Auditing Forgetting in Limited Memory Language Models
Pith reviewed 2026-07-02 13:07 UTC · model grok-4.3
The pith
Deleted facts in limited memory language models persist almost exclusively through retrieval artifacts rather than parametric memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
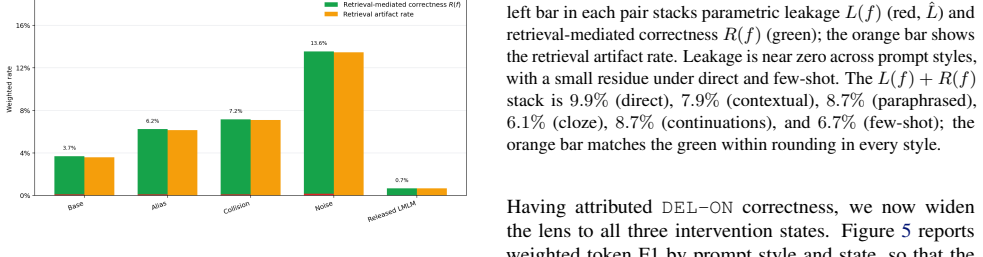
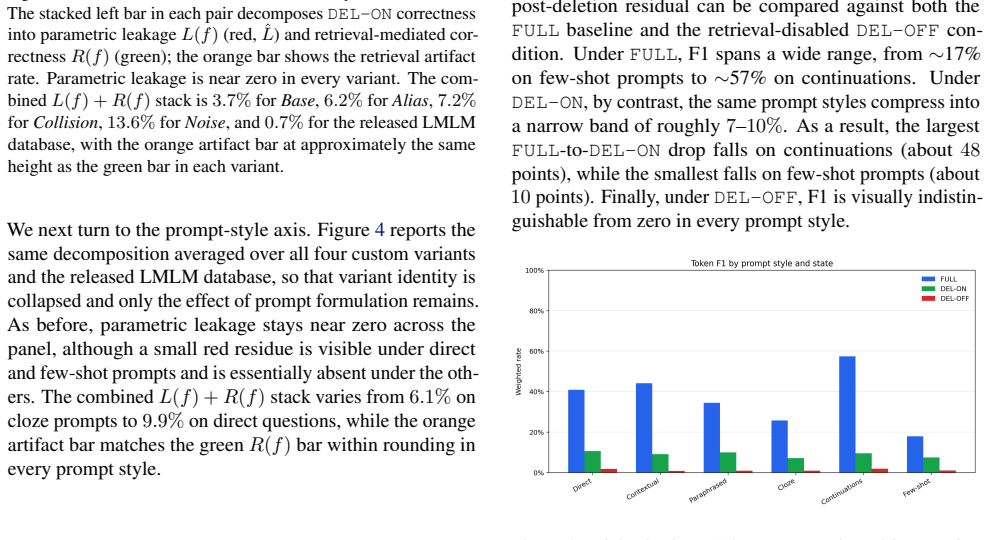
By holding the model fixed and varying the database state at inference across FULL, DEL-ON, and DEL-OFF conditions, the audit decomposes post-deletion performance into near-zero parametric leakage, retrieval-mediated correctness, and retrieval artifact rate. Across all tested variants and prompts, parametric leakage stays near zero while retrieval-mediated correctness matches the artifact rate, indicating that surviving knowledge is reconstituted from near-neighbor retrieval in the edited database. This residual ranges from 0.7% on the released LMLM database to 13.6% on the most adversarial variant.
What carries the argument
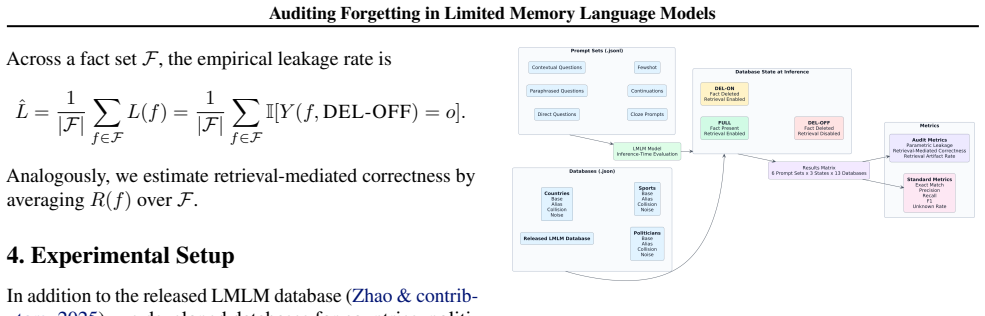
Causal auditing framework that decomposes post-deletion behavior into parametric leakage L(f), retrieval-mediated correctness R(f), and retrieval artifact rate by comparing FULL, DEL-ON, and DEL-OFF database states at inference time.
If this is right
- Parametric leakage remains near zero across all prompt styles and database topologies.
- Retrieval-mediated correctness matches the retrieval artifact rate within rounding.
- Post-deletion correctness is reconstituted from near-neighbor retrieval rather than residual parametric memory.
- The unlearning boundary is set by database administration rather than model parameters.
- Prompt formulation does not independently control how much of a deleted fact survives.
Where Pith is reading between the lines
- Database designers could lower residual leakage by reducing alias density or collision probability in the retrieval graph.
- The same auditing method could check whether forgetting is genuine in other retrieval-augmented models.
- Adversarial database topologies may require more than simple deletion to achieve low residual survival.
- Security against recovery of deleted facts in LMLMs depends on controlling the structure of the external memory.
Load-bearing premise
The three interventions correctly isolate parametric memory from retrieval effects without introducing new artifacts from the specific database topologies or prompt formulations.
What would settle it
A prompt or database variant where the model returns the deleted answer at substantially higher rates in the DEL-OFF condition than in the DEL-ON condition would indicate meaningful parametric leakage.
Figures



read the original abstract
Limited Memory Language Models (LMLMs) externalize factual knowledge to a database to enable deletion-based unlearning without retraining. Existing evaluations measure post-deletion correctness in aggregate and cannot tell whether a deleted fact persists through residual parametric memory, alternative retrieval paths, or near-neighbor retrieval artifacts. We propose a causal auditing framework that holds the model fixed and varies the database state at inference time across three interventions: FULL, DEL-ON, and DEL-OFF. The framework decomposes post-deletion behavior into parametric leakage L(f), retrieval-mediated correctness R(f), and a retrieval artifact rate grounded in the inference-time retrieval trace. We apply it to 12,228 alias-closure deletions across thirteen databases, including four adversarial topologies (Base, Alias, Noise, Collision) we construct in three domains, and six prompt formulations. Parametric leakage is near zero in every variant and every prompt style: the model rarely returns the deleted answer in the absence of retrieval. The residual that does survive lives in the retrieval graph: retrieval-mediated correctness and the retrieval artifact rate match within rounding everywhere, so post-deletion correctness is, in our audit, predominantly reconstituted from near-neighbor retrieval. This residual ranges from 0.7% on the released LMLM database to 13.6% on the most adversarial variant, and prompt formulation does not independently control how much of a deleted fact survives. These results suggest that, for this class of LMLM and deletion procedure, the unlearning boundary is drawn primarily by the database administrator rather than by the model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a causal auditing framework for Limited Memory Language Models (LMLMs) that externalize knowledge to a database. It varies database state at inference via FULL, DEL-ON, and DEL-OFF interventions to decompose post-deletion behavior into parametric leakage L(f), retrieval-mediated correctness R(f), and retrieval artifact rate. Applied to 12,228 alias-closure deletions across 13 databases (including four adversarial topologies) and six prompt formulations, it reports parametric leakage near zero in all cases, with residual post-deletion correctness (0.7% to 13.6%) attributable to near-neighbor retrieval artifacts rather than parametric memory.
Significance. If the interventions validly isolate the components without confounding, this provides a useful empirical decomposition showing that unlearning boundaries in this LMLM class are set primarily by database design. The evaluation across adversarial topologies and prompt styles adds robustness. The framework could support future audits of retrieval-augmented models.
major comments (2)
- [Auditing framework] Description of the three interventions (auditing framework): The claim that L(f) is near zero rests on DEL-OFF isolating pure parametric memory. However, disabling retrieval may independently alter the model's generation regime (e.g., refusal rates or fallback strategies), so the low rate of returning the deleted answer under DEL-OFF does not necessarily imply the same under enabled retrieval without the target fact. This assumption is load-bearing for the central conclusion and is not validated by direct comparisons of output distributions between conditions.
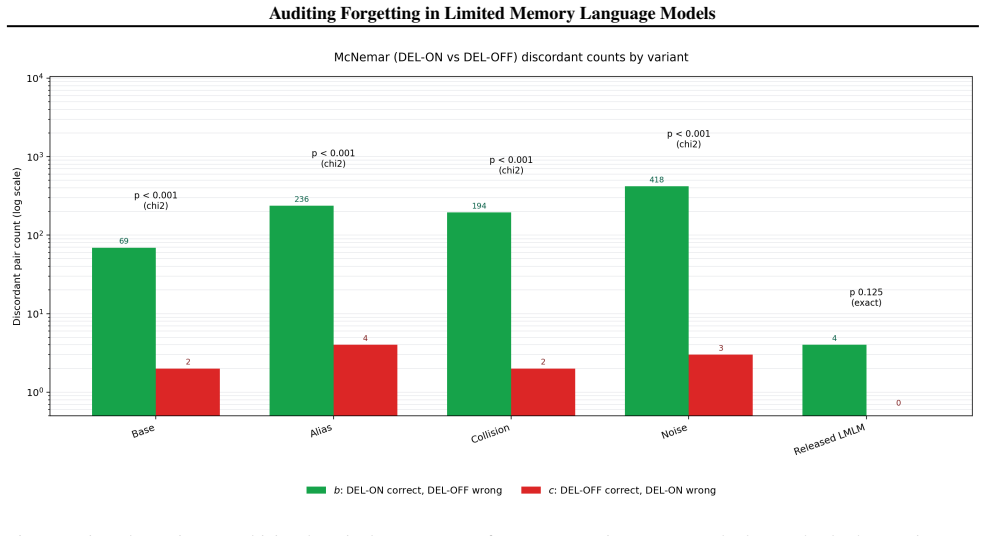
- [Empirical results] Results reporting the leakage and artifact rates (0.7% to 13.6% across variants): The concrete percentages are presented without error bars, confidence intervals, or statistical tests (e.g., tests against zero or equivalence between R(f) and artifact rate). With 12,228 deletions, this omission makes it difficult to assess whether 'near zero' and 'match within rounding' are statistically supported or sensitive to sampling.
minor comments (2)
- The notation L(f), R(f) and artifact rate would benefit from an explicit equation or definition box in the main text rather than relying on the abstract and later prose.
- A summary table aggregating rates by topology and prompt formulation would improve readability of the multi-condition results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Description of the three interventions (auditing framework): The claim that L(f) is near zero rests on DEL-OFF isolating pure parametric memory. However, disabling retrieval may independently alter the model's generation regime (e.g., refusal rates or fallback strategies), so the low rate of returning the deleted answer under DEL-OFF does not necessarily imply the same under enabled retrieval without the target fact. This assumption is load-bearing for the central conclusion and is not validated by direct comparisons of output distributions between conditions.
Authors: We agree that the validity of DEL-OFF as an isolator of parametric leakage requires confirmation that the generation regime is not materially altered by disabling retrieval. In the revised manuscript we will add explicit comparisons of output distributions (refusal rates, fallback strategy frequencies, and token-level statistics) between DEL-ON and DEL-OFF conditions on the same prompts. These comparisons will be reported for each database and prompt formulation to substantiate that the low L(f) rates reflect absence of parametric memory rather than a change in generation behavior. revision: yes
-
Referee: Results reporting the leakage and artifact rates (0.7% to 13.6% across variants): The concrete percentages are presented without error bars, confidence intervals, or statistical tests (e.g., tests against zero or equivalence between R(f) and artifact rate). With 12,228 deletions, this omission makes it difficult to assess whether 'near zero' and 'match within rounding' are statistically supported or sensitive to sampling.
Authors: We acknowledge that the absence of uncertainty quantification and formal tests limits the strength of the claims. In the revision we will report binomial confidence intervals for all rates and add statistical tests (equivalence tests for R(f) versus artifact rate, and one-sided tests against zero for L(f)) using the existing 12,228 observations. These additions will be included in the main results table and the supplementary material. revision: yes
Circularity Check
No circularity: empirical decomposition via direct interventions
full rationale
The paper's central claims rest on operational definitions of L(f), R(f), and artifact rate measured directly from three controlled database-state interventions (FULL, DEL-ON, DEL-OFF) applied to 12,228 deletions across multiple topologies and prompts. No equations, fitted parameters, or self-citations are invoked to derive the reported near-zero parametric leakage; the results are raw empirical counts under each intervention. The decomposition is therefore self-contained against external benchmarks and does not reduce any quantity to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Varying the database state at inference time while holding the model fixed isolates parametric memory effects from retrieval effects.
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/1912.03817. Carlini, N., Tramer, F., Wallace, E., Jagielski, M., Herbert- 7 Auditing Forgetting in Limited Memory Language Models V oss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, ´U., Oprea, A., and Raffel, C. Extracting training data from large language models. InUSENIX Security Symposium,
-
[2]
URL https://arxiv. org/abs/2012.07805. Guu, K., Lee, K., Tung, Z., Pasupat, P., and Chang, M.- W. Realm: Retrieval-augmented language model pre- training. InInternational Conference on Machine Learn- ing,
-
[3]
URL https://arxiv.org/abs/2002. 08909. Karpukhin, V ., O˘guz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2002
-
[4]
Dense Passage Retrieval for Open-Domain Question Answering
URL https: //arxiv.org/abs/2004.04906. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K¨uttler, H., Lewis, M., Yih, W.-t., Rockt¨aschel, T., Riedel, S., and Kiela, D. Retrieval-augmented gen- eration for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[5]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
URL https://arxiv.org/abs/2005.11401. Lizzo, T. and Heck, L. Unlearning in llms: Methods, evaluation, and open challenges,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[6]
Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z
URL https: //arxiv.org/abs/2601.13264. Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z. C., and Kolter, J. Z. Tofu: A task of fictitious unlearning for llms,
-
[7]
TOFU: A Task of Fictitious Unlearning for LLMs
URL https://arxiv.org/abs/ 2401.06121. Mallen, A., Asai, A., Zhong, V ., Das, R., Khashabi, D., and Hajishirzi, H. When not to trust language mod- els: Investigating effectiveness of parametric and non- parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguis- tics (ACL),
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL https://arxiv.org/abs/ 2212.10511. Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locat- ing and editing factual associations in gpt. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Locating and Editing Factual Associations in GPT
URL https://arxiv.org/abs/2202.05262. Meng, K., Sharma, A. S., Andonian, A., Belinkov, Y ., and Bau, D. Mass-editing memory in a transformer. InInter- national Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Mass-Editing Memory in a Transformer
URLhttps://arxiv.org/abs/2210.07229. Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W.-t., Koh, P. W., Iyyer, M., Zettlemoyer, L., and Hajishirzi, H. Factscore: Fine-grained atomic evaluation of factual pre- cision in long form text generation. InEmpirical Methods in Natural Language Processing (EMNLP),
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yao, Y ., Wang, P., Tian, B., Cheng, S., Li, Z., Deng, S., Chen, H., and Zhang, N
URL https://arxiv.org/abs/2305.14251. Yao, Y ., Wang, P., Tian, B., Cheng, S., Li, Z., Deng, S., Chen, H., and Zhang, N. Editing large language models: Problems, methods, and opportunities. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP),
- [12]
-
[13]
8 Auditing Forgetting in Limited Memory Language Models A
URL https://arxiv.org/abs/2505.15962. 8 Auditing Forgetting in Limited Memory Language Models A. Architecture This appendix details the two design axes that define the prompt × database grid used throughout the audit: the six prompt formulations applied to every target fact, and the four custom database topologies constructed to stress-test alias-closure ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.