TRACE: Temporal Relationship-Aware Conversational Entrainment Detection in Dyadic Speech
Pith reviewed 2026-06-30 06:00 UTC · model grok-4.3
The pith
TRACE detects emotional entrainment in dyadic speech at 97.01 percent accuracy by modeling conversations as ordered acoustic sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
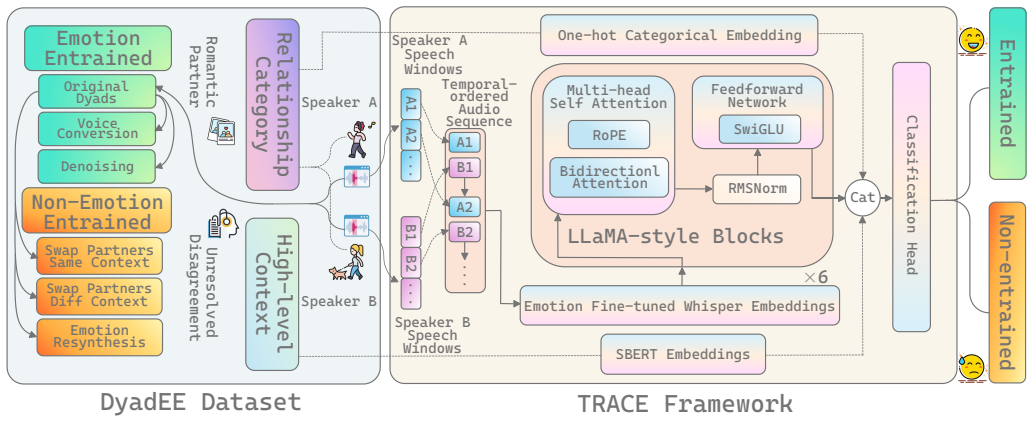
TRACE models each dyadic interaction as an ordered sequence of acoustic embeddings drawn from emotion fine-tuned Whisper representations at the window level, treating the full sample as an interaction trace. This approach captures temporal relationships and context that pooled methods miss, yielding 97.01 percent accuracy on the DyadEE dataset that mixes real entrained conversations with synthetically disrupted ones.
What carries the argument
TRACE, the window-level framework that converts dyadic speech into ordered sequences of acoustic embeddings and processes them as interaction traces to incorporate temporal and relationship context.
If this is right
- Adding explicit conversational context and relationship signals raises detection accuracy above methods that ignore sequence order.
- Window-level ordered embeddings outperform utterance pooling for entrainment tasks.
- The DyadEE construction of real-plus-synthetic pairs supplies a workable training signal for distinguishing entrained from non-entrained states.
- The same trace representation can be applied to other dyadic affective phenomena once labeled data exist.
Where Pith is reading between the lines
- The method could extend to real-time monitoring inside spoken dialogue systems so agents can adjust their own emotional pacing mid-conversation.
- If the trace approach generalizes, it may reduce the need for hand-crafted entrainment features in favor of end-to-end sequence models.
- Future datasets could replace synthetic disruption with naturally occurring low-entrainment pairs collected from the same speakers across different social contexts.
Load-bearing premise
The synthetic interactions made by partner swapping and emotion resynthesis accurately stand in for the absence of emotional entrainment that occurs in real conversations.
What would settle it
A controlled test in which TRACE accuracy drops to baseline levels when evaluated on a separate collection of naturally occurring non-entrained dyadic recordings would show the central claim does not hold.
Figures
read the original abstract
With the proliferation of speech AI agents, understanding emotional entrainment in conversational interaction has become increasingly important. Emotional entrainment is shaped by social relationships and conversational context, influencing affective coordination over time. We introduce DyadEE, a dataset for emotional entrainment detection in dyadic speech interactions, containing both emotionally entrained conversations and synthetic interactions where entrainment is disrupted through partner swapping and emotion resynthesis. We further propose TRACE, a window-level framework that models dyadic interaction as ordered sequences of acoustic embeddings derived from emotion fine-tuned Whisper representations, treating each sample as an interaction trace rather than pooled utterances. Experimental results on DyadEE show that incorporating conversational context and relationship information improves emotional entrainment detection, with TRACE achieving the best accuracy of 97.01%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the DyadEE dataset containing real emotionally entrained dyadic speech interactions alongside synthetic non-entrained samples generated by partner swapping and emotion resynthesis. It proposes TRACE, a window-level detection framework that represents each dyadic sample as an ordered sequence of acoustic embeddings extracted from emotion fine-tuned Whisper representations rather than pooled utterances. Experiments on DyadEE report that TRACE achieves 97.01% accuracy and that adding conversational context and relationship information improves performance over baselines.
Significance. If the synthetic non-entrained class is shown to be free of resynthesis artifacts, the dataset and temporal modeling approach would provide a useful resource for studying relationship-aware entrainment in conversational speech, with direct relevance to speech AI agents.
major comments (1)
- [Abstract] Abstract: The headline accuracy of 97.01% and the claim that context/relationship modeling improves detection both depend on DyadEE labels being valid (real entrained vs. synthetic non-entrained). No quantitative validation—acoustic distance metrics between real and resynthesized segments, human perceptual ratings of naturalness, or ablation using real non-entrained dyads—is described to rule out the possibility that Whisper embeddings exploit consistent resynthesis artifacts (timbre mismatch, timing discontinuities, or emotion-model artifacts) rather than entrainment dynamics.
minor comments (1)
- [Abstract] The abstract refers to 'relationship information' being incorporated but does not specify the input representation or fusion mechanism used in TRACE.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the synthetic non-entrained samples in DyadEE. This is a substantive concern regarding the interpretability of our results, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline accuracy of 97.01% and the claim that context/relationship modeling improves detection both depend on DyadEE labels being valid (real entrained vs. synthetic non-entrained). No quantitative validation—acoustic distance metrics between real and resynthesized segments, human perceptual ratings of naturalness, or ablation using real non-entrained dyads—is described to rule out the possibility that Whisper embeddings exploit consistent resynthesis artifacts (timbre mismatch, timing discontinuities, or emotion-model artifacts) rather than entrainment dynamics.
Authors: We agree that the absence of explicit validation leaves open the possibility that performance reflects resynthesis artifacts rather than entrainment. In the revised manuscript we will add: (1) acoustic distance metrics (e.g., Mel-cepstral distortion and cosine similarity on Whisper embeddings) comparing real and resynthesized segments; (2) a human perceptual rating study on naturalness of a subset of synthetic samples; and (3) discussion of why obtaining matched real non-entrained dyads is difficult, together with any feasible ablation that can be performed. These additions will be reported in a new subsection of the experiments and will qualify the headline claims accordingly. revision: yes
Circularity Check
No circularity: purely empirical evaluation on constructed dataset
full rationale
The paper reports an empirical accuracy (97.01%) on the DyadEE dataset created via partner swapping and emotion resynthesis. No equations, derivations, or first-principles predictions are described in the provided text. The performance figure is presented as an experimental measurement rather than a quantity obtained by fitting parameters to the target metric or by self-referential definition. The central claim (context/relationship modeling improves detection) rests on standard ML evaluation rather than any load-bearing self-citation chain or ansatz that reduces to the input labels by construction. This is the normal case for an applied detection paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rhythm perception, speak- ing rate entrainment, and conversational quality: A mediated model,
C. J. Wynn, T. S. Barrett, and S. A. Borrie, “Rhythm perception, speak- ing rate entrainment, and conversational quality: A mediated model,” Journal of Speech, Language, and Hearing Research, vol. 65, no. 6, pp. 2187–2203, 2022
2022
-
[2]
Measuring prosodic entrainment in conversation: A review and comparison of different methods,
J. Kruyt, D. de Jong, A. D’Ausilio, and ˇS. Be ˇnuˇs, “Measuring prosodic entrainment in conversation: A review and comparison of different methods,”Journal of Speech, Language, and Hearing Research, vol. 66, no. 11, pp. 4280–4314, 2023
2023
-
[3]
Relationship between speech entrainment and emotion,
J. Kejriwal, “Relationship between speech entrainment and emotion,” in2022 10th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW). IEEE, 2022, pp. 1–4
2022
-
[4]
Physiological coregulation during social support discussions
K. S. Zee and N. Bolger, “Physiological coregulation during social support discussions.”Emotion, vol. 23, no. 3, p. 825, 2023
2023
-
[5]
Social aspects of entrainment in spoken interaction,
ˇS. Be ˇnuˇs, “Social aspects of entrainment in spoken interaction,”Cogni- tive Computation, vol. 6, no. 4, pp. 802–813, 2014
2014
-
[6]
URL http://arxiv.org/abs/2504.03888
J. Phang, M. Lampe, L. Ahmad, S. Agarwal, C. M. Fang, A. R. Liu, V . Danry, E. Lee, S. W. Chan, P. Pataranutapornet al., “Investigating affective use and emotional well-being on chatgpt,”arXiv preprint arXiv:2504.03888, 2025
-
[7]
Artificial intelligence in positive mental health: a narrative review,
A. Thakkar, A. Gupta, and A. De Sousa, “Artificial intelligence in positive mental health: a narrative review,”Frontiers in digital health, vol. 6, p. 1280235, 2024
2024
-
[8]
Unpacking the gender-role interaction of prosodic entrainment in chinese long-and-short turn-taking: evidence from per- ceptual and acoustic similarities,
Y . Sun and H. Ding, “Unpacking the gender-role interaction of prosodic entrainment in chinese long-and-short turn-taking: evidence from per- ceptual and acoustic similarities,”Humanities and Social Sciences Communications, vol. 11, no. 1, p. 1618, 2024
2024
-
[9]
Measuring acoustic-prosodic entrainment with respect to multiple levels and dimensions,
R. Levitan and J. Hirschberg, “Measuring acoustic-prosodic entrainment with respect to multiple levels and dimensions,” inInterspeech 2011, 2011, pp. 3081–3084
2011
-
[10]
Modeling empathetic alignment in conversa- tion,
J. Yang and D. Jurgens, “Modeling empathetic alignment in conversa- tion,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), 2024, pp. 3127–3148
2024
-
[11]
Autoregressive cross-interlocutor attention scores meaningfully capture conversational dynamics
M. McNeill and R. Levitan, “Autoregressive cross-interlocutor attention scores meaningfully capture conversational dynamics.” ISCA, 2024
2024
-
[12]
V . R. D. M. Herbuela and Y . Nagai, “Spatiotemporal emotional syn- chrony in dyadic interactions: The role of speech conditions in facial and vocal affective alignment,”arXiv preprint arXiv:2505.13455, 2025
-
[13]
Speech emotion recognition using neural network and mlp classifier,
J. Joy, A. Kannan, S. Ram, and S. Rama, “Speech emotion recognition using neural network and mlp classifier,”Ijesc, vol. 2020, pp. 25 170– 25 172, 2020
2020
-
[14]
Dyad- former: A multi-modal transformer for long-range modeling of dyadic interactions,
D. Curto, A. Clap ´es, J. Selva, S. Smeureanu, J. Junior, J. CS, D. Gallardo-Pujol, G. Guilera, D. Leiva, T. B. Moeslundet al., “Dyad- former: A multi-modal transformer for long-range modeling of dyadic interactions,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2177–2188
2021
-
[15]
arXiv preprint arXiv:2506.22554 (2025) 4, 5, 22, 29
V . Agrawal, A. Akinyemi, K. Alvero, M. Behrooz, J. Buffalini, F. M. Carlucci, J. Chen, J. Chen, Z. Chen, S. Chenget al., “Seamless inter- action: Dyadic audiovisual motion modeling and large-scale dataset,” arXiv preprint arXiv:2506.22554, 2025
-
[16]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthramet al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
T. Feng, J. Lee, A. Xu, Y . Lee, T. Lertpetchpun, X. Shi, H. Wang, T. Thebaud, L. Moro-Velazquez, D. Byrdet al., “V ox-profile: A speech foundation model benchmark for characterizing diverse speaker and speech traits,”arXiv preprint arXiv:2505.14648, 2025
-
[18]
Emotivoice: a multi-voice and prompt-controlled tts engine,
NetEase Youdao, “Emotivoice: a multi-voice and prompt-controlled tts engine,” 2024, gitHub repository, commit. Accessed 2026-02-25
2024
-
[19]
arXiv preprint arXiv:2506.02863 , year=
H. Wang, J. Hai, D. Chong, K. Thakkar, T. Feng, D. Yang, J. Lee, T. Thebaud, L. M. Velazquez, J. Villalbaet al., “Capspeech: En- abling downstream applications in style-captioned text-to-speech,”arXiv preprint arXiv:2506.02863, 2025
-
[20]
Freevc: Towards high-quality text-free one-shot voice conversion,
J. Li, W. Tu, and L. Xiao, “Freevc: Towards high-quality text-free one-shot voice conversion,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[21]
Mossformer2: Combining transformer and rnn-free recurrent network for enhanced time-domain monaural speech separation,
S. Zhao, Y . Ma, C. Ni, C. Zhang, H. Wang, T. H. Nguyen, K. Zhou, J. Q. Yip, D. Ng, and B. Ma, “Mossformer2: Combining transformer and rnn-free recurrent network for enhanced time-domain monaural speech separation,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 356–10 360
2024
-
[22]
Fine-tuning whisper on low-resource languages for real-world applica- tions,
V . Timmel, C. Paonessa, M. V ogel, D. Perruchoud, and R. Kakooee, “Fine-tuning whisper on low-resource languages for real-world applica- tions,” inProceedings of the 10th edition of the Swiss Text Analytics Conference, 2025, pp. 57–65
2025
-
[23]
Does size matter? examining sentence similarity perfor- mance in large language models,
A. M. Korga, S. Wefers, K. Hanken, R. B. Tareaf, B. Steemers, and H. Avvad, “Does size matter? examining sentence similarity perfor- mance in large language models,” in2025 International Conference on Information Networking (ICOIN). IEEE, 2025, pp. 595–600
2025
-
[24]
Llama-omni 2: Llm- based real-time spoken chatbot with autoregressive streaming speech synthesis,
Q. Fang, Y . Zhou, S. Guo, S. Zhang, and Y . Feng, “Llama-omni 2: Llm- based real-time spoken chatbot with autoregressive streaming speech synthesis,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 18 617–18 629
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.