ViTL: Temporal Logic-Guided Zero-Shot Natural Language Navigation via Vision-Language Models
Pith reviewed 2026-07-01 02:08 UTC · model grok-4.3
The pith
ViTL turns natural language commands with timing constraints into logic formulas that steer vision-language models through multi-step navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
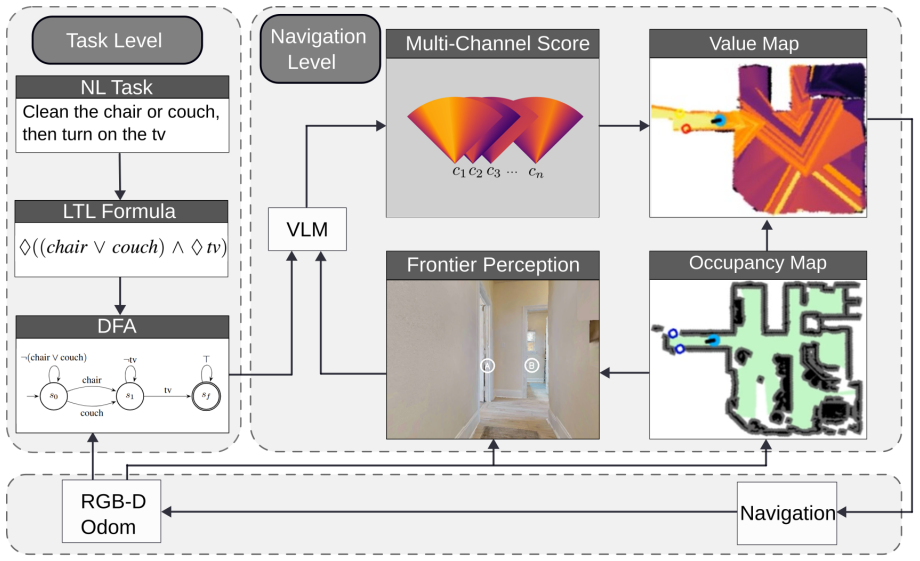
ViTL compiles natural language navigation commands into LTL formulas that are converted to DFAs; these DFAs coordinate multi-channel value maps and trigger dynamic replanning on new detections, while directional scoring from VLMs replaces direction-agnostic value maps, enabling zero-shot completion of long-horizon tasks with temporal constraints on HM3D.
What carries the argument
LTL-to-DFA conversion that coordinates multi-channel value maps for temporal constraints, paired with per-direction VLM scoring on labeled frontiers.
If this is right
- Robots can execute commands containing 'or', 'then', 'until', or similar constraints without retraining.
- Directional scoring raises accuracy and reduces steps needed for ordinary single-target searches.
- Newly detected objects automatically restart planning while respecting the original temporal order.
- The same pipeline scales to sequences longer than those handled by frontier-based VLM methods alone.
Where Pith is reading between the lines
- The directional scoring technique could be added to other VLM navigation systems even without temporal logic.
- If LLM translation to LTL becomes more reliable, the same structure might support spoken instructions for manipulation or inspection tasks.
- Real-world lighting, sensor noise, and speech recognition errors would test whether the simulation results transfer directly.
Load-bearing premise
Large language models can reliably translate arbitrary natural language commands into correct LTL formulas that capture every implicit temporal and logical constraint.
What would settle it
A command containing an implicit ordering or alternative that produces an LTL formula whose DFA drives the robot to visit targets in the wrong sequence or to miss a valid target entirely on HM3D.
Figures


read the original abstract
Enabling robots to follow natural language commands to complete zero-shot long-horizon tasks remains challenging. It requires extracting implicit temporal and logical constraints from natural language commands and executing multiple sub-tasks accordingly. Recent zero-shot object navigation methods use vision-language models (VLMs) to guide frontier-based exploration in unknown environments, but they are limited to single-target tasks. Real-world commands such as "Clean either the chair or the couch, then turn on the tv." require navigating to multiple targets in a temporally constrained order, which no existing zero-shot system can handle. We present ViTL, a framework that addresses this gap at two levels. At the task level, we use a large language model (LLM) to compile natural language commands into Linear Temporal Logic (LTL) formulas, which are then converted into Deterministic Finite Automata~(DFA) that coordinate multi-channel value maps and trigger dynamic replanning when new objects are detected. At the navigation level, we introduce directional score: rather than producing a direction-agnostic value across the entire field of view, we label frontier directions on the observation image and extract per-direction scores from the VLM. Experiments on Habitat-Matterport 3D (HM3D) show that the full framework enables zero-shot long-horizon completion of natural language navigation tasks with temporal constraints, and that directional score improves single-target navigation accuracy and efficiency over the baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViTL, a framework for zero-shot natural language navigation of long-horizon tasks with temporal constraints. At the task level, an LLM compiles natural language commands into LTL formulas that are converted to DFAs; these DFAs coordinate multi-channel value maps and trigger replanning upon new object detections. At the navigation level, a directional score extracts per-direction VLM scores from labeled frontier directions on the observation image rather than a single direction-agnostic value. Experiments on HM3D are claimed to show that the full framework enables zero-shot completion of temporally constrained multi-target tasks and that the directional score improves single-target accuracy and efficiency over a baseline.
Significance. If the central claims hold with supporting quantitative evidence, the work would represent a meaningful advance in combining formal methods (LTL/DFA) with VLMs for handling implicit temporal ordering in zero-shot navigation, addressing a clear gap beyond single-target methods. The directional-score mechanism is a concrete, local improvement that could be adopted more broadly. The approach reuses existing LTL and VLM components without introducing new free parameters or circular derivations.
major comments (2)
- [Abstract] Abstract: the central claim that the framework enables zero-shot long-horizon completion of natural language tasks with temporal constraints rests on the LLM reliably producing correct LTL formulas that capture all implicit ordering and logical constraints. No accuracy metrics, failure-mode analysis, or ground-truth LTL comparisons for the evaluated commands are supplied, leaving the DFA coordination step unverified.
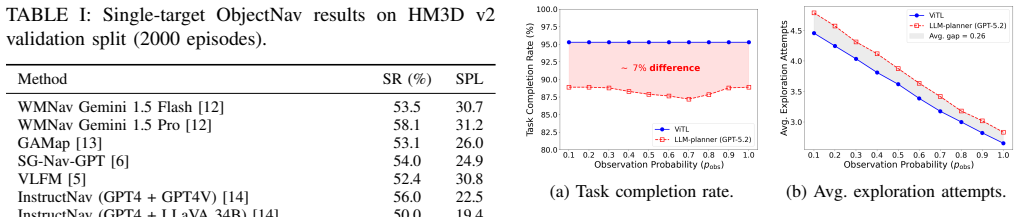
- [Abstract] Abstract (experimental claims): the statements that the full framework succeeds on HM3D and that directional score improves single-target navigation accuracy and efficiency are presented without any quantitative metrics, baselines, error analysis, or tables, preventing assessment of whether the data support the improvements.
minor comments (1)
- [Abstract] The abstract refers to 'multi-channel value maps' without a brief definition or pointer to the section that explains how DFA states map onto the channels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from greater quantitative support and will revise it (and add supporting analysis where needed) to address the points raised. Our responses to each major comment are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the framework enables zero-shot long-horizon completion of natural language tasks with temporal constraints rests on the LLM reliably producing correct LTL formulas that capture all implicit ordering and logical constraints. No accuracy metrics, failure-mode analysis, or ground-truth LTL comparisons for the evaluated commands are supplied, leaving the DFA coordination step unverified.
Authors: We agree that the abstract does not supply direct accuracy metrics, failure-mode analysis, or ground-truth LTL comparisons for the LLM compilation step. While end-to-end task success on HM3D provides indirect support, this leaves the DFA coordination unverified in the current text. We will add a new subsection (or appendix) with quantitative LTL accuracy metrics, failure cases, and ground-truth comparisons for the evaluated commands, and will update the abstract to reference these results. revision: yes
-
Referee: [Abstract] Abstract (experimental claims): the statements that the full framework succeeds on HM3D and that directional score improves single-target navigation accuracy and efficiency are presented without any quantitative metrics, baselines, error analysis, or tables, preventing assessment of whether the data support the improvements.
Authors: We agree that the abstract states the experimental outcomes without quoting specific metrics, baselines, or error analysis. The main body contains the supporting tables and figures, but the abstract itself does not enable direct assessment. We will revise the abstract to include key quantitative results (success rates, efficiency gains, and baseline comparisons) while preserving length constraints, and will ensure explicit pointers to the relevant tables and sections. revision: yes
Circularity Check
No circularity: framework composes standard LTL/VLM components without self-referential reduction
full rationale
The paper describes an applied framework chaining LLM-based NL-to-LTL compilation, DFA conversion, multi-channel value maps, and directional VLM scoring for navigation. No equations, fitted parameters, or derivations are presented that reduce to their own inputs by construction. The central claims rely on external components (LTL, VLMs, LLMs) applied to a new task without load-bearing self-citations or ansatzes that collapse into the target result. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM can reliably compile natural language commands into correct LTL formulas capturing all temporal and logical constraints
Reference graph
Works this paper leans on
-
[1]
Object goal navigation using goal-oriented semantic exploration,
D. S. Chaplot, D. P . Gandhi, A. Gupta, and R. Salakhutdinov, “Object goal navigation using goal-oriented semantic exploration,” in Advances in Neural Information Processing Systems (NeurIPS) , vol. 33, 2020, pp. 4247–4258
2020
-
[2]
PONI: Potential functions for objectgoal navigation with interaction-free learning,
S. K. Ramakrishnan, D. S. Chaplot, Z. Al-Halah, J. Malik, and K. Grauman, “PONI: Potential functions for objectgoal navigation with interaction-free learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2022, pp. 18 890–18 900
2022
-
[3]
CLIP on wheels: Zero-shot object navigation as object localization and exploration,
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “CLIP on wheels: Zero-shot object navigation as object localization and exploration,” arXiv preprint arXiv:2203.10421 , vol. 3, no. 4, p. 7, 2022
-
[4]
L3MVN: Leveraging large language models for visual target navigation,
B. Y u, H. Kasaei, and M. Cao, “L3MVN: Leveraging large language models for visual target navigation,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2023, pp. 3554–3560
2023
-
[5]
VLFM: Vision-language frontier maps for zero-shot semantic navigation,
N. Y okoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “VLFM: Vision-language frontier maps for zero-shot semantic navigation,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 42–48
2024
-
[6]
SG-Nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “SG-Nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,” Advances in neural information processing systems , vol. 37, pp. 5285–5307, 2024
2024
-
[7]
Lang2ltl: Translating natural language commands to temporal robot task specification,
J. X. Liu, Z. Y ang, I. Idrees, S. Liang, B. Schornstein, S. Tellex, and A. Shah, “Lang2ltl: Translating natural language commands to temporal robot task specification,” in 7th Annual Conference on Robot Learning (CoRL) , 2023
2023
-
[8]
LTLCodeGen: Code generation of syntactically correct temporal logic for robot task planning,
B. Rabiei, M. K. AR, Z. Dai, S. L. Pilla, Q. Dong, and N. Atanasov, “LTLCodeGen: Code generation of syntactically correct temporal logic for robot task planning,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2025, pp. 19 240– 19 247
2025
-
[9]
L. Luo, K. Liang, Y . Xia, and M. Cai, “Nl2spatial: Generating geometric spatio-temporal logic specifications from natural language for manipulation tasks,” arXiv preprint arXiv:2512.13670 , 2025
-
[10]
Linear temporal logic and linear dynamic logic on finite traces,
G. De Giacomo and M. Y . V ardi, “Linear temporal logic and linear dynamic logic on finite traces,” in Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence (IJCAI) , 2013, pp. 854–860
2013
-
[11]
ESC: Exploration with soft commonsense constraints for zero-shot object navigation,
K. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “ESC: Exploration with soft commonsense constraints for zero-shot object navigation,” in International Conference on Machine Learning (ICML) , 2023
2023
-
[12]
WMNA V: Integrating vision-language models into world models for object goal navigation,
D. Nie, X. Guo, Y . Duan, R. Zhang, and L. Chen, “WMNA V: Integrating vision-language models into world models for object goal navigation,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2025, pp. 2392–2399
2025
-
[13]
GAMap: Zero- shot object goal navigation with multi-scale geometric-affordance guidance,
H. Huang, Y . Hao, C. Wen, A. Tzes, Y . Fang et al. , “GAMap: Zero- shot object goal navigation with multi-scale geometric-affordance guidance,” Advances in Neural Information Processing Systems , vol. 37, pp. 39 386–39 408, 2024
2024
-
[14]
InstructNav: Zero-shot system for generic instruction navigation in unexplored environment,
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong, “InstructNav: Zero-shot system for generic instruction navigation in unexplored environment,” in Conference on Robot Learning . PMLR, 2025, pp. 2049–2060
2025
-
[15]
NavGpt-2: Unleashing navigational reasoning capability for large vision-language models,
G. Zhou, Y . Hong, Z. Wang, X. E. Wang, and Q. Wu, “NavGpt-2: Unleashing navigational reasoning capability for large vision-language models,” in European Conference on Computer Vision . Springer, 2024, pp. 260–278
2024
-
[16]
Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suen- derhauf, “Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning,” in Conference on Robot Learning. PMLR, 2023, pp. 23–72
2023
-
[17]
Nl2tl: Transforming natural languages to temporal logics using large language models,
Y . Chen, R. Gandhi, Y . Zhang, and C. Fan, “Nl2tl: Transforming natural languages to temporal logics using large language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 15 880–15 903
2023
-
[18]
NL2LTL–a python package for converting natural language (nl) instructions to linear temporal logic (ltl) formulas,
F. Fuggitti and T. Chakraborti, “NL2LTL–a python package for converting natural language (nl) instructions to linear temporal logic (ltl) formulas,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 13, 2023, pp. 16 428–16 430
2023
-
[19]
Nl2Hltl2Plan: Scaling up natural language understanding for multi-robots through hierarchical temporal logic task specifications,
S. Xu, X. Luo, Y . Huang, L. Leng, R. Liu, and C. Liu, “Nl2Hltl2Plan: Scaling up natural language understanding for multi-robots through hierarchical temporal logic task specifications,” IEEE Robotics and Automation Letters , 2025
2025
-
[20]
SELP: Generating safe and efficient task plans for robot agents with large language models,
Y . Wu, Z. Xiong, Y . Hu, S. S. Iyengar, N. Jiang, A. Bera, L. Tan, and S. Jagannathan, “SELP: Generating safe and efficient task plans for robot agents with large language models,” in 2025 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2025, pp. 2599–2605
2025
-
[21]
Motion planning under temporal logic specifications in semantically unknown environments,
A. Taheri and D. Aksaray, “Motion planning under temporal logic specifications in semantically unknown environments,” arXiv preprint arXiv:2511.03652, 2025
-
[22]
Spot 2.0a framework for ltl and-automata manipulation,
A. Duret-Lutz, A. Lewkowicz, A. Fauchille, T. Michaud, E. Renault, and L. Xu, “Spot 2.0a framework for ltl and-automata manipulation,” in International Symposium on Automated Technology for V erification and Analysis . Springer, 2016, pp. 122–129
2016
-
[23]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymets et al. , “Habitat 2.0: Training home assistants to rearrange their habitat,” in Advances in Neural Information Processing Systems (NeurIPS) , vol. 34, 2021, pp. 251–266
2021
-
[24]
Habitat-matterport 3d dataset (hm3d): 1000 large- scale 3d environments for embodied ai,
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang et al. , “Habitat-matterport 3d dataset (hm3d): 1000 large- scale 3d environments for embodied ai,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[25]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems , vol. 36, pp. 34 892–34 916, 2023
2023
-
[26]
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,
C.-Y . Wang, A. Bochkovskiy, and H.-Y . M. Liao, “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2023, pp. 7464–7475
2023
-
[27]
Optimality and robustness in multi-robot path planning with temporal logic con- straints,
A. Ulusoy, S. L. Smith, X. C. Ding, C. Belta, and D. Rus, “Optimality and robustness in multi-robot path planning with temporal logic con- straints,” in The International Journal of Robotics Research , vol. 32, no. 8, 2013, pp. 889–911
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.