SkillSpotter: Pose-Aware Multi-View Skilled Action Detection and Grading in Ego-Exo Videos
Pith reviewed 2026-07-01 06:53 UTC · model grok-4.3
The pith
SkillSpotter detects and grades skilled actions in ego-exo videos by fusing 3D body pose with multi-view features, raising mAP 76% over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
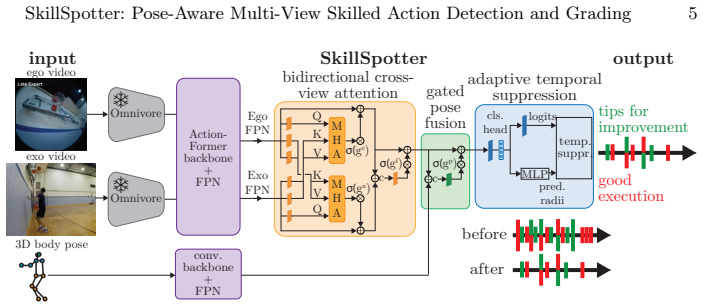
SkillSpotter is a pose-aware multi-view architecture that jointly detects and grades skilled actions through adaptive temporal suppression to handle varying densities, gated 3D body pose fusion to leverage kinematics as a complementary signal to visual features, and bidirectional cross-view attention to combine ego and exo views. It improves class-specific mAP from 12.40 to 21.82 and balanced accuracy from 55.99% to 60.40% over the best baseline on the Ego-Exo4D proficiency demonstration benchmark. The modules transfer to other temporal action detection models with consistent gains and the method generalizes to HoloAssist.
What carries the argument
gated 3D body pose fusion module that integrates body kinematics as a complementary signal to visual features for improved proficiency grading
If this is right
- The three modules transfer to other temporal action detection models with consistent gains.
- The method generalizes beyond Ego-Exo4D to the HoloAssist dataset.
- Existing state-of-the-art detectors grade near-randomly when extended to this detection-plus-grading task.
- The system supports understanding execution quality for applications such as real-time coaching with AR glasses or fixed cameras.
Where Pith is reading between the lines
- The gated pose fusion might be tested in single-view settings to isolate whether multi-view attention is required for the observed grading gains.
- Adaptive temporal suppression could be evaluated on datasets with highly irregular action timing to check robustness outside the current benchmark.
- The overall approach may extend to grading tasks in domains like surgical training where body kinematics are observable but visual cues alone are insufficient.
Load-bearing premise
That 3D body pose kinematics supply a complementary signal to visual features that meaningfully improves grading of action proficiency rather than merely aiding detection.
What would settle it
An ablation experiment on Ego-Exo4D showing no drop in balanced accuracy when the gated 3D body pose fusion module is removed would falsify the claim that pose fusion improves grading.
Figures
read the original abstract
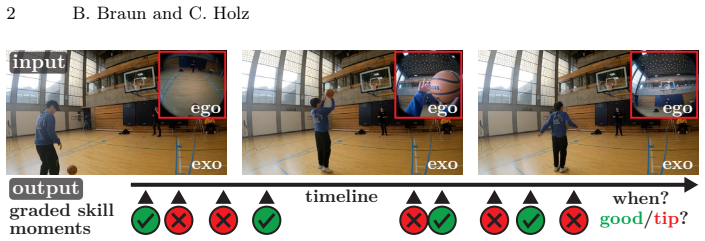
To enable personalized, real-time coaching using Augmented Reality glasses or fixed camera setups in domains such as sports, cooking, or music, a system must understand not just what a person does, but how well they execute an activity. In an ego-exo video setting, this requires simultaneously detecting individual skilled actions and classifying each as correct or needing improvement, which Ego-Exo4D's proficiency demonstration benchmark formalized. We first adapt seven state-of-the-art temporal action detection architectures to this task, extend the evaluation protocol to disentangle detection from grading, and show that existing methods grade near-randomly. We then introduce SkillSpotter, a pose-aware multi-view architecture that jointly detects and grades skilled actions through three task-specific modules: (1) adaptive temporal suppression to handle the varying density of skilled actions across diverse activities, (2) gated 3D body pose fusion to leverage body kinematics as a complementary signal to visual features, and (3) bidirectional cross-view attention to combine ego and exo views effectively. SkillSpotter improves class-specific mAP from 12.40 to 21.82 (+76%) and balanced accuracy from 55.99% to 60.40% over the best baseline. SkillSpotter's modules transfer to other temporal action detection models with consistent gains, and our method generalizes beyond Ego-Exo4D to HoloAssist. Code: https://github.com/eth-siplab/SkillSpotter
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SkillSpotter, a pose-aware multi-view architecture for joint skilled action detection and proficiency grading in ego-exo videos. It adapts seven state-of-the-art temporal action detection models to the Ego-Exo4D proficiency demonstration benchmark, extends the evaluation protocol to disentangle detection (class-specific mAP) from grading (balanced accuracy), shows that baselines grade near-randomly, and introduces three modules—adaptive temporal suppression, gated 3D body pose fusion, and bidirectional cross-view attention—that improve mAP from 12.40 to 21.82 (+76%) and balanced accuracy from 55.99% to 60.40% over the best baseline. The modules transfer to other models with consistent gains, the method generalizes to HoloAssist, and code is released.
Significance. If the reported gains hold under more rigorous validation, the work advances multi-view action understanding by incorporating 3D pose kinematics for proficiency assessment, with direct relevance to AR coaching applications. Explicit strengths include the released code, the disentangled evaluation protocol, and the demonstration that existing methods fail at grading; these elements support reproducibility and follow-on research even if the specific module contributions require further isolation.
major comments (2)
- [Abstract / gated 3D body pose fusion module] Abstract and gated 3D body pose fusion module description: the claim that this module supplies kinematics complementary to visual features specifically for proficiency grading (balanced accuracy) rather than only detection (mAP) is load-bearing for the central contribution, yet no ablation disables only the pose fusion while reporting differential impact on the grading metric. The +4.41% balanced accuracy gain could be driven by the other two modules or the visual backbone alone.
- [Experimental results] Experimental results: the abstract and results report point estimates for mAP and balanced accuracy without error bars, standard deviations across multiple runs, or a full experimental protocol (hyperparameter search, data splits, training details), which is required to establish that the gains are statistically reliable and not artifacts of a single run or tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the strengths of the code release, the disentangled evaluation protocol, and the observation that existing methods struggle with grading. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / gated 3D body pose fusion module] Abstract and gated 3D body pose fusion module description: the claim that this module supplies kinematics complementary to visual features specifically for proficiency grading (balanced accuracy) rather than only detection (mAP) is load-bearing for the central contribution, yet no ablation disables only the pose fusion while reporting differential impact on the grading metric. The +4.41% balanced accuracy gain could be driven by the other two modules or the visual backbone alone.
Authors: We agree that the specific contribution of the gated 3D body pose fusion to the grading task would be better supported by an ablation that disables only this module and reports the impact on balanced accuracy. While the manuscript demonstrates overall gains and transferability of the modules, it does not include this isolated ablation for the grading metric. We will add this ablation in the revised manuscript to clarify the module's role. revision: yes
-
Referee: [Experimental results] Experimental results: the abstract and results report point estimates for mAP and balanced accuracy without error bars, standard deviations across multiple runs, or a full experimental protocol (hyperparameter search, data splits, training details), which is required to establish that the gains are statistically reliable and not artifacts of a single run or tuning.
Authors: We recognize that providing measures of variability strengthens the reliability of the reported gains. The current results are point estimates from single runs using the protocol detailed in the supplementary material. In the revision, we will perform multiple runs with different random seeds, report means and standard deviations for mAP and balanced accuracy, and ensure the experimental protocol is clearly summarized in the main paper. revision: yes
Circularity Check
No circularity: empirical gains on public benchmark with independent baselines and released code
full rationale
The paper adapts existing temporal action detection architectures to the Ego-Exo4D proficiency benchmark, introduces three modules (adaptive temporal suppression, gated 3D pose fusion, bidirectional cross-view attention), and reports mAP and balanced accuracy improvements measured against external baselines. No equations, fitted parameters, or self-citations reduce the reported metrics to quantities defined by the authors' own inputs or prior work; the evaluation protocol explicitly disentangles detection from grading on a released dataset with code provided. The central claims rest on standard empirical comparison rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing temporal action detection architectures can be directly adapted to the skilled-action grading task while preserving their detection heads.
Reference graph
Works this paper leans on
-
[1]
Gated Multimodal Units for Information Fusion
Arevalo, J., Solorio, T., Montes-y Gómez, M., González, F.A.: Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ashutosh, K., Nagarajan, T., Pavlakos, G., Kitani, K., Grauman, K.: Expertaf: Expert actionable feedback from video. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13582–13594 (2025)
2025
-
[3]
In: 2025 IEEE International Workshop on Sport, Technol- ogy and Research (STAR)
Bianchi, E., Liotta, A.: Pats: Proficiency-aware temporal sampling for multi-view sports skill assessment. In: 2025 IEEE International Workshop on Sport, Technol- ogy and Research (STAR). pp. 1–6. IEEE (2025)
2025
-
[4]
arXiv preprint arXiv:2505.08665 (2025)
Bianchi, E., Liotta, A.: Skillformer: Unified multi-view video understanding for proficiency estimation. arXiv preprint arXiv:2505.08665 (2025)
-
[5]
ProfVLM: A lightweight video-language model for multi-view proficiency estimation
Bianchi, E., Staiano, J., Liotta, A.: Profvlm: A lightweight video-language model for multi-view proficiency estimation. arXiv preprint arXiv:2509.26278 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In: Proceedings of the IEEE international conference on computer vision
Bodla, N., Singh, B., Chellappa, R., Davis, L.S.: Soft-nms–improving object de- tection with one line of code. In: Proceedings of the IEEE international conference on computer vision. pp. 5561–5569 (2017)
2017
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision
Braun, B., Armani, R., Meier, M., Moebus, M., Holz, C.: egoPPG: Heart rate es- timation from eye-tracking cameras in egocentric systems to benefit downstream vision tasks. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision. pp. 5579–5590 (2025)
2025
-
[8]
Biomedical Optics Ex- press14(12), 6607–6628 (2023)
Braun, B., McDuff, D., Baltrusaitis, T., Holz, C.: Video-based sympathetic arousal assessment via peripheral blood flow estimation. Biomedical Optics Ex- press14(12), 6607–6628 (2023)
2023
-
[9]
In: 2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI)
Braun, B., McDuff, D., Baltrusaitis, T., Streli, P., Moebus, M., Holz, C.: Symp- cam: Remote optical measurement of sympathetic arousal. In: 2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). pp. 1–8. IEEE (2024)
2024
-
[10]
Braun, B., McDuff, D., Holz, C.: How suboptimal is training rppg models with videos and targets from different body sites? In: Proceedings of the ieee/cvf con- ference on computer vision and pattern recognition. pp. 410–418 (2024)
2024
-
[11]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[12]
Castillo, A., Escobar, M., Jeanneret, G., Pumarola, A., Arbeláez, P., Thabet, A., Sanakoyeu, A.: Bodiffusion: Diffusing sparse observations for full-body human mo- tionsynthesis.In:ProceedingsoftheIEEE/CVFInternationalConferenceonCom- puter Vision. pp. 4221–4231 (2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Chen, C.F.R., Fan, Q., Panda, R.: Crossvit: Cross-attention multi-scale vision transformer for image classification. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 357–366 (2021)
2021
-
[14]
International Journal of Computer Vision134(1), 20 (2026)
Chen, G., Huang, Y., Xu, J., Pei, B., Wang, J., Chen, Z., Li, Z., Lu, T., Wang, L.: Video mamba suite: State space model as a versatile alternative for video under- standing. International Journal of Computer Vision134(1), 20 (2026)
2026
-
[15]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Deliege, A., Cioppa, A., Giancola, S., Seikavandi, M.J., Dueholm, J.V., Nasrollahi, K., Ghanem, B., Moeslund, T.B., Van Droogenbroeck, M.: Soccernet-v2: A dataset and benchmarks for holistic understanding of broadcast soccer videos. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4508–4519 (2021) SkillSpotter: ...
2021
-
[16]
IEEE Transactions on Biomedical Engineering pp
Demirel, B.U., Holz, C.: Continuous heart rate variability estimation from ppg via state-space modeling. IEEE Transactions on Biomedical Engineering pp. 1–8 (2026).https://doi.org/10.1109/TBME.2026.3678004
-
[17]
In: European Conference on Computer Vision (ECCV) (2026)
Demirel, B.U., Holz, C.: EgoHRV: Continuous heart rate variability estimation from egocentric systems for autonomic response and skill assessment. In: European Conference on Computer Vision (ECCV) (2026)
2026
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Duan, H., Zhao, Y., Chen, K., Lin, D., Dai, B.: Revisiting skeleton-based action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2969–2978 (2022)
2022
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Giancola, S., Amine, M., Dghaily, T., Ghanem, B.: Soccernet: A scalable dataset for action spotting in soccer videos. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 1711–1721 (2018)
2018
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Girdhar, R., Singh, M., Ravi, N., Van Der Maaten, L., Joulin, A., Misra, I.: Omni- vore: A single model for many visual modalities. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16102–16112 (2022)
2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024)
2024
-
[22]
Han, B., Xu, Q., Bao, S., Yang, Z., Li, S., Huang, Q.: Dual-stage reweighted moe for long-tailed egocentric mistake detection. arXiv preprint arXiv:2509.12990 (2025)
-
[23]
In: Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track (2024)
Hollidt, D., Streli, P., Jiang, J., Haghighi, Y., Qian, C., Liu, X., Holz, C.: EgoSim: An egocentric multi-view simulator and real dataset for body-worn cameras dur- ing motion and activity. In: Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track (2024)
2024
-
[24]
In: European Conference on Computer Vision
Hong, J., Zhang, H., Gharbi, M., Fisher, M., Fatahalian, K.: Spotting temporally precise, fine-grained events in video. In: European Conference on Computer Vision. pp. 33–51. Springer (2022)
2022
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Hosang, J., Benenson, R., Schiele, B.: Learning non-maximum suppression. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4507–4515 (2017)
2017
-
[26]
In: Proceedings of the IEEE/CVF international conference on computer vision
Iskakov, K., Burkov, E., Lempitsky, V., Malkov, Y.: Learnable triangulation of hu- man pose. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7718–7727 (2019)
2019
-
[27]
arXiv preprint arXiv:2510.22129 (2025)
Jammot, M., Braun, B., Streli, P., Wampfler, R., Holz, C.: egoEMOTION: Ego- centric vision and physiological signals for emotion and personality recognition in real-world tasks. arXiv preprint arXiv:2510.22129 (2025)
-
[28]
In: European Conference on Computer Vision (ECCV) (2024)
Jiang,J.,Streli,P.,Meier,M.,Holz,C.:EgoPoser:Robustreal-timeegocentricpose estimation from sparse and intermittent observations everywhere. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[29]
In: European con- ference on computer vision
Jiang, J., Streli, P., Qiu, H., Fender, A., Laich, L., Snape, P., Holz, C.: Avatarposer: Articulated full-body pose tracking from sparse motion sensing. In: European con- ference on computer vision. pp. 443–460. Springer (2022)
2022
-
[30]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Kwak, I., Guo, J.Z., Hantman, A., Kriegman, D., Branson, K.: Detecting the start- ing frame of actions in video. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 489–497 (2020)
2020
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Nagarajan, T., Xiong, B., Grauman, K.: Ego-exo: Transferring visual representations from third-person to first-person videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6943– 6953 (2021) 18 B. Braun and C. Holz
2021
-
[32]
In: Eu- ropean conference on computer vision
Li, Y.M., Huang, W.J., Wang, A.L., Zeng, L.A., Meng, J.K., Zheng, W.S.: Egoexo- fitness: Towards egocentric and exocentric full-body action understanding. In: Eu- ropean conference on computer vision. pp. 363–382. Springer (2024)
2024
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Y.M., Wang, A.L., Zeng, L.A., Lin, K.Y., Tang, Y.M., Zheng, W.: Techcoach: Towards technical-point-aware descriptive action coaching. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 6699–6707 (2026)
2026
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C., Xu, C., Luo, D., Wang, Y., Tai, Y., Wang, C., Li, J., Huang, F., Fu, Y.: Learning salient boundary feature for anchor-free temporal action localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 3320–3329 (2021)
2021
-
[35]
In: Proceedings of the IEEE/CVF interna- tional conference on computer vision
Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: Bmn: Boundary-matching network for temporal action proposal generation. In: Proceedings of the IEEE/CVF interna- tional conference on computer vision. pp. 3889–3898 (2019)
2019
-
[36]
In: Proceedings of the European conference on computer vision (ECCV)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: Bsn: Boundary sensitive network for temporal action proposal generation. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
2018
-
[37]
arXiv preprint arXiv:2407.17792 (2024)
Liu, S., Sui, L., Zhang, C.L., Mu, F., Zhao, C., Ghanem, B.: Harnessing temporal causality for advanced temporal action detection. arXiv preprint arXiv:2407.17792 (2024)
-
[38]
Liu, S., Zhao, C., Zohra, F., Soldan, M., Pardo, A., Xu, M., Alssum, L., Ra- mazanova, M., Alcázar, J.L., Cioppa, A., et al.: Opentad: A unified framework and comprehensivestudyoftemporalactiondetection.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 2625–2635 (2025)
2025
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Huang, D., Wang, Y.: Adaptive nms: Refining pedestrian detection in a crowd. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6459–6468 (2019)
2019
-
[40]
IEEE Transactions on Image Processing 31, 5427–5441 (2022)
Liu, X., Wang, Q., Hu, Y., Tang, X., Zhang, S., Bai, S., Bai, X.: End-to-end tem- poral action detection with transformer. IEEE Transactions on Image Processing 31, 5427–5441 (2022)
2022
-
[41]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Parmar, P., Morris, B.T.: What and how well you performed? a multitask learning approach to action quality assessment. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 304–313 (2019)
2019
-
[43]
In: Proceedings of the AAAI conference on artificial intelligence
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21096–21106 (2022)
2022
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shi, D., Zhong, Y., Cao, Q., Ma, L., Li, J., Tao, D.: Tridet: Temporal action detection with relative boundary modeling. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18857–18866 (2023)
2023
-
[46]
arXiv preprint arXiv:2303.09055 (2023)
Tang, T.N., Kim, K., Sohn, K.: Temporalmaxer: Maximize temporal context with only max pooling for temporal action localization. arXiv preprint arXiv:2303.09055 (2023)
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tang, Y., Ni, Z., Zhou, J., Zhang, D., Lu, J., Wu, Y., Zhou, J.: Uncertainty-aware score distribution learning for action quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9839–9848 (2020) SkillSpotter: Pose-Aware Multi-View Skilled Action Detection and Grading 19
2020
-
[48]
In: 2021 International conference on networking systems of AI (INSAI)
Wang, S., Yang, D., Zhai, P., Yu, Q., Suo, T., Sun, Z., Li, K., Zhang, L.: A sur- vey of video-based action quality assessment. In: 2021 International conference on networking systems of AI (INSAI). pp. 1–9. IEEE (2021)
2021
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, X., Kwon, T., Rad, M., Pan, B., Chakraborty, I., Andrist, S., Bohus, D., Feniello, A., Tekin, B., Frujeri, F.V., et al.: Holoassist: an egocentric human in- teraction dataset for interactive ai assistants in the real world. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20270–20281 (2023)
2023
-
[50]
SkillSight: Efficient First-Person Skill Assessment with Gaze
Wu, C.H., Ashutosh, K., Grauman, K.: Skillsight: Efficient first-person skill assess- ment with gaze. arXiv preprint arXiv:2511.19629 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xarles, A., Escalera, S., Moeslund, T.B., Clapés, A.: T-deed: Temporal- discriminability enhancer encoder-decoder for precise event spotting in sports videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3410–3419 (2024)
2024
-
[52]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu,A.,Zeng,L.A.,Zheng,W.S.:Likertscoringwithgradedecouplingforlong-term action assessment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3232–3241 (2022)
2022
-
[53]
In: Proceed- ings of the IEEE/CVF Conference on computer vision and pattern recognition
Xu, J., Yin, S., Zhao, G., Wang, Z., Peng, Y.: Fineparser: A fine-grained spatio- temporal action parser for human-centric action quality assessment. In: Proceed- ings of the IEEE/CVF Conference on computer vision and pattern recognition. pp. 14628–14637 (2024)
2024
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, M., Zhao, C., Rojas, D.S., Thabet, A., Ghanem, B.: G-tad: Sub-graph localiza- tion for temporal action detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10156–10165 (2020)
2020
-
[55]
Advances in neural information processing systems35, 38571–38584 (2022)
Xu, Y., Zhang, J., Zhang, Q., Tao, D.: Vitpose: Simple vision transformer baselines for human pose estimation. Advances in neural information processing systems35, 38571–38584 (2022)
2022
-
[56]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yan, S., Xiong, X., Arnab, A., Lu, Z., Zhang, M., Sun, C., Schmid, C.: Multiview transformers for video recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3333–3343 (2022)
2022
-
[57]
In: European conference on computer vision
Yang, L., Zheng, Z., Han, Y., Cheng, H., Song, S., Huang, G., Li, F.: Dyfadet: Dy- namic feature aggregation for temporal action detection. In: European conference on computer vision. pp. 305–322. Springer (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF international confer- ence on computer vision
Yu, X., Rao, Y., Zhao, W., Lu, J., Zhou, J.: Group-aware contrastive regression for action quality assessment. In: Proceedings of the IEEE/CVF international confer- ence on computer vision. pp. 7919–7928 (2021)
2021
-
[59]
In: European Conference on Computer Vision
Zhang, C.L., Wu, J., Li, Y.: Actionformer: Localizing moments of actions with transformers. In: European Conference on Computer Vision. pp. 492–510. Springer (2022)
2022
-
[60]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhao, C., Thabet, A.K., Ghanem, B.: Video self-stitching graph network for tempo- ral action localization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13658–13667 (2021)
2021
-
[61]
A Comprehensive Survey of Action Quality Assessment: Method and Benchmark
Zhou, K., Cai, R., Wang, L., Shum, H.P., Liang, X.: A comprehensive survey of ac- tion quality assessment: Method and benchmark. arXiv preprint arXiv:2412.11149 (2024) 20 B. Braun and C. Holz A Computational Cost Tab. 6 reports model size, FLOPs, throughput, and latency for each ablation configuration. Adaptive suppression adds negligible overhead (+0.07M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.