Beyond the Mean: Three-Axis Fidelity for Aligning LLM-Based Survey Simulators from Small Pilot Data
Pith reviewed 2026-06-30 09:48 UTC · model grok-4.3
The pith
Fine-tuning on small pilot samples balances three fidelity axes in LLM survey simulators but varies across subsamples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a small pilot sample of human responses, fine-tuning an LLM recovers the statistical characteristics of the broader population along structural, marginal, and individual fidelity axes in a more balanced way than prompting or rectification, although the levels of fidelity achieved can vary across different subsamples from the pilot.
What carries the argument
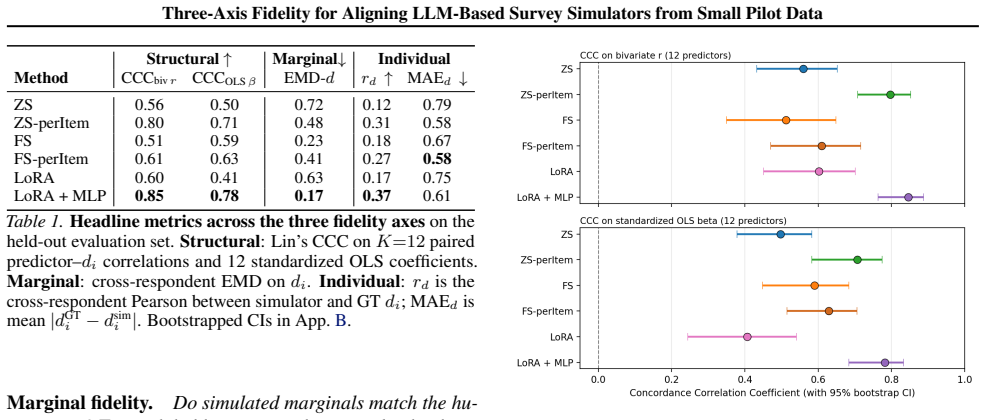
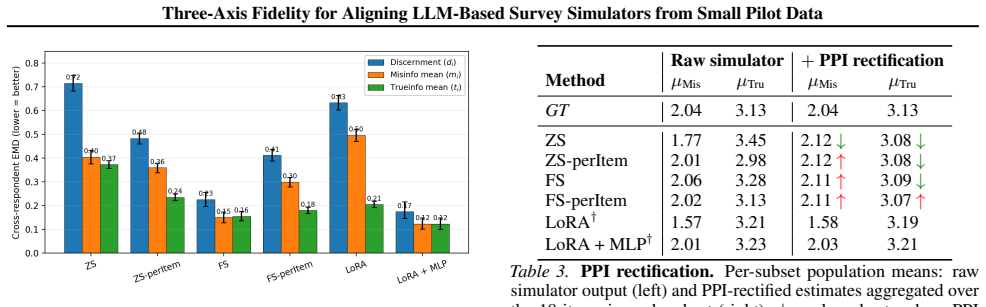
Three-axis fidelity decomposition (structural fidelity for relationships, marginal fidelity for distributions, individual fidelity for consistency) used to measure how well LLM outputs match population statistics from pilot data.
If this is right
- Fine-tuning offers a more balanced approach than prompting or rectification for achieving multiple forms of fidelity at once.
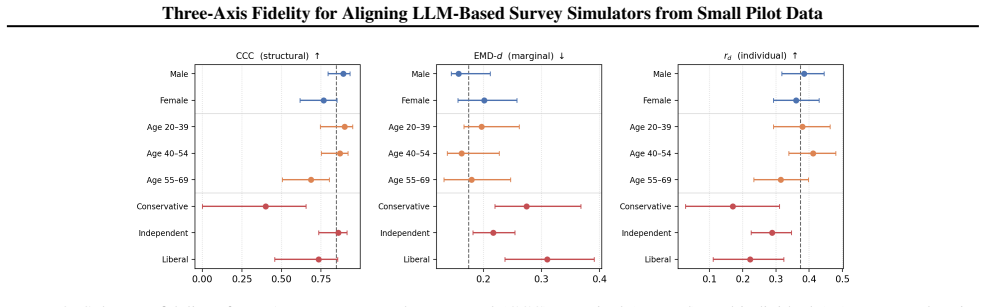
- The level of fidelity obtained can vary across different subsamples drawn from the same pilot.
- Such variation across subsamples may threaten pluralistic alignment in the simulated responses.
- The three-axis evaluation can be applied to compare any alignment method for LLM survey simulators.
Where Pith is reading between the lines
- High variation across subsamples would imply that pilots must be stratified to avoid under-representing certain groups in the simulator.
- The same three-axis test could be applied to non-survey simulation tasks such as generating synthetic user behavior logs.
- If subsample variation persists, it would limit how far small pilots can be trusted to stand in for full population diversity.
Load-bearing premise
The three fidelity axes are sufficient to recover the statistical characteristics of a broader population from a small pilot sample of human responses.
What would settle it
If fine-tuning on a pilot subsample produces outputs whose marginal distributions or predictor-outcome relationships do not match those measured in a large held-out human survey sample, the central claim is falsified.
Figures
read the original abstract
Large language models (LLMs) are increasingly used to simulate social survey responses, yet their outputs exhibit systematic biases: marginal distributions are skewed, response variance is poorly calibrated, and predictor-outcome relationships are attenuated. We ask a simple question: given a small pilot sample of human responses, can an LLM recover the statistical characteristics of a broader population? We decompose recovery along three axes: structural fidelity, marginal fidelity, and individual fidelity. Using a COVID-19 misinformation survey as a case study, we benchmark three families of approaches: prompting, rectification, and fine-tuning. The findings suggest that fine-tuning on small pilot samples offers a balanced approach for achieving multiple forms of fidelity, but the levels of such fidelity can vary across subsamples, potentially threatening pluralistic alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a three-axis framework (structural, marginal, and individual fidelity) to evaluate how well LLM-based simulators recover population-level survey statistics from small human pilot samples. Using a COVID-19 misinformation survey as a case study, it benchmarks prompting, rectification, and fine-tuning methods, finding that fine-tuning offers the most balanced performance across axes while noting that fidelity levels vary across subsamples, which may threaten pluralistic alignment.
Significance. If the empirical results hold under external validation, the work supplies a practical, multi-dimensional evaluation protocol for LLM survey simulators that directly targets documented biases in marginals, variance calibration, and predictor-outcome relationships. The focus on small pilots is relevant for deployment settings where large human samples are unavailable. The explicit discussion of subsample variation adds a cautionary note about alignment stability that is rarely quantified in this literature.
major comments (2)
- [Abstract / Case-study results] The central claim—that matching the three fidelity axes on a pilot sample implies recovery of the target population’s response distributions—rests on an untested sufficiency assumption. No held-out population benchmark or sensitivity analysis is reported that would show transfer beyond the pilot; the abstract presents this as resolved by the case study, yet the skeptic correctly notes the absence of external validation against sampling error or pilot size.
- [Findings on subsample variation] The reported variation in fidelity across subsamples is described qualitatively but not quantified relative to sampling variability or pilot size. Without statistical tests or confidence intervals on the subsample differences, it is unclear whether the observed heterogeneity exceeds what would be expected from finite-sample noise alone.
minor comments (2)
- [Abstract] The abstract states that fine-tuning is “balanced” but does not define the aggregation rule or weighting across the three axes; a short methods paragraph clarifying the composite metric would aid reproducibility.
- [Case study description] No sample sizes, number of pilot respondents, or exact fine-tuning hyperparameters appear in the provided abstract; these details are required for readers to assess whether the pilot is plausibly representative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing where the manuscript requires clarification or additional analysis, and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract / Case-study results] The central claim—that matching the three fidelity axes on a pilot sample implies recovery of the target population’s response distributions—rests on an untested sufficiency assumption. No held-out population benchmark or sensitivity analysis is reported that would show transfer beyond the pilot; the abstract presents this as resolved by the case study, yet the skeptic correctly notes the absence of external validation against sampling error or pilot size.
Authors: We agree that the manuscript does not include a held-out population benchmark or sensitivity analysis demonstrating transfer beyond the pilot sample, and that the abstract could be read as overstating the resolution of the sufficiency assumption. The case study is confined to internal validation within the COVID-19 misinformation survey data. We will revise the abstract to state explicitly that results are demonstrated via this case study without external validation, and add a dedicated limitations paragraph discussing the untested sufficiency assumption, the absence of held-out benchmarks, and the implications for generalizability to other populations or larger pilots. revision: yes
-
Referee: [Findings on subsample variation] The reported variation in fidelity across subsamples is described qualitatively but not quantified relative to sampling variability or pilot size. Without statistical tests or confidence intervals on the subsample differences, it is unclear whether the observed heterogeneity exceeds what would be expected from finite-sample noise alone.
Authors: We agree that the subsample variation is presented qualitatively without formal quantification against sampling variability. We will add bootstrap-based confidence intervals and a permutation test (or similar) to the results section to assess whether the observed fidelity differences across subsamples exceed what is expected from finite-sample noise alone, reporting p-values or interval estimates relative to pilot size. revision: yes
Circularity Check
No significant circularity; empirical case study with externally falsifiable benchmarks
full rationale
The paper defines three fidelity axes (structural, marginal, individual) and reports benchmarking results from a single COVID-19 survey case study comparing prompting, rectification, and fine-tuning. No equations, derivations, or self-citations appear in the abstract or described structure. Claims rest on observed performance differences across subsamples rather than any reduction of outputs to fitted inputs by construction. The central assumption that the axes suffice for population recovery is presented as an empirical question answered via the case study, not as a self-referential definition or imported uniqueness theorem. Results are externally falsifiable by replication on held-out surveys.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cao, Y ., Liu, H., Arora, A., Augenstein, I., R¨ottger, P., and Hershcovich, D
Forthcoming; preprint hal-04849013. Cao, Y ., Liu, H., Arora, A., Augenstein, I., R¨ottger, P., and Hershcovich, D. Specializing large language models to simulate survey response distributions for global popula- tions. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 3141–3154,
2025
-
[2]
Mitigating social de- sirability bias in random silicon sampling.arXiv preprint arXiv:2512.22725,
Chapala, S., Mironov, M., and Deng, S. Mitigating social de- sirability bias in random silicon sampling.arXiv preprint arXiv:2512.22725,
-
[3]
Overstating Attitudes, Ignoring Networks: LLM Biases in Simulating Misinformation Susceptibility
Choi, E. C., Young, L., and Ferrara, E. Overstating attitudes, ignoring networks: LLM biases in simulating misinfor- mation susceptibility.arXiv preprint arXiv:2602.04674,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The threat of analytic flexibility in using large language models to simulate human data
Cummins, J. The threat of analytic flexibility in using large language models to simulate human data: A call to attention.arXiv preprint arXiv:2509.13397,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Distribution Shift Alignment Helps LLMs Simulate Survey Response Distributions
Huang, J., Li, M., and Shao, S. Distribution shift alignment helps LLMs simulate survey response distributions.arXiv preprint arXiv:2510.21977,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Kim, S., Jeong, J., Han, J. S., and Shin, D. LLM-mirror: A generated-persona approach for survey pre-testing.arXiv preprint arXiv:2412.03162,
-
[7]
S., and Bernstein, M
Kolluri, A., Wu, S., Park, J. S., and Bernstein, M. S. Finetun- ing LLMs for human behavior prediction in social science experiments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 30084–30099,
2025
-
[8]
Krsteski, S., Russo, G., Chang, S., West, R., and Gligori´c, K. Valid survey simulations with limited human data: The roles of prompting, fine-tuning, and rectification.arXiv preprint arXiv:2510.11408,
-
[9]
F., Aslak, U., Fiaschi, L., Rismal, N., Fletcher, K., Luhmann, C
Maier, B. F., Aslak, U., Fiaschi, L., Rismal, N., Fletcher, K., Luhmann, C. C., Dow, R., Pappas, K., and Wiecki, T. V . LLMs reproduce human purchase intent via semantic similarity elicitation of Likert ratings.arXiv preprint arXiv:2510.08338,
-
[10]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
7 Three-Axis Fidelity for Aligning LLM-Based Survey Simulators from Small Pilot Data Park, J. S., Zou, C. Q., Shaw, A., Hill, B. M., Cai, C., Morris, M. R., Willer, R., Liang, P., and Bernstein, M. S. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Restoring Heterogeneity in LLM-based Social Simulation: An Audience Segmentation Approach
Qin, X., Li, Z., and Cheng, X. Restoring heterogeneity in LLM-based social simulation: An audience segmentation approach.arXiv preprint arXiv:2604.06663,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rupprecht, J., Ahnert, G., and Strohmaier, M. Prompt pertur- bations reveal human-like biases in large language model survey responses.arXiv preprint arXiv:2507.07188,
-
[13]
Sun, S., Lee, E., Nan, D., Zhao, X., Lee, W., Jansen, B. J., and Kim, J. H. Random silicon sampling: Simulating human sub-population opinion using a large language model based on group-level demographic information. arXiv preprint arXiv:2402.18144,
-
[14]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al
Also arXiv:2402.01908. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[15]
Large language model psychometrics: A systematic review of evaluation, validation, and enhancement,
Ye, H., Jin, J., Xie, Y ., Zhang, X., and Song, G. Large language model psychometrics: A systematic review of evaluation, validation, and enhancement.arXiv preprint arXiv:2505.08245,
-
[16]
Zhou, M., Yu, L., Geng, X., and Luo, L. ChatGPT vs social surveys: Probing objective and subjective silicon population.arXiv preprint arXiv:2409.02601,
-
[17]
exactly 36 labels
8 Three-Axis Fidelity for Aligning LLM-Based Survey Simulators from Small Pilot Data A. Example Prompt The full participant block reproduces the seven psychometric / exposure construct items verbatim with item-text=label pairs. The 36 claims are presented it a per-respondent shuffled order. The per-item variant queries the same model 36 times per responde...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.