A Contextual-Bandit Oversight Game with Two-Sided Informational Asymmetry
Pith reviewed 2026-07-02 19:17 UTC · model grok-4.3
The pith
In a contextual-bandit oversight game with two-sided asymmetry, the gap between the team optimum and the myopic rule equals the price of non-credible oversight communication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
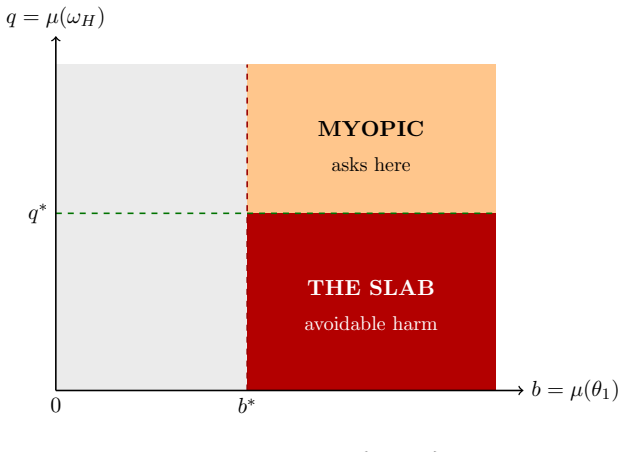
In the contextual-bandit team game with two-sided informational asymmetry, the team optimum and the myopic oversight rule differ by a slab of avoidable harm precisely when the AI knows the proposed action is harmful under the true reward yet the human, trusting her prior, chooses not to oversee; this difference is the price of non-credible oversight communication and contracts dynamically across rounds via passive learning from proposals and active signaling with one-period-lagged responses.
What carries the argument
The contextual-bandit team game with two-sided asymmetric information and the play/ask/trust/oversee interface, which supplies one-shot characterizations of the team optimum and myopic rule whose gap measures non-credible communication cost.
If this is right
- The team optimum achieves strictly lower expected harm than the myopic rule inside the identified slab.
- Repeated rounds reduce the gap through passive updating of the human's belief from observed AI proposals.
- Active signaling by the AI further narrows the gap when oversight responses arrive with a one-period lag.
- The bandit formulation supplies closed-form expressions for the harm slab that remain only conjectural in the full POMDP setting.
Where Pith is reading between the lines
- Explicit confidence signaling by the AI could shrink the avoidable-harm region in deployed systems that inherit the same information structure.
- Human training that accounts for the AI's private knowledge of action quality might compress the gap without altering the interface.
- Extending the lag analysis to multi-period oversight responses could uncover additional equilibrium dynamics not characterized here.
Load-bearing premise
The bandit structure removes physical state transitions and thereby yields exact one-shot characterizations.
What would settle it
A concrete instance or simulation in which the AI privately knows its action is suboptimal under the human's true reward, the human declines oversight on the basis of her prior, and the computed team optimum nevertheless prescribes oversight.
Figures
read the original abstract
We study runtime human oversight of an AI agent when private information runs in both directions: the human privately knows her reward function, while the AI privately knows the quality of the action it proposes. This is the kind of asymmetry that arises naturally when an autonomous robot or software agent has inspected a situation its human supervisor cannot directly assess. Building on Cooperative Inverse Reinforcement Learning (CIRL) and the Oversight Game, we introduce a contextual-bandit team game with two-sided asymmetric information and a play/ask/trust/oversee interface. The bandit structure removes physical state transitions and thereby yields exact one-shot characterizations that would remain conjectural in the full POMDP setting, though the common belief remains a dynamically controlled state across rounds. We give two one-shot characterizations, a team optimum and a behaviorally natural myopic rule, whose gap is a slab of avoidable harm: a region in which the AI privately knows the proposed action is harmful and shutdown would help, yet a myopic human, trusting her prior, declines to oversee. We show this gap is the price of non-credible oversight communication, and give a partial analysis of how it resolves dynamically over repeated rounds through passive learning and active signaling with a one-period-lagged oversight response.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a contextual-bandit oversight game with two-sided informational asymmetry (human privately knows reward function; AI privately knows action quality). It defines a play/ask/trust/oversee interface, derives two one-shot characterizations (team optimum and a behaviorally natural myopic rule), identifies their gap as a 'slab of avoidable harm' attributable to non-credible oversight communication, and provides a partial analysis of dynamic resolution over repeated rounds via passive learning and lagged signaling.
Significance. If the one-shot characterizations hold exactly, the work supplies a clean, analytically tractable model that isolates the cost of non-credible communication in human-AI oversight and quantifies avoidable harm in a bandit setting; this could serve as a foundation for mechanism design in runtime oversight. The explicit contrast between team optimum and myopic rule, together with the dynamic extension, is a concrete contribution to CIRL-style oversight literature.
major comments (2)
- [Abstract and characterizations section] Abstract and the one-shot characterizations section: the claim that the bandit structure 'removes physical state transitions and thereby yields exact one-shot characterizations' is load-bearing for attributing the entire gap to non-credible communication. Because common belief remains a dynamically controlled state, it is unclear whether the value functions for the team optimum and myopic rule are free of continuation values arising from passive learning or one-period-lagged signaling; if they embed multi-round effects, the gap is not isolated to a single-shot non-credibility price.
- [Gap analysis and dynamic resolution] The gap analysis: the identification of the gap as 'the price of non-credible oversight communication' requires an explicit argument that the myopic rule and team optimum differ solely because of the inability to credibly signal in one shot. Without a derivation showing that the characterizations remain exact when future rounds are present (or a clear separation of the one-shot component), the attribution risks conflating static asymmetry with dynamic belief updating.
minor comments (2)
- [Model definition] Notation for the play/ask/trust/oversee interface could be introduced with an explicit payoff matrix or decision tree to make the two-sided asymmetry immediately visible.
- [Dynamic resolution] The partial dynamic analysis would benefit from a short statement of the conditions under which passive learning closes the gap versus when active signaling is required.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the two major comments, which correctly identify the need for greater precision in separating one-shot effects from dynamic belief updating. We respond point by point.
read point-by-point responses
-
Referee: [Abstract and characterizations section] Abstract and the one-shot characterizations section: the claim that the bandit structure 'removes physical state transitions and thereby yields exact one-shot characterizations' is load-bearing for attributing the entire gap to non-credible communication. Because common belief remains a dynamically controlled state, it is unclear whether the value functions for the team optimum and myopic rule are free of continuation values arising from passive learning or one-period-lagged signaling; if they embed multi-round effects, the gap is not isolated to a single-shot non-credibility price.
Authors: We agree that common belief is a dynamically controlled state and that both value functions embed continuation values from passive learning and lagged signaling. The bandit structure nevertheless permits exact characterizations because the only state variable is the common belief; there are no physical transitions whose dynamics would remain conjectural. The 'one-shot characterizations' are the exact per-round policy functions obtained from the Bellman equation evaluated at the current belief. The team optimum internalizes the future value of belief updates produced by oversight, while the myopic rule optimizes only the current-round payoff. We will revise the abstract and characterizations section to state explicitly that continuation values are present and to separate the per-round policy gap from the dynamic component. revision: partial
-
Referee: [Gap analysis and dynamic resolution] The gap analysis: the identification of the gap as 'the price of non-credible oversight communication' requires an explicit argument that the myopic rule and team optimum differ solely because of the inability to credibly signal in one shot. Without a derivation showing that the characterizations remain exact when future rounds are present (or a clear separation of the one-shot component), the attribution risks conflating static asymmetry with dynamic belief updating.
Authors: We will add an explicit decomposition in the gap-analysis section. Let V_team(b) be the team-optimal value function and V_myopic(b) the value under the myopic rule, both solved exactly over the belief-state MDP. The difference V_team(b) - V_myopic(b) equals the expected one-period loss incurred when the AI's private signal about action quality is not credibly transmitted because the human follows the myopic oversight threshold. Because the myopic rule is defined to ignore all future signaling value, this difference isolates the cost of non-credible one-shot communication even though both policies operate inside the same dynamic belief process. The revision will include this short derivation and the corresponding separation of the one-shot component. revision: yes
Circularity Check
No circularity; one-shot characterizations derived from bandit modeling assumption without reduction to inputs.
full rationale
The paper's central results consist of two one-shot characterizations (team optimum and myopic rule) obtained by removing physical state transitions via the contextual-bandit structure. This modeling choice is stated explicitly in the abstract and yields the claimed gap without any fitted parameters, self-citations that bear the load of the uniqueness or derivation, or ansatzes smuggled from prior author work. The dynamic control of common belief is acknowledged but does not enter the one-shot derivations as a hidden input that the gap is then defined to equal. No equations or steps reduce the gap to a tautology or to a prior self-citation chain; the attribution to non-credible communication follows from the model definitions rather than being presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The bandit structure removes physical state transitions and thereby yields exact one-shot characterizations
Reference graph
Works this paper leans on
-
[1]
Hadfield-Menell, S
D. Hadfield-Menell, S. J. Russell, P. Abbeel, and A. Dragan. Cooperative inverse reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 29:3909–3917, 2016
2016
-
[2]
Hadfield-Menell, A
D. Hadfield-Menell, A. Dragan, P. Abbeel, and S. Russell. The off-switch game.International Joint Conference on Artificial Intelligence (IJCAI), 2017
2017
-
[3]
W. Overman and M. Bayati. The oversight game: Learning to cooperatively balance an AI agent’s safety and autonomy.arXiv:2510.26752, 2025 (revised 2026). A Proofs A.1 Proof of Proposition 1 and Corollary 1 General characterization.With simultaneous moves and the credible-ask protocol, a deter- ministic policy is (B, C). Decompose its value against always-p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.