Process Advantage Signal Shaping: A Paradigm-Agnostic Middleware for Process-Supervised RL in LLM Reasoners
Pith reviewed 2026-06-30 07:30 UTC · model grok-4.3
The pith
PASS middleware fixes channel contamination, resolution mismatch and cumulative trap when layering process signals on GRPO, delivering consistent pass@1 gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
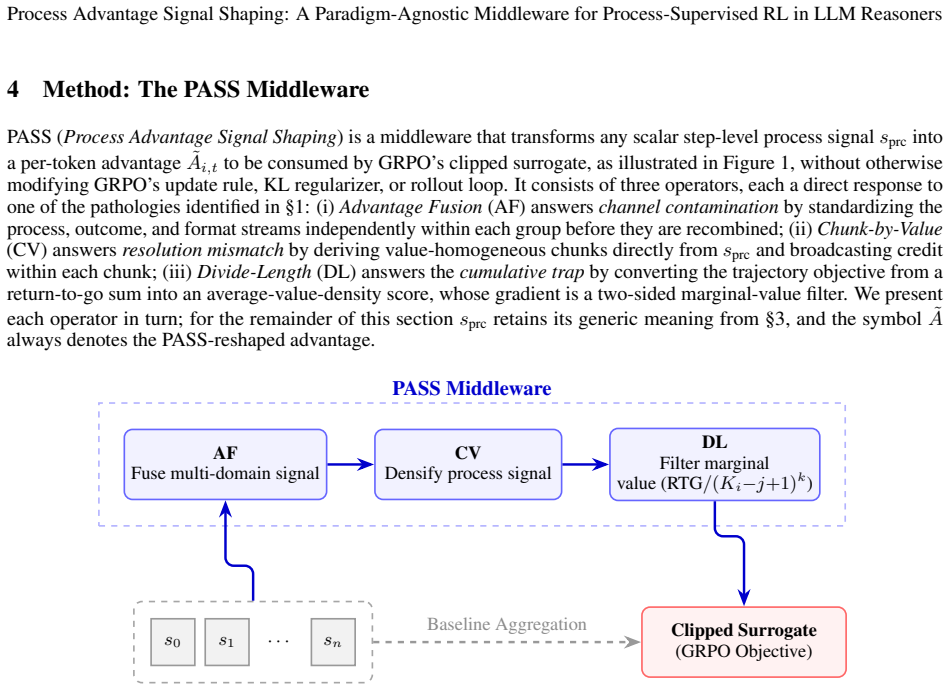
Process Advantage Signal Shaping (PASS) addresses three pathologies in process-supervised GRPO by standardizing process, outcome and format streams independently within each group (Advantage Fusion), deriving value-homogeneous chunks from the signal and broadcasting credit inside each chunk (Chunk-by-Value), and replacing the cumulative return-to-go with an average-value-density score (Divide-Length). Across mathematical reasoning and multi-hop question answering, using both learned PRM signals and on-policy KL signals, and under two group-standardization operators, PASS produces consistent pass@1 gains relative to the corresponding GRPO baseline.
What carries the argument
PASS middleware with Advantage Fusion for independent per-stream standardization, Chunk-by-Value for signal-derived homogeneous chunks, and Divide-Length for average-value-density conversion.
If this is right
- Process supervision can be added to GRPO without the three listed pathologies.
- The same shaping steps work for both learned PRM signals and on-policy distillation KL signals.
- Gains appear under different choices of group-standardization operator.
- The method applies across mathematical reasoning and multi-hop question-answering domains.
- Credit assignment improves without changing the base clipped-surrogate objective.
Where Pith is reading between the lines
- The same three operations could be ported to other group-relative or advantage-based RL recipes beyond GRPO.
- The chunking and density ideas might extend to outcome-only or sparse-reward settings where length bias is also observed.
- If the fixes prove robust at larger model sizes, they could become a default preprocessing layer for any step-level signal.
- The resolution-mismatch diagnosis suggests similar granularity problems may exist in other dense-reward RL pipelines for sequential decision tasks.
Load-bearing premise
The three pathologies dominate the failure modes when process signals are added to GRPO, and the three fixes correct them without introducing new offsetting problems at other scales or regimes.
What would settle it
A controlled experiment on a new task or model scale in which PASS produces no pass@1 improvement or a clear degradation relative to the GRPO baseline would falsify the claim of consistent gains.
Figures
read the original abstract
Group Relative Policy Optimization (GRPO) is a default recipe for process-supervised reinforcement learning of LLM reasoners, and dense process supervision -- via learned process reward models (PRMs) or on-policy-distillation KL signals -- is a common way to densify its otherwise weak outcome reward. Layering such a step-level signal on top of GRPO's group-standardized advantage, however, exposes three structural pathologies: \emph{channel contamination} between the pooled process, outcome, and format streams at group standardization; \emph{resolution mismatch} between the granularity of the process signal and the granularity of the logical decisions being credited; and a \emph{cumulative trap} by which GRPO's return-to-go sum surfaces either length inflation or truncated exploration depending on the sign regime of the signal. We propose \textbf{PASS} (\emph{Process Advantage Signal Shaping}), a compact middleware that sits between any scalar step-level process signal and GRPO's clipped surrogate and addresses the three pathologies in turn: \emph{Advantage Fusion} standardizes the three streams independently within each group, \emph{Chunk-by-Value} derives value-homogeneous chunks from the signal itself and broadcasts credit within each chunk, and \emph{Divide-Length} converts the cumulative objective into an average-value-density score. We validate PASS across two domains and two process-signal paradigms -- a learned PRM on mathematical reasoning and an on-policy-distillation KL signal (with a generalized variant) on multi-hop question answering -- and under two group-standardization operators. In every regime PASS delivers a consistent pass@1 gain over the corresponding GRPO baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
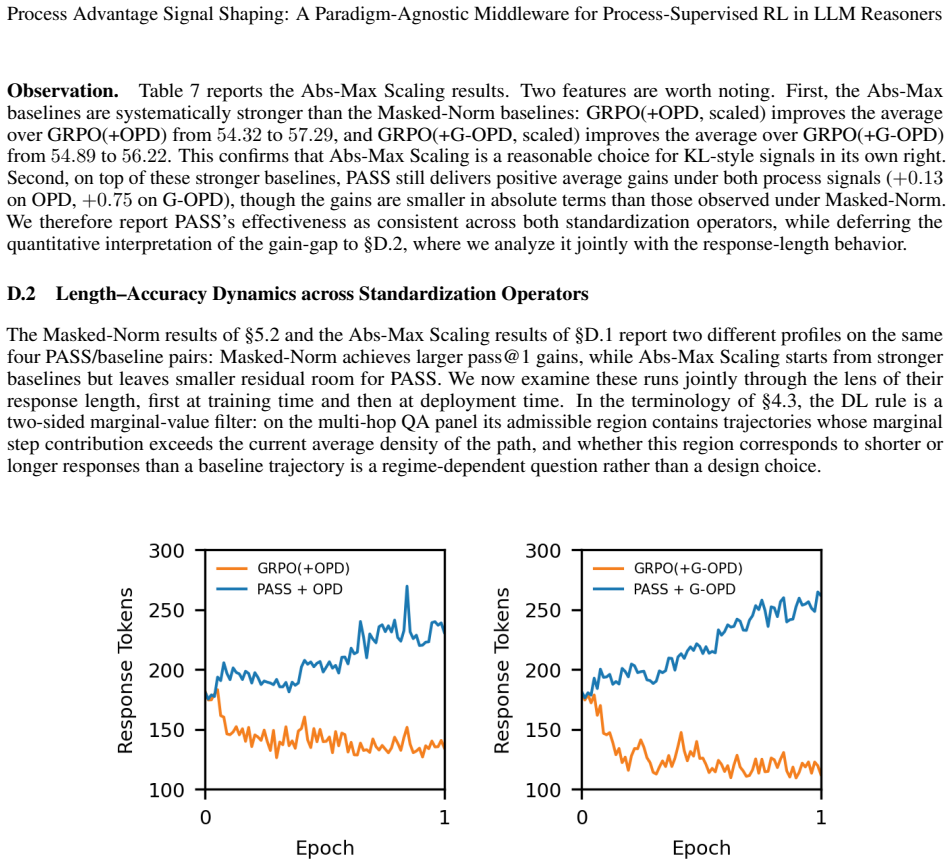
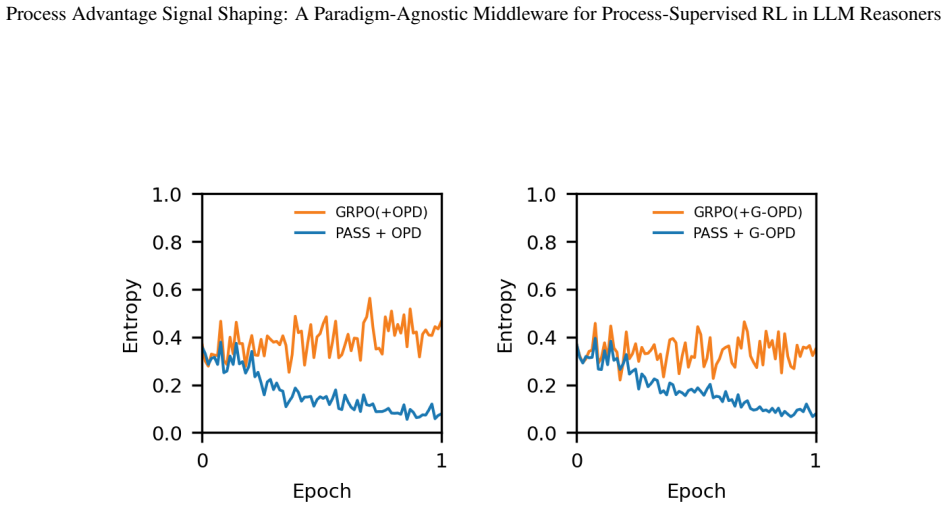
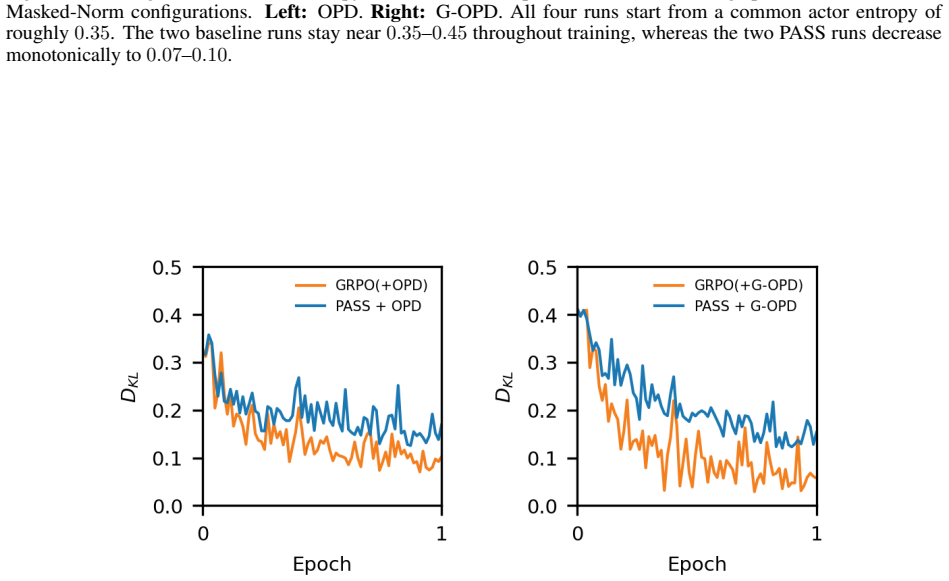
Summary. The paper proposes PASS (Process Advantage Signal Shaping), a paradigm-agnostic middleware for process-supervised RL with GRPO in LLM reasoners. It identifies three pathologies when layering step-level process signals (learned PRMs or on-policy KL distillation) on GRPO's group-standardized advantage—channel contamination, resolution mismatch, and cumulative trap—and addresses them via Advantage Fusion (independent per-stream standardization), Chunk-by-Value (value-homogeneous chunks for credit assignment), and Divide-Length (average-value-density objective). The central claim is that PASS yields consistent pass@1 gains over GRPO baselines across two domains (mathematical reasoning, multi-hop QA), two signal paradigms, and two standardization operators.
Significance. If the results hold, PASS supplies a compact, reusable layer that improves dense process supervision without requiring per-paradigm redesigns, which could streamline RL for LLM reasoning. The work is strengthened by its procedural (non-fitted, non-circular) construction from existing GRPO components and by explicit testing across multiple signal types and operators rather than a single setting.
major comments (2)
- [Abstract and empirical validation] Abstract (final sentence) and empirical validation: the claim that PASS 'delivers a consistent pass@1 gain ... in every regime' is load-bearing for the contribution yet rests on results from only two domains and two signal types; this narrow base leaves open the possibility that Chunk-by-Value or Divide-Length introduce offsetting side-effects (e.g., credit misalignment on noisy PRMs or length bias in longer horizons) that are not ruled out by the reported experiments.
- [Abstract and experiments section] Abstract and § on experiments: no quantitative deltas, confidence intervals, ablation tables, or details on hyper-parameter selection and data exclusion are supplied to support the 'consistent gains' assertion, making it impossible to assess effect size or robustness of the three proposed fixes.
minor comments (2)
- [Method description] Notation for the three streams (process, outcome, format) is introduced without an explicit equation or diagram showing how they are pooled before versus after Advantage Fusion.
- [Introduction] The term 'middleware' is used without a short comparison to existing RL wrappers or adapters in the related-work section.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recognition of PASS as a compact middleware. We respond to each major comment below, indicating planned revisions where the manuscript can be strengthened without misrepresenting the reported results.
read point-by-point responses
-
Referee: [Abstract and empirical validation] Abstract (final sentence) and empirical validation: the claim that PASS 'delivers a consistent pass@1 gain ... in every regime' is load-bearing for the contribution yet rests on results from only two domains and two signal types; this narrow base leaves open the possibility that Chunk-by-Value or Divide-Length introduce offsetting side-effects (e.g., credit misalignment on noisy PRMs or length bias in longer horizons) that are not ruled out by the reported experiments.
Authors: We agree that the empirical base is limited to two domains and two signal paradigms (learned PRM and on-policy KL distillation), even though consistency holds across both standardization operators. This scope does not fully exclude potential side-effects such as credit misalignment on noisier PRMs or length bias under longer horizons. In revision we will qualify the abstract claim to 'consistent gains in the evaluated regimes' and add an explicit limitations paragraph discussing these possibilities. revision: partial
-
Referee: [Abstract and experiments section] Abstract and § on experiments: no quantitative deltas, confidence intervals, ablation tables, or details on hyper-parameter selection and data exclusion are supplied to support the 'consistent gains' assertion, making it impossible to assess effect size or robustness of the three proposed fixes.
Authors: We accept that the abstract and experiments section lack the requested quantitative detail. The revised manuscript will incorporate specific pass@1 deltas (with confidence intervals where computed), ablation tables isolating Advantage Fusion, Chunk-by-Value, and Divide-Length, plus expanded descriptions of hyper-parameter selection and data exclusion criteria. revision: yes
- Expanding the experimental scope to additional domains or signal paradigms to more comprehensively rule out side-effects of Chunk-by-Value and Divide-Length.
Circularity Check
No circularity: procedural definitions and empirical validation are self-contained
full rationale
The paper defines PASS via three explicit algorithmic components (Advantage Fusion, Chunk-by-Value, Divide-Length) that operate on the input process signal and GRPO's group standardization; these are presented as direct procedural fixes for the three named pathologies rather than as fitted parameters or quantities derived from the target metric. No equations reduce a prediction to a self-referential fit, no self-citations are invoked as load-bearing uniqueness theorems, and the central claim rests on reported empirical gains across the tested regimes rather than on any renaming or ansatz smuggling. The derivation chain is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Group Relative Policy Optimization (GRPO) is a default recipe for process-supervised reinforcement learning of LLM reasoners
invented entities (1)
-
PASS middleware
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv, arXiv:2402.03300, April
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
doi: 10.48550/arXiv.2402.03300. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300
-
[3]
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
URL http://arxiv. org/abs/2509.03403. Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, Yejin Choi, Jan Kautz, and Pavlo Molchanov. GDPO: Group reward- Decoupled Normalization Policy Optimization for Multi-reward RL Optimization, January
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
URLhttps://arxiv.org/abs/2604.09459v2. Michael Sullivan. GRPO is Secretly a Process Reward Model, October
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Zichao Li, Jie Lou, Fangchen Dong, Zhiyuan Fan, Mengjie Ren, Hongyu Lin, Xianpei Han, Debing Zhang, Le Sun, Yaojie Lu, and Xing Yu. Tackling Length Inflation Without Trade-offs: Group Relative Reward Rescaling for Reinforcement Learning, 2026a. URLhttps://arxiv.org/abs/2603.10535v1. Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang...
-
[6]
URLhttp://arxiv.org/abs/2603.19835. Mykola Khandoga, Rui Yuan, and Vinay Kumar Sankarapu. Beyond Uniform Credit: Causal Credit Assignment for Policy Optimization,
-
[7]
Junxi Yin, Haisen Luo, Zhenyu Li, Yihua Liu, Dan Liu, Zequn Li, and Xiaohang Xu
URLhttps://arxiv.org/abs/2602.09331v1. Junxi Yin, Haisen Luo, Zhenyu Li, Yihua Liu, Dan Liu, Zequn Li, and Xiaohang Xu. Pinpointing crucial steps: Attribution-based Credit Assignment for Verifiable Reinforcement Learning,
-
[8]
Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D
URL https://arxiv.org/ abs/2510.08899v1. Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D. Lee, and Sanjeev Arora. What Makes a Reward Model a Good Teacher? An Optimization Perspective.arXiv, arXiv:2503.15477, March
-
[9]
doi: 10.48550/arXiv. 2503.15477. Gang Li, Yan Chen, Ming Lin, and Tianbao Yang. DRPO: Efficient Reasoning via Decoupled Reward Policy Optimization,
work page internal anchor Pith review doi:10.48550/arxiv
-
[10]
Li, Y ., Yuan, P., Feng, S., Pan, B., Wang, X., Sun, B., Wang, H., and Li, K
URLhttps://arxiv.org/abs/2510.04474v2. Qiyuan Liu, Hao Xu, Xuhong Chen, Wei Chen, Yee Whye Teh, and Ning Miao. Enhancing Large Language Model Reasoning with Reward Models: An Analytical Survey,
-
[11]
URLhttps://arxiv.org/abs/2510.01925v2. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe, 2026b. URLhttp://arxiv.org/abs/2604.13016. Wenkai Yang, Weijie Liu, Ruobing X...
-
[12]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
URL http://arxiv.org/abs/2602.12125. Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A Long Way to Go: Investigating Length Correlations in RLHF,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5- math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processin...
2018
-
[15]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
doi: 10.18653/v1/2020.coling-main.580. URL https://aclanthology.org/ 2020.coling-main.580/. Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop Questions via Single-hop Question Composition.Transactions of the Association for Computational Linguistics, 10:539–554,
-
[16]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
doi: 10.1162/tacl_a_00475. URLhttps://aclanthology.org/2022.tacl-1.31/. Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei ...
-
[17]
URLhttp://arxiv.org/abs/2412.15115. A Proof of the Length Collapse Theorem We restate Assumption 1 and Theorem 1 and give the detailed argument deferred from §4.3. Proof of Theorem
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Setting k<1.0 protects necessary reasoning verbosity and raises the exploratory ceiling; k=0.7 achieves the best average pass@1 and is used as the default throughout this paper
Metrics are pass@1 / pass@8 (%). Setting k<1.0 protects necessary reasoning verbosity and raises the exploratory ceiling; k=0.7 achieves the best average pass@1 and is used as the default throughout this paper. Decay Factor AIME24 AIME25 AMC23 GSM8K MATH Minerva Olympiad Average k= 1.0(Strict DL) 14.8/39.19.8/27.4 53.8/83.777.5/95.455.1/71.3 27.3/47.2 11....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.