Localized Conformal Prediction for Image Classification with Vision-Language Models
Pith reviewed 2026-07-01 05:40 UTC · model grok-4.3
The pith
A non-linear transformation of cosine similarities enables localized conformal prediction to produce smaller sets for vision-language model image classification while preserving marginal coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
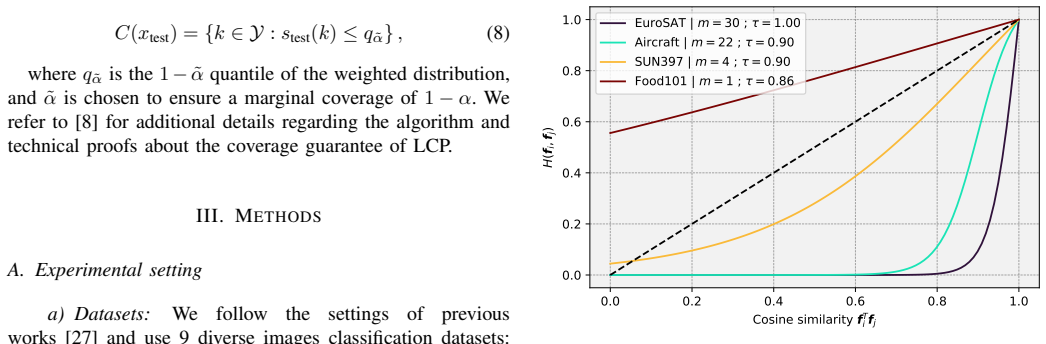
Straightforward cosine similarity between visual features is insufficient to improve localized conformal prediction over non-local baselines on image classification with vision-language models, but a simple non-linear transformation of the similarities conserves marginal coverage guarantees and produces statistically significant reductions in mean set sizes.
What carries the argument
A non-linear transformation applied to cosine similarities between test-time and calibration visual features inside a localized conformal prediction procedure.
If this is right
- Localized conformal sets become feasible for VLM-based image classification once the similarity scores are transformed.
- Mean prediction set size decreases while the marginal coverage guarantee is retained.
- The improvement is statistically significant relative to non-local conformal baselines.
- The approach works with open-source implementations of recent localized conformal algorithms.
Where Pith is reading between the lines
- The same non-linear adjustment might be tested on other embedding-based models where raw cosine similarity also fails to localize effectively.
- If the transform can be made data-dependent without breaking coverage, it could further tighten sets on datasets with clear cluster structure.
- Extending the method to multi-label or hierarchical classification would require checking whether the coverage property survives the change in label space.
Load-bearing premise
The chosen non-linear transformation of cosine similarities leaves the marginal coverage guarantees of the underlying conformal procedure unchanged.
What would settle it
Running the procedure on a fresh calibration set and observing that the empirical coverage on held-out test points falls below the nominal level after the non-linear transform would falsify the coverage claim.
Figures
read the original abstract
Conformal predictions have attracted significant attention in the field of uncertainty quantification, mainly because of their strong marginal coverage guarantees. Full conditional guarantee is not an attainable goal, a well known fact in conformal predictions literature. As a result, several approaches have tried to approximate this behavior by adapting the conformal sets of test-time samples according to their similarity to calibration examples. Although the latter has gained traction and shown impressive performances for regression problems, its application to image classification remains under-explored. We conduct an extensive benchmarking on natural image classification tasks with vision-language models (VLMs), using our open source implementation of a recent localized conformal prediction algorithm. We show that straightforward usage of the cosine similarity between test-time and calibration visual features, an intuitive choice for VLMs, is not sufficient to improve over the non-local baselines. In response, we propose a simple non-linear transformation of the cosine similarities, which conserves marginal coverage guarantees and achieves statistically significant mean set sizes reduction. Code is available at https://github.com/cfuchs2023/lcp-vlm/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks a localized conformal prediction algorithm on natural image classification tasks with vision-language models. It reports that direct use of cosine similarity between test-time and calibration visual features fails to improve over non-local baselines, but proposes a simple non-linear transformation of these similarities that is claimed to conserve marginal coverage guarantees while achieving statistically significant reductions in mean prediction set sizes.
Significance. If the transformation preserves coverage and the reported gains hold under scrutiny, the work would supply a practical, VLM-specific improvement to localized conformal prediction for classification, extending an approach previously explored mainly in regression.
major comments (2)
- [Abstract] Abstract: the central claim that the non-linear transformation 'conserves marginal coverage guarantees' is asserted without derivation or proof that the transformed scores remain exchangeable or that the p-value construction is unchanged. This is load-bearing for the validity guarantee.
- [Methods] Methods (transformation definition): the exact functional form of the non-linear transformation, its application to nonconformity scores or localization weights, and any supporting argument for validity are not supplied, preventing verification that standard conformal theory still applies.
minor comments (2)
- [Abstract] The abstract states 'statistically significant mean set sizes reduction' and 'extensive benchmarking' but supplies no dataset names, VLM architectures, number of trials, or exact p-value thresholds; these details belong in the abstract or early results section.
- The open-source implementation link is provided, but the manuscript should include a brief pseudocode or equation for the transformation to allow readers to reproduce the key step without consulting external code.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The comments correctly identify areas where additional theoretical detail is needed to support our claims. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the non-linear transformation 'conserves marginal coverage guarantees' is asserted without derivation or proof that the transformed scores remain exchangeable or that the p-value construction is unchanged. This is load-bearing for the validity guarantee.
Authors: We agree that the abstract asserts the coverage property without an accompanying derivation. The non-linear transformation is applied exclusively to the cosine similarities that determine localization weights; the nonconformity scores themselves remain unchanged. Because the transformation is a fixed, deterministic function of the observed features, the exchangeability of calibration and test points is preserved and the standard p-value construction is unaffected, so marginal coverage continues to hold. In the revision we will add a short formal argument in the Methods section and update the abstract to reference this justification. revision: yes
-
Referee: [Methods] Methods (transformation definition): the exact functional form of the non-linear transformation, its application to nonconformity scores or localization weights, and any supporting argument for validity are not supplied, preventing verification that standard conformal theory still applies.
Authors: We acknowledge that the precise functional form, its placement in the algorithm, and the validity argument were omitted from the submitted text. We will supply the exact definition of the transformation, state whether it modifies nonconformity scores or localization weights, and include the supporting argument that standard conformal theory still applies in a revised Methods section. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes a non-linear transformation of cosine similarities and asserts that it conserves marginal coverage guarantees of the underlying conformal procedure. This assertion is presented as following from the construction of the localized method (using an existing algorithm implemented by the authors), with performance gains demonstrated via benchmarking on VLM image classification tasks. No equations reduce by construction to fitted inputs or self-defined quantities; no load-bearing self-citations from the authors' prior work are invoked to justify uniqueness or the transformation; and the central empirical claim does not rename a known result or smuggle an ansatz via citation. The derivation remains self-contained against external conformal prediction theory and independent validation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The non-linear transformation of cosine similarities preserves the marginal coverage guarantees of conformal prediction
Reference graph
Works this paper leans on
-
[1]
Uncertainty sets for image classifiers using conformal prediction,
A. Angelopoulos, S. Bates, J. Malik, and M. I. Jordan, “Uncertainty sets for image classifiers using conformal prediction,”arXiv preprint arXiv:2009.14193, 2020
-
[2]
Food-101–mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” inComputer Vision– ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13. Springer, 2014, pp. 446–461
2014
-
[3]
Describing textures in the wild,
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 3606–3613
2014
-
[4]
Conformal predic- tion sets improve human decision making,
J. C. Cresswell, Y . Sui, B. Kumar, and N. V ouitsis, “Conformal predic- tion sets improve human decision making,” inForty-first International Conference on Machine Learning, 2024
2024
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[6]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,
L. Fei-Fei, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” in2004 conference on computer vision and pattern recognition workshop. IEEE, 2004, pp. 178–178
2004
-
[7]
Are foundation models for computer vision good conformal predictors?
L. Fillioux, J. Silva-Rodr ´ıguez, I. B. Ayed, P.-H. Courn `ede, M. Vakalopoulou, S. Christodoulidis, and J. Dolz, “Are foundation models for computer vision good conformal predictors?”arXiv preprint arXiv:2412.06082, 2024
-
[8]
Localized conformal prediction: A generalized inference framework for conformal prediction,
L. Guan, “Localized conformal prediction: A generalized inference framework for conformal prediction,”Biometrika, vol. 110, no. 1, pp. 33–50, 2023
2023
-
[9]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classi- fication,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A novel dataset and deep learning benchmark for land use and land cover classi- fication,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, no. 7, pp. 2217–2226, 2019
2019
-
[10]
3d object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representations for fine-grained categorization,” inProceedings of the IEEE interna- tional conference on computer vision workshops, 2013, pp. 554–561
2013
-
[11]
Convolutional networks for images, speech, and time series,
Y . LeCun, Y . Bengioet al., “Convolutional networks for images, speech, and time series,”The handbook of brain theory and neural networks, vol. 3361, no. 10, p. 1995, 1995
1995
-
[12]
A conformal prediction approach to explore functional data,
J. Lei, A. Rinaldo, and L. Wasserman, “A conformal prediction approach to explore functional data,”Annals of Mathematics and Artificial Intel- ligence, vol. 74, pp. 29–43, 2015
2015
-
[13]
Fine-Grained Visual Classification of Aircraft
S. Maji, E. Rahtu, J. Kannala, M. Blaschko, and A. Vedaldi, “Fine- grained visual classification of aircraft,”arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” in2008 Sixth Indian conference on computer vision, graphics & image processing. IEEE, 2008, pp. 722–729
2008
-
[15]
Cats and dogs,
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. Jawahar, “Cats and dogs,” in2012 IEEE conference on computer vision and pattern recog- nition. IEEE, 2012, pp. 3498–3505
2012
-
[16]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[17]
Classification with valid and adaptive coverage,
Y . Romano, M. Sesia, and E. Candes, “Classification with valid and adaptive coverage,”Advances in Neural Information Processing Systems, vol. 33, pp. 3581–3591, 2020
2020
-
[18]
Least ambiguous set-valued classifiers with bounded error levels,
M. Sadinle, J. Lei, and L. Wasserman, “Least ambiguous set-valued classifiers with bounded error levels,”Journal of the American Statistical Association, vol. 114, no. 525, pp. 223–234, 2019
2019
-
[19]
An analysis of variance test for normality (complete samples),
S. S. Shapiro and M. B. Wilk, “An analysis of variance test for normality (complete samples),”Biometrika, vol. 52, no. 3-4, pp. 591–611, 1965
1965
-
[20]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[21]
Designing decision support sys- tems using counterfactual prediction sets,
E. Straitouri and M. G. Rodriguez, “Designing decision support sys- tems using counterfactual prediction sets,” inForty-first International Conference on Machine Learning, 2024
2024
-
[22]
The probable error of a mean,
Student, “The probable error of a mean,”Biometrika, pp. 1–25, 1908
1908
-
[23]
V ovk, A
V . V ovk, A. Gammerman, and G. Shafer,Algorithmic learning in a random world. Springer, 2005, vol. 29
2005
-
[24]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods,” inBreak- throughs in statistics: Methodology and distribution. Springer, 1992, pp. 196–202
1992
-
[25]
Sun database: Large-scale scene recognition from abbey to zoo,
J. Xiao, J. Hays, K. A. Ehinger, A. Oliva, and A. Torralba, “Sun database: Large-scale scene recognition from abbey to zoo,” in2010 IEEE computer society conference on computer vision and pattern recognition. IEEE, 2010, pp. 3485–3492
2010
-
[26]
Tip-adapter: Training-free adaption of clip for few-shot classification,
R. Zhang, W. Zhang, R. Fang, P. Gao, K. Li, J. Dai, Y . Qiao, and H. Li, “Tip-adapter: Training-free adaption of clip for few-shot classification,” inEuropean conference on computer vision. Springer, 2022, pp. 493– 510
2022
-
[27]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”International Journal of Computer Vision, vol. 130, no. 9, pp. 2337–2348, 2022. TABLE I: Averaged set sizes (see Eq. 9) over 10 folds, forα= 0.1. The best (i.e., lowest) values are highlighted inbold. Statistical significance in the performance difference at the0.05,...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.