From Signals to Structure: How Memory Architecture Drives Language Emergence in LLM Agents
Pith reviewed 2026-07-02 18:58 UTC · model grok-4.3
The pith
Memory architecture decides whether LLM agents turn signals into stable shared languages, more than channel capacity does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
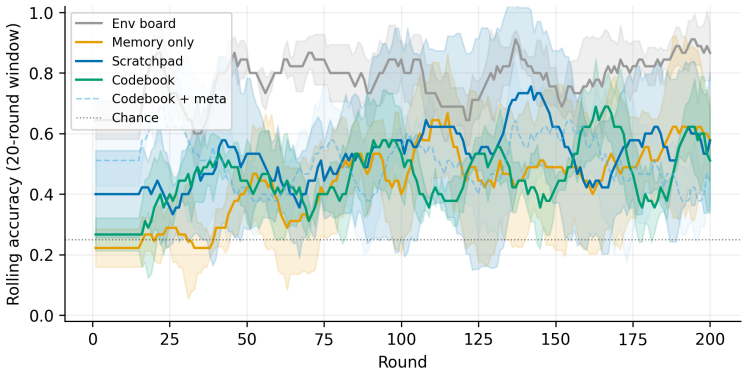
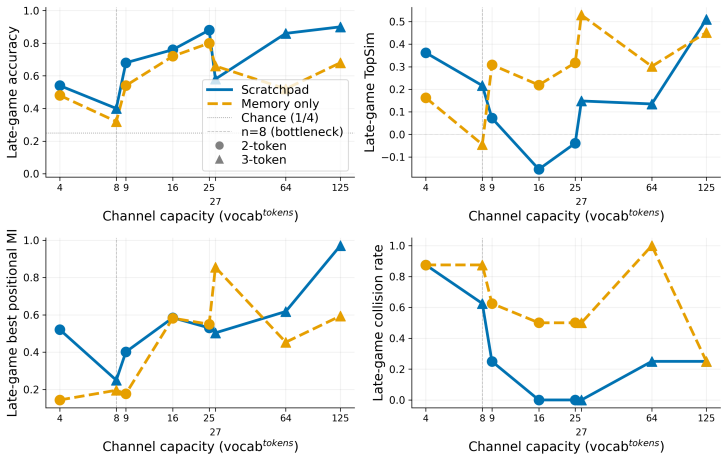
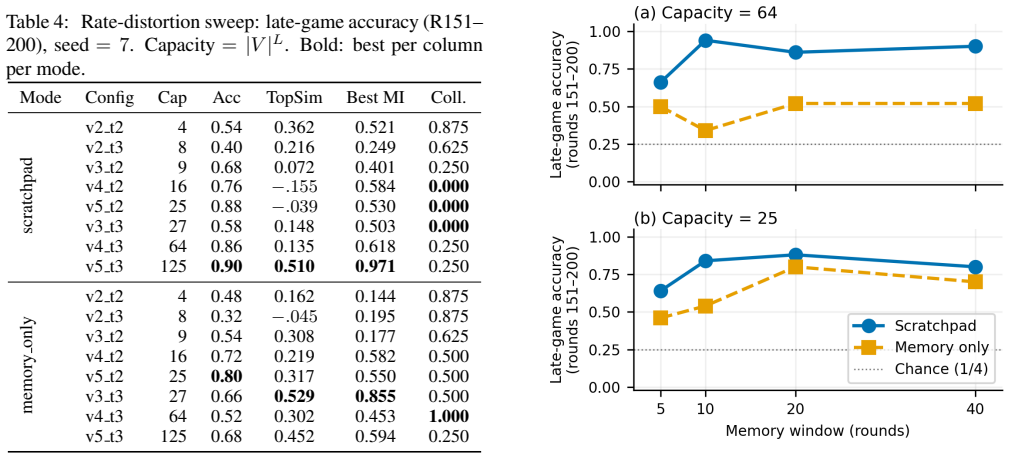
Agents equipped with a persistent private notebook achieve the highest coordination reliability (0.867 ± 0.023 at capacity = 25) by externalizing conventions, whereas stateless agents peak at moderate capacity and then decline as the vocabulary grows. The predicted bottleneck capacity of 8 acts as a fragility point rather than an optimum, and surplus capacity is generally advantageous. Memory architecture therefore determines whether interaction history becomes stable conventions.
What carries the argument
Persistent private notebook memory architecture, which stores learned conventions outside the agents' immediate context and frees them from re-deriving codes each round.
If this is right
- Agents with notebook memory benefit from surplus channel capacity instead of suffering high-capacity collapse.
- Stateless agents reach a performance peak at moderate capacity and then degrade as vocabulary size exceeds context tracking limits.
- An information bottleneck at capacity equal to the number of objects is a fragility point rather than an optimum.
- Channel capacity alone cannot predict coordination success; both memory architecture and capacity must be examined together.
Where Pith is reading between the lines
- External memory may become a necessary design choice when scaling multi-agent language emergence beyond small vocabularies.
- The same memory-capacity interaction could be tested in non-LLM agents to check whether the pattern is architecture-specific or general.
- Human language evolution might similarly depend on external memory aids once signal sets grow large.
Load-bearing premise
Observed differences in coordination success are caused by the choice of memory architecture rather than by other unmeasured differences in how the LLMs process or retain information.
What would settle it
Re-running the same signaling-game trials while holding memory architecture fixed but varying other LLM processing details, and finding that coordination success no longer tracks the original memory-type differences, would falsify the claim.
Figures


read the original abstract
How do two agents invent a shared language from scratch? In a Lewis signaling game, a sender and receiver must coordinate on a code using only their interaction history. We study five memory architectures across varying channel configurations with LLM agents and find that memory architecture matters more than channel capacity. Agents with a persistent private notebook benefit from surplus channel capacity and avoid the high-capacity collapse seen in stateless agents, achieving the most reliable coordination ($0.867 \pm 0.023$ at capacity = 25). Stateless agents peak at moderate capacity and then degrade as the vocabulary grows beyond what a rolling context window can track The notebook externalizes learned conventions, freeing agents from having to re-derive codes each round. An information bottleneck-inspired argument predicts an optimal capacity equal to the number of objects. Instead, the bottleneck (capacity = 8) proves to be a fragility point, and surplus capacity is generally better. We show that channel capacity alone cannot predict coordination; memory architecture determines whether agents turn interaction history into stable conventions, and both dimensions are needed to understand how signals become language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of language emergence in LLM agents playing a Lewis signaling game. It compares five memory architectures across channel capacities and reports that a persistent private notebook achieves the highest coordination success (0.867 ± 0.023 at capacity=25), benefits from surplus capacity, and avoids the high-capacity collapse seen in stateless agents. The authors conclude that memory architecture determines whether agents convert interaction history into stable conventions and that channel capacity alone cannot predict coordination success, contrary to an information-bottleneck prediction that capacity=8 should be optimal.
Significance. If the results hold after addressing potential confounds, the work would provide concrete evidence that externalized memory stabilizes conventions in LLM agents more effectively than capacity scaling, with implications for multi-agent system design. The inclusion of quantitative metrics with error bars is a positive feature of the empirical approach.
major comments (2)
- [Abstract] Abstract: the reported coordination success of 0.867 ± 0.023 lacks any details on the number of trials, the computation of error bars, statistical tests performed, or controls for LLM stochasticity, leaving the central empirical claim only weakly supported.
- [Methods] Methods/Experimental Design: all five architectures are realized inside the same LLM via different prompt structures, yet the manuscript supplies no evidence that prompt length, token overhead, or auxiliary instructions were matched across conditions; this leaves open the possibility that observed gaps (e.g., notebook vs. stateless) arise from effective context-length differences rather than the memory mechanism itself.
minor comments (1)
- [Abstract] The abstract lists five architectures but does not name them explicitly; adding the names would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study of memory architectures in LLM agents. The comments highlight opportunities to strengthen the reporting of results and experimental controls. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported coordination success of 0.867 ± 0.023 lacks any details on the number of trials, the computation of error bars, statistical tests performed, or controls for LLM stochasticity, leaving the central empirical claim only weakly supported.
Authors: We agree that the abstract would be strengthened by including these details. The reported value is the mean across 10 independent trials per condition, each using distinct random seeds to mitigate LLM stochasticity; error bars are standard error of the mean. Statistical tests (paired t-tests with Bonferroni correction) appear in the Methods section. We will revise the abstract to incorporate a concise statement of these elements so the central claim is more fully supported on first reading. revision: yes
-
Referee: [Methods] Methods/Experimental Design: all five architectures are realized inside the same LLM via different prompt structures, yet the manuscript supplies no evidence that prompt length, token overhead, or auxiliary instructions were matched across conditions; this leaves open the possibility that observed gaps (e.g., notebook vs. stateless) arise from effective context-length differences rather than the memory mechanism itself.
Authors: The referee correctly notes that the manuscript provides no explicit verification that prompt lengths and token overhead were matched. This is a legitimate potential confound. In the revision we will add to the Methods section both (i) measured average token counts for the prompt templates of each architecture and (ii) a description of how auxiliary instructions were minimized and standardized. Where lengths differ materially we will either re-run the affected conditions with length-matched prompts or report the measured differences and argue why they do not explain the observed performance gaps. This will allow readers to evaluate whether the memory mechanism itself drives the results. revision: yes
Circularity Check
No circularity: empirical comparison of LLM memory architectures with no derivations or fitted predictions
full rationale
The paper reports experimental results from Lewis signaling games run with LLM agents under five memory architectures and varying channel capacities. The central claim—that memory architecture determines coordination success more than channel capacity—is grounded in observed performance differences (e.g., notebook at 0.867 vs. stateless degradation). No equations, parameter fitting, or first-principles derivations are present. The reference to an 'information bottleneck-inspired argument' is external and contrasted with results rather than used as a load-bearing derivation. No self-citations, ansatzes, or renamings reduce any claim to its inputs by construction. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schulz, E. (2025). Playing repeated games with large lan- guage models.Nature Human Behaviour, 9(7):1380–1390
2025
-
[2]
F., Aiello, L
Ashery, A. F., Aiello, L. M., and Baronchelli, A. (2025). Emergent social conventions and collective bias in LLM populations. Science Advances, 11(20):eadu9368
2025
-
[3]
and Kirby, S
Brighton, H. and Kirby, S. (2006). Understanding linguistic evolu- tion by visualizing the emergence of topographic mappings. Artificial Life, 12:229–242
2006
-
[4]
Brown, T. B. et al. (2020). Language models are few-shot learners. InAdvances in Neural Information Processing Systems
2020
-
[5]
Kirby, S. (2001). Spontaneous evolution of linguistic structure: An iterated learning model of the emergence of regularity and ir- regularity.IEEE Transactions on Evolutionary Computation, 5:102–110
2001
-
[6]
Kirby, S., Cornish, H., and Smith, K. (2008). Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language.Proceedings of the National Academy of Sciences, 105:10681–10686
2008
-
[7]
Kirby, S., Tamariz, M., Cornish, H., and Smith, K. (2015). Com- pression and communication in the cultural evolution of lin- guistic structure.Cognition, 141:87–102
2015
-
[8]
Kouwenhoven, T., Peeperkorn, M., and Verhoef, T. (2025). Search- ing for structure: Investigating emergent communication with large language models. InInternational Conference on Com- putational Linguistics
2025
-
[9]
M., Tuyls, K., and Clark, S
Lazaridou, A., Hermann, K. M., Tuyls, K., and Clark, S. (2018). Emergence of linguistic communication from referential games with symbolic and pixel input. InInternational Con- ference on Learning Representations
2018
-
[10]
Lazaridou, A., Peysakhovich, A., and Baroni, M. (2017). Multi- agent cooperation and the emergence of (natural) language. InInternational Conference on Learning Representations
2017
-
[11]
(1969).Convention: A Philosophical Study
Lewis, D. (1969).Convention: A Philosophical Study. Harvard University Press
1969
-
[12]
and Bowling, M
Li, F. and Bowling, M. (2019). Ease-of-teaching and language structure from emergent communication. InAdvances in Neu- ral Information Processing Systems
2019
-
[13]
Lowe, R., Foerster, J., Boureau, Y ., Pineau, J., and Dauphin, Y . (2019). On the pitfalls of measuring emergent communica- tion. InInternational Conference on Autonomous Agents and Multi-Agent Systems
2019
-
[14]
Miller, G. A. (1956). The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological Review, 63:81–97
1956
-
[15]
Luan, D., Sutton, C., and Odena, A. (2021). Show your work: Scratchpads for intermediate computation with lan- guage models.arXiv preprint arXiv:2112.00114
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [16]
-
[17]
Regier, T., Kemp, C., and Kay, P. (2015). Word meanings across languages support efficient communication. In MacWhin- ney, B. and O’Grady, W., editors,The Handbook of Language Emergence, pages 237–263. Wiley
2015
-
[18]
B., and Kirby, S
Ren, Y ., Guo, S., Labeau, M., Cohen, S. B., and Kirby, S. (2020). Compositional languages emerge in a neural iterated learning model. InInternational Conference on Learning Representa- tions
2020
-
[19]
M., and Cho, K
Resnick, C., Gupta, A., Foerster, J., Dai, A. M., and Cho, K. (2020). Capacity, bandwidth, and compositionality in emer- gent language learning. InInternational Conference on Au- tonomous Agents and Multi-Agent Systems
2020
-
[20]
Shannon, C. E. (1948). A mathematical theory of communication. Bell System Technical Journal, 27:379–423
1948
-
[21]
(2010).Signals: Evolution, Learning, and Information
Skyrms, B. (2010).Signals: Evolution, Learning, and Information. Oxford University Press
2010
- [22]
-
[23]
C., and Bialek, W
Tishby, N., Pereira, F. C., and Bialek, W. (1999). The information bottleneck method. In37th Annual Allerton Conference on
1999
-
[24]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. InAd- vances in Neural Information Processing Systems
2022
-
[25]
Zaslavsky, N., Kemp, C., Regier, T., and Tishby, N. (2018). Effi- cient compression in color naming and its evolution.Pro- ceedings of the National Academy of Sciences, 115:7937– 7942
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.