Meta-learning as a principle for human-like visual representations
Pith reviewed 2026-06-30 01:25 UTC · model grok-4.3
The pith
Meta-learning across thousands of tasks yields visual representations that better predict human similarity judgments and brain activity than standard pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
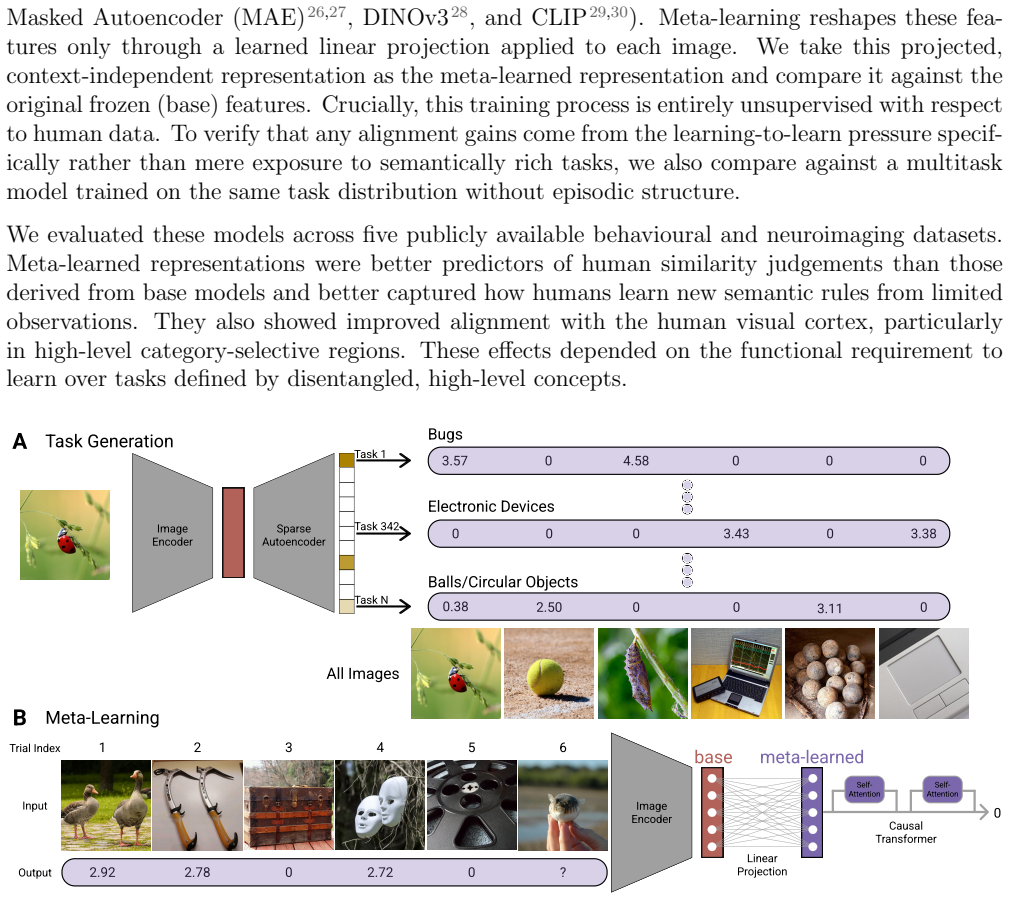
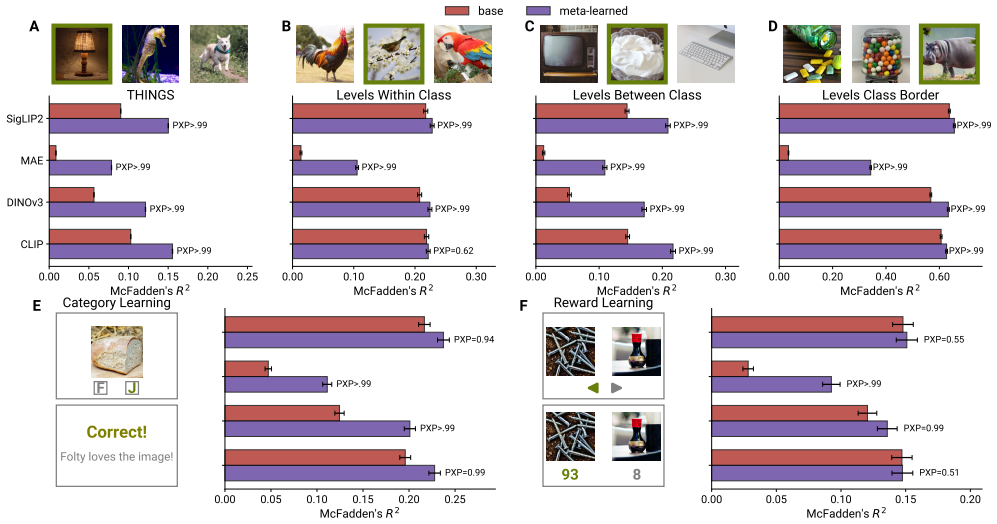
Training a sequence model across thousands of semantically rich tasks mapping images to high-level concepts, without supervision from human data, produces representations that better predict human similarity judgements, semantic rule learning, and high-level visual cortex than their pretrained base encoders.
What carries the argument
Meta-learning across a distribution of tasks that shapes representations to acquire new semantic relationships from few observations.
If this is right
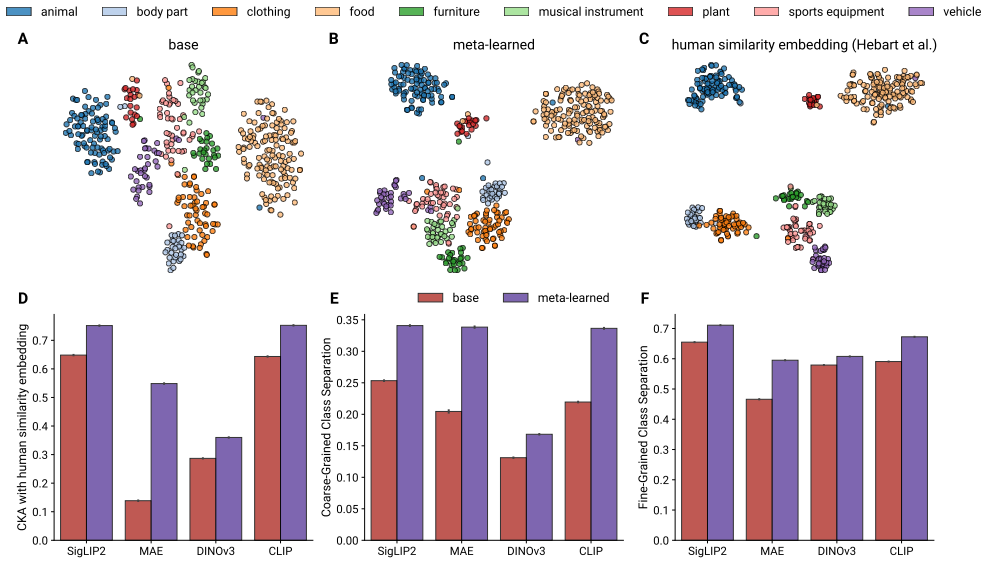
- Meta-learned representations better predict human similarity judgements than pretrained encoders.
- Meta-learned representations support improved semantic rule learning compared to pretrained encoders.
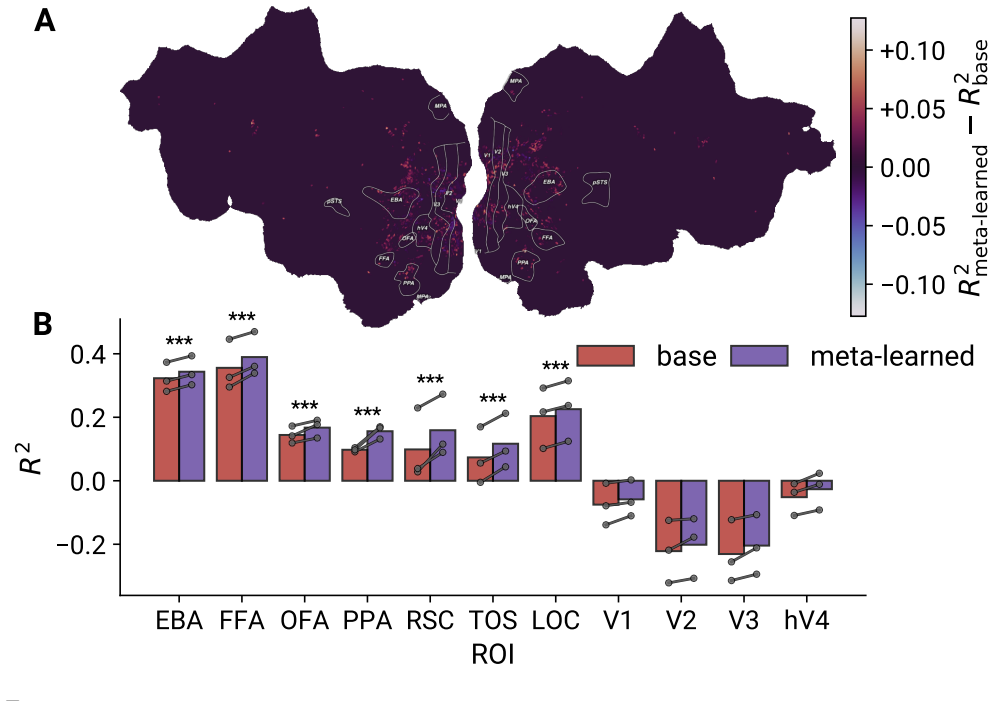
- Meta-learned representations show stronger alignment with high-level visual cortex responses.
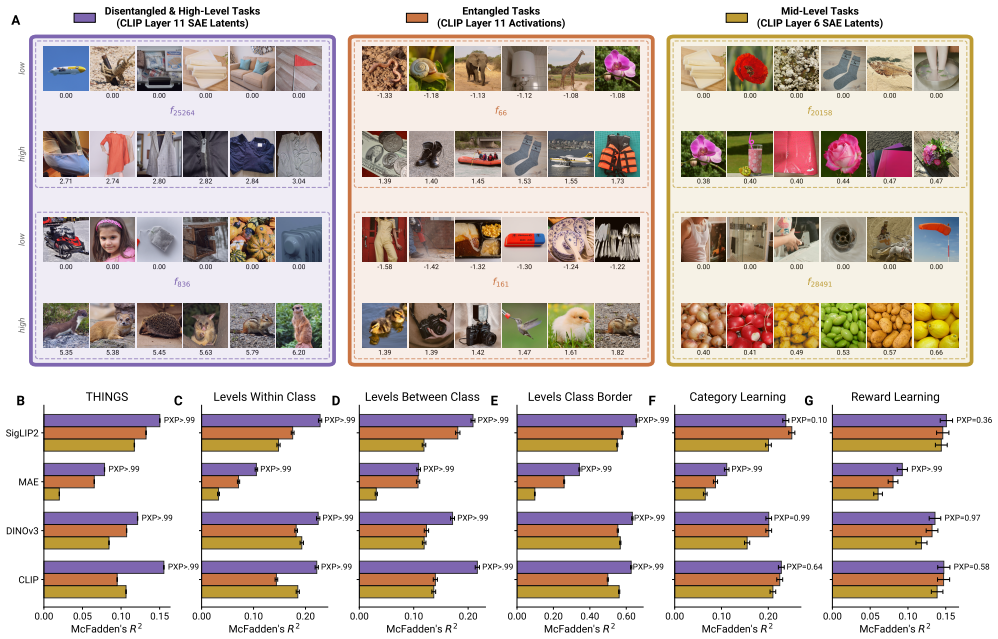
- Behavioural gains require disentangled, high-level task distributions.
- Brain alignment is driven primarily by the learning-to-learn pressure rather than task content alone.
Where Pith is reading between the lines
- Standard single-objective pretraining misses the open-ended adaptability that human vision exhibits.
- Meta-learning could be applied to other modalities to test whether similar pressures produce human-like representations.
- The approach highlights a possible reason current vision models struggle with rapid concept acquisition in new domains.
Load-bearing premise
The flexibility of human visual representations arises from meta-learning pressure that shapes them to acquire new tasks from few observations.
What would settle it
If a new set of human similarity judgments or brain scans shows the meta-learned model performing no better or worse than the base encoder, the central claim would be falsified.
Figures
read the original abstract
The structure of human visual representations underpins our capacity for adaptive behaviour. While pretrained neural networks model human visual representations with unprecedented success, a large discrepancy remains. We propose one reason: these networks optimise a single fixed objective, whereas human representations must support open-ended tasks. We hypothesise this flexibility arises from meta-learning (learning to learn), a pressure shaping representations to acquire new tasks from few observations. To test this, we train a sequence model, without any supervision from human data, across thousands of semantically rich tasks mapping images to high-level concepts. Compared to their pretrained base encoders, meta-learned representations better predict human similarity judgements, semantic rule learning, and high-level visual cortex. Behavioural gains depend on disentangled, high-level task distributions, while brain alignment is driven primarily by the learning-to-learn pressure. Our results suggest the flexibility of human visual representations reflects the functional demand to learn new semantic relationships on the fly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the flexibility of human visual representations arises from meta-learning pressure (learning to learn) that enables rapid acquisition of new tasks, rather than optimization of a single fixed objective. To test this, the authors train a sequence model without human supervision across thousands of semantically rich tasks that map images to high-level concepts. They report that the resulting meta-learned representations outperform their pretrained base encoders in predicting human similarity judgments, semantic rule learning performance, and alignment with high-level visual cortex activity. Behavioral gains are attributed to disentangled high-level task distributions, while brain alignment is attributed primarily to the learning-to-learn pressure.
Significance. If the central results hold after isolating the meta-learning mechanism, the work would offer a functional account of why human visual representations support open-ended adaptation, bridging computational neuroscience and machine learning. The unsupervised training regime on diverse tasks and the direct comparison to base encoders are strengths that could inform both model design and interpretations of cortical representations.
major comments (2)
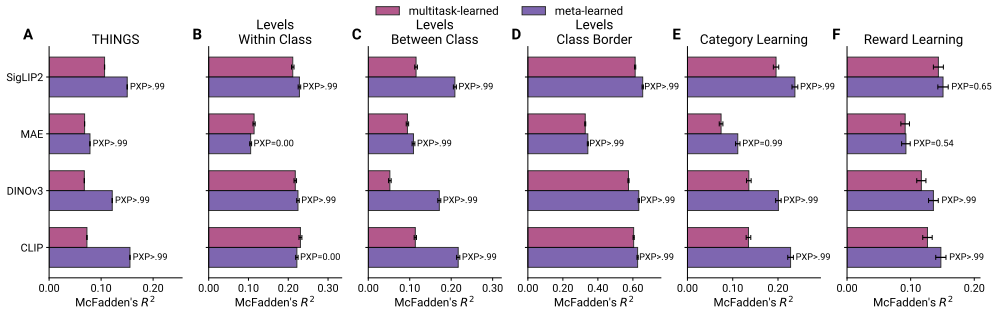
- [Methods] Methods section (task training and controls): The central claim attributes superior alignment to meta-learning pressure specifically, yet the manuscript provides no control condition that trains on the identical task set using a joint multi-task objective without the sequential meta-learning structure. Without this ablation, gains cannot be distinguished from benefits of multi-task exposure to disentangled semantic distributions, which directly undermines the load-bearing hypothesis that flexibility arises from the learning-to-learn mechanism.
- [Results] Results on brain alignment: The abstract states that brain alignment is driven primarily by learning-to-learn pressure while behavioral gains depend on task distributions, but the manuscript does not report the statistical interaction or ablation that would support separating these two effects; this separation is required to sustain the differential attribution.
minor comments (2)
- [Methods] The description of the sequence model architecture and how task sequences are constructed should include explicit pseudocode or a diagram to clarify the distinction between the meta-learning objective and standard multi-task training.
- [Figures] Figure captions for the human benchmark comparisons should report exact sample sizes, statistical tests, and effect sizes alongside the qualitative statements of improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the isolation of the meta-learning mechanism.
read point-by-point responses
-
Referee: [Methods] Methods section (task training and controls): The central claim attributes superior alignment to meta-learning pressure specifically, yet the manuscript provides no control condition that trains on the identical task set using a joint multi-task objective without the sequential meta-learning structure. Without this ablation, gains cannot be distinguished from benefits of multi-task exposure to disentangled semantic distributions, which directly undermines the load-bearing hypothesis that flexibility arises from the learning-to-learn mechanism.
Authors: We agree that the absence of a joint multi-task baseline on the identical task set limits the ability to isolate the sequential meta-learning structure from multi-task exposure. The current comparisons are to base encoders trained on standard objectives, but this does not fully address the referee's concern. We will add the requested joint multi-task control condition in the revised manuscript. revision: yes
-
Referee: [Results] Results on brain alignment: The abstract states that brain alignment is driven primarily by learning-to-learn pressure while behavioral gains depend on task distributions, but the manuscript does not report the statistical interaction or ablation that would support separating these two effects; this separation is required to sustain the differential attribution.
Authors: The differential attribution draws from observed patterns across experiments (behavioral sensitivity to task disentanglement versus brain alignment gains tied to the meta-learning procedure). We acknowledge that a formal statistical interaction test and supporting ablations are not currently reported. We will include these analyses in the revised manuscript to substantiate the separation of effects. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper trains sequence models on independent task distributions (images to high-level concepts) without human supervision, then compares meta-learned representations to pretrained encoders on separate human similarity judgements, rule learning tasks, and fMRI data. No equations or claims reduce a reported gain to a fitted parameter, self-citation chain, or definitional equivalence. Behavioural and brain-alignment results are presented as empirical outcomes of the training procedure against external data, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Meta-learning pressure shapes representations to support few-shot acquisition of new semantic tasks
Reference graph
Works this paper leans on
-
[1]
Deep neural networks: a new framework for modeling biological vision and brain information processing.Annual review of vision science1, 417–446 (2015)
Kriegeskorte, N. Deep neural networks: a new framework for modeling biological vision and brain information processing.Annual review of vision science1, 417–446 (2015)
2015
-
[2]
URLhttps://openreview.net/forum?id=Hiq7lUh4Yn
Sucholutsky, I.et al.Getting aligned on representational alignment.Transactions on Machine Learn- ing Research(2025). URLhttps://openreview.net/forum?id=Hiq7lUh4Yn
2025
-
[3]
Yamins, D. L. K.et al.Performance-optimized hierarchical models predict neural re- sponses in higher visual cortex.Proceedings of the National Academy of Sciences111, 8619–8624 (2014). URLhttps://www.pnas.org/doi/abs/10.1073/pnas.1403112111. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas.1403112111
-
[4]
Schrimpf, M.et al.Brain-score: Which artificial neural network for object recognition is most brain- like?BioRxiv407007 (2018)
2018
-
[5]
& Griffiths, T
Sucholutsky, I. & Griffiths, T. L. Alignment with human representations supports robust few-shot learning. InThirty-seventh Conference on Neural Information Processing Systems(2023). URL https://openreview.net/forum?id=HYGnmSLBCf
2023
-
[6]
Muttenthaler, L., Linhardt, L., Dippel, J., Vandermeulen, R. A. & Kornblith, S. Human alignment of neural network representations. InSVRHM 2022 Workshop @ NeurIPS(2022). URLhttps: //openreview.net/forum?id=b2DmQYY-XY
2022
-
[7]
S., Kay, K
Conwell, C., Prince, J. S., Kay, K. N., Alvarez, G. A. & Konkle, T. A large-scale examination of induc- tive biases shaping high-level visual representation in brains and machines.Nature Communications 15, 9383 (2024). URLhttps://www.nature.com/articles/s41467-024-53147-y
2024
-
[8]
Demircan, C.et al.Evaluating alignment between humans and neural network representations in image-based learning tasks.Advances in Neural Information Processing Systems37, 122406–122433 (2024)
2024
-
[9]
Nature647, 349–355 (2025)
Muttenthaler, L.et al.Aligning machine and human visual representations across abstraction levels. Nature647, 349–355 (2025)
2025
-
[10]
FEL, T., Rodriguez, I. F. R., Linsley, D. & Serre, T. Harmonizing the object recognition strategies of deep neural networks with humans. In Oh, A. H., Agarwal, A., Belgrave, D. & Cho, K. (eds.) Advances in Neural Information Processing Systems(2022). URLhttps://openreview.net/forum? id=ZYKWi6Ylfg
2022
-
[11]
InThirty-seventh Conference on Neural Information Processing Systems(2023)
Fu, S.et al.DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data. InThirty-seventh Conference on Neural Information Processing Systems(2023). URLhttps: //openreview.net/forum?id=DEiNSfh1k7
2023
-
[12]
URLhttps: //openreview.net/forum?id=NmlnmLYMZ4
Sundaram, S.et al.When does perceptual alignment benefit vision representations? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems(2024). URLhttps: //openreview.net/forum?id=NmlnmLYMZ4
2024
-
[13]
Roads, B. D. & Love, B. C. Enriching imagenet with human similarity judgments and psychological embeddings. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, 3547–3557 (2021)
2021
-
[14]
InThirty-seventh Conference on Neural Information Processing Systems(2023)
Muttenthaler, L.et al.Improving neural network representations using human similarity judgments. InThirty-seventh Conference on Neural Information Processing Systems(2023). URLhttps:// openreview.net/forum?id=Nh5dp6Uuvx
2023
-
[15]
Binz, M.et al.Meta-learned models of cognition.Behavioral and Brain Sciences47, e147 (2024)
2024
-
[16]
L.et al.Doing more with less: meta-reasoning and meta-learning in humans and machines.Current Opinion in Behavioral Sciences29, 24–30 (2019)
Griffiths, T. L.et al.Doing more with less: meta-reasoning and meta-learning in humans and machines.Current Opinion in Behavioral Sciences29, 24–30 (2019)
2019
-
[17]
X.et al.Prefrontal cortex as a meta-reinforcement learning system.Nature neuroscience 21, 860–868 (2018)
Wang, J. X.et al.Prefrontal cortex as a meta-reinforcement learning system.Nature neuroscience 21, 860–868 (2018)
2018
-
[18]
Lake, B. M. & Baroni, M. Human-like systematic generalization through a meta-learning neural network.Nature623, 115–121 (2023)
2023
-
[19]
K., Coda-Forno, J., Thalmann, M., Schulz, E
Jagadish, A. K., Coda-Forno, J., Thalmann, M., Schulz, E. & Binz, M. Human-like category learn- ing by injecting ecological priors from large language models into neural networks.arXiv preprint arXiv:2402.01821(2024)
-
[20]
Jagadish, A. K., Thalmann, M., Coda-Forno, J., Binz, M. & Schulz, E. Meta-learning ecological priors from large language models explains human learning and decision making.arXiv preprint arXiv:2509.00116(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, H., Ewart, A., Riggs, L., Huben, R. & Sharkey, L. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Bricken, T.et al.Towards Monosemanticity: Decomposing Language Models With Dictionary Learn- ing.Transformer Circuits Thread(2023)
2023
-
[23]
Elhage, N.et al.Toy Models of Superposition.Transformer Circuits Thread(2022)
2022
-
[24]
& Torralba, A
Bau, D., Zhou, B., Khosla, A., Oliva, A. & Torralba, A. Network dissection: Quantifying inter- pretability of deep visual representations. InProceedings of the IEEE conference on computer vision and pattern recognition, 6541–6549 (2017)
2017
-
[25]
Tschannen, M.et al.Siglip 2: Multilingual vision-language encoders with improved semantic under- standing, localization, and dense features.arXiv preprint arXiv:2502.14786(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
InProceedings of the IEEE/CVF International Conference on Computer Vision, 370–382 (2025)
Fan, D.et al.Scaling language-free visual representation learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, 370–382 (2025)
2025
-
[27]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16000–16009 (2022)
He, K.et al.Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16000–16009 (2022)
2022
-
[28]
Sim´ eoni, O.et al.Dinov3.arXiv preprint arXiv:2508.10104(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Ilharco, G.et al.OpenCLIP (2021). URLhttps://doi.org/10.5281/zenodo.5143773
-
[30]
InInter- national conference on machine learning, 8748–8763 (PmLR, 2021)
Radford, A.et al.Learning transferable visual models from natural language supervision. InInter- national conference on machine learning, 8748–8763 (PmLR, 2021)
2021
-
[31]
M., Perkuhn, J
Stoinski, L. M., Perkuhn, J. & Hebart, M. N. THINGSplus: New norms and metadata for the THINGS database of 1854 object concepts and 26,107 natural object images.Behavior Research Methods56, 1583–1603 (2024)
2024
-
[32]
N., Zheng, C
Hebart, M. N., Zheng, C. Y., Pereira, F. & Baker, C. I. Revealing the multidimensional mental representations of natural objects underlying human similarity judgements.Nature human behaviour 4, 1173–1185 (2020)
2020
-
[33]
N.et al.THINGS-data, a multimodal collection of large-scale datasets for investigating object representations in human brain and behavior.Elife12, e82580 (2023)
Hebart, M. N.et al.THINGS-data, a multimodal collection of large-scale datasets for investigating object representations in human brain and behavior.Elife12, e82580 (2023)
2023
-
[34]
Muttenthaler, L.et al.The Levels Dataset (2024)
2024
-
[35]
Multitask learning.Machine learning28, 41–75 (1997)
Caruana, R. Multitask learning.Machine learning28, 41–75 (1997)
1997
-
[36]
& Hinton, G
Van der Maaten, L. & Hinton, G. Visualizing data using t-SNE.Journal of machine learning research 9(2008)
2008
-
[37]
& Hinton, G
Kornblith, S., Norouzi, M., Lee, H. & Hinton, G. Similarity of neural network representations revis- ited. InInternational conference on machine learning, 3519–3529 (PMlR, 2019)
2019
-
[38]
Kubilius, J.et al.Brain-like object recognition with high-performing shallow recurrent ANNs.Ad- vances in neural information processing systems32(2019)
2019
-
[39]
Kietzmann, T. C.et al.Recurrence is required to capture the representational dynam- ics of the human visual system.Proceedings of the National Academy of Sciences116, 21854–21863 (2019). URLhttps://www.pnas.org/doi/abs/10.1073/pnas.1905544116. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas.1905544116
-
[40]
Vong, W. K., Wang, W., Orhan, A. E. & Lake, B. M. Grounded language acquisition through the eyes and ears of a single child.Science383, 504–511 (2024). URLhttps://www.science.org/doi/abs/ 10.1126/science.adi1374. eprint: https://www.science.org/doi/pdf/10.1126/science.adi1374
-
[41]
Mehrer, J., Spoerer, C. J., Jones, E. C., Kriegeskorte, N. & Kietzmann, T. C. An ecologically motivated image dataset for deep learning yields better models of human vision.Proceedings of the National Academy of Sciences118, e2011417118 (2021). URLhttps://www.pnas.org/doi/abs/10. 1073/pnas.2011417118. eprint: https://www.pnas.org/doi/pdf/10.1073/pnas.2011417118
-
[42]
& Alvarez, G
Konkle, T. & Alvarez, G. A. A self-supervised domain-general learning framework for human ventral stream representation.Nature Communications13, 491 (2022). URLhttps://doi.org/10.1038/ s41467-022-28091-4
2022
-
[43]
& Richards, B
Bakhtiari, S., Mineault, P., Lillicrap, T., Pack, C. & Richards, B. The functional special- ization of visual cortex emerges from training parallel pathways with self-supervised predictive learning. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P. S. & Vaughan, J. W. (eds.)Advances in Neural Information Processing Systems, vol. 34, 25164–25178 (Cur...
2021
-
[44]
J., Yamins, D
Tang, Y., Gokce, A., Al-Karkari, K. J., Yamins, D. & Schrimpf, M. Diverse perceptual representations across visual pathways emerge from a single objective.bioRxiv2025–07 (2025)
2025
-
[45]
Dasgupta, I., Schulz, E., Tenenbaum, J. B. & Gershman, S. J. A theory of learning to infer.Psycho- logical review127, 412 (2020)
2020
-
[46]
J., Schulz, E
Binz, M., Gershman, S. J., Schulz, E. & Endres, D. Heuristics from bounded meta-learned inference. Psychological review129, 1042 (2022)
2022
-
[47]
T., Grant, E., Smolensky, P., Griffiths, T
McCoy, R. T., Grant, E., Smolensky, P., Griffiths, T. L. & Linzen, T. Universal linguistic inductive biases via meta-learning.arXiv preprint arXiv:2006.16324(2020)
-
[48]
ViT Prisma: A Mechanistic Interpretability Library for Vision Transformers (2023)
Joseph, S. ViT Prisma: A Mechanistic Interpretability Library for Vision Transformers (2023). URL https://github.com/soniajoseph/vit-prisma. Publication Title: GitHub repository
2023
-
[49]
URLhttps://arxiv.org/abs/2504.19475
Joseph, S.et al.Prisma: An Open Source Toolkit for Mechanistic Interpretability in Vision and Video (2025). URLhttps://arxiv.org/abs/2504.19475. eprint: 2504.19475
-
[50]
InThe Thirteenth International Conference on Learning Representations(2025)
Gao, L.et al.Scaling and evaluating sparse autoencoders. InThe Thirteenth International Conference on Learning Representations(2025). URLhttps://openreview.net/forum?id=tcsZt9ZNKD
2025
-
[51]
In2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (2009)
Deng, J.et al.ImageNet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (2009)
2009
-
[52]
InEuropean conference on computer vision, 740–755 (Springer, 2014)
Lin, T.-Y.et al.Microsoft coco: Common objects in context. InEuropean conference on computer vision, 740–755 (Springer, 2014)
2014
-
[53]
Vaswani, A.et al.Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[54]
Su, J.et al.Roformer: Enhanced transformer with rotary position embedding.Neurocomputing568, 127063 (2024)
2024
-
[55]
Ba, J. L., Kiros, J. R. & Hinton, G. E. Layer normalization.arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
& Schmidhuber, J
Hochreiter, S. & Schmidhuber, J. Long short-term memory.Neural computation9, 1735–1780 (1997)
1997
-
[57]
& Cipolla, R
Kendall, A., Gal, Y. & Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition, 7482–7491 (2018)
2018
-
[58]
Defazio, A.et al.The road less scheduled.Advances in Neural Information Processing Systems37, 9974–10007 (2024)
2024
-
[59]
PyTorch Image Models (2019)
Wightman, R. PyTorch Image Models (2019). URLhttps://github.com/rwightman/ pytorch-image-models. Publication Title: GitHub repository
2019
-
[60]
Conditional logit analysis of qualitative choice behavior (1972)
McFadden, D. Conditional logit analysis of qualitative choice behavior (1972)
1972
-
[61]
N.et al.THINGS: A database of 1,854 object concepts and more than 26,000 naturalistic object images.PloS one14, e0223792 (2019)
Hebart, M. N.et al.THINGS: A database of 1,854 object concepts and more than 26,000 naturalistic object images.PloS one14, e0223792 (2019)
2019
-
[62]
InProceedings of the Annual Meeting of the Cognitive Science Society, vol
Demircan, C.et al.Decision-making with naturalistic options. InProceedings of the Annual Meeting of the Cognitive Science Society, vol. 44 (2022)
2022
-
[63]
E., Friston, K
Rigoux, L., Stephan, K. E., Friston, K. J. & Daunizeau, J. Bayesian model selection for group studies—revisited.Neuroimage84, 971–985 (2014)
2014
-
[64]
& Norouzi, M
Kornblith, S., Chen, T., Lee, H. & Norouzi, M. Why do better loss functions lead to less transferable features?Advances in Neural Information Processing Systems34, 28648–28662 (2021). Supplementary Information Meta-learning as a principle for human-like visual representations 1 Robustness to architectural variations We investigated whether the emergence o...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.