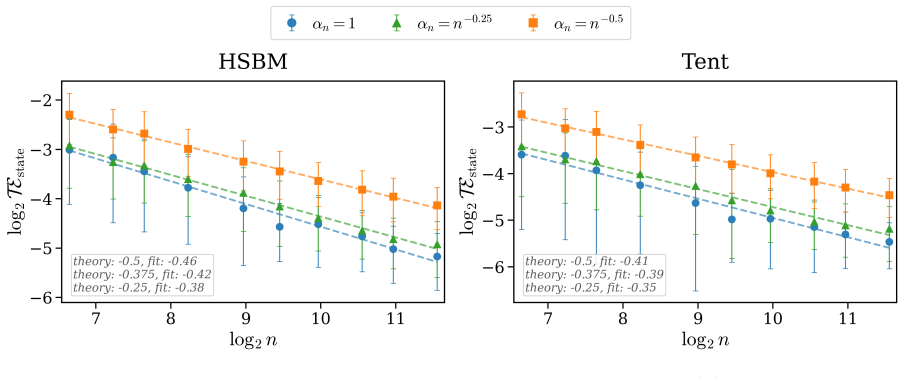
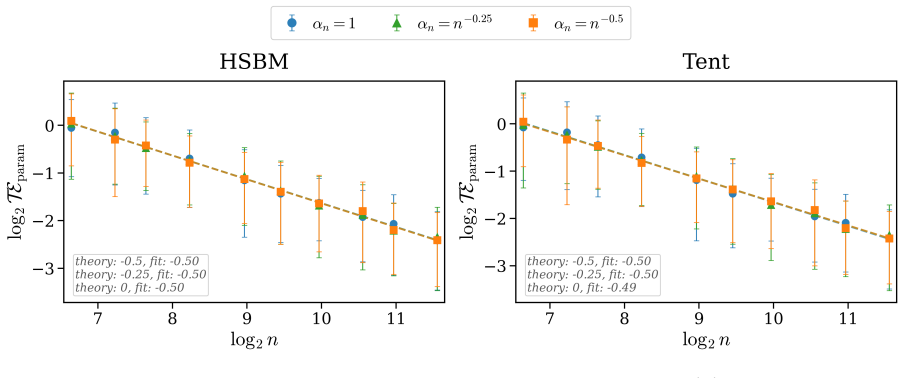
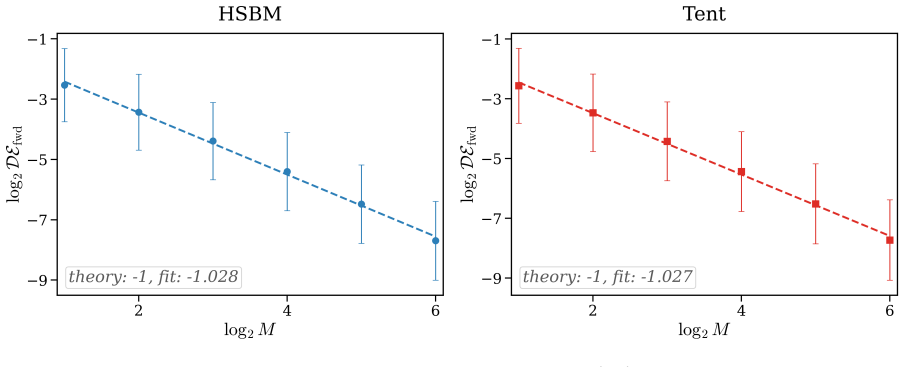
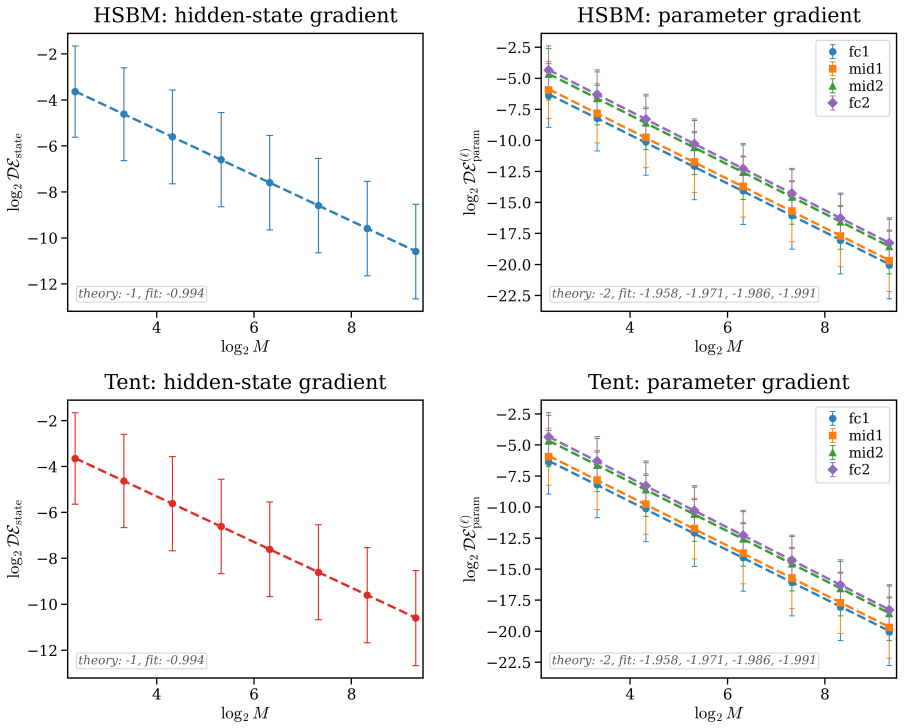
For an n-node random graph with sparsity parameter α_n sampled independently from a fixed graphon, GNDE solutions converge trajectory-wise to Graphon-NDE solutions at rate O((α_n n)^{-1/2}), up to logarithmic factors, with high probability. Uniform-in-time convergence bounds are obtained for the adjoint systems that govern hidden-state and parameter gradients. Under explicit Euler discretization with M steps, discretize-then-optimize and optimize-then-discretize training are asymptotically consistent, with hidden-state discrepancies of order O(1/M) and local parameter-gradient discrepancies of order O(1/M^2), up to sparsity and logarithmic factors.
What carries the argument
Graphon-NDEs and adjoint Graphon-NDEs as the infinite-node limits of GNDE forward and adjoint systems on sparse random graphs sampled from graphons.
If this is right
- Trajectory-wise convergence of GNDE solutions to Graphon-NDE solutions holds at the stated rate with high probability.
- Uniform-in-time convergence bounds apply to the adjoint systems used for gradient computation.
- Discretize-then-optimize and optimize-then-discretize training become asymptotically consistent with hidden-state error O(1/M) and parameter-gradient error O(1/M^2).
- Zero-shot deployment of a trained GNDE on larger independently sampled graphs from the same graphon is justified by the convergence.
Where Pith is reading between the lines
- The rate suggests that transfer accuracy improves when the product α_n n grows, even if individual graphs remain sparse.
- The same limit argument could be checked numerically by comparing transfer error across graph sizes while fixing the product α_n n.
- Adjoint convergence implies that gradient estimates obtained on small graphs remain reliable when the model is evaluated on larger ones.
Load-bearing premise
The finite graphs are sampled independently from a fixed graphon and the GNN velocity fields use local size-independent filters that admit a well-defined graphon limit.
What would settle it
Run GNDE and Graphon-NDE trajectories on independent samples from the same graphon at increasing n while holding α_n n fixed; if the observed trajectory difference fails to contract at the predicted O((α_n n)^{-1/2}) rate, the convergence statement is false.
Figures
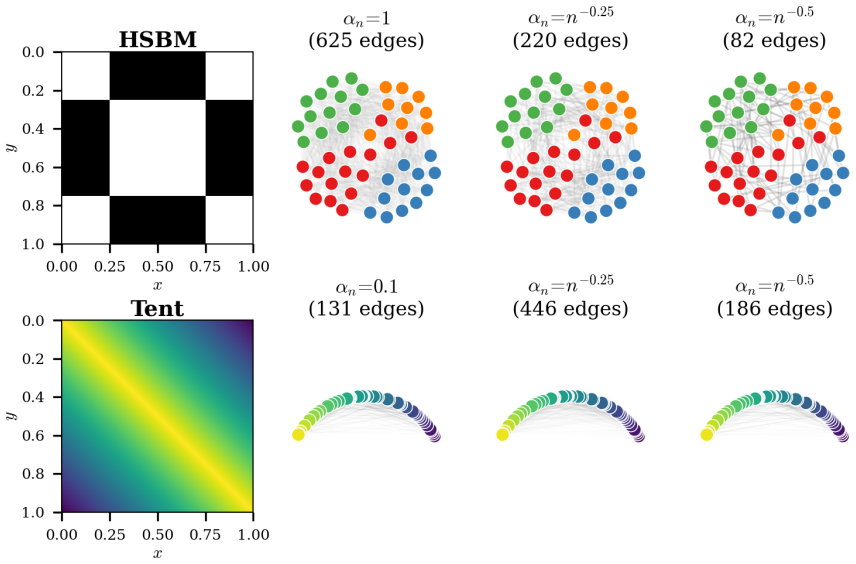
read the original abstract
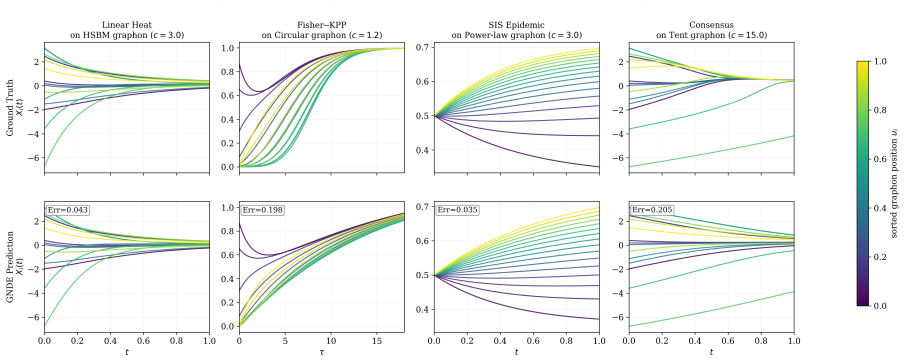
Graph Neural Differential Equations (GNDEs) model continuous-time graph dynamics by parameterizing Neural ODE velocity fields with Graph Neural Networks. Their local, size-independent filters suggest a zero-shot size-transfer principle: train on a small graph and deploy on larger, similar graphs without retraining. We develop a quantitative theory for this principle on sparse random graphs sampled from graphons. We consider Graphon Neural Differential Equations (Graphon-NDEs) and adjoint Graphon-NDEs as the infinite-node limits of the forward and adjoint GNDE systems, and establish well-posedness. For an $n$-node random graph with sparsity parameter $\alpha_n$, we prove trajectory-wise convergence of GNDE solutions to Graphon-NDE solutions at rate $O((\alpha_n n)^{-1/2})$, up to logarithmic factors, with high probability. We also establish uniform-in-time convergence bounds for adjoint systems governing hidden-state and parameter gradients. We further study discretize-then-optimize (DTO) and optimize-then-discretize (OTD) training. Under explicit Euler discretization with $M$ steps, we show that DTO and OTD are asymptotically consistent, with hidden-state and local parameter-gradient discrepancies of orders $O(1/M)$ and $O(1/M^2)$, respectively, up to sparsity and logarithmic factors. Experiments on HSBM and tent graphons support the theoretical rates, while zero-shot transfer experiments across four graphon classes demonstrate accurate deployment of learned GNDEs on larger independently sampled graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a quantitative theory for zero-shot size transfer in Graph Neural Differential Equations (GNDEs) on sparse random graphs sampled from graphons. It defines Graphon-NDEs (and their adjoints) as the infinite-node limits of the forward and adjoint GNDE systems, establishes well-posedness, and proves trajectory-wise convergence of n-node GNDE solutions to the Graphon-NDE limit at rate O((α_n n)^{-1/2}) (up to logarithmic factors) with high probability. Uniform-in-time convergence bounds are derived for the adjoint systems. Under explicit Euler discretization with M steps, discretize-then-optimize and optimize-then-discretize schemes are shown to be asymptotically consistent, with hidden-state and local parameter-gradient discrepancies of orders O(1/M) and O(1/M^2) (up to sparsity and log factors). Experiments on HSBM and tent graphons validate the rates and demonstrate zero-shot transfer across graphon classes.
Significance. If the central claims hold, the work supplies explicit, high-probability convergence rates and adjoint bounds that justify size-independent deployment of trained GNDEs, a practically relevant property for continuous-time graph models. The derivation of the O((α_n n)^{-1/2}) rate directly from graphon sampling assumptions and standard Gronwall arguments, together with the asymptotic consistency results for the two training paradigms, constitutes a clear technical contribution. The paper supplies parameter-free rate expressions and high-probability bounds rather than data-fitted quantities.
minor comments (2)
- [§3.2] §3.2: the statement of the local, size-independent filter assumption could be restated more explicitly as a hypothesis on the GNN velocity field to make the invocation of the graphon limit fully self-contained.
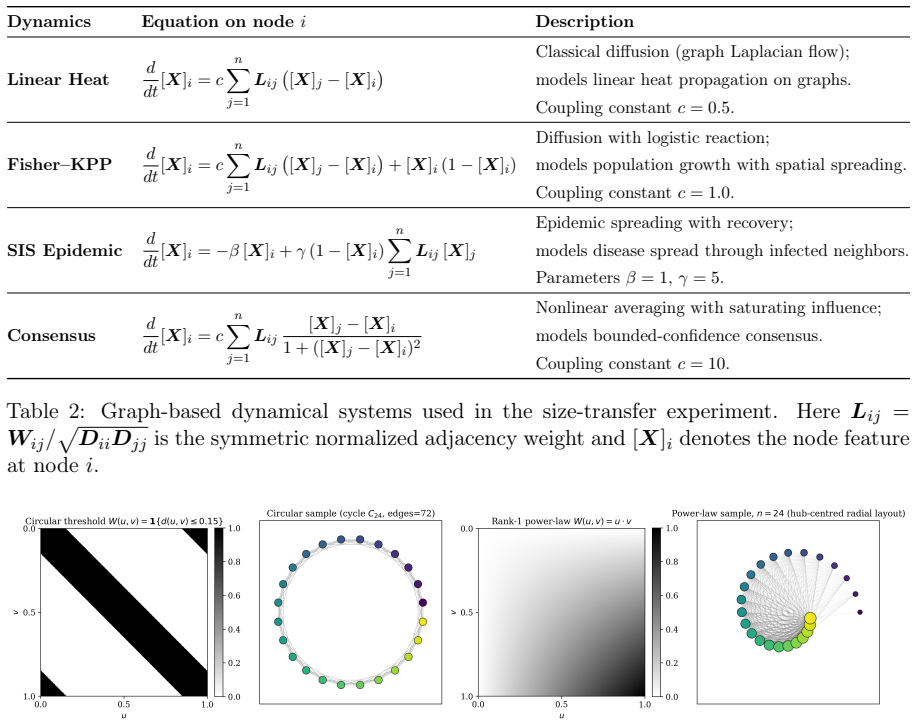
- [Figure 2] Figure 2 caption: the legend for the four graphon classes is slightly compressed; enlarging the font or adding a separate key would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough reading and positive recommendation to accept the manuscript. The report accurately summarizes the contributions, and we have no major comments to address.
Circularity Check
No significant circularity
full rationale
The derivation relies on explicit graphon sampling assumptions, standard concentration inequalities, and Gronwall lifting from graphon approximation error to ODE trajectories. These are external to the paper's fitted quantities and do not reduce by construction to self-defined predictions, fitted inputs renamed as outputs, or load-bearing self-citations. The central claims (trajectory-wise convergence at O((α_n n)^{-1/2}) and adjoint bounds) follow from the stated setup without internal redefinition or smuggling of ansatzes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Well-posedness of the Graphon-NDE and adjoint Graphon-NDE systems
- domain assumption Graphs are sampled independently from a fixed graphon with sparsity α_n
invented entities (1)
-
Graphon-NDE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural ODEs as the deep limit of ResNets with constant weights
Benny Avelin and Kaj Nystr \"o m. Neural ODEs as the deep limit of ResNets with constant weights. Analysis and Applications, 19 0 (03): 0 397--437, 2021
2021
-
[2]
Mean-field and graph limits for collective dynamics models with time-varying weights
Nathalie Ayi and Nastassia Pouradier Duteil. Mean-field and graph limits for collective dynamics models with time-varying weights. Journal of Differential Equations, 299: 0 65--110, 2021
2021
-
[3]
Graphon mean field systems
Erhan Bayraktar, Suman Chakraborty, and Ruoyu Wu. Graphon mean field systems. The Annals of Applied Probability, 33 0 (5): 0 3587--3619, 2023
2023
-
[4]
Permutation equivariant neural controlled differential equations for dynamic graph representation learning
Torben Berndt, Benjamin Walker, Tiexin Qin, Jan St \"u hmer, and Andrey Kormilitzin. Permutation equivariant neural controlled differential equations for dynamic graph representation learning. Advances in Neural Information Processing Systems, 38: 0 98276--98311, 2026
2026
-
[5]
Brooks, Philip S
Heather Z. Brooks, Philip S. Chodrow, and Mason A. Porter. Emergence of polarization in a sigmoidal bounded-confidence model of opinion dynamics. SIAM Journal on Applied Dynamical Systems, 23 0 (2): 0 1442--1475, 2024
2024
-
[6]
Grand: Graph neural diffusion
Ben Chamberlain, James Rowbottom, Maria I Gorinova, Michael Bronstein, Stefan Webb, and Emanuele Rossi. Grand: Graph neural diffusion. In International Conference on Machine Learning, pages 1407--1418. PMLR, 2021
2021
-
[7]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[8]
GREAD : Graph neural reaction-diffusion networks
Jeongwhan Choi, Seoyoung Hong, Noseong Park, and Sung-Bae Cho. GREAD : Graph neural reaction-diffusion networks. In International Conference on Machine Learning, pages 5722--5747. PMLR, 2023
2023
-
[9]
Fan R. K. Chung. Spectral Graph Theory, volume 92 of CBMS Regional Conference Series in Mathematics. American Mathematical Society, 1997
1997
-
[10]
Diffusion and elastic equations on networks
Soon-Yeong Chung, Yun-Sung Chung, and Jong-Ho Kim. Diffusion and elastic equations on networks. Publications of the Research Institute for Mathematical Sciences, 43 0 (3): 0 699--726, 2007
2007
-
[11]
Some G ronwall type inequalities and applications
Sever Silvestru Dragomir. Some G ronwall type inequalities and applications. Science Direct Working Paper, 0 (S1574-0358): 0 04, 2003
2003
-
[12]
The fisher--kpp equation over simple graphs: Varied persistence states in river networks
Yihong Du, Bendong Lou, Rui Peng, and Maolin Zhou. The fisher--kpp equation over simple graphs: Varied persistence states in river networks. Journal of Mathematical Biology, 80: 0 1559--1616, 2020
2020
-
[13]
Convex analysis and variational problems
Ivar Ekeland and Roger Temam. Convex analysis and variational problems. SIAM, 1999
1999
-
[14]
Spatial-temporal graph ODE networks for traffic flow forecasting
Zheng Fang, Qingqing Long, Guojie Song, and Kunqing Xie. Spatial-temporal graph ODE networks for traffic flow forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 364--373, 2021
2021
-
[15]
A stable and scalable method for solving initial value PDEs with neural networks
Marc Finzi, Andres Potapczynski, Matthew Choptuik, and Andrew Gordon Wilson. A stable and scalable method for solving initial value PDEs with neural networks. arXiv preprint arXiv:2304.14994, 2023
-
[16]
R. A. Fisher. The wave of advance of advantageous genes. Annals of Eugenics, 7 0 (4): 0 355--369, 1937
1937
-
[17]
Global convergence in neural ODEs : Impact of activation functions
Tianxiang Gao, Siyuan Sun, Hailiang Liu, and Hongyang Gao. Global convergence in neural ODEs : Impact of activation functions. arXiv preprint arXiv:2509.22436, 2025
-
[18]
ANODE: Unconditionally Accurate Memory-Efficient Gradients for Neural ODEs
Amir Gholami, Kurt Keutzer, and George Biros. ANODE : Unconditionally accurate memory-efficient gradients for neural odes. arXiv preprint arXiv:1902.10298, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[20]
Opinion dynamics and bounded confidence models, analysis, and simulation
Rainer Hegselmann and Ulrich Krause. Opinion dynamics and bounded confidence models, analysis, and simulation. Journal of Artificial Societies and Social Simulation, 5 0 (3): 0 2, 2002
2002
-
[21]
Higher-order graphon neural networks: Approximation and cut distance
Daniel Herbst and Stefanie Jegelka. Higher-order graphon neural networks: Approximation and cut distance. arXiv preprint arXiv:2503.14338, 2025
-
[22]
Invasion fronts on graphs: The fisher--kpp equation on homogeneous trees and erd o s--r \'e nyi graphs
Aaron Hoffman and Matt Holzer. Invasion fronts on graphs: The fisher--kpp equation on homogeneous trees and erd o s--r \'e nyi graphs. Discrete and Continuous Dynamical Systems - Series B, 24 0 (2): 0 671--694, 2019
2019
-
[23]
Generalizing graph ODE for learning complex system dynamics across environments
Zijie Huang, Yizhou Sun, and Wei Wang. Generalizing graph ODE for learning complex system dynamics across environments. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 798--809, 2023
2023
-
[24]
Causal graph ODE : Continuous treatment effect modeling in multi-agent dynamical systems
Zijie Huang, Jeehyun Hwang, Junkai Zhang, Jinwoo Baik, Weitong Zhang, Dominik Wodarz, Yizhou Sun, Quanquan Gu, and Wei Wang. Causal graph ODE : Continuous treatment effect modeling in multi-agent dynamical systems. In Proceedings of the ACM Web Conference 2024, pages 4607--4617, 2024
2024
-
[25]
Sparse M onte C arlo method for nonlocal diffusion problems
Dmitry Kaliuzhnyi-Verbovetskyi and Georgi S Medvedev. Sparse M onte C arlo method for nonlocal diffusion problems. SIAM Journal on Numerical Analysis, 60 0 (6): 0 3001--3028, 2022
2022
-
[26]
Convergence and stability of graph convolutional networks on large random graphs
Nicolas Keriven, Alberto Bietti, and Samuel Vaiter. Convergence and stability of graph convolutional networks on large random graphs. Advances in Neural Information Processing Systems, 33: 0 21512--21523, 2020
2020
-
[27]
On neural differential equations
Patrick Kidger. On neural differential equations. arXiv preprint arXiv:2202.02435, 2022
-
[28]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[29]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
A. N. Kolmogorov, I. G. Petrovskii, and N. S. Piskunov. A study of the diffusion equation with increase in the amount of substance, and its application to a biological problem. Bulletin of Moscow University, Mathematics and Mechanics, 1 0 (6): 0 1--26, 1937
1937
-
[31]
Ana Lajmanovich and James A. Yorke. A deterministic model for gonorrhea in a nonhomogeneous population. Mathematical Biosciences, 28 0 (3--4): 0 221--236, 1976
1976
-
[32]
Limits, approximation and size transferability for GNNs on sparse graphs via graphops
Thien Le and Stefanie Jegelka. Limits, approximation and size transferability for GNNs on sparse graphs via graphops. Advances in Neural Information Processing Systems, 36: 0 41305--41342, 2023
2023
-
[33]
Transferability of spectral graph convolutional neural networks
Ron Levie, Wei Huang, Lorenzo Bucci, Michael Bronstein, and Gitta Kutyniok. Transferability of spectral graph convolutional neural networks. Journal of Machine Learning Research, 22 0 (272): 0 1--59, 2021
2021
-
[34]
Graph ODEs and beyond: A comprehensive survey on integrating differential equations with graph neural networks
Zewen Liu, Xiaoda Wang, Bohan Wang, Zijie Huang, Carl Yang, and Wei Jin. Graph ODEs and beyond: A comprehensive survey on integrating differential equations with graph neural networks. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, pages 6118--6128, 2025
2025
-
[35]
Large networks and graph limits, volume 60
L \'a szl \'o Lov \'a sz. Large networks and graph limits, volume 60. American Mathematical Society, 2012
2012
-
[36]
HOPE : High-order graph ODE for modeling interacting dynamics
Xiao Luo, Jingyang Yuan, Zijie Huang, Huiyu Jiang, Yifang Qin, Wei Ju, Ming Zhang, and Yizhou Sun. HOPE : High-order graph ODE for modeling interacting dynamics. In International Conference on Machine Learning, pages 23124--23139. PMLR, 2023
2023
-
[37]
Transferability of graph neural networks: an extended graphon approach
Sohir Maskey, Ron Levie, and Gitta Kutyniok. Transferability of graph neural networks: an extended graphon approach. Applied and Computational Harmonic Analysis, 63: 0 48--83, 2023
2023
-
[38]
The nonlinear heat equation on dense graphs and graph limits
Georgi S Medvedev. The nonlinear heat equation on dense graphs and graph limits. SIAM Journal on Mathematical Analysis, 46 0 (4): 0 2743--2766, 2014 a
2014
-
[39]
The nonlinear heat equation on W -random graphs
Georgi S Medvedev. The nonlinear heat equation on W -random graphs. Archive for Rational Mechanics and Analysis, 212 0 (3): 0 781--803, 2014 b
2014
-
[40]
Heterophilious dynamics enhances consensus
S \'e bastien Motsch and Eitan Tadmor. Heterophilious dynamics enhances consensus. SIAM Review, 56 0 (4): 0 577--621, 2014
2014
-
[41]
Derek Onken and Lars Ruthotto. Discretize-optimize vs. optimize-discretize for time-series regression and continuous normalizing flows. arXiv preprint arXiv:2005.13420, 2020
-
[42]
Thierry Paul and Emmanuel Tr \'e lat. From microscopic to macroscopic scale equations: mean field, hydrodynamic and graph limits. arXiv preprint arXiv:2209.08832, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Graph neural ordinary differential equations
Michael Poli, Stefano Massaroli, Junyoung Park, Atsushi Yamashita, Hajime Asama, and Jinkyoo Park. Graph neural ordinary differential equations. arXiv preprint arXiv:1911.07532, 2019
-
[44]
Graphon neural networks and the transferability of graph neural networks
Luana Ruiz, Luiz Chamon, and Alejandro Ribeiro. Graphon neural networks and the transferability of graph neural networks. Advances in Neural Information Processing Systems, 33: 0 1702--1712, 2020
2020
-
[45]
Graph-coupled oscillator networks
T Konstantin Rusch, Ben Chamberlain, James Rowbottom, Siddhartha Mishra, and Michael Bronstein. Graph-coupled oscillator networks. In International Conference on Machine Learning, pages 18888--18909. PMLR, 2022
2022
-
[46]
Do residual neural networks discretize neural ordinary differential equations? Advances in Neural Information Processing Systems, 35: 0 36520--36532, 2022
Michael Sander, Pierre Ablin, and Gabriel Peyr \'e . Do residual neural networks discretize neural ordinary differential equations? Advances in Neural Information Processing Systems, 35: 0 36520--36532, 2022
2022
-
[47]
The graph neural network model
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20 0 (1): 0 61--80, 2008
2008
-
[48]
The N -intertwined SIS epidemic network model
Piet Van Mieghem. The N -intertwined SIS epidemic network model. Computing, 93 0 (2--4): 0 147--169, 2011
2011
-
[49]
Virus spread in networks
Piet Van Mieghem, Jasmina Omic, and Robert Kooij. Virus spread in networks. IEEE/ACM Transactions on Networking, 17 0 (1): 0 1--14, 2009
2009
-
[50]
Correcting auto-differentiation in neural- ODE training
Yewei Xu, Shi Chen, and Qin Li. Correcting auto-differentiation in neural- ODE training. arXiv preprint arXiv:2306.02192, 2023
-
[51]
On the Convergence and Size Transferability of Continuous-depth Graph Neural Networks
Mingsong Yan, Charles Kulick, and Sui Tang. On the convergence and size transferability of continuous-depth graph neural networks. arXiv preprint arXiv:2510.03923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.