What's Hidden Matters: Identifying Planning-Critical Occluded Agents using Vision-Language Models
Pith reviewed 2026-07-02 12:17 UTC · model grok-4.3
The pith
Planning KL-divergence ranking of occluded agents lets fine-tuned VLMs identify critical hidden objects more accurately than larger zero-shot models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
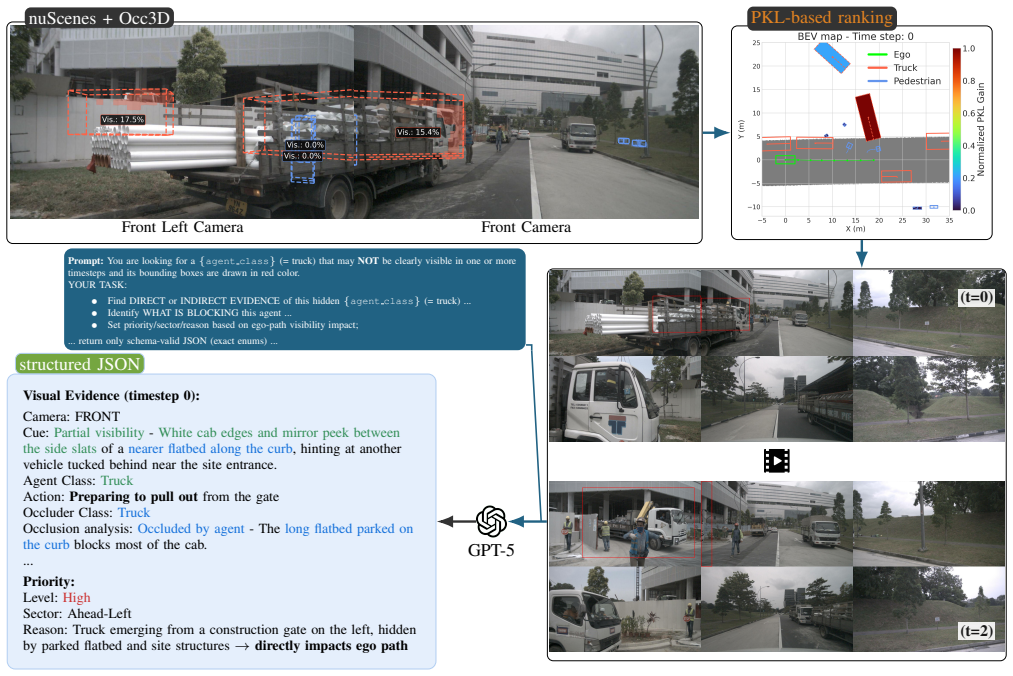
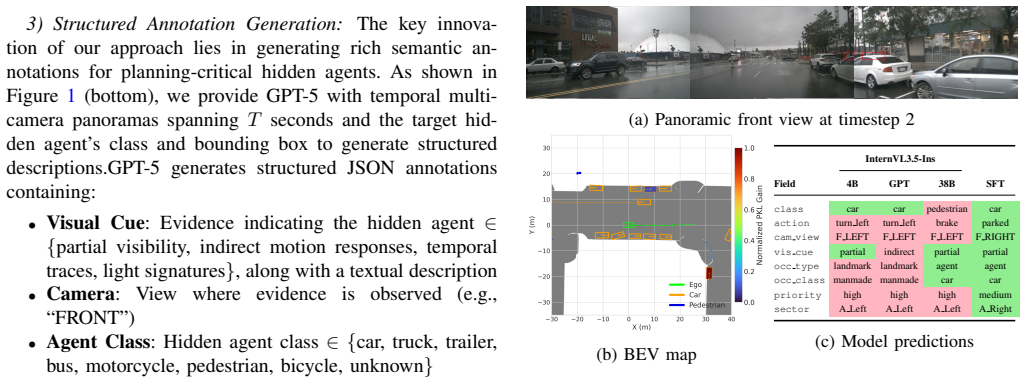
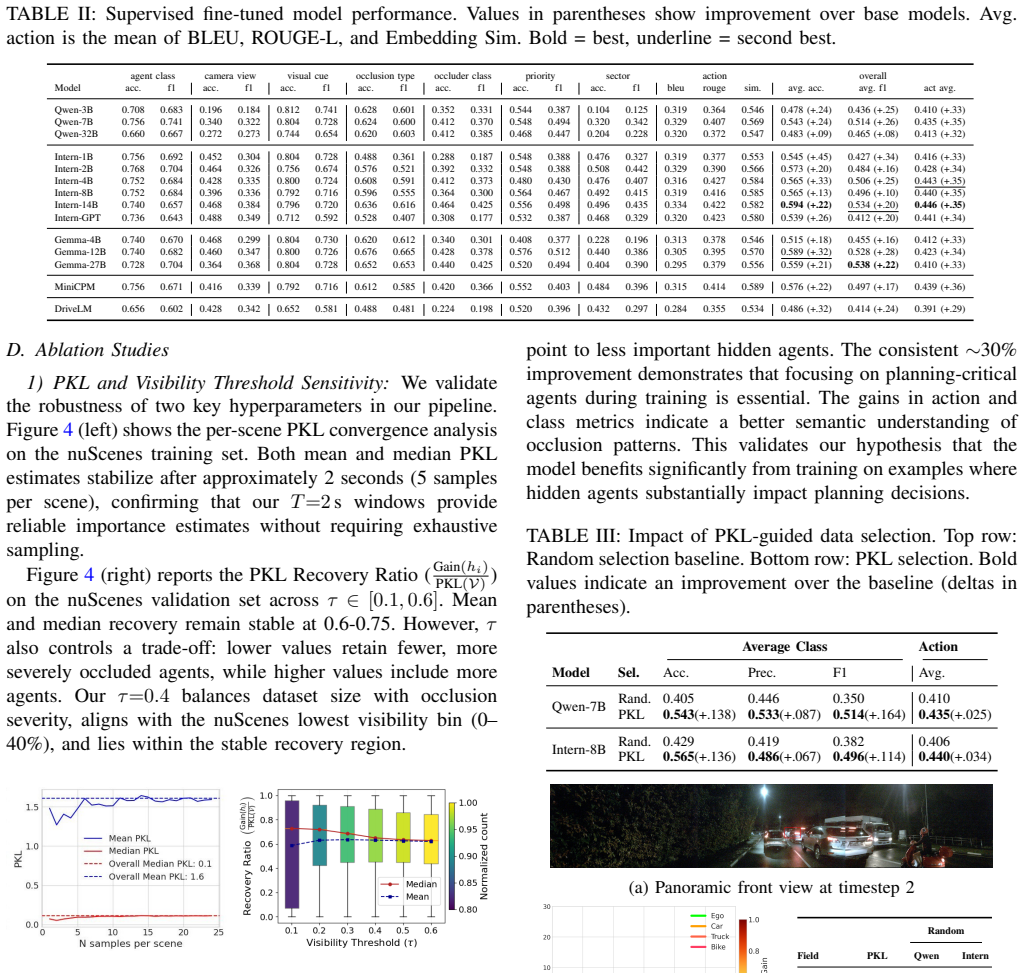
By computing Planning KL-divergence between trajectory distributions with and without each occluded agent, the framework ranks hidden agents according to their influence on the ego-vehicle's plan. An expert VLM then annotates the top-ranked cases with visual evidence and planning reasoning, creating a benchmark dataset. Fine-tuning general and domain-adapted VLMs on this PKL-guided data produces consistent performance gains, including smaller fine-tuned models outperforming larger zero-shot models and a 30 percent lift from the guided selection over random sampling.
What carries the argument
Planning KL-divergence (PKL) metric that quantifies how much each occluded agent changes the distribution of the ego-vehicle's planned trajectories, used to rank and prioritize cases for VLM annotation and fine-tuning.
If this is right
- Fine-tuning on PKL-guided data improves identification performance across all tested VLMs.
- Smaller fine-tuned models can exceed the accuracy of much larger zero-shot models on this task.
- PKL-guided data selection boosts results by approximately 30 percent compared with random sampling.
- The resulting models support more targeted risk assessment instead of uniform defensive responses to all occlusions.
- This constitutes the first systematic method for training VLMs specifically on planning-critical hidden agents.
Where Pith is reading between the lines
- The method could allow autonomous vehicles to maintain higher speeds or smoother paths in low-impact occlusion scenarios without sacrificing safety.
- The same ranking idea might extend to other perception-to-planning gaps, such as identifying critical visible objects or dynamic hazards.
- Applying the framework to additional datasets or real-world logs would test whether the performance pattern holds beyond nuScenes.
- End-to-end integration of the VLM output into the planner could close the loop and produce measurable efficiency gains in trajectory planning.
Load-bearing premise
The Planning KL-divergence metric correctly measures which occluded agents have the largest effect on the ego-vehicle's planner.
What would settle it
Replacing the PKL-based ranking with random selection or an alternative metric and retraining the VLMs yields no performance improvement over the zero-shot or random-data baselines.
Figures


read the original abstract
Autonomous vehicles must safely navigate complex environments where planning-critical agents may be hidden from view. Current approaches often treat all occlusions with uniform conservatism, yielding needlessly defensive driving, or they infer hidden spaces without estimating the impact on the planner. This work bridges the critical gap between perception and planning by enabling Vision-Language Models (VLMs) to identify and reason about the specific hidden agents that are most critical to the ego-vehicle's trajectory. We introduce a novel framework that uses Planning KL-divergence (PKL), an information-theoretic metric, to systematically identify and rank occluded agents based on their impact on the ego vehicle's plan. Using this planning-aware ranking, we employ an expert VLM (GPT-5) to generate rich, structured annotations that capture the visual evidence and reasoning required for this task. We apply this framework to the nuScenes dataset to create a new benchmark focused on high-impact scenarios. We conduct comprehensive experiments on a wide range of general-purpose and domain-adapted VLMs, demonstrating that fine-tuning on our PKL-guided data yields dramatic performance improvements across all models. Notably, our results show that smaller, fine-tuned models significantly outperform their much larger zero-shot counterparts, and that our PKL-guided data selection strategy improves performance by approximately 30\% over random sampling. Our work presents the first systematic approach for training VLMs to focus on planning-critical occlusions, enabling more semantically grounded and efficient risk assessment in autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Planning KL-divergence (PKL) can rank occluded agents by their impact on an ego-vehicle planner; this ranking is used to select scenarios from nuScenes for GPT-5 annotation, producing a benchmark on which fine-tuning VLMs yields large gains (smaller fine-tuned models beat larger zero-shot models; PKL-guided selection beats random sampling by ~30%).
Significance. If PKL is shown to be a valid planner-impact proxy and the reported gains are reproducible with proper controls, the work would provide a concrete method for focusing VLM reasoning on planning-critical rather than merely visible occlusions, which could reduce unnecessary conservatism in AV trajectory planning.
major comments (3)
- [Abstract] Abstract: the central empirical claims (dramatic gains across models, smaller fine-tuned models outperforming larger zero-shot counterparts, and ~30% improvement over random sampling) are stated without any mention of evaluation metrics, baselines, dataset splits, number of runs, error bars, or ablation controls, so the soundness of the performance results cannot be assessed from the provided text.
- [Framework description] Framework description (and abstract): no derivation, correlation study, or ablation is supplied showing that agents ranked high by PKL actually produce larger changes in planner output (trajectory divergence, collision probability, or plan cost) than low-PKL agents when revealed; without this, the data-selection step and the interpretation that the resulting annotations address planning-critical cases rest on an unvalidated assumption.
- [Abstract] Abstract and experimental section: the claim that PKL-guided selection improves performance by approximately 30% over random sampling is presented without the underlying numbers, the precise metric on which the percentage is computed, or a control confirming that the improvement is due to planning relevance rather than visual salience or scene frequency.
minor comments (1)
- [Abstract] The abstract refers to 'GPT-5' without clarifying whether this is a hypothetical or actual model version; this should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each of the major comments below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (dramatic gains across models, smaller fine-tuned models outperforming larger zero-shot counterparts, and ~30% improvement over random sampling) are stated without any mention of evaluation metrics, baselines, dataset splits, number of runs, error bars, or ablation controls, so the soundness of the performance results cannot be assessed from the provided text.
Authors: While the abstract prioritizes brevity, the manuscript body provides full details on the evaluation metrics (F1-score for critical agent identification), baselines (random sampling and various VLM sizes), nuScenes dataset splits, multiple experimental runs with error bars, and ablation studies. We will revise the abstract to include references to the primary metric and experimental controls for better standalone readability. revision: yes
-
Referee: [Framework description] Framework description (and abstract): no derivation, correlation study, or ablation is supplied showing that agents ranked high by PKL actually produce larger changes in planner output (trajectory divergence, collision probability, or plan cost) than low-PKL agents when revealed; without this, the data-selection step and the interpretation that the resulting annotations address planning-critical cases rest on an unvalidated assumption.
Authors: The PKL metric is derived in Section 3 as the KL-divergence between the ego-planner's output distribution in the occluded scenario versus the scenario with the agent unoccluded. This definition directly measures the agent's impact on the plan, providing the theoretical grounding for ranking. The substantial performance gains from PKL-selected data over random selection offer supporting evidence for its relevance. We will add an explicit empirical correlation analysis between PKL values and measured planner output changes in the revised version. revision: partial
-
Referee: [Abstract] Abstract and experimental section: the claim that PKL-guided selection improves performance by approximately 30% over random sampling is presented without the underlying numbers, the precise metric on which the percentage is computed, or a control confirming that the improvement is due to planning relevance rather than visual salience or scene frequency.
Authors: The experimental section details that the 30% figure represents the relative improvement in F1-score when using PKL-guided selection compared to random sampling. Controls for alternative selection criteria are discussed. We will update the abstract to explicitly state the metric used for the percentage calculation and reference the relevant controls in the experiments. revision: yes
Circularity Check
No significant circularity; empirical pipeline remains independent of its inputs
full rationale
The paper defines PKL as an information-theoretic ranking metric, uses it to select training data, generates VLM annotations, fine-tunes models, and evaluates on a held-out benchmark. No equations, self-citations, or fitted parameters are shown to make the reported ~30% gains or model-size comparisons reduce to the same quantities by construction. The central claims rest on external validation against held-out data rather than definitional equivalence or load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Planning KL-divergence accurately quantifies the effect of an occluded agent on the ego planner's output distribution
- domain assumption An expert VLM (GPT-5) can produce high-quality structured annotations of visual evidence for planning-critical occlusions
invented entities (1)
-
Planning KL-divergence (PKL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bevformer: learning bird’s-eye- view representation from lidar-camera via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye- view representation from lidar-camera via spatiotemporal transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[2]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 194–210. Springer, 2020
2020
-
[3]
Jiayu Yang, Enze Xie, Miaomiao Liu, and Jose M. Alvarez. Parametric depth based feature representation learning for object detection and segmentation in bird’s eye view. 7 2023
2023
-
[4]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving, 2023
Xiaoyu Tian, Tao Jiang, Longfei Yun, Yue Wang, Yilun Wang, and Hang Zhao. Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving.arXiv preprint arXiv:2304.14365, 2023
-
[5]
Learning to evaluate perception models using planner-centric metrics
Jonah Philion, Amlan Kar, and Sanja Fidler. Learning to evaluate perception models using planner-centric metrics. 2020 ieee. InCVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14052–14061, 2020
2020
-
[6]
Drive like a human: Rethinking autonomous driving with large language models, 2023
Daocheng Fu, Xin Li, Licheng Wen, Min Dou, Pinlong Cai, Botian Shi, and Yu Qiao. Drive like a human: Rethinking autonomous driving with large language models, 2023
2023
-
[7]
Reasondrive: Efficient visual question answering for autonomous vehicles with reasoning-enhanced small vision-language models
Amirhosein Chahe and Lifeng Zhou. Reasondrive: Efficient visual question answering for autonomous vehicles with reasoning-enhanced small vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3870–3879, 2025
2025
-
[8]
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning.arXiv preprint arXiv:2405.01533, 2024
work page Pith review arXiv 2024
-
[9]
Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, and Anirudha Majum- dar. Robots that ask for help: Uncertainty alignment for large language model planners. 9 2023
2023
-
[10]
Drama: Joint risk localization and captioning in driving
Srikanth Malla, Chiho Choi, Isht Dwivedi, Joon Hee Choi, and Jiachen Li. Drama: Joint risk localization and captioning in driving. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1043–1052, 2023
2023
-
[11]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[12]
Technical report, OpenAI, August 2025
Gpt-5 system card. Technical report, OpenAI, August 2025. Accessed: 2025-09-07
2025
-
[13]
Set-based prediction of traffic participants considering occlusions and traffic rules.IEEE Trans- actions on Intelligent Vehicles, 6(2):249–265, June 2021
Markus Koschi and Matthias Althoff. Set-based prediction of traffic participants considering occlusions and traffic rules.IEEE Trans- actions on Intelligent Vehicles, 6(2):249–265, June 2021. Publisher Copyright: © 2016 IEEE
2021
-
[14]
Orzechowski, Annika Meyer, and Martin Lauer
Piotr F. Orzechowski, Annika Meyer, and Martin Lauer. Tackling occlusions & limited sensor range with set-based safety verification. In2018 21st International Conference on Intelligent Transportation Systems (ITSC), page 1729–1736. IEEE Press, 2018
2018
-
[15]
Occlusion-aware motion planning with visibility maximization via active lateral position adjustment.IEEE Access, 10:57759–57782, 2022
Patiphon Narksri, Hatem Darweesh, Eijiro Takeuchi, Yoshiki Ni- nomiya, and Kazuya Takeda. Occlusion-aware motion planning with visibility maximization via active lateral position adjustment.IEEE Access, 10:57759–57782, 2022
2022
-
[16]
A pomdp maneuver planner for occlusions in urban scenarios
Constantin Hubmann, Nils Quetschlich, Jens Schulz, Julian Bernhard, Daniel Althoff, and Christoph Stiller. A pomdp maneuver planner for occlusions in urban scenarios. In2019 IEEE Intelligent Vehicles Symposium (IV), pages 2172–2179, 2019
2019
-
[17]
Witwicki, Atsuhide Kobashi, Sachin Hagaribommanahalli, and David Ilstrup
Kyle Hollins Wray, Bernard Lange, Arec Jamgochian, Stefan J. Witwicki, Atsuhide Kobashi, Sachin Hagaribommanahalli, and David Ilstrup. Pomdps for safe visibility reasoning in autonomous vehicles. In2021 IEEE International Conference on Intelligence and Safety for Robotics (ISR), pages 191–195, 2021
2021
-
[18]
Mapprior: Bird’s-eye view map layout estimation with generative models
Xiyue Zhu, Vlas Zyrianov, Zhijian Liu, and Shenlong Wang. Mapprior: Bird’s-eye view map layout estimation with generative models. 8 2023
2023
-
[19]
Corrbev: Multi-view 3d object detection by correlation learning with multi-modal prototypes
Ziteng Xue, Mingzhe Guo, Heng Fan, Shihui Zhang, and Zhipeng Zhang. Corrbev: Multi-view 3d object detection by correlation learning with multi-modal prototypes. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27413–27423, 2025
2025
-
[20]
Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving
Tushar Choudhary, Vikrant Dewangan, Shivam Chandhok, Shubham Priyadarshan, Anushka Jain, Arun K Singh, Siddharth Srivastava, Krishna Murthy Jatavallabhula, and K Madhava Krishna. Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16345–16352. IEEE, 2024
2024
-
[21]
Katharina Winter, Mark Azer, and Fabian B Flohr. Bevdriver: Lever- aging bev maps in llms for robust closed-loop driving.arXiv preprint arXiv:2503.03074, 2025
-
[22]
Fuhao Li, Huan Jin, Bin Gao, Liaoyuan Fan, Lihui Jiang, and Long Zeng. Nugrounding: A multi-view 3d visual grounding framework in autonomous driving.arXiv preprint arXiv:2503.22436, 2025
-
[23]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
2024
-
[24]
Embodied understanding of driving scenarios.arXiv preprint arXiv:2403.04593, 2024
Yunsong Zhou, Linyan Huang, Qingwen Bu, Jia Zeng, Tianyu Li, Hang Qiu, Hongzi Zhu, Minyi Guo, Yu Qiao, and Hongyang Li. Embodied understanding of driving scenarios.arXiv preprint arXiv:2403.04593, 2024
-
[25]
Yiluan Guo, Holger Caesar, Oscar Beijbom, Jonah Philion, and Sanja Fidler. The efficacy of neural planning metrics: A meta-analysis of pkl on nuscenes.arXiv preprint arXiv:2010.09350, 2020
-
[26]
Injecting planning-awareness into prediction and detection evaluation
Boris Ivanovic and Marco Pavone. Injecting planning-awareness into prediction and detection evaluation. In2022 IEEE Intelligent Vehicles Symposium (IV), pages 821–828. IEEE, 2022
2022
-
[27]
Sentence-bert: Sentence embed- dings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embed- dings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019
2019
-
[28]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[29]
Swift:a scalable lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024
2024
-
[30]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
arXiv preprint arXiv:2412.076892(3), 8 (2024) 3
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Drivemm: All-in-one large multimodal model for autonomous driving.arXiv preprint arXiv:2412.07689, 2024
-
[35]
Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% performance.Visual Intelligence, 2(1):1–17, 2024
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% performance.Visual Intelligence, 2(1):1–17, 2024
2024
-
[36]
Drivegpt4: In- terpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan- Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: In- terpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024
2024
-
[37]
Mme- realworld: Could your multimodal llm challenge high-resolution real- world scenarios that are difficult for humans?, 2025
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, Liang Wang, Rong Jin, and Tieniu Tan. Mme- realworld: Could your multimodal llm challenge high-resolution real- world scenarios that are difficult for humans?, 2025
2025
-
[38]
Yaozu Wu, Dongyuan Li, Yankai Chen, Renhe Jiang, Henry Peng Zou, Wei-Chieh Huang, Yangning Li, Liancheng Fang, Zhen Wang, and Philip S. Yu. Multi-agent autonomous driving systems with large language models: A survey of recent advances, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.