Digitizing Coaching Intelligence: An Agentic Framework for Holistic Athlete Profiling using VLM and RAG
Pith reviewed 2026-06-30 01:00 UTC · model grok-4.3
The pith
A hybrid agentic system merges computer vision and vision-language models to generate SAI-aligned holistic athlete profiles from video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
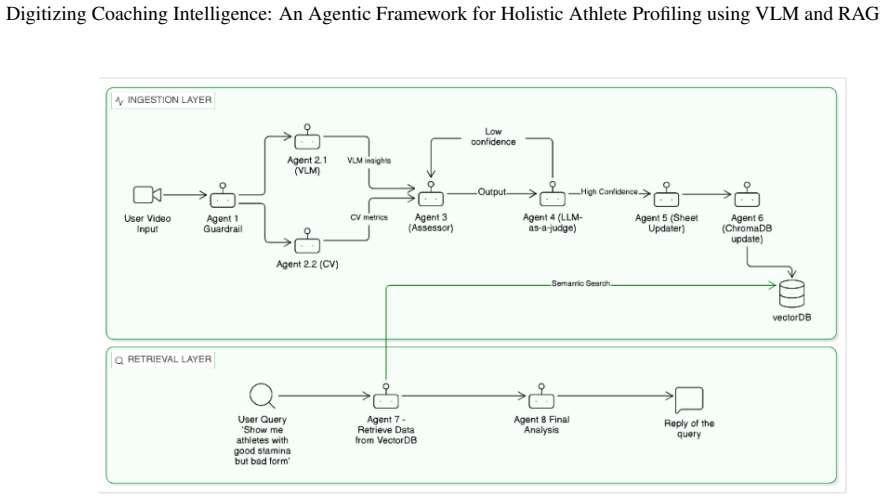
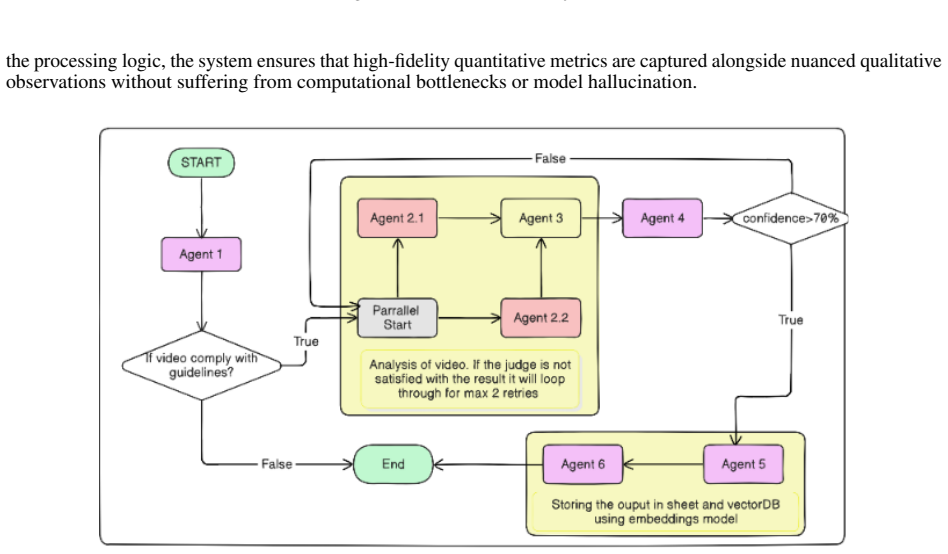
The authors claim their dual-pipeline architecture, orchestrated through LangGraph, synthesizes CV kinematic data with VLM semantic reasoning, employs a 3x3 Smart Grid chunking strategy to cut overhead by over 88 percent, runs an LLM-as-a-Judge self-correction loop to limit hallucination, and stores results in a dual-persistence RAG system with ChromaDB to support semantic searches while strictly following SAI assessment protocols.
What carries the argument
The LLM-based hybrid agentic framework with LLM-as-a-Judge self-correction loop and dual-persistence RAG pipeline that integrates MediaPipe kinematics and Llama-4-scout semantic analysis.
Load-bearing premise
The autonomous LLM-as-a-Judge self-correction loop can reliably cross-reference quantitative and qualitative metrics to mitigate hallucination and guarantee alignment with SAI protocols.
What would settle it
A side-by-side comparison on the same set of athlete videos where expert human coaches score qualitative markers such as form degradation and core rigidity, then measure agreement percentage and error rates against the framework's outputs.
Figures

read the original abstract
Athlete assessment is a critical process for tracking physical progress and identifying elite talent. However, during mass recruitment drives, traditional methods rely on manual observation, which is inherently subjective and unscalable, or basic computer vision (CV) systems limited to quantitative repetition counting. These standard approaches lack the "coaching intelligence" required to evaluate qualitative physiological markers such as form degradation, spinal articulation, and fatigue. This paper presents a novel, LLM-based hybrid agentic framework for automated, holistic athlete profiling that strictly aligns with the Sports Authority of India (SAI) assessment protocols. Orchestrated via LangGraph, our dual-pipeline architecture synthesizes the geometric precision of CV (MediaPipe) for kinematic tracking with the semantic reasoning of Vision-Language Models (Llama-4-scout). To overcome the latency and token constraints associated with multimodal video processing, we introduce a 3 X 3 "Smart Grid" temporal chunking strategy, reducing computational overhead by over 88% while preserving critical temporal continuity. To ensure data integrity and mitigate hallucination, the framework pioneers an autonomous "LLM-as-a-Judge" self-correction loop that cross-references quantitative and qualitative metrics before persistence. Finally, we implement a dual-persistence Retrieval-Augmented Generation (RAG) pipeline utilizing a vector search engine (ChromaDB). This enables coaches to bypass rigid SQL databases and perform complex semantic queries (e.g., "Identify athletes with high endurance but poor core rigidity") using natural language. Experimental results demonstrate that this multi-agent approach significantly bridges the gap between raw biometric tracking and actionable coaching insights, offering a scalable, objective solution for national talent identification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent framework for automated, holistic athlete profiling aligned with Sports Authority of India (SAI) protocols. It combines MediaPipe-based kinematic tracking with Llama-4-scout VLM reasoning, orchestrated via LangGraph. Key innovations include a 3x3 Smart Grid temporal chunking strategy claimed to reduce overhead by over 88%, an autonomous LLM-as-a-Judge self-correction loop to mitigate hallucination by cross-referencing quantitative and qualitative metrics, and a dual-persistence RAG pipeline with ChromaDB enabling natural-language semantic queries on athlete data. The abstract asserts that experimental results demonstrate the approach significantly bridges raw biometric tracking and actionable coaching insights for scalable national talent identification.
Significance. If the empirical claims were substantiated, the work could represent a meaningful step toward objective, scalable AI-assisted talent identification in sports science by integrating CV precision with semantic reasoning. The design of the Smart Grid chunking and self-correction mechanisms, if validated, would address practical constraints in multimodal processing. However, the manuscript supplies no supporting data, so any assessment of significance remains conditional on future validation.
major comments (3)
- [Abstract] Abstract: The central claim that 'Experimental results demonstrate that this multi-agent approach significantly bridges the gap between raw biometric tracking and actionable coaching insights' is unsupported; the manuscript provides no quantitative metrics, baselines, error rates, ablation studies, inter-rater agreement with human coaches, or comparisons to manual SAI scoring.
- [Abstract] Abstract: The asserted 'over 88%' computational overhead reduction from the 3 X 3 Smart Grid temporal chunking strategy is presented without any timing benchmarks, token counts, ablation against full-video processing, or explicit calculation showing how the chunking preserves temporal continuity while achieving the reduction.
- [Abstract] Abstract (final paragraph): The claim that the LLM-as-a-Judge self-correction loop 'mitigate[s] hallucination' and 'ensure[s] data integrity' and 'guarantee[s] alignment with SAI protocols' rests on an untested axiom; no validation experiments, failure cases, or comparison to independent human judgment are reported.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We acknowledge that the abstract contains several claims that are not supported by quantitative evidence or validation experiments in the current manuscript, which focuses on describing the proposed framework architecture and its alignment with SAI protocols. We will revise the manuscript to qualify or remove unsupported assertions and add appropriate sections on limitations and future empirical work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experimental results demonstrate that this multi-agent approach significantly bridges the gap between raw biometric tracking and actionable coaching insights' is unsupported; the manuscript provides no quantitative metrics, baselines, error rates, ablation studies, inter-rater agreement with human coaches, or comparisons to manual SAI scoring.
Authors: We agree that this claim is overstated given the absence of supporting quantitative results. The manuscript presents the design of the hybrid agentic framework rather than a completed empirical evaluation. We will revise the abstract to state that the framework is intended to bridge this gap and add a dedicated Limitations and Future Work section that outlines planned experiments including the metrics suggested by the referee. revision: yes
-
Referee: [Abstract] Abstract: The asserted 'over 88%' computational overhead reduction from the 3 X 3 Smart Grid temporal chunking strategy is presented without any timing benchmarks, token counts, ablation against full-video processing, or explicit calculation showing how the chunking preserves temporal continuity while achieving the reduction.
Authors: The 88% figure originates from an internal estimate of reduced VLM token processing due to operating on 9 temporal chunks instead of full video. We concede that the manuscript lacks the required benchmarks and explicit derivation. We will either remove the specific percentage or add a new subsection providing the calculation details, token estimates, and explanation of temporal continuity preservation. revision: yes
-
Referee: [Abstract] Abstract (final paragraph): The claim that the LLM-as-a-Judge self-correction loop 'mitigate[s] hallucination' and 'ensure[s] data integrity' and 'guarantee[s] alignment with SAI protocols' rests on an untested axiom; no validation experiments, failure cases, or comparison to independent human judgment are reported.
Authors: We accept that these effectiveness claims for the self-correction loop lack empirical support in the manuscript. The loop is architecturally designed to cross-reference quantitative CV outputs with VLM qualitative assessments, but no validation data is provided. We will revise the wording to describe the intended function of the mechanism and expand the discussion to include its design rationale plus plans for future human-judgment comparisons. revision: yes
Circularity Check
No circularity in derivation chain; framework description lacks equations or self-referential reductions
full rationale
The paper is a system-description manuscript presenting an agentic architecture (LangGraph orchestration, MediaPipe + Llama-4-scout, Smart Grid chunking, LLM-as-Judge loop, ChromaDB RAG) aligned to SAI protocols. No mathematical derivations, first-principles predictions, fitted parameters, or equations appear in the provided text. The abstract's reference to 'experimental results demonstrate...' is a claim of empirical outcome rather than a derivation that reduces to its own inputs by construction. None of the six enumerated circularity patterns apply: no self-definitional X defined via Y, no fitted input relabeled as prediction, no load-bearing self-citation, no uniqueness theorem imported from the same authors, no ansatz smuggled via citation, and no renaming of a known result. The central claims rest on unshown experiments, but that is an evidence gap, not a circular reduction of the derivation chain to its inputs. Score 0 is the appropriate finding for a self-contained descriptive framework without the specified circular structures.
Axiom & Free-Parameter Ledger
free parameters (1)
- 3 X 3 Smart Grid temporal chunking
axioms (2)
- ad hoc to paper LLM-as-a-Judge self-correction loop reliably mitigates hallucination and ensures data integrity
- domain assumption Framework strictly aligns with SAI assessment protocols
invented entities (2)
-
Smart Grid temporal chunking strategy
no independent evidence
-
LLM-as-a-Judge self-correction loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on rag with llms.Procedia computer science, 246:3781–3790, 2024
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. A survey on rag with llms.Procedia computer science, 246:3781–3790, 2024
2024
-
[2]
Ansar W, S. Goswami, and A. Chakrabarti. From transformers to llms: A systematic survey of efficiency considerations in nlp. arXiv preprint arXiv:2406.16893, 2025
-
[3]
M. J. Ferdous et al. Fitcam: Detecting and counting repetitive exercises with deep learning.Journal of Big Data, 11(45), 2024
2024
-
[4]
Research on sit-up counting method and system based on human skeleton key point detection
Zhiming Shi et al. Research on sit-up counting method and system based on human skeleton key point detection. Quality in Sport, 24:55408, 2024
2024
-
[5]
Imagery based parametric classification of correct and incorrect motion for push-up counter using openpose
Ho-Jun Park, Jang-Woon Baek, and Jong-Hwan Kim. Imagery based parametric classification of correct and incorrect motion for push-up counter using openpose. In2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), pages 1389–1394. IEEE, 2020
2020
-
[6]
Fitness action counting algorithm based on pose estimation
Menghao Wang and Weiwei Kong. Fitness action counting algorithm based on pose estimation. InProceedings of the 2024 7th International Conference on Artificial Intelligence and Pattern Recognition (AIPR ’24), pages 523–528, New York, NY , USA, 2024. Association for Computing Machinery. 15 Digitizing Coaching Intelligence: An Agentic Framework for Holistic ...
2024
-
[7]
Deep learning approaches for workout repetition counting and validation.Pattern Recognition Letters, 151:259–266, 2021
Bruno Ferreira et al. Deep learning approaches for workout repetition counting and validation.Pattern Recognition Letters, 151:259–266, 2021
2021
-
[8]
Testing and profiling athletes: recommendations for test selection, implementation, and maximizing information.Strength & Conditioning Journal, 46(2):159–179, 2024
Jonathon Weakley, Georgia Black, Shaun McLaren, Sean Scantlebury, Timothy J Suchomel, Eric McMahon, David Watts, and Dale B Read. Testing and profiling athletes: recommendations for test selection, implementation, and maximizing information.Strength & Conditioning Journal, 46(2):159–179, 2024
2024
- [9]
-
[10]
T. T. Nguyen et al. Pushup counting and evaluating based on human keypoint detection. In2022 9th NAFOSTED Conference on Information and Computer Science (NICS). IEEE, 2022
2022
-
[11]
A novel vision-based tracking algorithm for a human-following mobile robot.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(7):1415–1427, 2016
Meenakshi Gupta, Swagat Kumar, Laxmidhar Behera, and Venkatesh K Subramanian. A novel vision-based tracking algorithm for a human-following mobile robot.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(7):1415–1427, 2016
2016
-
[12]
S. R. Khanal et al. A review on computer vision technology for physical exercise monitoring.Algorithms, 15(12):444, 2022
2022
-
[13]
Christopher Koch. From governance norms to enforceable controls: A layered translation method for runtime guardrails in agentic ai. arXiv preprint arXiv:2604.05229, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Dongrui Liu et al. Agentdog: A diagnostic guardrail framework for ai agent safety and security. arXiv preprint arXiv:2601.18491, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
The rise of agentic ai: implications, concerns, and the path forward.IEEE Intelligent Systems, 40(2):8–14, 2025
San Murugesan. The rise of agentic ai: implications, concerns, and the path forward.IEEE Intelligent Systems, 40(2):8–14, 2025
2025
-
[16]
Spfresh: Incremental in-place update for billion-scale vector search
Yuming Xu, Hengyu Liang, Jin Li, Shuotao Xu, Qi Chen, Qianxi Zhang, Cheng Li, Ziyue Yang, Fan Yang, Yuqing Yang, et al. Spfresh: Incremental in-place update for billion-scale vector search. InProceedings of the 29th Symposium on Operating Systems Principles, pages 545–561, 2023
2023
-
[17]
Vector search with openai embeddings: Lucene is all you need
Jasper Xian, Tommaso Teofili, Ronak Pradeep, and Jimmy Lin. Vector search with openai embeddings: Lucene is all you need. InProceedings of the 17th ACM International Conference on Web Search and Data Mining, pages 1090–1093, 2024
2024
-
[18]
B. Jin, J. Yoon, J. Han, and S. O. Arik. Long-context llms meet rag: Overcoming challenges for long inputs in rag. InProceedings of the 13th International Conference on Learning Representations (ICLR), 2025
2025
-
[19]
Rl-vlm-f: Reinforcement learning from vision language foundation model feedback,
Y . Wang et al. Rl-vlm-f: Reinforcement learning from vision language foundation model feedback. arXiv preprint arXiv:2402.03681, 2024. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.