ELDR: Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
Pith reviewed 2026-07-02 06:38 UTC · model grok-4.3
The pith
Routing decode requests by predicted expert activations cuts median TPOT 5.9-13.9% in MoE PD-disaggregated serving while keeping outputs identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
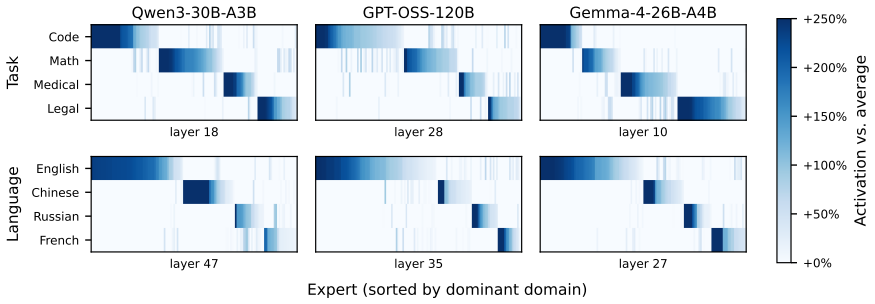
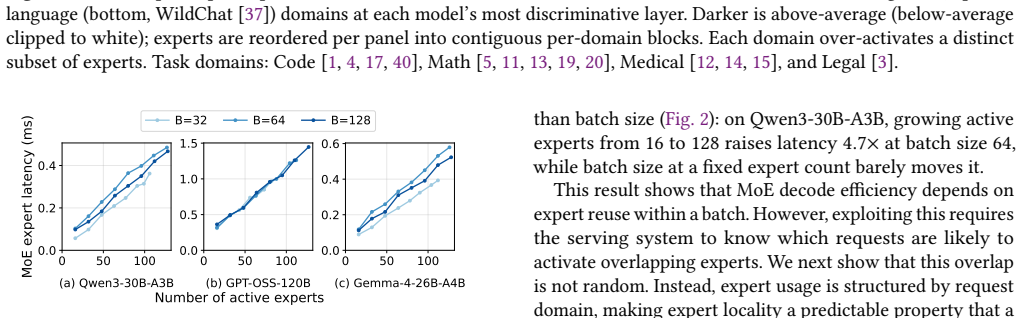
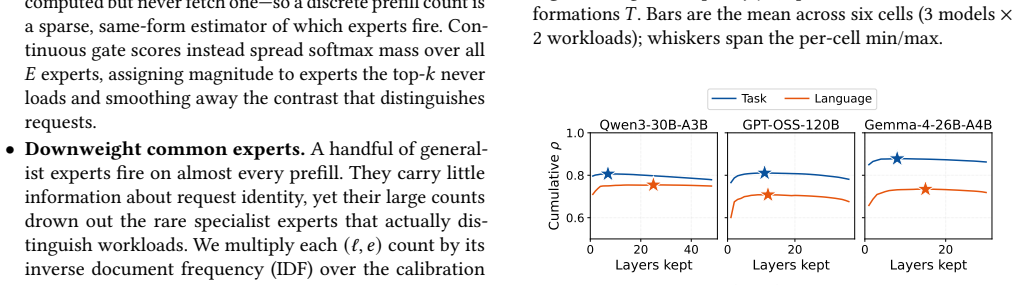
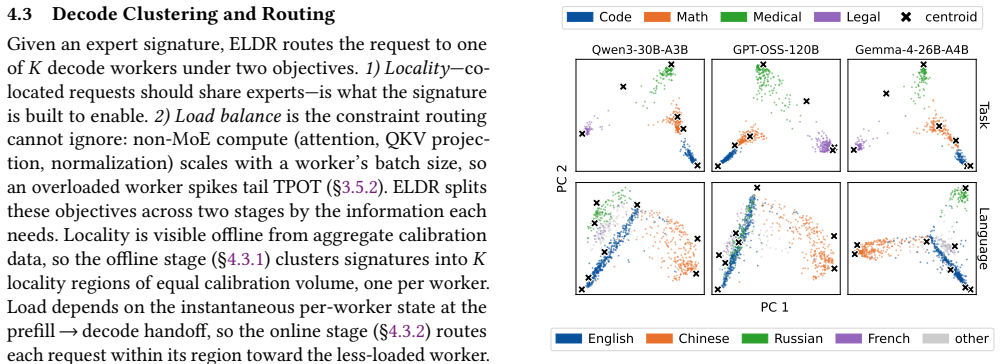
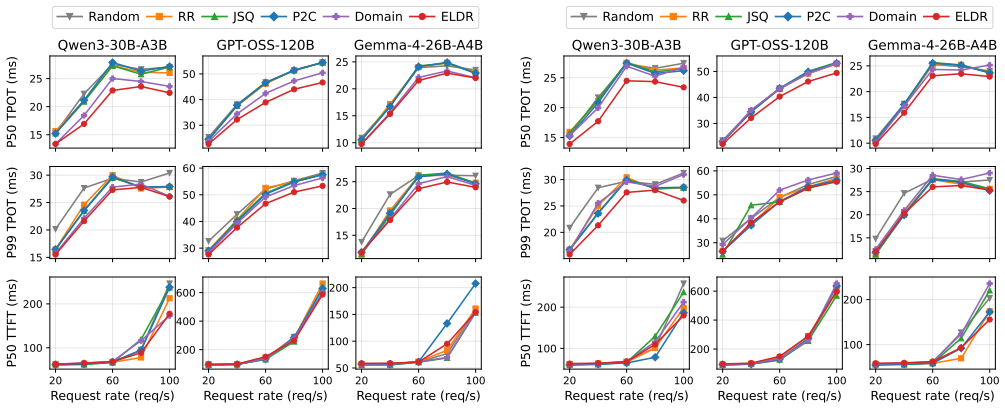
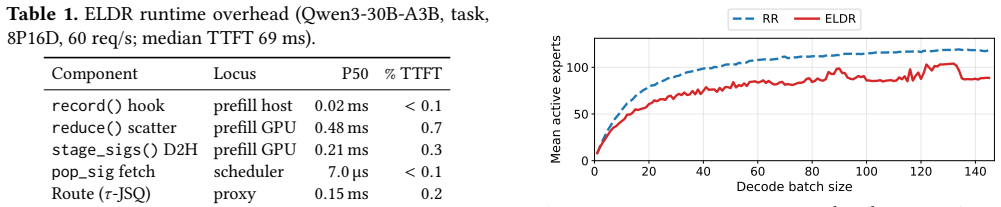
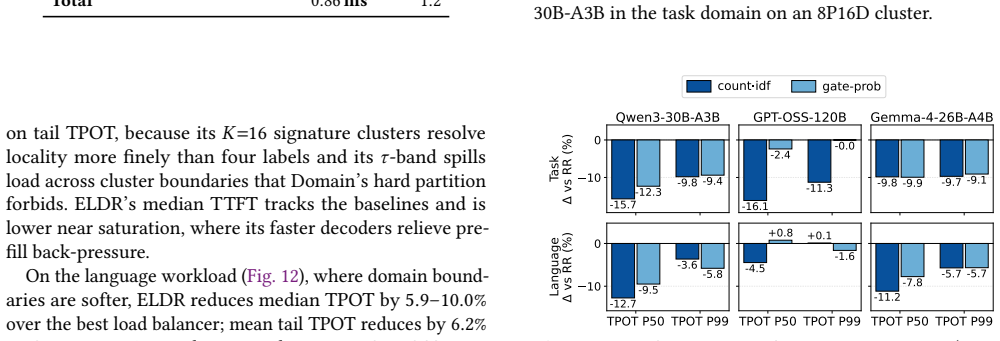
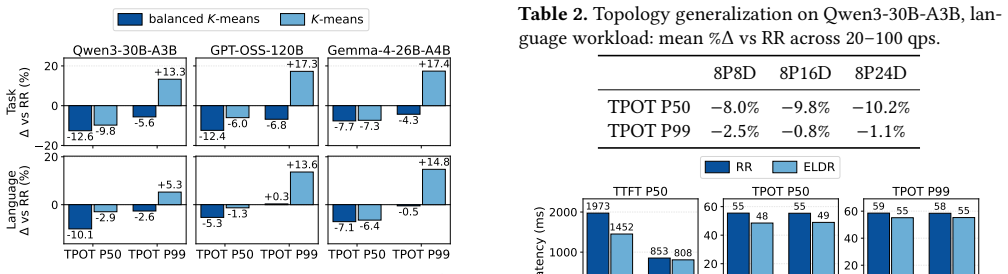
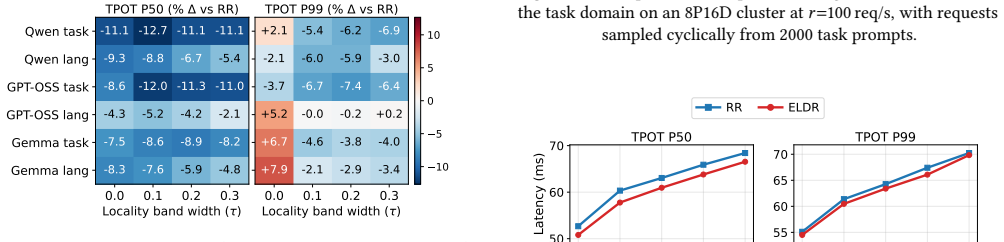
ELDR builds an expert signature from a request's prefill expert activations to forecast the experts it will activate during decode. Balanced K-means partitions the signature space across decode workers offline. Online locality-band routing directs each request to the least-loaded worker among those whose partition best matches its signature. A signature cache co-indexed with the KV cache maintains precision when prefix caching is used. Across three MoE models and two workloads the approach reduces median time-per-output-token by 5.9-13.9 percent relative to the strongest load-balancing baselines while producing unchanged model outputs.
What carries the argument
The expert signature from prefill activations, combined with offline balanced K-means partitioning of signature space and online locality-band routing that selects the least-loaded matching worker.
If this is right
- Decode routing decisions can be improved by incorporating predicted expert locality in addition to instantaneous load.
- Tying the signature cache to KV-block granularity preserves routing accuracy under prefix caching.
- The same routing logic leaves model outputs unchanged, so correctness is unaffected.
- The measured gains hold for deployments scaling to 40 GPUs and across multiple MoE architectures.
Where Pith is reading between the lines
- If signatures remain stable across turns, the method could reduce the frequency of expert weight movement between workers.
- The same signature-based partitioning idea might apply to other serving disaggregation boundaries where activation patterns are request-specific.
- Dynamic re-partitioning of signature space could be tested if workload expert distributions drift over time.
Load-bearing premise
The set of experts activated during prefill for a request reliably predicts the experts that will be activated during its decode phase.
What would settle it
A direct comparison, for a large set of requests, showing that the experts actually activated during decode frequently differ from the signature predicted from prefill activations.
Figures





read the original abstract
In prefill-decode (PD) disaggregated LLM serving, each request is assigned to a decode worker after prefill. Existing decode routers balance only load; for mixture-of-experts (MoE) models this is incomplete: equally loaded workers can differ in latency, since each decode step loads the weights of every distinct expert its batch activates. We present ELDR, an expert-locality-aware decode router for PD-disaggregated MoE serving. From a request's prefill expert activations, ELDR builds an expert signature predicting the experts it will activate during generation. Offline, balanced K-means partitions signature space across decode workers; online, locality-band routing sends each request to the least-loaded worker among those best matching its signature. A signature cache, co-indexed with the KV cache at KV-block granularity, keeps signatures exact under prefix caching. Implemented in vLLM and evaluated on deployments of up to 40 GPUs, ELDR reduces median TPOT by 5.9-13.9% over the strongest of four load-balancing baselines across three MoE models and two workloads, with model outputs unchanged.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ELDR, an expert-locality-aware decode router for prefill-decode disaggregated MoE LLM serving. From a request's prefill expert activations, it constructs an expert signature to predict decode-phase experts, applies offline balanced K-means partitioning of signature space across decode workers, and performs online locality-band routing to the least-loaded best-matching worker. A signature cache co-indexed with the KV cache at block granularity supports prefix caching. Implemented in vLLM, it reports 5.9-13.9% median TPOT reduction versus the strongest of four load-balancing baselines across three MoE models and two workloads on up to 40 GPUs, with unchanged model outputs.
Significance. If the prefill-to-decode prediction holds, the approach yields a practical latency improvement for MoE serving by reducing per-step expert weight loading via locality without quality loss. Credit is due for the vLLM implementation, the KV-cache-co-indexed signature mechanism, and the multi-model/multi-workload evaluation scope, which together support deployability claims.
major comments (1)
- [methods (expert signature)] Expert signature construction (methods section): the claim that the prefill-derived signature 'predicts' the experts activated during autoregressive decode generation is load-bearing for the locality benefit, yet the manuscript provides no quantitative validation such as per-request overlap statistics, correlation coefficients, or ablation on prediction accuracy between prefill signatures and actual decode expert choices. Without this, the reported TPOT gains cannot be attributed to the expert-locality mechanism rather than load balancing or tie-breaking.
minor comments (2)
- [abstract] Abstract and evaluation: workloads, model sizes, and exact baseline implementations should be named explicitly rather than summarized as 'two workloads' and 'four load-balancing baselines' to allow reproduction.
- [system design] The signature cache description would benefit from a diagram showing its co-indexing with KV blocks at the stated granularity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [methods (expert signature)] Expert signature construction (methods section): the claim that the prefill-derived signature 'predicts' the experts activated during autoregressive decode generation is load-bearing for the locality benefit, yet the manuscript provides no quantitative validation such as per-request overlap statistics, correlation coefficients, or ablation on prediction accuracy between prefill signatures and actual decode expert choices. Without this, the reported TPOT gains cannot be attributed to the expert-locality mechanism rather than load balancing or tie-breaking.
Authors: We agree that the manuscript lacks explicit quantitative validation of the prefill-to-decode prediction accuracy, which is needed to more rigorously attribute gains to locality rather than load balancing. In the revised manuscript we will add: (1) per-request overlap statistics (Jaccard similarity and set overlap ratios between the prefill expert signature and experts activated in the first 8–32 decode steps, reported as workload averages with standard deviation); (2) Pearson or Spearman correlation coefficients between signature similarity and observed decode expert overlap where applicable; and (3) an ablation that replaces the signature-based locality band with either pure load balancing or randomized worker assignment while keeping all other components fixed. These additions will be placed in a new subsection of the methods or evaluation and will use the same three models and two workloads already reported. The end-to-end TPOT results remain unchanged, but the new metrics will directly address the attribution concern. revision: yes
Circularity Check
No circularity; empirical system evaluated against external baselines
full rationale
The paper describes a routing heuristic that constructs an expert signature from observed prefill activations, applies offline K-means partitioning on that signature space, and routes online to the least-loaded matching worker. Performance is measured directly via TPOT reductions on real deployments against four independent load-balancing baselines. No derivation step reduces by construction to a fitted parameter renamed as prediction, no self-citation chain supports a uniqueness claim, and the predictiveness assumption is not smuggled in via definition but is instead the subject of the end-to-end empirical comparison. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert activations during prefill are predictive of those during decode generation
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL]https://arxiv.org/abs/2108. 07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Abhimanyu Bambhaniya, Geonhwa Jeong, Jason Park, Jiecao Yu, Jae- won Lee, Pengchao Wang, Changkyu Kim, Chunqiang Tang, and Tushar Krishna. 2026. Scaling Multi-Node Mixture-of-Experts In- ference Using Expert Activation Patterns. arXiv:2604.23150 [cs.LG] https://arxiv.org/abs/2604.23150
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion An- droutsopoulos, Daniel Katz, and Nikolaos Aletras. 2022. LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. In Proceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), Smaranda Muresan, Preslav Nakov, and Al...
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Hee- woo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Train- ing Verifiers to Solve Math Word Problems. arXiv:2110.14168 [cs.LG] https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
DeepSeek-AI. 2025. EPLB: Expert Parallelism Load Balancer.https: //github.com/deepseek-ai/EPLB
2025
-
[7]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Google DeepMind. 2025. Gemma 4 26B-A4B.https://huggingface.co/ google/gemma-4-26b-a4b
2025
-
[10]
Vima Gupta, Jae Hyung Ju, Kartik Sinha, Ada Gavrilovska, and Anand Padmanabha Iyer. 2026. Lynx: Enabling Efficient MoE Inference through Dynamic Batch-Aware Expert Selection. arXiv:2411.08982 [cs.LG]https://arxiv.org/abs/2411.08982
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. 2024. OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. arXiv:2402.14008 [cs.CL] https://arxiv.org/abs/2402.14008
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mas- sive Multitask Language Understanding. arXiv:2009.03300 [cs.CY] https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Mea- suring Mathematical Problem Solving With the MATH Dataset. arXiv:2103.03874 [cs.LG]https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams.Applied Sciences11, 14 (2021). doi:10.3390/app11146421
-
[15]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. PubMedQA: A Dataset for Biomedical Research Question Answering. InProceedings of the 2019 Conference on Empiri- cal Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent ...
-
[16]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv:2309.06180 [cs.LG]https://arxiv. org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2023. DS-1000: a natural and reliable benchmark for data science code generation. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 756, 27 pages
2023
- [19]
-
[20]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s Verify Step by Step. arXiv:2305.20050 [cs.LG] https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems. arXiv:1705.04146 [cs.AI] https://arxiv.org/abs/1705.04146
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
S. Lloyd. 1982. Least squares quantization in PCM.IEEE Transactions on Information Theory28, 2 (1982), 129–137. doi:10.1109/TIT.1982.1056489
-
[23]
Malinen and Pasi Fränti
Mikko I. Malinen and Pasi Fränti. 2014. Balanced K-Means for Clus- tering. InStructural, Syntactic, and Statistical Pattern Recognition, Pasi Fränti, Gavin Brown, Marco Loog, Francisco Escolano, and Marcello Pelillo (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 32–41
2014
-
[24]
M. Mitzenmacher. 2001. The power of two choices in randomized load balancing.IEEE Transactions on Parallel and Distributed Systems12, 10 (2001), 1094–1104. doi:10.1109/71.963420
- [25]
-
[26]
NVIDIA. 2026. NVIDIA Dynamo: A Datacenter-Scale Distributed In- ference Serving Framework.https://github.com/ai-dynamo/dynamo
2026
-
[27]
NVIDIA Corporation. 2024. NIXL: NVIDIA Inference Xfer Library. https://github.com/ai-dynamo/nixl
2024
-
[28]
Costin-Andrei Oncescu, Qingyang Wu, Wai Tong Chung, Robert Wu, Bryan Gopal, Junxiong Wang, Tri Dao, and Ben Athiwaratkun. 2025. Opportunistic Expert Activation: Batch-Aware Expert Routing for Faster Decode Without Retraining. arXiv:2511.02237 [cs.LG]https: //arxiv.org/abs/2511.02237
-
[29]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
- [31]
- [32]
-
[33]
The llm-d Authors. 2026. llm-d: Kubernetes-Native Distributed Infer- ence.https://github.com/llm-d/llm-d. 14
2026
- [34]
-
[35]
Wayne Winston. 1977. Optimality of the shortest line discipline.Jour- nal of Applied Probability14, 1 (1977), 181??89. doi:10.2307/3213271
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Yanpeng Yu, Haiyue Ma, Krish Agarwal, Nicolai Oswald, Qijing Huang, Hugo Linsenmaier, Chunhui Mei, Ritchie Zhao, Ritika Borkar, Bita Darvish Rouhani, David Nellans, Ronny Krashinsky, and Anurag Khandelwal. 2025. Efficient MoE Serving in the Memory-Bound Regime: Balance Activated Experts, Not Tokens. arXiv:2512.09277 [cs.DC]https://arxiv.org/abs/2512.09277
-
[38]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. WildChat: 1M ChatGPT Interaction Logs in the Wild. arXiv:2405.01470 [cs.CL]https://arxiv.org/abs/2405.01470
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Sto- ica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. arXiv:2312.07104 [cs.AI]https://arxiv.org/abs/2312.07104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 193– 210.https://www.usenix.org/co...
2024
-
[41]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhou- jun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Bi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.