GaussianFusion: Unified 3D Gaussian Representation for Multi-Modal Fusion Perception
Pith reviewed 2026-07-02 14:27 UTC · model grok-4.3
The pith
3D Gaussian representation unifies multi-modal sensor features in continuous space for 3D perception tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
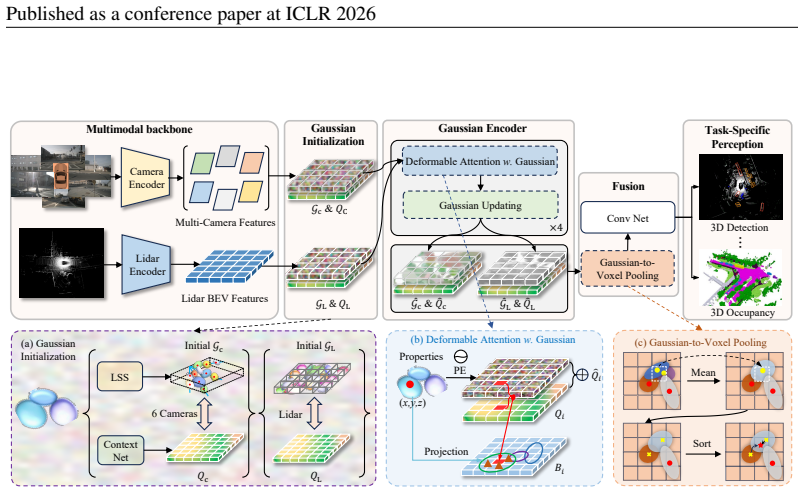
GaussianFusion unifies multi-modal features inside a shared continuous 3D Gaussian space by initializing Gaussians through forward projection from each sensor and then updating their properties with a shared attention-based cross-modal encoder; the resulting representation is task-agnostic and yields 2.6 NDS gains over BEVFusion on nuScenes detection plus 1.55 mIoU improvement over GaussFormer on occupancy while using 30 percent fewer Gaussians and running 4.5 times faster.
What carries the argument
The 3D Gaussian as a continuous scene primitive, initialized by forward projection of multi-modal inputs and refined by an attention-based cross-modal encoder that performs the fusion.
If this is right
- The same Gaussian representation supports both 3D object detection and semantic occupancy without retraining the core fusion module.
- Performance scales with fewer primitives than prior Gaussian methods while delivering higher accuracy.
- Continuous properties preserve fine details that discrete grids lose, directly benefiting tasks that rely on edges and textures.
Where Pith is reading between the lines
- The approach could incorporate an extra modality such as radar by extending the same forward-projection and attention stages.
- Uncertainty estimates might be derived directly from the learned Gaussian covariances for downstream planning.
- Real-time systems could benefit from the reported speedup when running on embedded hardware with limited compute.
Load-bearing premise
Forward projection plus attention encoding can align features from different sensors without creating alignment artifacts or discarding critical information.
What would settle it
A controlled experiment on nuScenes-style data with known artificial sensor misalignment that measures whether the Gaussian fusion produces larger accuracy drops than a BEV baseline or single-modality inputs.
Figures


read the original abstract
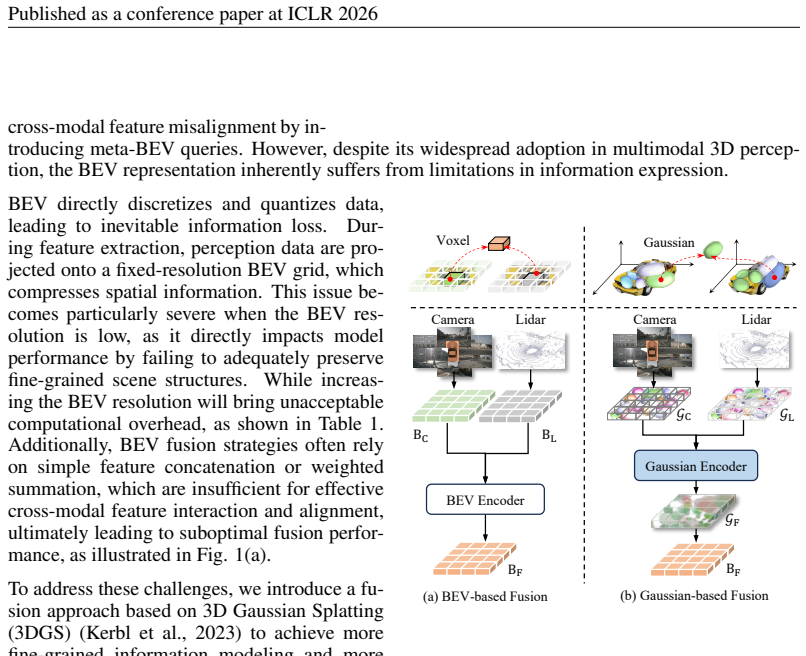
The bird's-eye view (BEV) representation enables multi-sensor features to be fused within a unified space, serving as the primary approach for achieving comprehensive 3D perception. However, the discrete grid representation of BEV leads to significant detail loss and limits feature alignment and cross-modal information interaction in multimodal fusion perception. In this work, we break from the conventional BEV paradigm and propose a new universal framework for multi-modal fusion based on 3D Gaussian representation. This approach naturally unifies multi-modal features within a shared and continuous 3D Gaussian space, effectively preserving edge and fine texture details. To achieve this, we design a novel forward-projection-based multi-modal Gaussian initialization module and a shared cross-modal Gaussian encoder that iteratively updates Gaussian properties based on an attention mechanism. GaussianFusion is inherently a task-agnostic model, with its unified Gaussian representation naturally supporting various 3D perception tasks. Extensive experiments demonstrate the generality and robustness of GaussianFusion. On the nuScenes dataset, it outperforms the 3D object detection baseline BEVFusion by 2.6 NDS. Its variant surpasses GaussFormer on 3D semantic occupancy with 1.55 mIoU improvement while using only 30% of the Gaussians and achieving a 450% speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GaussianFusion, a task-agnostic framework that replaces discrete BEV grids with a continuous 3D Gaussian representation for multi-modal (LiDAR+camera) fusion in 3D perception. It introduces a forward-projection-based multi-modal Gaussian initialization module to create a shared Gaussian set and a shared cross-modal Gaussian encoder that iteratively refines Gaussian properties via attention. On nuScenes, the method reports a 2.6 NDS gain over BEVFusion for detection and a 1.55 mIoU gain over GaussFormer for occupancy while using 30% fewer Gaussians and achieving 450% speedup.
Significance. If the unification and alignment claims hold with supporting derivations and ablations, the shift to continuous 3D Gaussians could meaningfully advance multi-modal perception by reducing detail loss and enabling more natural cross-modal interaction than BEV. The reported efficiency improvements would be practically relevant for real-time systems.
major comments (2)
- [Abstract] Abstract: the central unification claim rests on the forward-projection initialization producing reliably aligned 3D Gaussians from heterogeneous sensors, yet no projection equations (e.g., mapping of 2D features to Gaussian means/covariances/opacities) or lifting procedure are supplied. This directly affects whether the subsequent attention encoder can compensate for misalignment.
- [Experiments] Experiments (performance claims): the 2.6 NDS and 1.55 mIoU gains are stated without reference to specific tables, ablation studies on calibration error, modality dropout, or density mismatch, nor error bars or dataset-split details. These omissions make the robustness of the shared encoder impossible to assess from the provided text.
minor comments (1)
- [Abstract] Abstract: '450% speedup' is nonstandard phrasing; rewrite as '4.5× speedup' for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central unification claim rests on the forward-projection initialization producing reliably aligned 3D Gaussians from heterogeneous sensors, yet no projection equations (e.g., mapping of 2D features to Gaussian means/covariances/opacities) or lifting procedure are supplied. This directly affects whether the subsequent attention encoder can compensate for misalignment.
Authors: We agree that explicit projection equations would strengthen the presentation of the unification claim. While Section 3.2 of the manuscript describes the forward-projection-based multi-modal Gaussian initialization module, the equations mapping 2D camera features and LiDAR points to initial Gaussian means, covariances, and opacities are not fully formalized. In the revision we will insert these derivations (including the lifting procedure) immediately after the module description to clarify how initial alignment is obtained before the shared encoder. revision: yes
-
Referee: [Experiments] Experiments (performance claims): the 2.6 NDS and 1.55 mIoU gains are stated without reference to specific tables, ablation studies on calibration error, modality dropout, or density mismatch, nor error bars or dataset-split details. These omissions make the robustness of the shared encoder impossible to assess from the provided text.
Authors: The 2.6 NDS and 1.55 mIoU figures are taken from Table 2 (detection) and Table 4 (occupancy) respectively; we will add explicit table citations to the abstract. The manuscript already contains modality-dropout and density ablations in Section 4.4. We do not currently report calibration-error sweeps or error bars; we will add a short calibration-robustness ablation and standard-deviation reporting in the revision (or supplementary material) to address this concern. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a forward-projection initialization module and attention-based cross-modal encoder to create a shared 3D Gaussian representation, claiming empirical gains on nuScenes without any equations that reduce predictions to fitted inputs or self-citations that bear the central load. No self-definitional loops, renamed known results, or ansatzes smuggled via prior work appear in the provided text. The unification and task-agnostic claims rest on the architectural description and experimental validation rather than tautological reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Florian Chabot, Nicolas Granger, and Guillaume Lapouge. Gaussianbev: 3d gaussian representation meets perception models for bev segmentation.arXiv preprint arXiv:2407.14108,
-
[2]
Wanshui Gan, Fang Liu, Hongbin Xu, Ningkai Mo, and Naoto Yokoya. Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting.arXiv preprint arXiv:2408.11447,
-
[3]
Yuanhui H, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction.arXiv preprint arXiv:2405.17429,
-
[4]
Chunyong Hu, Hang Zheng, Kun Li, Jianyun Xu, Weibo Mao, Maochun Luo, Lingxuan Wang, Mingxia Chen, Kaixuan Liu, Yiru Zhao, et al. Fusionformer: A multi-sensory fusion in bird’s- eye-view and temporal consistent transformer for 3d objection.arXiv preprint arXiv:2309.05257, 2023a. Haotian Hu, Fanyi Wang, Jingwen Su, Yaonong Wang, Laifeng Hu, Weiye Fang, Jing...
-
[5]
Bevdet4d: Exploit temporal cues in multi- camera 3d object detection,
Junjie Huang and Guan Huang. Bevdet4d: Exploit temporal cues in multi-camera 3d object detec- tion.arXiv preprint arXiv:2203.17054, 2022a. Junjie Huang and Guan Huang. Bevpoolv2: A cutting-edge implementation of bevdet toward de- ployment.arXiv preprint arXiv:2211.17111, 2022b. 11 Published as a conference paper at ICLR 2026 Yang Jiao, Zequn Jie, Shaoxian...
-
[6]
Fully sparse 3d occupancy prediction.arXiv preprint arXiv:2312.17118,
Haisong Liu, Yang Chen, Haiguang Wang, Zetong Yang, Tianyu Li, Jia Zeng, Li Chen, Hongyang Li, and Limin Wang. Fully sparse 3d occupancy prediction.arXiv preprint arXiv:2312.17118,
-
[7]
Shuai Liu, Quanmin Liang, Zefeng Li, Boyang Li, and Kai Huang. Gaussianfusion: Gaussian-based multi-sensor fusion for end-to-end autonomous driving.arXiv preprint arXiv:2506.00034,
-
[8]
Decoupled Weight Decay Regularization
Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela L Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In 2023 IEEE international conference on robotics and automation (ICRA), pp. 2774–2781. IEEE, 2023b. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Yuhang Lu, Xinge Zhu, Tai Wang, and Yuexin Ma. Octreeocc: Efficient and multi-granularity occupancy prediction using octree queries.arXiv preprint arXiv:2312.03774,
-
[10]
Cam4docc: Benchmark for camera-only 4d occupancy forecasting in au- tonomous driving applications
Junyi Ma, Xieyuanli Chen, Jiawei Huang, Jingyi Xu, Zhen Luo, Jintao Xu, Weihao Gu, Rui Ai, and Hesheng Wang. Cam4docc: Benchmark for camera-only 4d occupancy forecasting in au- tonomous driving applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21486–21495, 2024a. 12 Published as a conference paper at IC...
2026
-
[11]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pp. 194–210. Springer,
2020
-
[12]
Unitr: A unified and efficient multi-modal transformer for bird’s-eye-view representation
Haiyang Wang, Hao Tang, Shaoshuai Shi, Aoxue Li, Zhenguo Li, Bernt Schiele, and Liwei Wang. Unitr: A unified and efficient multi-modal transformer for bird’s-eye-view representation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6792–6802, 2023a. Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li, and Xiangyu Zhang. Explorin...
-
[13]
Cross modal transformer: Towards fast and robust 3d object detection
13 Published as a conference paper at ICLR 2026 Junjie Yan, Yingfei Liu, Jianjian Sun, Fan Jia, Shuailin Li, Tiancai Wang, and Xiangyu Zhang. Cross modal transformer: Towards fast and robust 3d object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 18268–18278,
2026
-
[14]
Deepinteraction: 3d object detection via modality interaction.Advances in Neural Information Processing Systems, 35:1992–2005,
Zeyu Yang, Jiaqi Chen, Zhenwei Miao, Wei Li, Xiatian Zhu, and Li Zhang. Deepinteraction: 3d object detection via modality interaction.Advances in Neural Information Processing Systems, 35:1992–2005,
1992
-
[15]
Junbo Yin, Jianbing Shen, Runnan Chen, Wei Li, Ruigang Yang, Pascal Frossard, and Wenguan Wang. Is-fusion: Instance-scene collaborative fusion for multimodal 3d object detection.arXiv preprint arXiv:2403.15241,
-
[16]
Sparselif: High- performance sparse lidar-camera fusion for 3d object detection
Hongcheng Zhang, Liu Liang, Pengxin Zeng, Xiao Song, and Zhe Wang. Sparselif: High- performance sparse lidar-camera fusion for 3d object detection. InEuropean Conference on Computer Vision, pp. 109–128. Springer, 2024a. Shuo Zhang, Yupeng Zhai, Jilin Mei, and Yu Hu. Fusionocc: Multi-modal fusion for 3d occupancy prediction. InProceedings of the 32nd ACM I...
-
[17]
Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, and Gang Yu. Class-balanced grouping and sampling for point cloud 3d object detection.arXiv preprint arXiv:1908.09492,
-
[18]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Sicheng Zuo, Wenzhao Zheng, Yuanhui Huang, Jie Zhou, and Jiwen Lu. Gaussianworld: Gaussian world model for streaming 3d occupancy prediction.arXiv preprint arXiv:2412.10373,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.