M³ QuestionIng: Multi-modal Multi-span Medical Question Answering
Pith reviewed 2026-06-30 18:07 UTC · model grok-4.3
The pith
M³QAFrame outputs medical answers by selecting relevant text spans and images from documents via transformer relevance scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
M³QAFrame takes the context, query, and images as input and outputs an answer containing both textual answers and relevant images. The text and image embeddings are processed using a transformer-based architecture to determine the sentence and image relevance.
What carries the argument
M³QAFrame, a transformer-based architecture that computes relevance scores for sentences and images from their embeddings to select spans for the answer.
If this is right
- Medical QA systems can now draw answers from both textual paragraphs and associated images within the same source document.
- Transformer embeddings enable joint scoring of sentence and image relevance for multi-span outputs.
- The curated dataset supplies labeled examples with user intent and query type to support training.
- Performance gains appear across multiple evaluation metrics relative to prior single-modality approaches.
Where Pith is reading between the lines
- Similar relevance scoring could apply to domains such as technical manuals or legal filings that mix text with diagrams.
- The intent and query-type labels might allow downstream systems to route or personalize responses without additional training.
- Real deployment would need to handle cases where images are low-quality or only loosely related to the query text.
Load-bearing premise
Adding image relevance scoring via transformer embeddings will produce meaningfully better answers in real clinical documents than text-only baselines.
What would settle it
A head-to-head test on clinical documents where answer quality metrics for the full model show no improvement over an otherwise identical text-only version.
Figures

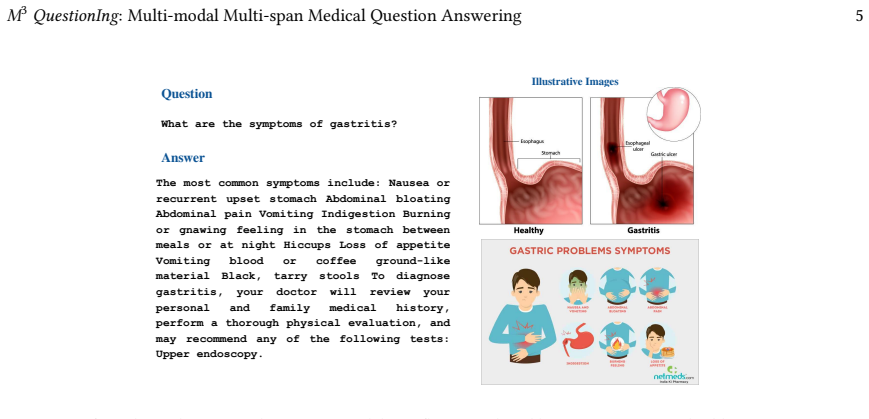
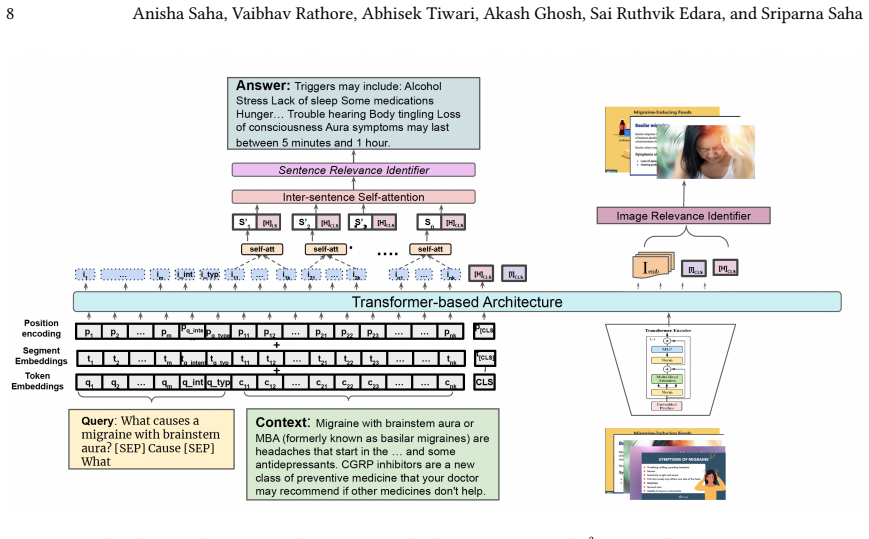
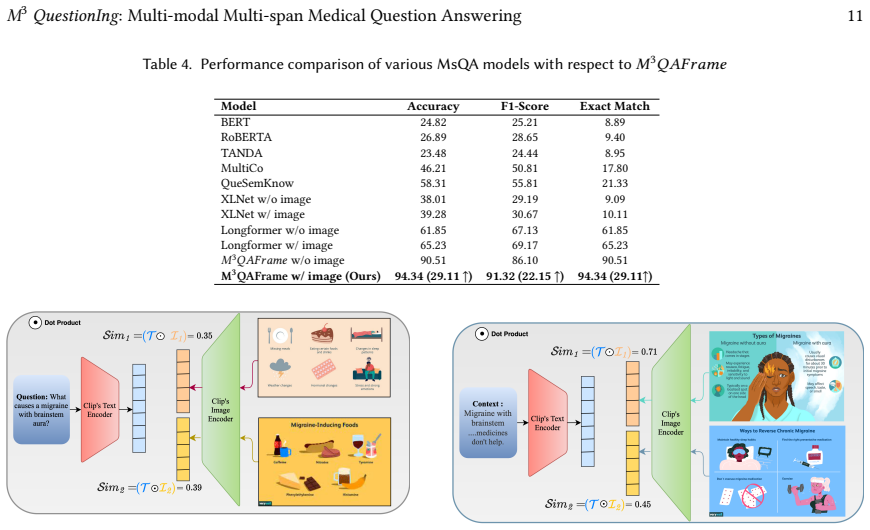


read the original abstract
The growing adoption of AI in healthcare, particularly in preventive care, highlights the critical need for accessibility and precision in Medical Question Answering (MedQA). In recent years, significant efforts have been made to develop multi-span medical question-answering systems, where the answer to a query may span multiple sections or paragraphs of a source document. However, existing systems fall short of aligning with real-world scenarios, where source documents often include both textual and visual content, requiring answers to incorporate images for better comprehension. To address this gap, we propose $M^3QAFrame$, a multi-modal, multi-span medical question-answering framework that leverages visual cues to enhance the generation of comprehensive answers drawn from diverse textual and visual spans. The model takes the context, query, and images as input and outputs an answer containing both textual answers and relevant images. The text and image embeddings are processed using a transformer-based architecture to determine the sentence and image relevance. We curate a multi-modal, multi-span medical question-answering ($M^3 QuestionIng$) dataset containing queries, medical contexts, associated medical images, and extractive answers. Additionally, each query-answer pair is labeled with user intent and query type to enhance query and context comprehension. Extensive experiments show that our approach consistently outperforms existing methods across various evaluation metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes M³QAFrame, a multi-modal multi-span medical QA framework that takes context, query, and images as input, uses transformer-based processing of text and image embeddings to score sentence and image relevance, and outputs extractive textual answers along with relevant images. It introduces the M³ QuestionIng dataset containing queries, medical contexts, associated images, extractive answers, and labels for user intent and query type. The authors claim that extensive experiments demonstrate consistent outperformance over existing methods across various evaluation metrics.
Significance. If the empirical claims hold with proper controls, the work could advance multi-modal QA systems for medical documents by incorporating visual content, addressing a noted gap in existing text-only multi-span approaches. The curation of a dataset with intent and query-type annotations is a concrete positive contribution that could support future research on query comprehension.
major comments (2)
- [Abstract] Abstract: the central claim that the approach 'consistently outperforms existing methods across various evaluation metrics' is asserted without any reported numbers, baselines, dataset statistics, error bars, or ablation results, rendering the contribution of the visual-cue component unverifiable from the provided text.
- [Model description / Experiments] Model and experiments description: no ablation isolating the transformer-based image relevance scoring is described, so any reported gains cannot be attributed to the multi-modal component rather than dataset differences, architecture scale, or other factors (directly relevant to the weakest assumption that visual cues produce meaningfully better answers).
minor comments (1)
- [Abstract] Abstract: the phrases 'M³QAFrame' and 'M³ QuestionIng' are introduced without an explicit expansion or definition on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and ablations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the approach 'consistently outperforms existing methods across various evaluation metrics' is asserted without any reported numbers, baselines, dataset statistics, error bars, or ablation results, rendering the contribution of the visual-cue component unverifiable from the provided text.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the performance claims. While the full manuscript reports detailed results (including baselines, metrics, and comparisons) in the Experiments section, the abstract itself summarizes without specific numbers. In the revised version we will update the abstract to report key metrics, baseline comparisons, and the magnitude of improvements to make the claims verifiable from the abstract. revision: yes
-
Referee: [Model description / Experiments] Model and experiments description: no ablation isolating the transformer-based image relevance scoring is described, so any reported gains cannot be attributed to the multi-modal component rather than dataset differences, architecture scale, or other factors (directly relevant to the weakest assumption that visual cues produce meaningfully better answers).
Authors: We acknowledge that a dedicated ablation isolating the transformer-based image relevance scoring would strengthen attribution of gains to the multi-modal component. Our current experiments compare the full model against text-only baselines, but we agree this does not fully isolate the image scoring module. We will add an ablation study in the revised manuscript that removes or disables the image relevance scoring component while keeping other factors fixed. revision: yes
Circularity Check
No circularity: framework proposal and dataset curation are self-contained
full rationale
The paper describes an applied system (M³QAFrame) that ingests context/query/images, computes transformer embeddings for relevance, and outputs multi-span answers plus images, plus a new curated dataset with intent labels. No equations, parameter-fitting steps, or predictions are presented that could reduce to inputs by construction. Performance claims rest on experiments against external baselines rather than any self-referential derivation or self-citation chain. This is the normal case for an engineering contribution and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Asma Ben Abacha, Yassine Mrabet, Mark Sharp, Travis R Goodwin, Sonya E Shooshan, and Dina Demner-Fushman. 2019. Bridging the gap between consumers’ medication questions and trusted answers. InMEDINFO 2019: Health and Wellbeing e-Networks for All. IOS Press, 25–29
2019
-
[2]
Rawan AlSaad, Alaa Abd-Alrazaq, Sabri Boughorbel, Arfan Ahmed, Max-Antoine Renault, Rafat Damseh, and Javaid Sheikh. 2024. Multimodal large language models in health care: applications, challenges, and future outlook.Journal of medical Internet research26 (2024), e59505
2024
-
[3]
Seongsu Bae, Daeyoung Kim, Jiho Kim, and Edward Choi. 2021. Question answering for complex electronic health records database using unified encoder-decoder architecture. InMachine learning for health. PMLR, 13–25
2021
-
[4]
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, Jungwoo Oh, Lei Ji, Eric Chang, Tackeun Kim, et al. 2023. Ehrxqa: A multi-modal question answering dataset for electronic health records with chest x-ray images.Advances in Neural Information Processing Systems36 (2023), 3867–3880
2023
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. 2023. Learning to exploit temporal structure for biomedical vision-language processing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15016–1502...
2023
-
[7]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Asma Ben Abacha and Dina Demner-Fushman. 2019. A question-entailment approach to question answering.BMC bioinformatics20 (2019), 1–23
2019
-
[9]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging Properties in Self- Supervised Vision Transformers. In2021 IEEE/CVF International Conference on Computer Vision (ICCV). 9630–9640. doi:10.1109/ICCV48922.2021.00951
-
[10]
Jun Chen, Jingbo Zhou, Zhenhui Shi, Bin Fan, and Chengliang Luo. 2019. Knowledge Abstraction Matching for Medical Question Answering. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 342–347. doi:10.1109/BIBM47256.2019.8982973
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy ...
-
[12]
Tripti Dodiya and Sonal Jain. 2016. Question classification for medical domain Question Answering system. In2016 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE). 204–207. doi:10.1109/WIECON-ECE.2016.8009118
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 [cs.CV] https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Siddhant Garg, Thuy Vu, and Alessandro Moschitti. 2019. TANDA: Transfer and Adapt Pre-Trained Transformer Models for Answer Sentence Selection. InAAAI Conference on Artificial Intelligence. https://api.semanticscholar.org/CorpusID:207853043
2019
-
[15]
Travis R Goodwin and Sanda M Harabagiu. 2016. Medical question answering for clinical decision support. InProceedings of the 25th ACM international on conference on information and knowledge management. 297–306
2016
-
[16]
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2021. Domain- Specific Language Model Pretraining for Biomedical Natural Language Processing.ACM Transactions on Computing for Healthcare3, 1 (Oct. 2021), 1–23. doi:10.1145/3458754
-
[17]
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. 2020. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. CLIPScore: A Reference-free Evaluation Metric for Image Captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association for Computational Linguis...
-
[19]
Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. 2019. Clinicalbert: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [20]
-
[21]
Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, and Zuozhu Liu. 2024. Med-MoE: Mixture of Domain-Specific Experts for Lightweight Medical Vision-Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024. 3843–3860
2024
-
[22]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2024. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [23]
-
[24]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. 2018. A dataset of clinically generated visual questions and answers about radiology images.Scientific data5, 1 (2018), 1–10
2018
-
[25]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics36, 4 (2020), 1234–1240
2020
-
[26]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2024. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems36 (2024)
2024
-
[27]
Haonan Li, Martin Tomko, Maria Vasardani, and Timothy Baldwin. 2022. MultiSpanQA: A dataset for multi-span question answering. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 1250–1260
2022
-
[28]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv:2301.12597 [cs.CV] https://arxiv.org/abs/2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
Tianwei Lin, Wenqiao Zhang, SIJING LI, Yuqian Yuan, Binhe Yu, Haoyuan Li, Wanggui He, Hao Jiang, Mengze Li, Siliang Tang, et al . [n. d.]. HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heterogeneous Knowledge Adaptation. In Forty-second International Conference on Machine Learning
-
[31]
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023. Pmc-clip: Contrastive language-image pre-training using biomedical documents. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 525–536. 18 Anisha Saha, Vaibhav Rathore, Abhisek Tiwari, Akash Ghosh, Sai Ruthvi...
2023
- [32]
-
[33]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruction tuning.Advances in neural information processing systems36 (2024)
2024
-
[34]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692 [cs.CL] https://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Jacek Lorkowski and Agnieszka Jugowicz. 2021. Shortage of physicians: a critical review.Medical Research and Innovation(2021), 57–62
2021
-
[36]
Qiuhao Lu, Dejing Dou, and Thien Nguyen. 2022. ClinicalT5: A generative language model for clinical text. InFindings of the Association for Computational Linguistics: EMNLP 2022. 5436–5443
2022
-
[37]
João Matos, Shan Chen, Siena Kathleen V. Placino, Yingya Li, Juan Carlos Climent Pardo, Daphna Idan, Takeshi Tohyama, David Restrepo, Luis Filipe Nakayama, José María Millet Pascual-Leone, Guergana K Savova, Hugo Aerts, Leo Anthony Celi, An-Kwok Ian Wong, Danielle Bitterman, and Jack Gallifant. 2025. WorldMedQA-V: a multilingual, multimodal medical examin...
-
[38]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alex...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Ben Peters, Vlad Niculae, and André F. T. Martins. 2019. Sparse Sequence-to-Sequence Models. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 1504–1519. doi:10.18653/v1/P19-1146
-
[40]
Richard M Scheffler and Daniel R Arnold. 2019. Projecting shortages and surpluses of doctors and nurses in the OECD: what looms ahead.Health Economics, Policy and Law14, 2 (2019), 274–290
2019
-
[41]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. 2025. Medgemma technical report.arXiv preprint arXiv:2507.05201(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Sheng Shen, Yaliang Li, Nan Du, Xian Wu, Yusheng Xie, Shen Ge, Tao Yang, Kai Wang, Xingzheng Liang, and Wei Fan. 2020. On the generation of medical question-answer pairs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8822–8829
2020
- [43]
- [44]
-
[45]
Abhisek Tiwari, Aman Bhansali, Sriparna Saha, Pushpak Bhattacharyya, Preeti Verma, and Minakshi Dhar. 2023. Local context is not enough! Towards Query Semantic and Knowledge Guided Multi-Span Medical Question Answering.. InECAI. 2354–2361
2023
-
[46]
Abhisek Tiwari, Manisimha Manthena, Sriparna Saha, Pushpak Bhattacharyya, Minakshi Dhar, and Sarbajeet Tiwari. 2022. Dr. can see: towards a multi-modal disease diagnosis virtual assistant. InProceedings of the 31st ACM international conference on information & knowledge management. 1935–1944
2022
-
[47]
Abhisek Tiwari, Anisha Saha, Sriparna Saha, Pushpak Bhattacharyya, and Minakshi Dhar. 2023. Experience and Evidence are the eyes of an excellent summarizer! Towards Knowledge Infused Multi-modal Clinical Conversation Summarization. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2452–2461
2023
-
[48]
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, et al
-
[49]
Towards conversational diagnostic artificial intelligence.Nature(2025), 1–9
2025
-
[50]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010
2017
-
[51]
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. 2022. MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing 2022 (2022), 3876–3887. https://api.semanticscholar.org/CorpusID:252992913
2022
-
[52]
Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, and Huaxiu Yao. [n. d.]. MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models. ([n. d.])
-
[53]
Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E Smith, Christopher Parisien, Colin Compas, Cheryl Martin, Mona G Flores, Ying Zhang, et al. 2022. Gatortron: A large clinical language model to unlock patient information from unstructured electronic health records. arXiv preprint arXiv:2203.03540(2022)
-
[54]
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019.XLNet: generalized autoregressive pretraining for language understanding. Curran Associates Inc., Red Hook, NY, USA
2019
-
[55]
Juan Manuel Zambrano Chaves, Shih-Cheng Huang, Yanbo Xu, Hanwen Xu, Naoto Usuyama, Sheng Zhang, Fei Wang, Yujia Xie, Mahmoud Khademi, Ziyi Yang, et al. 2025. A clinically accessible small multimodal radiology model and evaluation metric for chest X-ray findings.Nature Communications16, 1 (2025), 3108
2025
-
[56]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Qi Zhi Lim, Chin Poo Lee, Kian Ming Lim, and Ahmad Kamsani Samingan. 2024. UniRaG: Unification, Retrieval, and Generation for Multimodal Question Answering With Pre-Trained Language Models.IEEE Access12 (2024), 71505–71519. doi:10.1109/ACCESS.2024.3403101
-
[58]
Ming Zhu, Aman Ahuja, Da-Cheng Juan, Wei Wei, and Chandan K Reddy. 2020. Question answering with long multiple-span answers. InFindings of the Association for Computational Linguistics: EMNLP 2020. 3840–3849
2020
-
[59]
Ming Zhu, Aman Ahuja, Wei Wei, and Chandan K Reddy. 2019. A hierarchical attention retrieval model for healthcare question answering. InThe World Wide Web Conference. 2472–2482. 11 Appendix Zero-Shot Prompt 20 Anisha Saha, Vaibhav Rathore, Abhisek Tiwari, Akash Ghosh, Sai Ruthvik Edara, and Sriparna Saha Prompt:You are given a set of context sentences and...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.