ReWorld: Learning Better Representations for World Action Models
Pith reviewed 2026-06-29 01:55 UTC · model grok-4.3
The pith
ReWorld improves world action models by directly supervising intermediate representations with three targeted losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
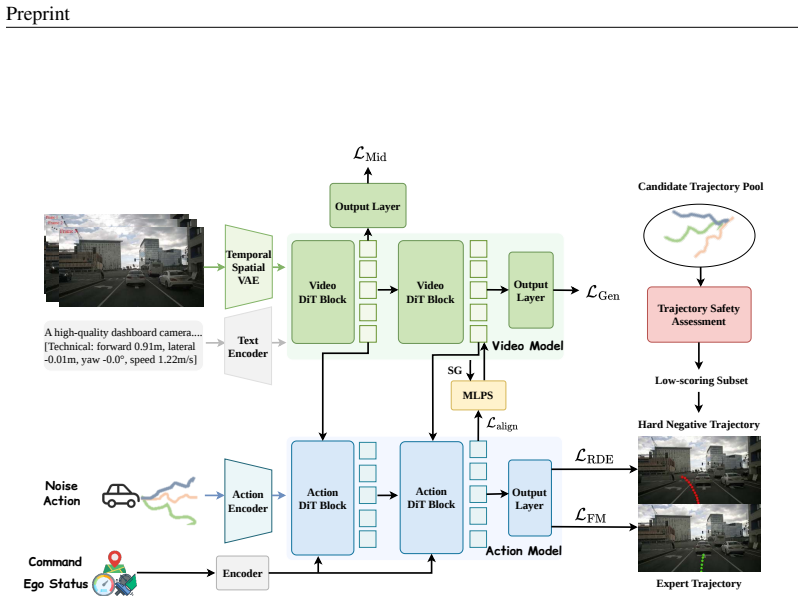
ReWorld is a representation learning framework that treats intermediate representations inside the Video DiT and Action DiT as direct targets of optimization rather than byproducts. It applies future-predictive supervision to the generation module's hidden states, aligns the planning module's states cross-modally with the video world representation, and further shapes them with hard-negative supervision around safety-critical boundaries. This addresses the gap left by output-only supervision and produces the measured gains in generation and planning.
What carries the argument
Three complementary supervision signals applied directly to intermediate representations: future-predictive loss on Video DiT, cross-modal alignment on Action DiT, and hard-negative loss for safety discrimination.
If this is right
- Fine-tuned video generation improves by 23.9 percent in FVD from 81.3 to 61.9.
- Closed-loop planning score rises from 89.1 to 90.4 without reinforcement learning or post-processing.
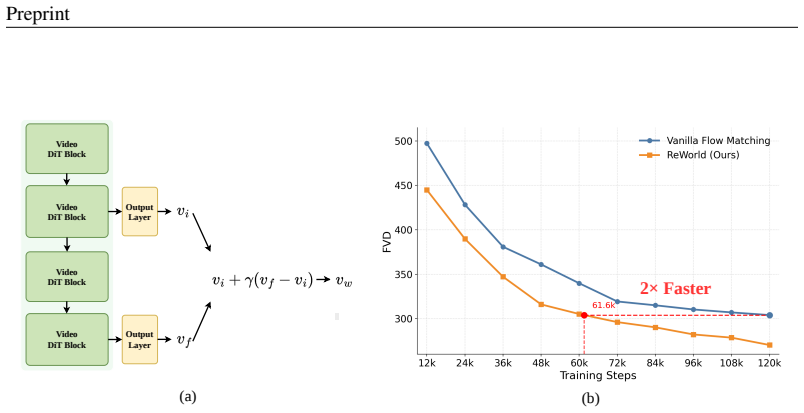
- From-scratch training converges approximately twice as fast.
Where Pith is reading between the lines
- The same intermediate-supervision pattern could be tested on world models outside autonomous driving.
- Existing representation-learning techniques may need modification to address cross-modal and safety-boundary requirements specific to action-conditioned driving models.
Load-bearing premise
The reported performance gains are produced by the three new intermediate-representation losses rather than by unmentioned differences in architecture, data, or training schedule.
What would settle it
An experiment that adds only the three ReWorld losses to an otherwise identical baseline world action model and measures the resulting change in FVD and PDMS.
Figures

read the original abstract
World Action Models (WAMs) model future environment evolution under action conditioning, offering a scalable paradigm for autonomous driving. However, existing approaches focus largely on model architecture design, and how a WAM can efficiently learn better world representations for planning remains underexplored. To address this gap, we propose ReWorld, the first representation learning framework specifically designed for autonomous-driving world action models. In WAMs, standard training supervises only the output ends of the generation and planning modules, leaving the intermediate representations that carry world knowledge to be shaped only indirectly, as byproducts of fitting these outputs. The core idea of ReWorld is to treat intermediate representations as direct targets of optimization, shaping them along three complementary dimensions. On the Video DiT responsible for generation, we impose future-predictive supervision on its intermediate representations. On the Action DiT responsible for planning, we first align its intermediate representations cross-modally with the video world representation, then further shape them to be discriminative around safety-critical boundaries via hard-negative supervision. In addition, we systematically analyze the effectiveness of existing representation learning methods in video generation world models, and discuss why their performance is limited on this task. Experiments on nuScenes and NAVSIM show that ReWorld improves fine-tuned video generation by 23.9% in FVD (81.3 to 61.9), raises closed-loop PDMS from 89.1 to 90.4 without any post-training such as RL or post-processing, and accelerates from-scratch convergence by approximately 2x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReWorld, a representation learning framework for World Action Models (WAMs) in autonomous driving. It introduces three intermediate-representation losses: future-predictive supervision on Video DiT intermediates, cross-modal alignment on Action DiT intermediates, and hard-negative supervision around safety-critical boundaries. Experiments on nuScenes and NAVSIM report a 23.9% FVD reduction in fine-tuned video generation (81.3 to 61.9), PDMS improvement from 89.1 to 90.4 in closed-loop planning without post-training, and ~2x faster from-scratch convergence.
Significance. If the gains are causally due to the proposed losses rather than uncontrolled factors, the work would demonstrate a practical way to directly optimize intermediate representations in world models, improving both generation and planning without RL or post-processing. This could influence scalable training of action-conditioned video models for driving.
major comments (2)
- [Experiments] Experiments section: The abstract directly attributes the FVD (81.3→61.9), PDMS (89.1→90.4), and convergence improvements to the three new losses, yet no ablation experiments are described that re-train the baseline WAM under identical architecture, data, optimizer, and schedule with only those losses removed. This control is required to support the causal claim.
- [Method] Method section: The implementation details of the future-predictive supervision (Video DiT), cross-modal alignment, and hard-negative supervision (Action DiT) must include explicit loss equations, layer selection, and weighting coefficients; without them the reproducibility of the reported deltas cannot be assessed.
minor comments (1)
- [Abstract] The abstract states that existing representation learning methods were systematically analyzed for limitations on this task; a dedicated table or subsection summarizing those findings and why they underperform would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to address the concerns about missing ablations and implementation details.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract directly attributes the FVD (81.3→61.9), PDMS (89.1→90.4), and convergence improvements to the three new losses, yet no ablation experiments are described that re-train the baseline WAM under identical architecture, data, optimizer, and schedule with only those losses removed. This control is required to support the causal claim.
Authors: We agree that controlled ablations isolating the contribution of the three proposed losses are required to substantiate the causal claims in the abstract. In the revised manuscript we will add experiments that retrain the baseline WAM from scratch under identical architecture, data, optimizer, and schedule while removing only the new losses. revision: yes
-
Referee: [Method] Method section: The implementation details of the future-predictive supervision (Video DiT), cross-modal alignment, and hard-negative supervision (Action DiT) must include explicit loss equations, layer selection, and weighting coefficients; without them the reproducibility of the reported deltas cannot be assessed.
Authors: We will expand the Method section to include the explicit loss equations for future-predictive supervision, cross-modal alignment, and hard-negative supervision, together with the chosen DiT layers and the numerical weighting coefficients applied in the combined objective. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces ReWorld as a representation learning framework adding three explicit intermediate losses (future-predictive on Video DiT, cross-modal alignment plus hard-negative on Action DiT) and reports empirical metric improvements on nuScenes/NAVSIM. No equations, self-citations, or uniqueness theorems are present in the supplied text. The performance deltas are presented as experimental outcomes rather than any mathematical prediction or quantity that reduces by construction to the inputs or to a fitted parameter. The central claim therefore remains an independent empirical assertion whose validity depends on experimental controls, not on definitional equivalence or self-referential fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chat- topadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
-
[2]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
-
[3]
Alan Baade, Eric Ryan Chan, Kyle Sargent, Changan Chen, Justin Johnson, Ehsan Adeli, and Li Fei- Fei. Latent forcing: Reordering the diffusion trajectory for pixel-space image generation.arXiv preprint arXiv:2602.11401,
-
[4]
Florent Bartoccioni, Elias Ramzi, Victor Besnier, Shashanka Venkataramanan, Tuan-Hung Vu, Yihong Xu, Loick Chambon, Spyros Gidaris, Serkan Odabas, David Hurych, et al. Vavim and vavam: Autonomous driving through video generative modeling.arXiv preprint arXiv:2502.15672,
-
[5]
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles.arXiv preprint arXiv:2106.11810,
-
[6]
Self-supervised flow matching for scalable multi-modal synthesis
Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Tor- ralba, and Robin Rombach. Self-supervised flow matching for scalable multi-modal synthesis. arXiv preprint arXiv:2603.06507,
-
[7]
Aligning visual foundation encoders to tokenizers for diffusion models
Bowei Chen, Sai Bi, Hao Tan, He Zhang, Tianyuan Zhang, Zhengqi Li, Yuanjun Xiong, Jianming Zhang, and Kai Zhang. Aligning visual foundation encoders to tokenizers for diffusion models. InThe Fourteenth International Conference on Learning Representations, 2025a. Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, an...
-
[8]
Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, et al. Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning.arXiv preprint arXiv:2502.13144,
-
[9]
Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601,
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601,
-
[10]
Xingtai Gui, Meijie Zhang, Tianyi Yan, Wencheng Han, Jiahao Gong, Feiyang Tan, Cheng-zhong Xu, and Jianbing Shen. Bridging scene generation and planning: Driving with world model via unifying vision and motion representation.arXiv preprint arXiv:2603.14948,
-
[11]
Xiangyu Guo, Zhanqian Wu, Kaixin Xiong, Ziyang Xu, Lijun Zhou, Gangwei Xu, Shaoqing Xu, Haiyang Sun, Bing Wang, Guang Chen, et al. Genesis: Multimodal driving scene generation with spatio-temporal and cross-modal consistency.arXiv preprint arXiv:2506.07497,
-
[12]
Ltx-video: Realtime video latent diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103,
-
[13]
Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023a
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shot- ton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023a. Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented ...
-
[14]
Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
-
[15]
Uniscene: Unified occupancy-centric driving scene gener- ation
15 Preprint Bohan Li, Jiazhe Guo, Hongsi Liu, Yingshuang Zou, Yikang Ding, Xiwu Chen, Hu Zhu, Feiyang Tan, Chi Zhang, Tiancai Wang, et al. Uniscene: Unified occupancy-centric driving scene gener- ation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 11971– 11981, 2025a. Bohan Li, Zhuang Ma, Dalong Du, Baorui Peng, Zhujin Lian...
-
[16]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
-
[17]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[18]
Driveva: Video action models are zero-shot drivers.arXiv preprint arXiv:2604.04198,
Mengmeng Liu, Diankun Zhang, Jiuming Liu, Jianfeng Cui, Hongwei Xie, Guang Chen, Hangjun Ye, Michael Ying Yang, Francesco Nex, and Hao Cheng. Driveva: Video action models are zero-shot drivers.arXiv preprint arXiv:2604.04198,
-
[19]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
-
[20]
Chaojun Ni, Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Wenkang Qin, Xinze Chen, Guanghong Jia, Guan Huang, and Wenjun Mei. Recondreamer-rl: Enhancing reinforcement learning via diffusion-based scene reconstruction.arXiv preprint arXiv:2508.08170,
-
[21]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
-
[22]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523,
-
[23]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301,
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301,
-
[24]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Sain- ing Xie. What matters for representation alignment: Global information or spatial structure? arXiv preprint arXiv:2512.10794,
-
[25]
Towards accurate generative models of video: A new metric & challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717,
-
[26]
Haiguang Wang, Daqi Liu, Hongwei Xie, Haisong Liu, Enhui Ma, Kaicheng Yu, Limin Wang, and Bing Wang. Mila: Multi-view intensive-fidelity long-term video generation world model for autonomous driving.arXiv preprint arXiv:2503.15875,
-
[27]
Junli Wang, Zhihua Hua, Xueyi Liu, Zebin Xing, Haochen Tian, Kun Ma, Hangjun Ye, Guang Chen, Long Chen, and Qichao Zhang. Beyond imitation: Learning safe end-to-end autonomous driving from hard negatives.arXiv preprint arXiv:2605.19771, 2026a. Lening Wang, Wenzhao Zheng, Yilong Ren, Han Jiang, Zhiyong Cui, Haiyang Yu, and Jiwen Lu. Occsora: 4d occupancy g...
-
[28]
Linbo Wang, Yupeng Zheng, Qiang Chen, Shiwei Li, Yichen Zhang, Zebin Xing, Qichao Zhang, Xiang Li, Deheng Qian, Pengxuan Yang, et al. Latent-wam: Latent world action modeling for end-to-end autonomous driving.arXiv preprint arXiv:2603.24581, 2026b. Mengmeng Wang, Dengyang Jiang, Liuzhuozheng Li, Yucheng Lin, Guojiang Shen, Xiangjie Kong, Yong Liu, Guang D...
-
[29]
Resim: Reliable world simulation for autonomous driving.arXiv preprint arXiv:2506.09981,
Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao, Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, and Li Chen. Resim: Reliable world simulation for autonomous driving.arXiv preprint arXiv:2506.09981,
-
[30]
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940,
-
[31]
Epona: Autoregressive diffusion world model for autonomous driving.arXiv preprint arXiv:2506.24113,
Kaiwen Zhang, Zhenyu Tang, Xiaotao Hu, Xingang Pan, Xiaoyang Guo, Yuan Liu, Jingwei Huang, Li Yuan, Qian Zhang, Xiao-Xiao Long, et al. Epona: Autoregressive diffusion world model for autonomous driving.arXiv preprint arXiv:2506.24113,
-
[32]
Diffusion transformers with repre- sentation autoencoders.arXiv preprint arXiv:2510.11690,
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with repre- sentation autoencoders.arXiv preprint arXiv:2510.11690,
-
[33]
Occ- world: Learning a 3d occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. Occ- world: Learning a 3d occupancy world model for autonomous driving. InEuropean conference on computer vision, pp. 55–72. Springer, 2024a. Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end autonomous driving.arXiv preprin...
-
[34]
Guiding a diffusion transformer with the internal dynamics of itself
18 Preprint Xingyu Zhou, Qifan Li, Xiaobin Hu, Hai Chen, and Shuhang Gu. Guiding a diffusion transformer with the internal dynamics of itself. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11536–11545, 2026a. Yang Zhou, Xiaofeng Wang, Hao Shao, Letian Wang, Guosheng Zhao, Jiangnan Shao, Jiagang Zhu, Tingdong Yu, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.