CooperScene: Multi-Modal Cooperative Autonomy Benchmark with C-V2X Communication Characterization
Pith reviewed 2026-07-01 06:05 UTC · model grok-4.3
The pith
CooperScene introduces a benchmark dataset for cooperative autonomy that records real C-V2X communication from commercial radios across three vehicles and one roadside unit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CooperScene is a high-fidelity cooperative autonomy dataset with real-world C-V2X communication characterization. The dataset is organized into diverse scenes involving three CAVs and one RSU, all equipped with multi-modal sensors and commercial C-V2X radios. Scenes are annotated with globally consistent 3D labels at 10 Hz, totaling 344K objects across 59K frames, underpinned by tight sensor- and agent-synchronization, centimeter-level localization and spatial alignment, precise cross-modality calibration, and 3GPP-standard-compliant C-V2X communication. CooperScene establishes a rigorous benchmark for evaluating multi-agent scaling and actual performance in real-world deployable settings.
What carries the argument
The CooperScene dataset, which records synchronized multi-modal sensor streams and C-V2X communication traces from three CAVs plus one RSU across varied real scenes.
If this is right
- Algorithms can be tested for robustness when communication bandwidth varies and is limited rather than assumed perfect.
- Evaluation can now include scaling to multiple agents and infrastructure units instead of pairs.
- Methods handling heterogeneous sensor modalities across agents can be compared on standardized real traces.
- Development of cooperative systems can target metrics that reflect deployable conditions with commercial radios.
Where Pith is reading between the lines
- The benchmark could be extended by adding explicit tasks for prediction and planning to measure end-to-end cooperative performance.
- Direct comparison of the recorded C-V2X traces against simulated channel models would highlight where current models fail to capture real bandwidth dynamics.
- Widespread use might push industry groups to adopt similar multi-agent, multi-modality test protocols for certification of cooperative driving features.
Load-bearing premise
The collected scenes, sensor setups, and C-V2X traces with commercial radios are representative of the real-world deployment complexities that existing datasets overlook.
What would settle it
If cooperative algorithms evaluated on CooperScene produce performance numbers that diverge from results obtained in live uncontrolled road tests using comparable hardware and traffic densities, the benchmark's representativeness would be challenged.
Figures

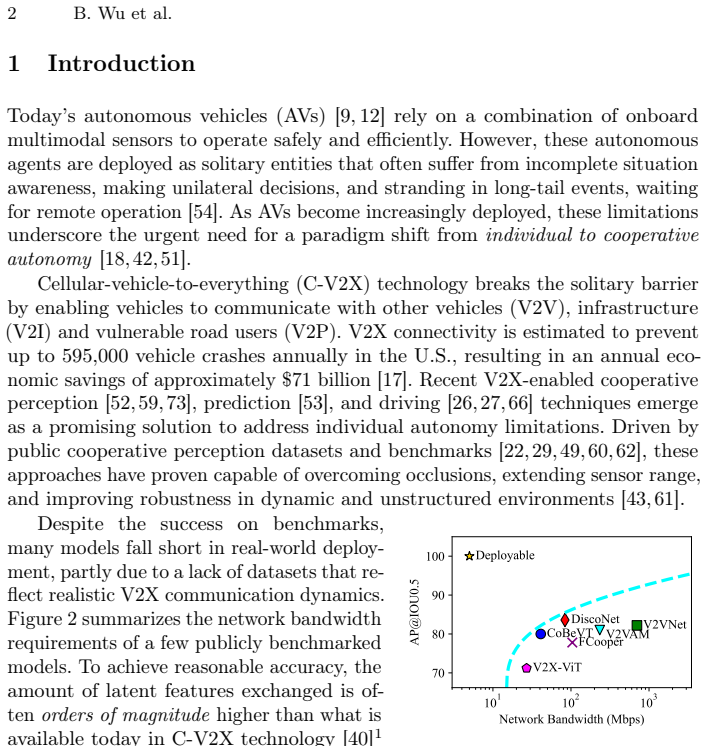


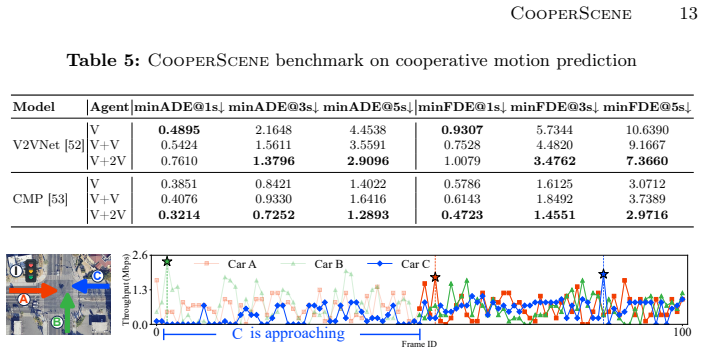
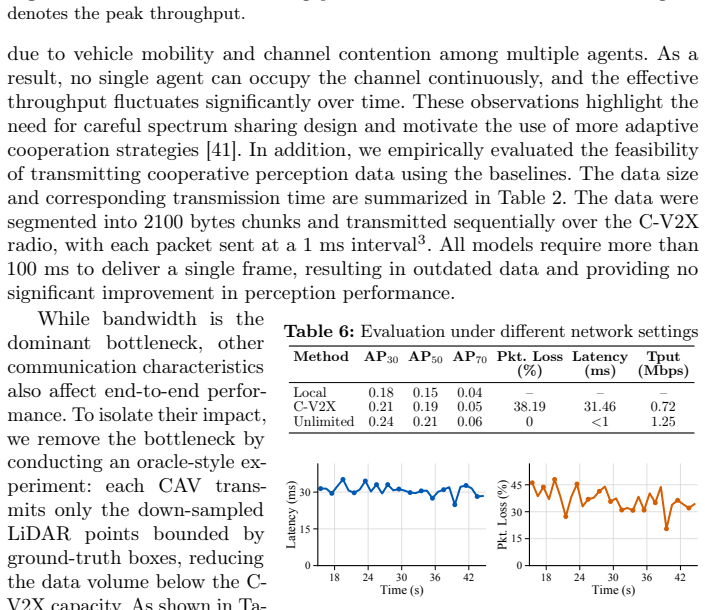

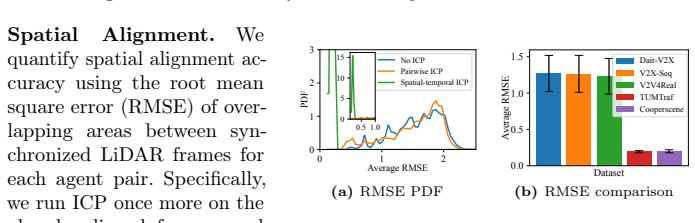






read the original abstract
Cellular vehicle-to-everything (C-V2X) enables cooperative perception, prediction, and planning beyond the field of view of individual agents. However, existing datasets often overlook the complexities of real-world deployment, such as limited communication bandwidth and its dynamics, heterogeneous sensing modalities, and scalability beyond a single cooperative partner. In this paper, we introduce CooperScene, a high-fidelity cooperative autonomy dataset with real-world C-V2X communication characterization. The dataset is organized into diverse scenes, including intersections, highway ramps, and parking lots. These scenes involve three connected and autonomous vehicles (CAVs) and one infrastructure roadside unit (RSU), all equipped with multi-modal sensors and commercial off-the-shelf C-V2X communication radios. All scenes are annotated with globally consistent 3D labels at 10 Hz, totaling 344K objects across 59K frames, underpinned by tight sensor- and agent-synchronization, centimeter-level localization and spatial alignment, precise cross-modality calibration, and 3GPP-standard-compliant C-V2X communication. CooperScene establishes a rigorous benchmark for evaluating multi-agent scaling and actual performance in real-world deployable settings. Project website for data and benchmark: https://cisl.ucr.edu/CooperScene
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CooperScene, a high-fidelity multi-modal cooperative autonomy dataset featuring data from three connected autonomous vehicles (CAVs) and one roadside unit (RSU) equipped with various sensors and commercial C-V2X radios. The dataset covers diverse scenes such as intersections, highway ramps, and parking lots, with globally consistent 3D annotations at 10 Hz, totaling 344K objects across 59K frames. It emphasizes tight synchronization, centimeter-level localization, precise calibration, and 3GPP-compliant C-V2X communication, positioning itself as a benchmark for evaluating multi-agent scaling and real-world performance in cooperative autonomy.
Significance. If the data collection and characterization claims are validated, CooperScene could significantly advance research in cooperative perception and planning by providing real-world C-V2X communication traces and multi-modal data under realistic constraints, which are often missing in existing datasets. This would enable more accurate evaluation of algorithms in deployable settings.
major comments (2)
- [Abstract] Abstract: The assertion that the dataset 'establishes a rigorous benchmark for evaluating multi-agent scaling' is undermined by the fixed configuration of exactly three CAVs and one RSU in all scenes, with no reported variation in agent count or density. This prevents direct empirical assessment of scaling trends from the collected data.
- [Abstract] Abstract: The abstract asserts high-fidelity properties including centimeter-level localization, precise cross-modality calibration, and 3GPP-standard-compliant C-V2X communication, but provides no validation measurements, error analysis, or comparison tables to support these claims.
minor comments (1)
- [Abstract] Abstract: The total number of frames and objects is given, but it would be helpful to include breakdowns by scene type for better context on diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the dataset 'establishes a rigorous benchmark for evaluating multi-agent scaling' is undermined by the fixed configuration of exactly three CAVs and one RSU in all scenes, with no reported variation in agent count or density. This prevents direct empirical assessment of scaling trends from the collected data.
Authors: We agree that the fixed configuration of three CAVs and one RSU across all scenes does not permit direct empirical assessment of scaling trends with varying agent counts or densities from the collected data. The phrasing in the abstract regarding 'multi-agent scaling' is therefore not fully supported by the dataset design. We will revise the abstract to remove this specific claim and instead state that CooperScene establishes a benchmark for evaluating cooperative autonomy in multi-agent settings with real-world C-V2X constraints. revision: yes
-
Referee: [Abstract] Abstract: The abstract asserts high-fidelity properties including centimeter-level localization, precise cross-modality calibration, and 3GPP-standard-compliant C-V2X communication, but provides no validation measurements, error analysis, or comparison tables to support these claims.
Authors: The abstract summarizes properties achieved during data collection, with supporting characterization and compliance details provided in the main manuscript sections on sensor setup, localization, calibration, and C-V2X communication. However, the abstract itself does not include explicit validation metrics or references. We will revise the abstract to qualify these claims by adding a brief reference to the validation and characterization results presented in the body of the paper. revision: yes
Circularity Check
No circularity: dataset contribution with no derivations or self-referential claims
full rationale
The paper presents a data-collection effort (scenes, sensors, C-V2X traces, annotations) rather than any derivation chain, equations, fitted parameters, or predictions. The abstract's benchmark claim is a statement about the dataset's intended use, not a result derived from prior steps within the paper. No self-citations, ansatzes, or reductions to inputs appear in the provided text. This is the expected non-finding for a benchmark paper whose central contribution is empirical data rather than a closed-form result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The recorded scenes, sensor configurations, and C-V2X traces are representative of real-world deployment complexities such as bandwidth dynamics and multi-agent scaling.
Reference graph
Works this paper leans on
-
[1]
Cohda Wireless MK6.https://www.cohdawireless.com/solutions/mk6/
-
[2]
Iperf 2.https://iperf.fr/iperf-doc.php
-
[3]
Linux ptp4l.https://linuxptp.nwtime.org
-
[4]
https://thinklucid.com/product/triton- 5- mp- imx490/
Lucid Triton Gig-e Camera. https://thinklucid.com/product/triton- 5- mp- imx490/
-
[5]
Mikrotik poe css610-8p-2s+in.https://mikrotik.com/product/css610_8p_2s_in
-
[6]
OptiTrack Motion Capture System.https://optitrack.com/
-
[7]
Ouster.https://ouster.com
-
[8]
https://www.calian.com/advanced- technologies/gnss_ product/tw8889-dual-band-gnss-antenna
Tallysman tw8889. https://www.calian.com/advanced- technologies/gnss_ product/tw8889-dual-band-gnss-antenna
-
[9]
https://www.tesla.com/robotaxi
Tesla Robotaxi. https://www.tesla.com/robotaxi
-
[10]
https : / / www
Thunderbolt 4 10g ethernet adapter. https : / / www . owc . com / solutions / thunderbolt-4-10g-ethernet-adapter
-
[11]
Vicon Motion Capture System.https://www.vicon.com/
-
[12]
https://waymo.com
Waymo. https://waymo.com
-
[13]
https://www.movella.com/sensor-modules/xsens-mti- 680-rtk-gnss-ins
XSense MTi-680 RTK GNSS. https://www.movella.com/sensor-modules/xsens-mti- 680-rtk-gnss-ins
-
[14]
IEEE Std 1588-2019 (Revision ofIEEE Std 1588-2008) pp
Ieee standard for a precision clock synchronization protocol for networked measure- ment and control systems. IEEE Std 1588-2019 (Revision ofIEEE Std 1588-2008) pp. 1–499 (2020).https://doi.org/10.1109/IEEESTD.2020.9120376
-
[15]
Technical Specification (TS) 36.213 (2021), version 14.17.0
3GPP: Physical layer procedures. Technical Specification (TS) 36.213 (2021), version 14.17.0
2021
-
[16]
3GPP, E..: Digital cellular telecommunications system (phase 2+) (gsm); universal mobile telecommunications system (umts); lte; 5g; release description; release 14 (3gpp tr 21.914 version 14.0.0) — etsi tr 121 914 v14.0.0. Tech. Rep. TR 121 914 V14.0.0, ETSI (Jun 2018),https://www.etsi.org/deliver/etsi_tr/ 121900_121999/121914/14.00.00_60/tr_121914v140000...
2018
-
[17]
Accessed: 2025-11-13
2025
-
[18]
federal motor vehicle safety standards; v2v communications
Administration, N.H.T.S., et al.: Department of transportation (dot)," federal motor vehicle safety standards; v2v communications", notice of proposed rulemaking (nprm). Tech. rep. (2016) CooperScene17
2016
-
[19]
SAE International (2020)
Automation, C.D.: SAE J3216: Taxonomy and definitions for terms related to cooperative driving automation for on-road motor vehicles. SAE International (2020)
2020
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence14(2), 239–256 (1992).https://doi
Besl, P., McKay, N.D.: A method for registration of 3-d shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence14(2), 239–256 (1992).https://doi. org/10.1109/34.121791
-
[21]
Brettle, F., et al.: Google/draco: a library for compressing and decompressing 3d geometric meshes and point clouds.https://github.com/google/draco (2018), accessed: [Insert date of access, e.g., 2025-11-13]
2018
-
[22]
C-V2X Technical Committee: Sae j3161: LTE vehicle-to-everything (LTE-V2X) deployment profiles and radio parameters for single radio channel multi-service coexistence. Tech. rep., SAE International, 400 Commonwealth Drive, Warrendale, PA, United States (2022)
2022
-
[23]
nuScenes: A multimodal dataset for autonomous driving
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. arXiv:1903.11027 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[24]
Chen, Q., Ma, X., Tang, S., Guo, J., Yang, Q., Fu, S.: F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3d pointclouds.In:Proceedingsofthe4thACM/IEEESymposiumonEdgeComputing. p. 88–100. SEC ’19, Association for Computing Machinery, New York, NY, USA (2019)
2019
-
[25]
In: 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS)
Chen, Q., Tang, S., Yang, Q., Fu, S.: Cooper: Cooperative perception for connected autonomous vehicles based on 3d point clouds. In: 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). pp. 514–524 (2019). https://doi.org/10.1109/ICDCS.2019.00058
-
[26]
https://github.com/open-mmlab/mmdetection3d (2020)
Contributors, M.: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection. https://github.com/open-mmlab/mmdetection3d (2020)
2020
-
[27]
Cui, J., Qiu, H., Chen, D., Stone, P., Zhu, Y.: Coopernaut: End-to-end driving with cooperative perception for networked vehicles. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). p. 17231–17241. IEEE (Jun 2022). https://doi.org/10.1109/cvpr52688.2022.01674 , http://dx.doi.org/ 10.1109/CVPR52688.2022.01674
-
[28]
In: Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems
Cui, J., Tang, C., Holtz, J., Nguyen, J., Allievi, A.G., Qiu, H., Stone, P.: Coopreflect: Towards natural language communication for cooperative autonomous driving via multi-agent learning. In: Proceedings of the 25th International Conference on Autonomous Agents and Multiagent Systems. AAMAS ’26 (2026),https: //arxiv.org/abs/2505.18334, oral Presentation
-
[29]
In: 5th Symposium on Operating Systems Design and Implementation (OSDI 02)
Elson, J., Girod, L., Estrin, D.: Fine-Grained network time synchronization us- ing reference broadcasts. In: 5th Symposium on Operating Systems Design and Implementation (OSDI 02). USENIX Association, Boston, MA (Dec 2002)
2002
-
[30]
International Journal of Robotics Research (IJRR) (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR) (2013)
2013
-
[31]
In: 2011 IEEE 32nd Real-Time Systems Symposium
Hao, T., Zhou, R., Xing, G., Mutka, M.: Wizsync: Exploiting wi-fi infrastructure for clock synchronization in wireless sensor networks. In: 2011 IEEE 32nd Real-Time Systems Symposium. pp. 149–158 (2011)
2011
-
[32]
Advances in neural information processing systems (2022) 18 B
Hu, Y., Fang, S., Lei, Z., Zhong, Y., Chen, S.: Where2comm: Communication- efficient collaborative perception via spatial confidence maps. Advances in neural information processing systems (2022) 18 B. Wu et al
2022
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, Y., Peng, J., Liu, S., Ge, J., Liu, S., Chen, S.: Communication-efficient col- laborative perception via information filling with codebook. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 15481–15490 (2024)
2024
-
[34]
In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Iyer, G., Ram, R.K., Murthy, J.K., Krishna, K.M.: Calibnet: Geometrically super- vised extrinsic calibration using 3d spatial transformer networks. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE (Oct 2018). https://doi.org/10.1109/iros.2018.8593693 , http://dx.doi.org/10. 1109/IROS.2018.8593693
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12697–12705 (2019)
2019
-
[36]
In: 2020 IEEE Intelligent Vehicles Symposium (IV)
Li, E., Wang, S., Li, C., Li, D., Wu, X., Hao, Q.: Sustech points: A portable 3d point cloud interactive annotation platform system. In: 2020 IEEE Intelligent Vehicles Symposium (IV). pp. 1108–1115 (2020).https://doi.org/10.1109/IV47402.2020. 9304562
-
[37]
IEEE Transactions on Intelligent Vehicles8(4), 2650–2660 (Apr 2023).https://doi.org/10.1109/tiv
Li, J., Xu, R., Liu, X., Ma, J., Chi, Z., Ma, J., Yu, H.: Learning for vehicle-to- vehicle cooperative perception under lossy communication. IEEE Transactions on Intelligent Vehicles8(4), 2650–2660 (Apr 2023).https://doi.org/10.1109/tiv. 2023.3260040,http://dx.doi.org/10.1109/TIV.2023.3260040
work page doi:10.1109/tiv 2023
-
[38]
Advances in Neural Information Processing Systems34, 29541–29552 (2021)
Li, Y., Ren, S., Wu, P., Chen, S., Feng, C., Zhang, W.: Learning distilled collabora- tion graph for multi-agent perception. Advances in Neural Information Processing Systems34, 29541–29552 (2021)
2021
-
[39]
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D.L., Han, S.: Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 2774–2781 (2023).https://doi.org/10.1109/ICRA48891.2023.10160968
-
[40]
Maróti, M., Kusy, B., Simon, G., Lédeczi, A.: The flooding time synchronization protocol. p. 39–49. SenSys ’04, Association for Computing Machinery, New York, NY, USA (2004)
2004
-
[41]
In: Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems
Mo, R., Wu, B., Tan, Z., Qiu, H.: See-v2x: C-v2x direct communication dataset: An application-centric approach. In: Proceedings of the 23rd ACM Conference on Embedded Networked Sensor Systems. p. 305–311. Association for Computing Machinery, New York, NY, USA (2025), https://doi.org/10.1145/3715014. 3722077
-
[42]
In: The Fourteenth In- ternational Conference on Learning Representations
Mukhopadhyay, S., Roy-Chowdhury, A., Qiu, H.: Coopertrim: Adaptive data selection for uncertainty-aware cooperative perception. In: The Fourteenth In- ternational Conference on Learning Representations. ICLR ’26 (2026),https: //openreview.net/forum?id=8NgKNuHRiH
2026
-
[43]
National Academics (2020)
National Academies of Sciences, Engineering, and Medicine and others: Business models to facilitate deployment of connected vehicle infrastructure to support automated vehicle operations. National Academics (2020)
2020
-
[44]
In: Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services
Qiu, H., Ahmad, F., Bai, F., Gruteser, M., Govindan, R.: Avr: Augmented vehicular reality. In: Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services. p. 81–95. MobiSys ’18, New York, NY, USA (2018)
2018
-
[45]
In: Proceedings of the 20th Annual International Conference on Mobile Systems, Applications, and Services
Qiu, H., Huang, P., Asavisanu, N., Liu, X., Psounis, K., Govindan, R.: Autocast: Scalable infrastructure-less cooperative perception for distributed collaborative driving. In: Proceedings of the 20th Annual International Conference on Mobile Systems, Applications, and Services. MobiSys ’22 (December 2022) CooperScene19
2022
-
[46]
In: 2018 21st Inter- national Conference on Intelligent Transportation Systems (ITSC)
Rawashdeh, Z.Y., Wang, Z.: Collaborative automated driving: A machine learning- based method to enhance the accuracy of shared information. In: 2018 21st Inter- national Conference on Intelligent Transportation Systems (ITSC). pp. 3961–3966 (2018).https://doi.org/10.1109/ITSC.2018.8569832
-
[47]
In: Proceedings of the 23rd Annual International Conference on Mobile Systems, Applications, and Services
Ren, H., Zhang, W., Shi, S., Zhang, X., Zhang, L., Zhang, Y.: Unisense: Spatial- uncertainty-aware collaborative sensing for autonomous driving. In: Proceedings of the 23rd Annual International Conference on Mobile Systems, Applications, and Services. MobiSys ’25 (2025)
2025
-
[48]
Sekaran, K.C., Geisler, M., Rößle, D., Mohan, A., Cremers, D., Utschick, W., Botsch, M., Huber, W., Schön, T.: Urbaning-v2x: A large-scale multi-vehicle, multi- infrastructure dataset across multiple intersections for cooperative perception (2025), https://arxiv.org/abs/2510.23478
-
[49]
In: 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems
Strobl, K.H., Hirzinger, G.: Optimal hand-eye calibration. In: 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 4647–4653 (2006). https://doi.org/10.1109/IROS.2006.282250
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings ...
2020
-
[51]
IEEE Journal on Robotics and Automation3(4), 323–344 (1987)
Tsai, R.: A versatile camera calibration technique for high-accuracy 3d machine vi- sion metrology using off-the-shelf tv cameras and lenses. IEEE Journal on Robotics and Automation3(4), 323–344 (1987). https://doi.org/10.1109/JRA.1987. 1087109
-
[52]
https://www.transportation.gov/av/3 (2018)
USDOT: Preparing for the future of transportation: Automated vehicles 3.0. https://www.transportation.gov/av/3 (2018)
2018
-
[53]
In: ECCV (2020)
Wang, T.H., Manivasagam, S., Liang, M., Bin, Y., Zeng, W., Tu, J., Urtasun, R.: V2VNet: Vehicle-to-vehicle communication for joint perception and prediction. In: ECCV (2020)
2020
-
[54]
IEEE Robotics and Automation Letters (2025)
Wang, Z., Wang, Y., Wu, Z., Ma, H., Li, Z., Qiu, H., Li, J.: Cmp: Cooperative motion prediction with multi-agent communication. IEEE Robotics and Automation Letters (2025)
2025
-
[55]
Waymo: Fleet response: Lending a helpful hand to Waymo’s autonomously driven vehicles.https://waymo.com/blog/2024/05/fleet-response
2024
-
[56]
In: Na- tional Institute of Standards and Technology (NIST), USA,[Online]: www
Weiss, M.: Telecom requirements for time and frequency synchronization. In: Na- tional Institute of Standards and Technology (NIST), USA,[Online]: www. gps. gov/cgsic/meetings/2012/weiss1. pdf (2012)
2012
-
[57]
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Weng, X., Wang, J., Held, D., Kitani, K.: 3d multi-object tracking: A baseline and new evaluation metrics. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 10359–10366 (2020).https://doi.org/10.1109/ IROS45743.2020.9341164
-
[58]
Wu, B., Li, J., Mo, R., Yue, J., Bharadia, D., Qiu, H.: Demo Abstract: Cooperative Multi-modal Sensing, p. 712–713. Association for Computing Machinery, New York, NY, USA (2025),https://doi.org/10.1145/3715014.3724372
- [59]
-
[60]
In: Conference on Robot Learning (CoRL) (2022) 20 B
Xu, R., Tu, Z., Xiang, H., Shao, W., Zhou, B., Ma, J.: Cobevt: Cooperative bird’s eye view semantic segmentation with sparse transformers. In: Conference on Robot Learning (CoRL) (2022) 20 B. Wu et al
2022
-
[61]
In: The IEEE/CVF Computer Vision and Pattern Recognition Conference (2023)
Xu, R., Xia, X., Li, J., Li, H., Zhang, S., Tu, Z., Meng, Z., Xiang, H., Dong, X., Song, R., Yu, H., Zhou, B., Ma, J.: V2v4real: A real-world large-scale dataset for vehicle-to-vehicle cooperative perception. In: The IEEE/CVF Computer Vision and Pattern Recognition Conference (2023)
2023
-
[62]
In: Proceedings of the European Conference on Computer Vision (2022)
Xu,R.,Xiang,H.,Tu,Z.,Xia,X.,Yang,M.H.,Ma,J.:V2x-vit:Vehicle-to-everything cooperative perception with vision transformer. In: Proceedings of the European Conference on Computer Vision (2022)
2022
-
[63]
In: 2022 International Conference on Robotics and Automation (ICRA)
Xu, R., Xiang, H., Xia, X., Han, X., Li, J., Ma, J.: Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 2583–2589. IEEE (2022)
2022
-
[64]
Sensors18(10), 3337 (2018)
Yan, Y., Mao, Y., Li, B.: Second: Sparsely embedded convolutional detection. Sensors18(10), 3337 (2018)
2018
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, H., Luo, Y., Shu, M., Huo, Y., Yang, Z., Shi, Y., Guo, Z., Li, H., Hu, X., Yuan, J., Nie, Z.: Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21361–21370 (2022)
2022
-
[66]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Yu, H., Yang, W., Ruan, H., Yang, Z., Tang, Y., Gao, X., Hao, X., Shi, Y., Pan, Y., Sun, N., Song, J., Yuan, J., Luo, P., Nie, Z.: V2x-seq: A large-scale sequential dataset for vehicle-infrastructure cooperative perception and forecasting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[67]
In: The 39th Annual AAAI Conference on Artificial Intelligence (2025)
Yu, H., Yang, W., Zhong, J., Yang, Z., Fan, S., Luo, P., Nie, Z.: End-to-end au- tonomous driving through v2x cooperation. In: The 39th Annual AAAI Conference on Artificial Intelligence (2025)
2025
-
[68]
In: 9th Annual Conference on Robot Learning
Yuan, W., Li, J., Yue, J., Shah, D., Karydis, K., Qiu, H.: Bevcalib: Lidar-camera calibration via geometry-guided bird’s-eye view representations. In: 9th Annual Conference on Robot Learning. CoRL ’25 (2025),https://arxiv.org/abs/2506. 02587
2025
-
[69]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Zhang, J., Yang, K., Wang, Y., Wang, H., Sun, P., Song, L.: Ermvp: Communication- efficient and collaboration-robust multi-vehicle perception in challenging environ- ments. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 12575–12584 (2024).https://doi.org/10.1109/CVPR52733. 2024.01195
-
[70]
In: 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat
Zhang, Q., Pless, R.: Extrinsic calibration of a camera and laser range finder (improves camera calibration). In: 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566). vol. 3, pp. 2301–2306 vol.3 (2004).https://doi.org/10.1109/IROS.2004.1389752
-
[71]
In: Proceedings of the 29th Annual International Conference on Mobile Computing and Networking
Zhang, Q., Zhang, X., Zhu, R., Bai, F., Naserian, M., Mao, Z.M.: Robust real-time multi-vehicle collaboration on asynchronous sensors. In: Proceedings of the 29th Annual International Conference on Mobile Computing and Networking. pp. 1–15 (2023)
2023
-
[72]
In: Proceedings of the 27th Annual International Conference on Mobile Computing and Networking
Zhang, X., Zhang, A., Sun, J., Zhu, X., Guo, Y.E., Qian, F., Mao, Z.M.: Emp: edge- assisted multi-vehicle perception. In: Proceedings of the 27th Annual International Conference on Mobile Computing and Networking. p. 545–558. MobiCom ’21, Association for Computing Machinery, New York, NY, USA (2021).https://doi. org/10.1145/3447993.3483242,https://doi.org...
-
[73]
A flexible new technique for camera calibration
Zhang, Z.: A flexible new technique for camera calibration. IEEE Transactions on Pattern Analysis and Machine Intelligence22(11), 1330–1334 (2000).https: //doi.org/10.1109/34.888718 CooperScene21
-
[74]
In: Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems
Zhu, R., Zhu, X., Zhang, A., Zhang, X., Sun, J., Qian, F., Qiu, H., Mao, Z.M., Lee, M.: Boosting collaborative vehicular perception on the edge with vehicle-to- vehicle communication. In: Proceedings of the 22nd ACM Conference on Embedded Networked Sensor Systems. p. 141–154. SenSys ’24 (2024).https://doi.org/10. 1145/3666025.3699328,https://doi.org/10.11...
-
[75]
arXiv preprint arXiv:2403.01316 (2024)
Zimmer, W., Wardana, G.A., Sritharan, S., Zhou, X., Song, R., Knoll, A.: Tumtraf v2x cooperative perception dataset. arXiv preprint arXiv:2403.01316 (2024)
-
[76]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 22 B
Zimmer, W., Wardana, G.A., Sritharan, S., Zhou, X., Song, R., Knoll, A.C.: Tumtraf v2x cooperative perception dataset. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 22 B. Wu et al. Appendix A Limitations and Discussions CooperScenepresents a significant step in real-world cooperative perception, though we acknowledge spe...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.