Booster Lab: A Data-Centric Pipeline for Learning Deployable Humanoid Locomotion Policies
Pith reviewed 2026-06-29 04:31 UTC · model grok-4.3
The pith
A data-centric pipeline integrates motion curation, real-to-sim adaptation, AMP reinforcement learning, and sim-to-real deployment to yield locomotion policies that transfer to real humanoid robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the integrated pipeline of motion data curation, real-to-sim model adaptation, AMP-based reinforcement learning, and sim-to-real deployment produces physically feasible and natural locomotion behaviors that transfer to real Booster T1 and K1 humanoid robots.
What carries the argument
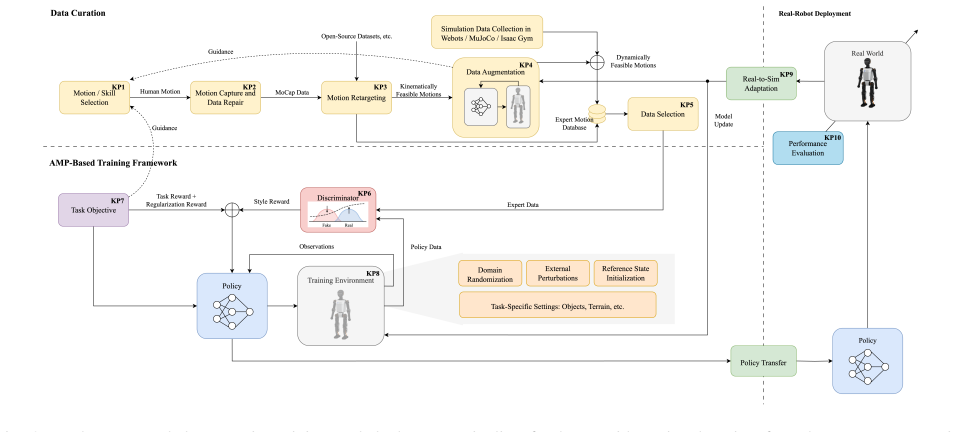
data-centric training and deployment pipeline that sequences motion data curation, real-to-sim model adaptation, AMP-based reinforcement learning, and sim-to-real deployment
If this is right
- Locomotion policies become deployable on the Booster T1 without platform-specific post-training adjustments.
- The same sequence supports preliminary transfer to the Booster K1 across different robot morphologies.
- Curated and adapted data overcomes scarcity of robot-feasible motion examples for training.
- AMP-based learning produces behaviors that remain both task-effective and physically plausible after deployment.
Where Pith is reading between the lines
- If the curation and adaptation steps scale, the pipeline could support training for additional gaits such as turning or uneven terrain without redesigning the learning stage.
- Standardizing the four-stage sequence might allow reuse of adapted motion priors across multiple humanoid platforms beyond the two tested here.
- The approach implies that data quality steps can substitute for some hardware-specific controller design in future deployments.
Load-bearing premise
Curated motion data combined with real-to-sim adaptation will produce policies that stay stable and natural after direct transfer to real hardware without extra tuning or safety layers.
What would settle it
Running the trained policy on the physical Booster T1 robot and observing repeated instability, falls, or gaits that deviate sharply from the simulated natural motion within the first 10-20 steps.
Figures



read the original abstract
Humanoid robot motion learning requires not only task-oriented control policies but also physically feasible and natural behaviors that can be transferred to real robots. However, robot-feasible motion data are often scarce: raw human demonstrations may be incompatible with the robot morphology, open-source clips vary in quality, and simulation-collected robot trajectories still require feasibility checking. To address these challenges, we propose a data-centric training and deployment pipeline that integrates motion data curation, real-to-sim model adaptation, AMP-based reinforcement learning, and sim-to-real deployment. We validate the framework on the Booster T1 robot and further provide preliminary cross-platform validation on Booster K1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Booster Lab, a data-centric pipeline integrating motion data curation, real-to-sim adaptation, AMP-based reinforcement learning, and sim-to-real deployment to produce physically feasible and natural humanoid locomotion policies that transfer to real robots. It claims validation on the Booster T1 platform with preliminary cross-platform results on the K1.
Significance. If the pipeline demonstrably yields stable, natural behaviors with high transfer success rates, it would address a key bottleneck in humanoid learning by systematically bridging human motion data to robot morphology and simulation, potentially reducing reliance on hardware-specific tuning.
major comments (1)
- [Abstract] Abstract: The central claim that the pipeline produces deployable policies that transfer successfully is load-bearing but unsupported by any quantitative transfer metrics (e.g., success rate over N trials, average time/distance before failure, torque tracking error, or explicit failure cases). The text only states that the framework is 'validated' and offers 'preliminary cross-platform validation' without numbers, tables, or analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for quantitative support of the transfer claims. We agree this is a substantive point and will strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the pipeline produces deployable policies that transfer successfully is load-bearing but unsupported by any quantitative transfer metrics (e.g., success rate over N trials, average time/distance before failure, torque tracking error, or explicit failure cases). The text only states that the framework is 'validated' and offers 'preliminary cross-platform validation' without numbers, tables, or analysis.
Authors: We acknowledge the concern. The current abstract and results section present validation primarily through qualitative description and video evidence. In the revised manuscript we will add explicit quantitative metrics for sim-to-real transfer on the T1 (including success rate over repeated trials, average distance/time before failure, torque tracking error, and documented failure modes) together with a corresponding table and analysis. The preliminary K1 results will likewise be quantified. revision: yes
Circularity Check
No circularity detected; pipeline is an empirical engineering workflow without self-referential derivations
full rationale
The paper presents a data-centric pipeline (motion curation + real-to-sim adaptation + AMP RL + sim-to-real) validated on Booster T1/K1 robots. No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes are described. The claim reduces to an integrated workflow whose success is asserted via validation rather than any quantity defined by the authors' own prior results. This is a standard systems paper whose central assertion is externally falsifiable via robot experiments and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,” inACM Transactions on Graphics (ToG), vol. 37, no. 4, 2018, pp. 1–14
2018
-
[2]
Learning human-to-humanoid real-time whole- body teleoperation,
T. He, Z. Luo, W. Xiao, C. Zhang, K. Kitani, C. Liu, and G. Shi, “Learning human-to-humanoid real-time whole- body teleoperation,” in2024 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 8944–8951
2024
-
[3]
arXiv preprint arXiv:2406.10454 , year=
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn, “Human- plus: Humanoid shadowing and imitation from humans,” arXiv preprint arXiv:2406.10454, 2024
-
[4]
Amp: Adversarial motion priors for stylized physics-based character control,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Adversarial motion priors for stylized physics-based character control,”ACM Transactions on Graphics (ToG), vol. 40, no. 4, pp. 1–20, 2021
2021
-
[5]
Adversarial motion priors make good substitutes for complex reward functions,
A. Escontrela, X. B. Peng, W. Yu, T. Zhang, A. Iscen, K. Goldberg, and P. Abbeel, “Adversarial motion priors make good substitutes for complex reward functions,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 25–32
2022
-
[6]
Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters,”ACM Transactions on Graphics (TOG), vol. 41, no. 4, pp. 1–17, 2022
2022
-
[7]
Motion retargeting for hu- manoid robots based on simultaneous morphing parameter identification and motion optimization,
K. Ayusawa and E. Yoshida, “Motion retargeting for hu- manoid robots based on simultaneous morphing parameter identification and motion optimization,”IEEE Transactions on Robotics, vol. 33, no. 6, pp. 1343–1357, 2017
2017
-
[8]
Whole-body geometric retargeting for humanoid robots,
K. Darvish, Y . Tirupachuri, G. Romualdi, L. Rapetti, D. Ferigo, F. J. A. Chavez, and D. Pucci, “Whole-body geometric retargeting for humanoid robots,” in2019 IEEE- RAS 19th International Conference on Humanoid Robots (Humanoids). IEEE, 2019, pp. 679–686
2019
-
[9]
Multicontact motion retargeting using whole-body optimization of full kinematics and sequential force equilibrium,
Q. Rouxel, K. Yuan, R. Wen, and Z. Li, “Multicontact motion retargeting using whole-body optimization of full kinematics and sequential force equilibrium,”IEEE/ASME Transactions on Mechatronics, vol. 27, no. 5, pp. 4188– 4198, 2022
2022
-
[10]
Retargeting matters: General motion retargeting for humanoid motion tracking,
J. P. Araujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu, “Retargeting matters: General motion retargeting for humanoid motion tracking,”arXiv preprint arXiv:2510.02252, 2025
-
[11]
ProtoMotions: Retargeting with PyRoki,
NVIDIA, “ProtoMotions: Retargeting with PyRoki,” https://protomotions.github.io/tutorials/workflows/ retargeting pyroki.html, 2025, online documentation, accessed: 2026-06-04
2025
-
[12]
Implicit kinodynamic motion retargeting for human-to-humanoid imitation learning,
X. Chen, H. Wu, S. Wu, M. Zhou, D. Xiang, and H. Zhang, “Implicit kinodynamic motion retargeting for human-to-humanoid imitation learning,”arXiv preprint arXiv:2509.15443, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
H. Wang, Q. Liao, B. Zhang, K. Ren, K. Sreenath, and X. Xiong, “Spark: Skeleton-parameter aligned retargeting on humanoid robots with kinodynamic trajectory optimiza- tion,”arXiv preprint arXiv:2603.11480, 2026
-
[14]
X. Zhang, S. Haener, V . Madabushi, and M. Tucker, “Kin- odynamic motion retargeting for humanoid locomotion via multi-contact whole-body trajectory optimization,”arXiv preprint arXiv:2603.09956, 2026
-
[15]
Feature-based vs. gan- based learning from demonstrations: When and why,
C. Li, M. Hutter, and A. Krause, “Feature-based vs. gan- based learning from demonstrations: When and why,”arXiv preprint arXiv:2507.05906, 2025
-
[16]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,” inAdvances in Neural Information Processing Systems, vol. 29, 2016
2016
-
[17]
Calm: Conditional adversarial latent models for directable virtual characters,
C. Tessler, Y . Kasten, Y . Guo, S. Mannor, G. Chechik, and X. B. Peng, “Calm: Conditional adversarial latent models for directable virtual characters,” inACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–9
2023
-
[18]
Per- petual humanoid control for real-time simulated avatars,
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu, “Per- petual humanoid control for real-time simulated avatars,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 895–10 904
2023
-
[19]
Twist: Teleoperated whole-body imitation system,
Y . Ze, Z. Chen, J. P. Ara ´ujo, Z.-a. Cao, X. B. Peng, J. Wu, and C. K. Liu, “Twist: Teleoperated whole-body imitation system,”arXiv preprint arXiv:2505.02833, 2025
-
[20]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac gym: High performance gpu-based physics simulation for robot learning,”arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
arXiv preprint arXiv:2404.05695 , year=
X. Gu, Y .-J. Wang, and J. Chen, “Humanoid-gym: Re- inforcement learning for humanoid robot with zero-shot sim2real transfer,”arXiv preprint arXiv:2404.05695, 2024
-
[22]
Booster gym: An end-to-end reinforcement learning framework for humanoid robot locomotion,
Y . Wang, P. Chen, X. Han, F. Wu, and M. Zhao, “Booster gym: An end-to-end reinforcement learning frame- work for humanoid robot locomotion,”arXiv preprint arXiv:2506.15132, 2025
-
[23]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
NVIDIA, M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Mu ˜noz, X. Yao, R. Zurbr ¨ugg et al., “Isaac lab: A gpu-accelerated simulation frame- work for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
TienKung-Lab: Direct IsaacLab workflow for legged robots,
Open-X-Humanoid, “TienKung-Lab: Direct IsaacLab workflow for legged robots,” https://github.com/ Open-X-Humanoid/TienKung-Lab, 2025, gitHub repository, accessed: 2026-06-04
2025
-
[25]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu, “Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion,” arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Improved training of wasserstein gans,
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. C. Courville, “Improved training of wasserstein gans,” Advances in neural information processing systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.