RoamFlow: Reinforcement-Aligned One-Step Action MeanFlow Policy for Image-Goal Navigation
Pith reviewed 2026-06-30 05:44 UTC · model grok-4.3
The pith
RoamFlow predicts average velocity fields via MeanFlow to enable one-step image-goal navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
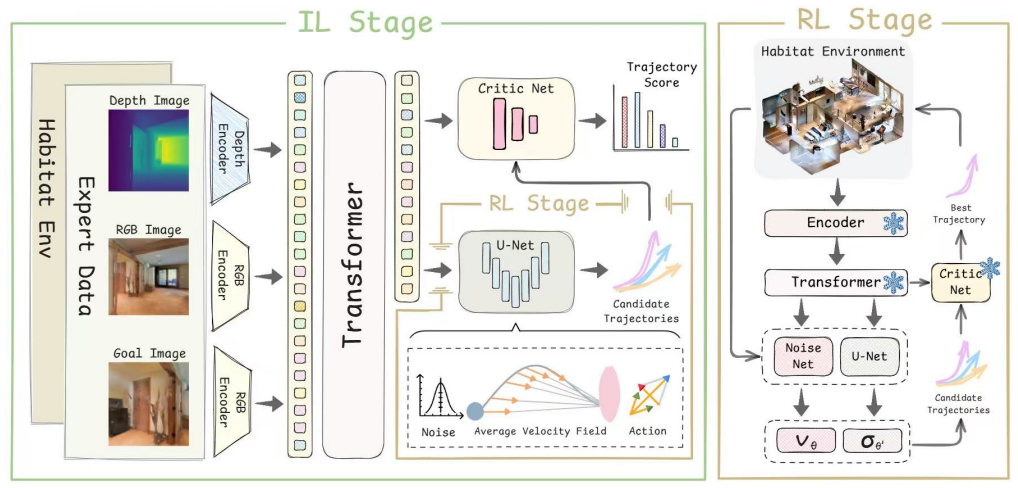
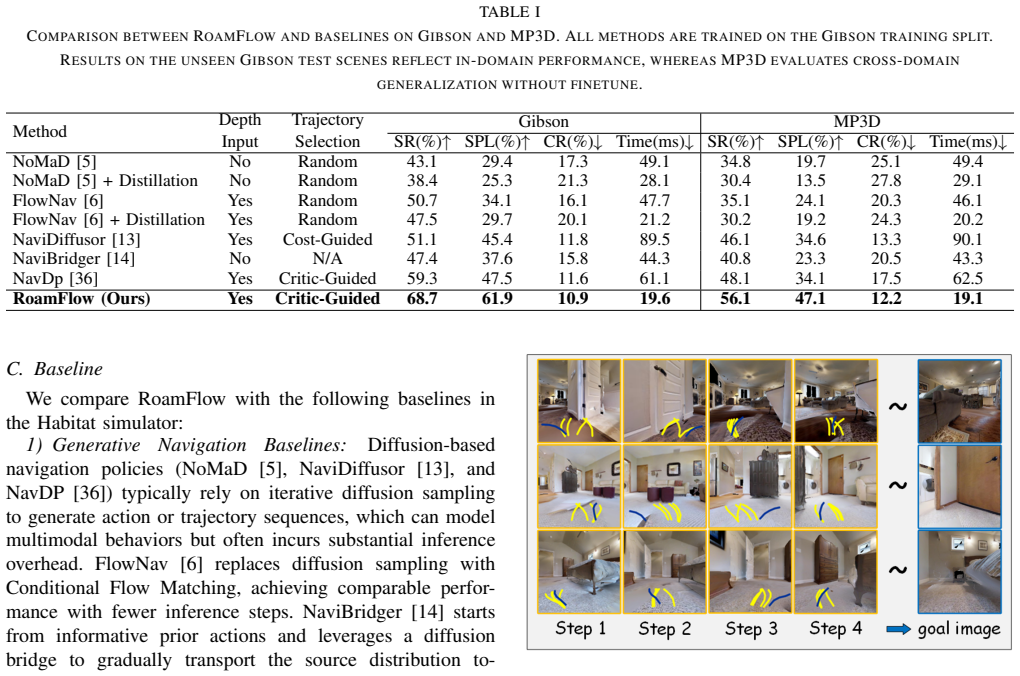
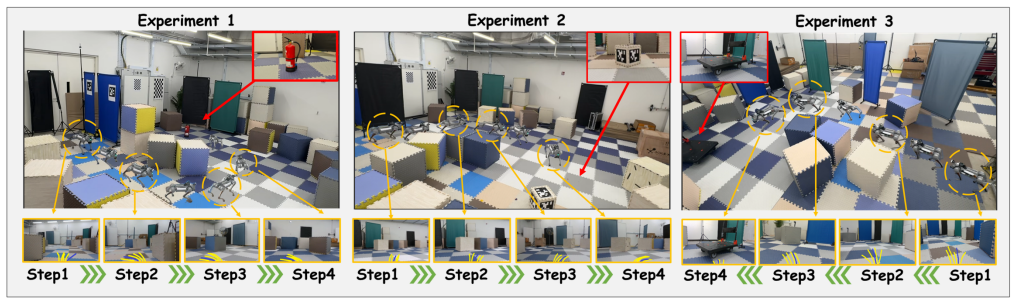
RoamFlow is a generative navigation framework that leverages MeanFlow to predict the average velocity field for trajectory synthesis, enabling efficient few-step generation and reducing inference latency. The method adopts a two-stage training strategy that combines expert imitation for stable initialization with reinforcement learning for task-specific policy refinement. Experiments in Habitat simulation and on real-world robotic platforms show that this produces efficient inference while maintaining strong navigation performance under real-time constraints.
What carries the argument
MeanFlow policy that predicts the average velocity field from image observations to synthesize navigation trajectories in one or few steps.
If this is right
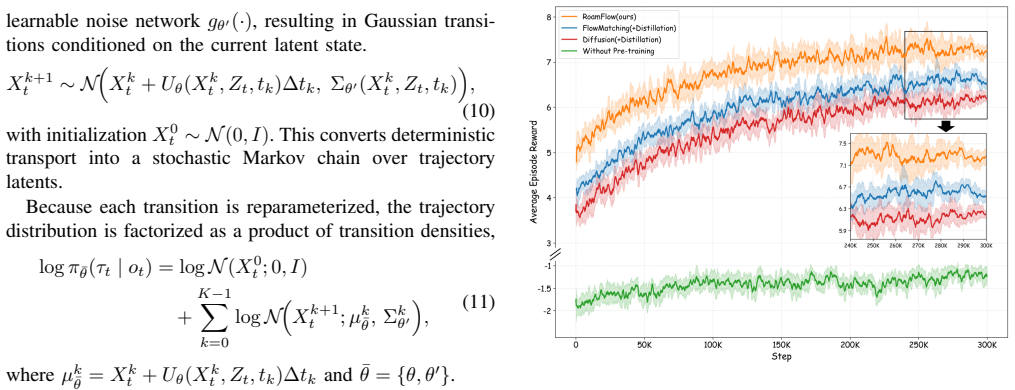
- Enables efficient few-step generation that reduces inference latency for real-time use.
- Maintains strong navigation performance under real-time constraints in both simulation and physical robots.
- Improves handling of long-horizon dependencies compared with direct observation-to-action mapping.
- The two-stage imitation-plus-reinforcement training produces stable yet task-aligned policies.
Where Pith is reading between the lines
- The velocity-field formulation could transfer to other visual goal-reaching tasks that lack explicit coordinate goals.
- One-step generation may lower compute demands on resource-limited robot hardware.
- Further combinations of MeanFlow with additional generative components might increase robustness in changing environments.
Load-bearing premise
That predicting an average velocity field via MeanFlow sufficiently captures long-horizon trajectory information from image observations to support effective goal reaching without explicit long-term planning.
What would settle it
A test in which RoamFlow success rates fall sharply on tasks requiring more than a few steps while a planning-based baseline maintains performance, or where measured inference latency shows no reduction over direct-action baselines.
Figures

read the original abstract
Image-goal navigation is a key challenge in embodied robotics, where an agent must reach a target specified solely by a goal image. While existing reinforcement learning approaches map perceptual observations directly to actions, they struggle to model long-horizon dependencies, often leading to suboptimal trajectories. To address this limitation, we propose RoamFlow, a generative navigation framework that leverages MeanFlow to predict the average velocity field for trajectory synthesis, enabling efficient few-step generation and reducing inference latency. We further adopt a two-stage training strategy that combines expert imitation for stable initialization with reinforcement learning for task-specific policy refinement. Extensive experiments in both Habitat simulation and real-world robotic platforms demonstrate that RoamFlow achieves efficient inference while maintaining strong navigation performance under real-time constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RoamFlow, a generative navigation framework for image-goal navigation. It uses MeanFlow to predict an average velocity field from image observations for trajectory synthesis, enabling efficient few-step generation and reduced inference latency. A two-stage training pipeline combines expert imitation for initialization with reinforcement learning for task-specific refinement. Experiments in Habitat simulation and real-world robotic platforms are claimed to show efficient inference while maintaining strong navigation performance under real-time constraints.
Significance. If substantiated with quantitative evidence, the approach could be significant for embodied robotics by combining generative velocity-field prediction with RL alignment to better handle long-horizon dependencies in image-goal tasks, offering a path to real-time policies that avoid explicit planning.
major comments (1)
- [Abstract] Abstract: The central claims that RoamFlow 'achieves efficient inference while maintaining strong navigation performance' and addresses long-horizon dependencies are unsupported by any quantitative metrics, baselines, success rates, latency measurements, or ablation results, rendering the primary contribution unverifiable from the supplied text.
minor comments (1)
- [Abstract] Abstract: 'MeanFlow' is used without definition, equation, or citation, leaving the core technical mechanism unclear.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify the presentation of our results. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that RoamFlow 'achieves efficient inference while maintaining strong navigation performance' and addresses long-horizon dependencies are unsupported by any quantitative metrics, baselines, success rates, latency measurements, or ablation results, rendering the primary contribution unverifiable from the supplied text.
Authors: We agree that the abstract, as written, does not contain the specific quantitative metrics needed to make the claims immediately verifiable on its own. The body of the manuscript reports Habitat and real-world results with success rates, SPL, latency, and baseline comparisons, but these are not summarized numerically in the abstract. We will revise the abstract to include key quantitative highlights (e.g., success-rate gains and measured inference latency) drawn from the experimental sections so that the primary claims are supported within the abstract itself. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description outline a two-stage training approach (expert imitation followed by RL refinement) that uses MeanFlow to predict an average velocity field from image observations for navigation. No equations, derivations, or self-citations are provided that would allow any prediction or result to reduce by construction to its inputs. The performance claims are presented as outcomes of experiments in Habitat and real-world platforms, which constitute external validation rather than an internal definitional loop. The derivation chain, as described, remains self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Target-driven visual navigation in indoor scenes using deep reinforcement learning,
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 3357–3364
2017
-
[2]
Sign: Safety- aware image-goal navigation for autonomous drones via reinforcement learning,
Z. Yan, R. Huang, L. He, S. Guo, and L. Zhao, “Sign: Safety- aware image-goal navigation for autonomous drones via reinforcement learning,”IEEE Robotics and Automation Letters, vol. 11, no. 2, pp. 1962–1969, 2025
1962
-
[3]
Memory-augmented reinforcement learning for image-goal navigation,
L. Mezghan, S. Sukhbaatar, T. Lavril, O. Maksymets, D. Batra, P. Bojanowski, and K. Alahari, “Memory-augmented reinforcement learning for image-goal navigation,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 3316–3323
2022
-
[4]
An improved reinforce- ment learning-based uav obstacle avoidance framework using ppo- cma,
Y . Chen, J. Gao, Y . Deng, and M. Feroskhan, “An improved reinforce- ment learning-based uav obstacle avoidance framework using ppo- cma,” in2025 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2025, pp. 5845–5850
2025
-
[5]
Nomad: Goal masked diffusion policies for navigation and exploration,
A. Sridhar, D. Shah, C. Glossop, and S. Levine, “Nomad: Goal masked diffusion policies for navigation and exploration,” pp. 63–70, 2024
2024
-
[6]
Flownav: Combining flow matching and depth priors for efficient navigation,
S. Gode, A. Nayak, D. N. Oliveira, M. Krawez, C. Schmid, and W. Burgard, “Flownav: Combining flow matching and depth priors for efficient navigation,”arXiv preprint arXiv:2411.09524, 2024
-
[7]
Z. Wang, Z. Li, A. Mandlekar, Z. Xu, J. Fan, Y . Narang, L. Fan, Y . Zhu, Y . Balaji, M. Zhouet al., “One-step diffusion policy: Fast visuomotor policies via diffusion distillation,”arXiv preprint arXiv:2410.21257, 2024
- [8]
-
[9]
Variational distillation of diffusion policies into mixture of experts,
H. Zhou, D. Blessing, G. Li, O. Celik, X. Jia, G. Neumann, and R. Lioutikov, “Variational distillation of diffusion policies into mixture of experts,”Advances in Neural Information Processing Systems, vol. 37, pp. 12 739–12 766, 2024
2024
-
[10]
Mean Flows for One-step Generative Modeling
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,”arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Habitat: A Platform for Embodied AI Research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A Platform for Embodied AI Research,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[12]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[13]
Navidiffusor: Cost-guided diffusion model for visual navigation,
Y . Zeng, H. Ren, S. Wang, J. Huang, and H. Cheng, “Navidiffusor: Cost-guided diffusion model for visual navigation,”arXiv preprint arXiv:2504.10003, 2025
-
[14]
Prior does matter: Visual navigation via denoising diffusion bridge models,
H. Ren, Y . Zeng, Z. Bi, Z. Wan, J. Huang, and H. Cheng, “Prior does matter: Visual navigation via denoising diffusion bridge models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 100–12 110
2025
-
[15]
Denoising diffusion bridge models,
L. Zhou, A. Lou, S. Khanna, and S. Ermon, “Denoising diffusion bridge models,”arXiv preprint arXiv:2309.16948, 2023
-
[16]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Knowledge diffusion for distillation,
T. Huang, Y . Zhang, M. Zheng, S. You, F. Wang, C. Qian, and C. Xu, “Knowledge diffusion for distillation,”Advances in Neural Information Processing Systems, vol. 36, pp. 65 299–65 316, 2023
2023
-
[18]
One-step diffusion distillation through score implicit matching,
W. Luo, Z. Huang, Z. Geng, J. Z. Kolter, and G.-j. Qi, “One-step diffusion distillation through score implicit matching,”Advances in Neural Information Processing Systems, vol. 37, pp. 115 377–115 408, 2024
2024
-
[19]
Progressive Distillation for Fast Sampling of Diffusion Models
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,”arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” 2023
2023
-
[21]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[23]
Diffusion Policy Policy Optimization
A. Z. Ren, J. Lidard, L. L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz, “Diffusion policy policy optimization,”arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Fdpp: Fine-tune diffusion policy with human preference,
Y . Chen, D. K. Jha, M. Tomizuka, and D. Romeres, “Fdpp: Fine-tune diffusion policy with human preference,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 12 010–12 016
2025
-
[25]
Fine-tuning diffusion policies with backpropagation through diffusion timesteps,
N. Yang, J. Gao, F. Gao, Y . Wu, and C. Yu, “Fine-tuning diffusion policies with backpropagation through diffusion timesteps,”arXiv preprint arXiv:2505.10482, 2025
-
[26]
T. Zhang, C. Yu, S. Su, and Y . Wang, “Reinflow: Fine-tuning flow matching policy with online reinforcement learning,”arXiv preprint arXiv:2505.22094, 2025
-
[27]
Rethinking model scaling for convolutional neural networks,
M. Tan, Q. E. Leet al., “Rethinking model scaling for convolutional neural networks,” inProceedings of the International conference on machine learning, Long Beach, CA, USA, vol. 15, 2019
2019
-
[28]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[29]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[30]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Confer- ence on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[31]
Gibson env: Real-world perception for embodied agents,
F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese, “Gibson env: Real-world perception for embodied agents,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018, pp. 9068–9079
2018
-
[32]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Deep visual mpc-policy learning for navigation,
N. Hirose, F. Xia, R. Mart ´ın-Mart´ın, A. Sadeghian, and S. Savarese, “Deep visual mpc-policy learning for navigation,”IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3184–3191, 2019
2019
-
[34]
Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation,
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone, “Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 11 807–11 814, 2022
2022
-
[35]
Depth anything v2,
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”Advances in Neural Information Processing Systems, vol. 37, pp. 21 875–21 911, 2024
2024
-
[36]
Navdp: Learning sim-to-real navigation dif- fusion policy with privileged information guidance,
W. Cai, J. Peng, Y . Yang, Y . Zhang, M. Wei, H. Wang, Y . Chen, T. Wang, and J. Pang, “Navdp: Learning sim-to-real navigation dif- fusion policy with privileged information guidance,”arXiv preprint arXiv:2505.08712, 2025
-
[37]
arXiv preprint arXiv:2509.25127 , year=
M. Zhou, Y . Gu, H. Zheng, L. Song, G. He, Y . Zhang, W. Hu, and Y . Yang, “Score distillation of flow matching models,”arXiv preprint arXiv:2509.25127, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.