Learning Gait-Aware Quadruped Locomotion with Temporal Logic Specifications
Pith reviewed 2026-07-02 11:56 UTC · model grok-4.3
The pith
Signal Temporal Logic specifications shape rewards that improve quadruped velocity tracking and training stability over hand-crafted baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
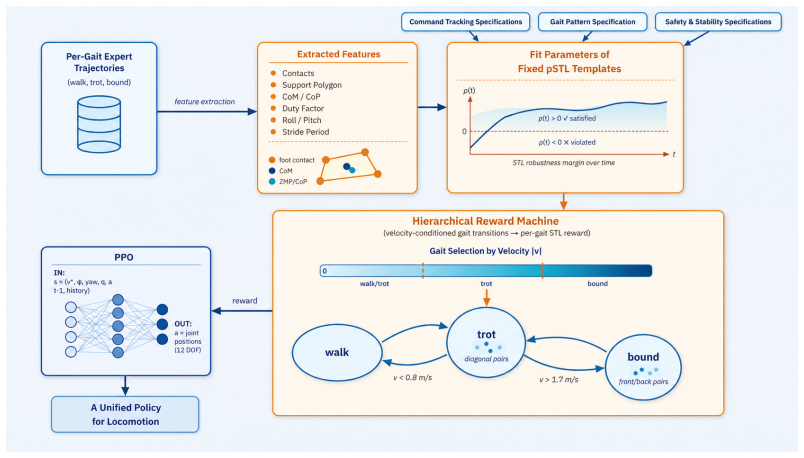
We introduce a framework where distinct gaits are specified using parameterized constraints expressed in Signal Temporal Logic (STL). These include safety bounds, gait synchronization constraints, command tracking, and actuation bounds. From these specifications, we develop a reward shaping mechanism that provides learning agents a dense, continuous reward landscape that encodes desired behavior. We define parametric STL templates for three speed regimes (walking-trot, trot, bound), calibrate their parameters from reference rollouts, and compute rewards from using smooth approximations of STL robustness over the rollouts. The generated rewards can be used to provide shaped gradients compatib
What carries the argument
Parameterized STL templates for three speed regimes that generate dense rewards from smooth robustness approximations for PPO training.
If this is right
- Policies can be trained with explicit control over gait type through adjustments to the STL parameters.
- Reward signals derived from temporal logic provide denser gradients that stabilize PPO training.
- Velocity tracking accuracy improves when rewards encode synchronization and command constraints from STL.
- Domain randomization combines with the shaped rewards to produce policies robust to variations in simulation.
Where Pith is reading between the lines
- The same STL specifications used for reward shaping could later verify whether a trained policy satisfies the original gait requirements.
- Calibrating templates directly from real-robot data rather than simulation rollouts might reduce the sim-to-real gap.
- Similar parametric STL templates could be developed for other periodic robot behaviors such as manipulation or multi-agent coordination.
Load-bearing premise
The parametric STL templates for the three speed regimes, calibrated from reference rollouts, accurately capture desired gait behaviors and produce effective dense rewards.
What would settle it
Training experiments in which STL-shaped rewards produce higher velocity tracking error or less stable learning curves than hand-crafted rewards would falsify the performance advantage.
Figures

read the original abstract
Reinforcement learning (RL) for quadruped locomotion commonly depends on fixed, hand-crafted, and Markovian reward functions that limit both interpretability of learned policies and lack explicit control over gait behaviors. We introduce a framework where distinct gaits are specified using parameterized constraints expressed in Signal Temporal Logic (STL). These include safety bounds, gait synchronization constraints, command tracking, and actuation bounds. From these specifications, we develop a reward shaping mechanism that provides learning agents a dense, continuous reward landscape that encodes desired behavior. We define parametric STL templates for three speed regimes (walking-trot, trot, bound), calibrate their parameters from reference rollouts, and compute rewards from using smooth approximations of STL robustness over the rollouts. The generated rewards can be used to provide shaped gradients compatible with Proximal Policy Optimization (PPO). We instantiate the approach on Google's Barkour quadruped robot in MuJoCo XLA (MJX). We use parallelization within the simulator to improve training speeds and use domain randomization to robustify learned policies. We show that compared to a baseline of hand-crafted rewards, the STL-shaped rewards yield tighter velocity tracking and more stable training. Videos can be found on our project website: https://stl-locomotion.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for quadruped locomotion in RL that uses parameterized Signal Temporal Logic (STL) templates to encode gait behaviors (safety bounds, synchronization, command tracking) across three speed regimes. Parameters are calibrated from reference rollouts; smooth robustness approximations then produce dense rewards for PPO. The method is instantiated on the Barkour robot in MuJoCo with domain randomization and parallel simulation; the central empirical claim is that STL-shaped rewards produce tighter velocity tracking and more stable training than a hand-crafted reward baseline.
Significance. If the comparison is shown to be non-circular and the quantitative gains are reproducible, the work would demonstrate a practical route to injecting interpretable, temporally structured specifications into reward shaping for legged RL. This could improve policy transparency and gait control without sacrificing sample efficiency, a useful contribution to the intersection of formal methods and robotics.
major comments (2)
- [method section on parametric templates] Calibration procedure for STL templates (method section on parametric templates for walking-trot/trot/bound): the paper states that parameters are fitted from reference rollouts, yet provides no description of how those rollouts were generated (e.g., whether they came from policies already optimized for the target velocities or from the same simulator setup used in the experiments). Without an explicit statement that the reference data are independent of both the STL and hand-crafted training loops, the reported advantage in velocity tracking cannot be unambiguously attributed to the temporal-logic structure rather than to the calibration step itself.
- [results section] Experimental comparison (results section reporting velocity tracking and training stability): the abstract and claim assert tighter tracking and more stable PPO training, but the provided text supplies no numerical values, standard deviations, number of seeds, or statistical tests. A load-bearing claim of superiority therefore rests on unreported quantitative evidence; the manuscript must include these metrics (e.g., mean tracking error per regime, success rate, or learning curves) to allow verification.
minor comments (2)
- [abstract] The abstract mentions "Videos can be found on our project website" but the manuscript does not include a persistent link or DOI; a stable reference should be added.
- [reward shaping subsection] Notation for the smooth robustness approximation is introduced without an explicit equation number or reference to the approximation formula used (e.g., the specific sigmoid or log-sum-exp form); adding an equation label would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and provide supporting evidence.
read point-by-point responses
-
Referee: [method section on parametric templates] Calibration procedure for STL templates (method section on parametric templates for walking-trot/trot/bound): the paper states that parameters are fitted from reference rollouts, yet provides no description of how those rollouts were generated (e.g., whether they came from policies already optimized for the target velocities or from the same simulator setup used in the experiments). Without an explicit statement that the reference data are independent of both the STL and hand-crafted training loops, the reported advantage in velocity tracking cannot be unambiguously attributed to the temporal-logic structure rather than to the calibration step itself.
Authors: We agree that the manuscript does not explicitly describe how the reference rollouts were generated. We will revise the method section on parametric templates to state that these rollouts were produced by a preliminary policy trained independently using only a basic velocity-tracking reward (without STL or the hand-crafted baseline) in the same MuJoCo Barkour environment with domain randomization. This addition will establish the independence of the calibration data from the reported training loops. revision: yes
-
Referee: [results section] Experimental comparison (results section reporting velocity tracking and training stability): the abstract and claim assert tighter tracking and more stable PPO training, but the provided text supplies no numerical values, standard deviations, number of seeds, or statistical tests. A load-bearing claim of superiority therefore rests on unreported quantitative evidence; the manuscript must include these metrics (e.g., mean tracking error per regime, success rate, or learning curves) to allow verification.
Authors: We acknowledge that the manuscript reports only qualitative improvements without the requested quantitative details. We will revise the results section to include mean velocity tracking errors per regime with standard deviations, the number of random seeds used, success rates, and learning curve comparisons, along with any applicable statistical tests. This will substantiate the claims of tighter tracking and more stable training. revision: yes
Circularity Check
No significant circularity
full rationale
The paper explicitly states it defines parametric STL templates for three speed regimes, calibrates their parameters from reference rollouts, and computes rewards via smooth robustness approximations for use with PPO. It then reports an empirical comparison showing STL-shaped rewards yield tighter velocity tracking and more stable training than a hand-crafted baseline. This calibration step is presented as part of the method rather than a hidden fit renamed as a prediction, and the performance claim rests on independent training outcomes rather than reducing by construction to the reference data. No self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The approach is self-contained against the stated external baseline.
Axiom & Free-Parameter Ledger
free parameters (1)
- STL template parameters for gaits =
calibrated from reference rollouts
axioms (1)
- domain assumption Signal Temporal Logic can express gait behaviors using parameterized constraints for safety, synchronization, tracking, and actuation
Reference graph
Works this paper leans on
-
[1]
Raibert, K
M. Raibert, K. Blankespoor, G. Nelson, and R. Playter. Bigdog, the rough-terrain quadruped robot.IFAC Proceedings Volumes, 41(2):10822–10825, 2008
2008
-
[2]
B. Katz, J. Di Carlo, and S. Kim. Mini cheetah: A platform for pushing the limits of dynamic quadruped control. In2019 international conference on robotics and automation (ICRA), pages 6295–6301. IEEE, 2019
2019
- [3]
-
[4]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomo- tion over challenging terrain.Science robotics, 5(47):eabc5986, 2020
2020
-
[5]
Z. Xie, X. Da, M. Van de Panne, B. Babich, and A. Garg. Dynamics randomization revisited: A case study for quadrupedal locomotion. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 4955–4961. IEEE, 2021
2021
-
[6]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InConference on robot learning, pages 403–415. PMLR, 2023
2023
- [7]
-
[8]
Nguyen, M
Q. Nguyen, M. J. Powell, B. Katz, J. Di Carlo, and S. Kim. Optimized jumping on the mit cheetah 3 robot. In2019 International Conference on Robotics and Automation (ICRA), pages 7448–7454. IEEE, 2019
2019
-
[9]
Di Carlo, P
J. Di Carlo, P. M. Wensing, B. Katz, G. Bledt, and S. Kim. Dynamic locomotion in the mit cheetah 3 through convex model-predictive control. In2018 IEEE/RSJ international confer- ence on intelligent robots and systems (IROS), pages 1–9. IEEE, 2018
2018
-
[10]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[11]
Hutter, C
M. Hutter, C. Gehring, D. Jud, A. Lauber, C. D. Bellicoso, V . Tsounis, J. Hwangbo, K. Bodie, P. Fankhauser, M. Bloesch, et al. Anymal-a highly mobile and dynamic quadrupedal robot. In2016 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 38–44. IEEE, 2016
2016
-
[12]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
K. Caluwaerts, A. Iscen, J. C. Kew, W. Yu, T. Zhang, D. Freeman, K.-H. Lee, L. Lee, S. Sal- iceti, V . Zhuang, et al. Barkour: Benchmarking animal-level agility with quadruped robots. arXiv preprint arXiv:2305.14654, 2023
-
[14]
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke. Sim- to-real: Learning agile locomotion for quadruped robots.arXiv preprint arXiv:1804.10332, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Maler and D
O. Maler and D. Nickovic. Monitoring temporal properties of continuous signals. InInterna- tional symposium on formal techniques in real-time and fault-tolerant systems, pages 152–166. Springer, 2004. 9
2004
-
[16]
X. Ding, S. L. Smith, C. Belta, and D. Rus. Optimal control of markov decision processes with linear temporal logic constraints.IEEE Transactions on Automatic Control, 59(5):1244–1257, 2014
2014
-
[18]
Aksaray, A
D. Aksaray, A. Jones, Z. Kong, M. Schwager, and C. Belta. Q-learning for robust satisfaction of signal temporal logic specifications. In2016 IEEE 55th Conference on Decision and Control (CDC), pages 6565–6570. IEEE, 2016
2016
-
[19]
Kapinski, X
J. Kapinski, X. Jin, J. Deshmukh, A. Donze, T. Yamaguchi, H. Ito, T. Kaga, S. Kobuna, and S. Seshia. St-lib: A library for specifying and classifying model behaviors. Technical report, SAE Technical Paper, 2016
2016
-
[20]
J. V . Deshmukh, A. Donz ´e, S. Ghosh, X. Jin, G. Juniwal, and S. A. Seshia. Robust online monitoring of signal temporal logic.Formal Methods in System Design, 51(1):5–30, 2017
2017
-
[21]
Camacho, R
A. Camacho, R. T. Icarte, T. Q. Klassen, R. A. Valenzano, and S. A. McIlraith. Ltl and be- yond: Formal languages for reward function specification in reinforcement learning. InIJCAI, volume 19, pages 6065–6073, 2019
2019
-
[22]
Balakrishnan and J
A. Balakrishnan and J. V . Deshmukh. Structured reward shaping using signal temporal logic specifications. in 2019 ieee/rsj iros, 3481–3486, 2019
2019
- [23]
-
[24]
Jiang, S
Y . Jiang, S. Bharadwaj, B. Wu, R. Shah, U. Topcu, and P. Stone. Temporal-logic-based reward shaping for continuing reinforcement learning tasks. InProceedings of the AAAI Conference on artificial Intelligence, volume 35, pages 7995–8003, 2021
2021
-
[25]
Hasanbeig, D
M. Hasanbeig, D. Kroening, and A. Abate. Deep reinforcement learning with temporal logics. InInternational Conference on Formal Modeling and Analysis of Timed Systems, pages 1–22. Springer, 2020
2020
-
[26]
M. Wen, R. Ehlers, and U. Topcu. Correct-by-synthesis reinforcement learning with tempo- ral logic constraints. In2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4983–4990. IEEE, 2015
2015
-
[27]
R. T. Icarte, T. Q. Klassen, R. Valenzano, and S. A. McIlraith. Reward machines: Exploiting reward function structure in reinforcement learning.Journal of Artificial Intelligence Research, 73:173–208, 2022
2022
-
[28]
Dayan and B
P. Dayan and B. W. Balleine. Reward, motivation, and reinforcement learning.Neuron, 36(2): 285–298, 2002
2002
-
[29]
Eschmann
J. Eschmann. Reward function design in reinforcement learning.Reinforcement learning algorithms: Analysis and Applications, pages 25–33, 2021
2021
- [30]
-
[31]
Kim, Y .-H
G. Kim, Y .-H. Lee, and H.-W. Park. A learning framework for diverse legged robot locomotion using barrier-based style rewards. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10004–10010. IEEE, 2025
2025
-
[32]
J. Fu, K. Luo, and S. Levine. Learning robust rewards with adversarial inverse reinforcement learning.arXiv preprint arXiv:1710.11248, 2017. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
A. Y . Ng, S. Russell, et al. Algorithms for inverse reinforcement learning. InIcml, volume 1, page 2, 2000
2000
-
[34]
Arora and P
S. Arora and P. Doshi. A survey of inverse reinforcement learning: Challenges, methods and progress.Artificial Intelligence, 297:103500, 2021
2021
-
[35]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[36]
D. Youm, H. Jung, H. Kim, J. Hwangbo, H.-W. Park, and S. Ha. Imitating and finetuning model predictive control for robust and symmetric quadrupedal locomotion.IEEE Robotics and Automation Letters, 8(11):7799–7806, 2023
2023
-
[37]
T. Li, J. Won, J. Cho, S. Ha, and A. Rai. Fastmimic: Model-based motion imitation for agile, diverse and generalizable quadrupedal locomotion.Robotics, 12(3):90, 2023
2023
-
[38]
H.-C. Liao. A survey of reinforcement learning with temporal logic rewards. 2020
2020
-
[39]
Li, C.-I
X. Li, C.-I. Vasile, and C. Belta. Reinforcement learning with temporal logic rewards. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3834–
- [40]
-
[41]
Puranic, J
A. Puranic, J. Deshmukh, and S. Nikolaidis. Learning from demonstrations using signal tem- poral logic. InConference on Robot Learning, pages 2228–2242. PMLR, 2021
2021
-
[42]
S. Feng, X. Xinjilefu, W. Huang, and C. G. Atkeson. 3d walking based on online optimization. In2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids), pages 21–27. IEEE, 2013
2013
-
[43]
Y . Zhao, U. Topcu, and L. Sentis. High-level planner synthesis for whole-body locomotion in unstructured environments. In2016 IEEE 55th Conference on Decision and Control (CDC), pages 6557–6564. IEEE, 2016
2016
-
[44]
Audren, A
H. Audren, A. Kheddar, and P. Gergondet. Stability polygons reshaping and morphing for smooth multi-contact transitions and force control of humanoid robots. In2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), pages 1037–1044. IEEE, 2016
2016
-
[45]
Z. Gu, R. Guo, W. Yates, Y . Chen, Y . Zhao, and Y . Zhao. Walking-by-logic: Signal temporal logic-guided model predictive control for bipedal locomotion resilient to external perturba- tions. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 1121–1127. IEEE, 2024
2024
-
[46]
Z. Gu, Y . Zhao, Y . Chen, R. Guo, J. K. Leestma, G. S. Sawicki, and Y . Zhao. Robust- locomotion-by-logic: Perturbation-resilient bipedal locomotion via signal temporal logic guided model predictive control.IEEE Transactions on Robotics, 2025
2025
-
[47]
Humphreys and C
J. Humphreys and C. Zhou. Learning to adapt through bio-inspired gait strategies for versatile quadruped locomotion.Nature Machine Intelligence, 7(7):1141–1153, 2025
2025
-
[48]
DeFazio, Y
D. DeFazio, Y . Hayamizu, and S. Zhang. Learning quadruped locomotion policies using logi- cal rules. InProceedings of the International Conference on Automated Planning and Schedul- ing, volume 34, pages 142–150, 2024
2024
-
[49]
Sch ¨oner, W
G. Sch ¨oner, W. Y . Jiang, and J. S. Kelso. A synergetic theory of quadrupedal gaits and gait transitions.Journal of theoretical Biology, 142(3):359–391, 1990. 11
1990
-
[50]
S. M. Danner, S. D. Wilshin, N. A. Shevtsova, and I. A. Rybak. Central control of interlimb coordination and speed-dependent gait expression in quadrupeds.The Journal of physiology, 594(23):6947–6967, 2016
2016
-
[51]
Righetti and A
L. Righetti and A. J. Ijspeert. Pattern generators with sensory feedback for the control of quadruped locomotion. In2008 IEEE International Conference on Robotics and Automation, pages 819–824. IEEE, 2008
2008
-
[52]
C. Liu, Y . Chen, J. Zhang, and Q. Chen. Cpg driven locomotion control of quadruped robot. In2009 IEEE International Conference on Systems, Man and Cybernetics, pages 2368–2373. IEEE, 2009
2009
-
[53]
Humphreys, J
J. Humphreys, J. Li, Y . Wan, H. Gao, and C. Zhou. Bio-inspired gait transitions for quadruped locomotion.IEEE Robotics and Automation Letters, 8(10):6131–6138, 2023
2023
-
[54]
Neunert, F
M. Neunert, F. Farshidian, A. W. Winkler, and J. Buchli. Trajectory optimization through contacts and automatic gait discovery for quadrupeds.IEEE Robotics and Automation Letters, 2(3):1502–1509, 2017
2017
-
[55]
H. Sun, J. Yang, Y . Jia, and C. Wang. Online hierarchical planning for multicontact locomotion control of quadruped robots.IEEE/ASME Transactions on Mechatronics, 30(3):1718–1728, 2024
2024
-
[56]
K. Liu, L. Dong, X. Tan, W. Zhang, and L. Zhu. Optimization-based flocking control and mpc-based gait synchronization control for multiple quadruped robots.IEEE Robotics and Automation Letters, 9(2):1929–1936, 2024
1929
-
[57]
Bellegarda, M
G. Bellegarda, M. Shafiee, and A. Ijspeert. Allgaits: Learning all quadruped gaits and tran- sitions. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15929–15935. IEEE, 2025
2025
-
[58]
Y . H. Lee, D. T. Tran, J.-h. Hyun, L. T. Phan, I. M. Koo, S. U. Yang, and H. R. Choi. A gait transition algorithm based on hybrid walking gait for a quadruped walking robot.Intelligent Service Robotics, 8(4):185–200, 2015
2015
-
[59]
B. Hu, S. Shao, Z. Cao, Q. Xiao, Q. Li, and C. Ma. Learning a faster locomotion gait for a quadruped robot with model-free deep reinforcement learning. In2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), pages 1097–1102. IEEE, 2019
2019
-
[60]
Tsounis, M
V . Tsounis, M. Alge, J. Lee, F. Farshidian, and M. Hutter. Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning.IEEE Robotics and Automation Letters, 5(2):3699–3706, 2020
2020
-
[61]
Y . Shao, Y . Jin, X. Liu, W. He, H. Wang, and W. Yang. Learning free gait transition for quadruped robots via phase-guided controller.IEEE Robotics and Automation Letters, 7(2): 1230–1237, 2021
2021
-
[62]
S. Xu, L. Zhu, and C. P. Ho. Learning efficient and robust multi-modal quadruped locomotion: A hierarchical approach. In2022 international conference on robotics and automation (ICRA), pages 4649–4655. IEEE, 2022
2022
-
[63]
L. Wei, Y . Li, Y . Ai, Y . Wu, H. Xu, W. Wang, and G. Hu. Learning multiple-gait quadrupedal locomotion via hierarchical reinforcement learning.International Journal of Precision Engi- neering and Manufacturing, 24(9):1599–1613, 2023
2023
-
[64]
Y . Yang, T. Zhang, E. Coumans, J. Tan, and B. Boots. Fast and efficient locomotion via learned gait transitions. InConference on robot learning, pages 773–783. PMLR, 2022
2022
- [65]
- [66]
-
[67]
Shafiee, G
M. Shafiee, G. Bellegarda, and A. Ijspeert. Manyquadrupeds: Learning a single locomotion policy for diverse quadruped robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 3471–3477. IEEE, 2024
2024
- [68]
-
[69]
R. M. Alexander and A. Jayes. A dynamic similarity hypothesis for the gaits of quadrupedal mammals.Journal of zoology, 201(1):135–152, 1983
1983
-
[70]
Donz ´e and O
A. Donz ´e and O. Maler. Robust satisfaction of temporal logic over real-valued signals. In International conference on formal modeling and analysis of timed systems, pages 92–106. Springer, 2010
2010
-
[71]
G. E. Fainekos and G. J. Pappas. Robustness of temporal logic specifications for continuous- time signals.Theoretical Computer Science, 410(42):4262–4291, 2009
2009
-
[72]
Asarin, A
E. Asarin, A. Donz ´e, O. Maler, and D. Nickovic. Parametric identification of temporal proper- ties. InInternational Conference on Runtime Verification, pages 147–160. Springer, 2011
2011
-
[73]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
Kohl and P
N. Kohl and P. Stone. Policy gradient reinforcement learning for fast quadrupedal locomotion. InIEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, volume 3, pages 2619–2624. IEEE, 2004
2004
-
[75]
Schulman, S
J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[76]
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
1928
-
[77]
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem. Brax–a differen- tiable physics engine for large scale rigid body simulation.arXiv preprint arXiv:2106.13281, 2021. A Appendix A.1 STL Specifications We additionally evaluated the two rules described below; however, given the constraints already established in the main text, they d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.