Beyond the Performance Illusion: Structure-Aware Stratified Partitioning and Curriculum Distributionally Robust Optimization for Spatially Correlated Domains
Pith reviewed 2026-07-03 17:07 UTC · model grok-4.3
The pith
Structure-aware stratified partitioning and curriculum distributionally robust optimization reduce data leakage and hidden stratification in spatiotemporally correlated domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
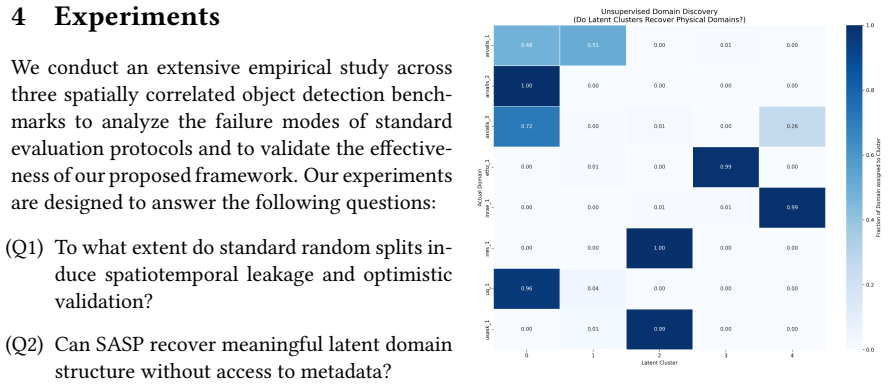
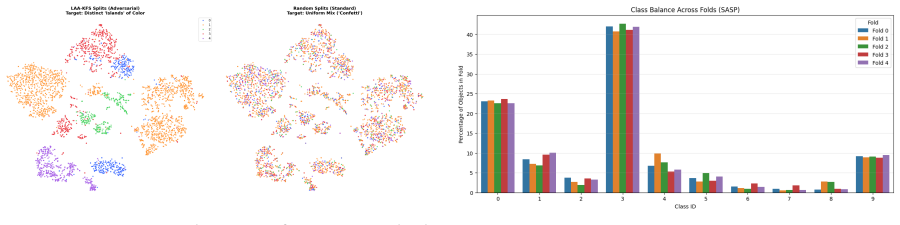
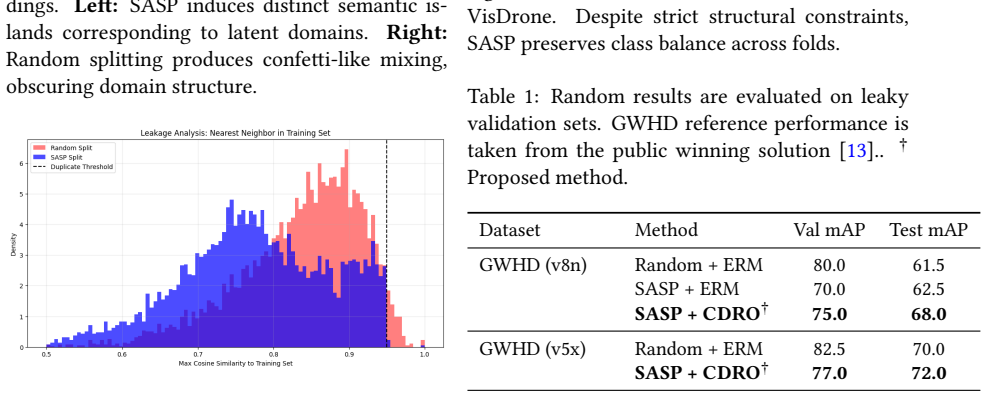
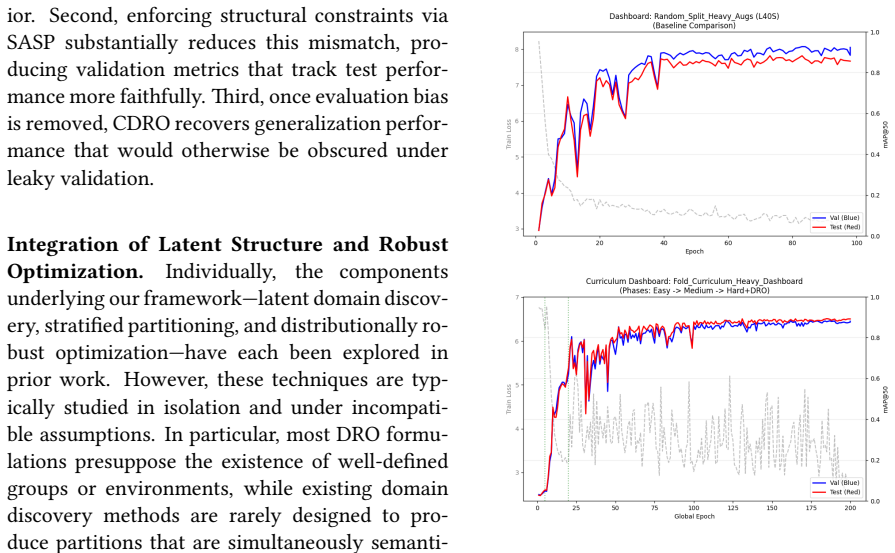
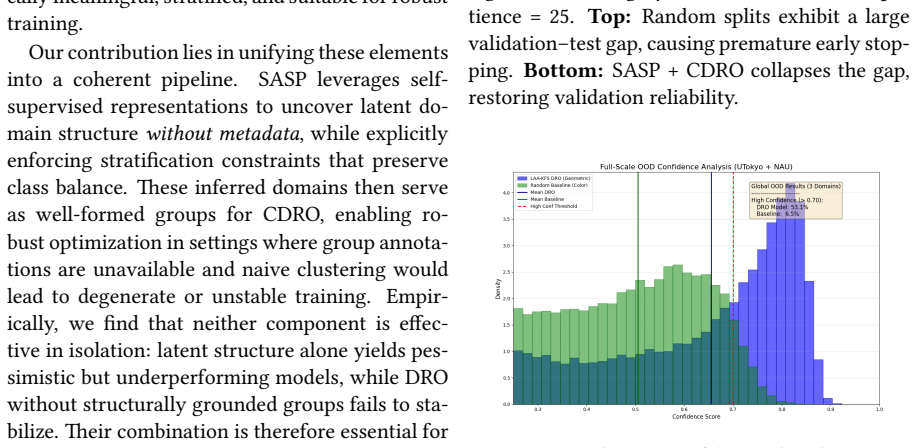
In spatiotemporally correlated domains, random splits allow correlated samples to span training and validation sets, inflating performance estimates, while aggregate metrics obscure failures on minority groups. Structure-Aware Stratified Partitioning constructs validation splits that reduce this leakage while preserving meaningful class balance. Curriculum Distributionally Robust Optimization applies a curriculum-based relaxation of distributionally robust training to stabilize learning under these partitions. The combination produces improved generalization, more reliable confidence calibration, and reveals failure modes that conventional random-split evaluation conceals.
What carries the argument
Structure-Aware Stratified Partitioning (SASP), which builds validation splits that respect spatial or temporal structure, and Curriculum Distributionally Robust Optimization (CDRO), which relaxes distributionally robust training into a curriculum schedule to stabilize optimization.
If this is right
- Models evaluated and trained under the new framework exhibit improved generalization to new regions or time periods.
- Confidence scores become better calibrated, reflecting true error rates on held-out structured data.
- Aggregate performance numbers no longer mask errors on minority subpopulations that arise from hidden stratification.
- Benchmark results become more conservative and therefore more predictive of deployment behavior.
Where Pith is reading between the lines
- The same partitioning logic could be applied to temporal sequences or graph-structured data where random splits also induce leakage.
- Existing public benchmarks in remote sensing and medical imaging could be re-partitioned with SASP to produce more diagnostic leaderboards.
- Practitioners might adopt the curriculum schedule in CDRO even without the full SASP pipeline when training under distribution shift.
Load-bearing premise
That the proposed partitioning and training steps will reduce spatiotemporal leakage and hidden stratification without introducing new biases or losing critical class balance in the target domains.
What would settle it
A comparison on an additional benchmark with known spatial correlation in which the combined method shows no gain in out-of-distribution generalization or calibration accuracy relative to standard random splits would falsify the central claim.
Figures
read the original abstract
Performance evaluation in AI systems commonly assumes that random dataset splits produce independent and identically distributed (i.i.d.) subsets. We show that this assumption often breaks down in spatiotemporally correlated domains such as aerial surveillance, precision agriculture, and medical imaging, leading to two systematic failures: data leakage, where correlated samples span training and validation splits and inflate performance estimates, and hidden stratification, where errors on minority subpopulations are obscured by aggregate metrics. To address these issues, we propose a unified evaluation and training framework for spatially correlated data. We introduce Structure-Aware Stratified Partitioning (SASP), which constructs validation splits that reduce spatiotemporal leakage while preserving meaningful class balance, and Curriculum Distributionally Robust Optimization (CDRO), a curriculum-based relaxation of distributionally robust training that stabilizes optimization under these stricter splits. Across multiple benchmarks, this combination yields consistently improved generalization, more reliable confidence calibration, and exposes failure modes that remain hidden under conventional random-split evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that random dataset splits in spatiotemporally correlated domains (e.g., aerial surveillance, precision agriculture, medical imaging) violate the i.i.d. assumption, causing data leakage and hidden stratification that inflate performance estimates. It proposes Structure-Aware Stratified Partitioning (SASP) to construct leakage-reduced validation splits while preserving class balance, and Curriculum Distributionally Robust Optimization (CDRO) as a stabilized curriculum-based DRO training method. The combination is claimed to yield improved generalization, more reliable confidence calibration, and exposure of failure modes hidden under random splits, across multiple benchmarks.
Significance. If the empirical claims hold with rigorous validation, the work would be significant for evaluation practices in spatially correlated domains by providing tools to mitigate leakage and stratification biases, leading to more trustworthy model assessments and potentially better real-world deployment reliability.
major comments (2)
- [Abstract] Abstract: the central claim that SASP+CDRO 'yields consistently improved generalization [and] more reliable confidence calibration' is unsupported by any quantitative results, tables, figures, baselines, or error analysis, rendering the magnitude and reliability of the improvements impossible to assess.
- [Abstract] Abstract: no details are given on how SASP measures or reduces spatiotemporal leakage, how it preserves class balance without introducing new biases, or the specific curriculum schedule and robustness radius in CDRO, all of which are load-bearing for the claims of exposing hidden failure modes.
minor comments (1)
- The abstract refers to 'multiple benchmarks' without naming them or describing the domains' correlation structures; this should be expanded in the introduction or experimental section for clarity.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We address each major comment below, clarifying that the abstract serves as a high-level summary while the full quantitative support and methodological details appear in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SASP+CDRO 'yields consistently improved generalization [and] more reliable confidence calibration' is unsupported by any quantitative results, tables, figures, baselines, or error analysis, rendering the magnitude and reliability of the improvements impossible to assess.
Authors: Abstracts are designed to summarize contributions at a high level without embedding specific numerical results or tables. The manuscript provides these in the experimental sections, including tables and figures that compare SASP+CDRO against random splits and other baselines, report generalization metrics, calibration measures, and include error analysis with statistical details to substantiate the claims. revision: no
-
Referee: [Abstract] Abstract: no details are given on how SASP measures or reduces spatiotemporal leakage, how it preserves class balance without introducing new biases, or the specific curriculum schedule and robustness radius in CDRO, all of which are load-bearing for the claims of exposing hidden failure modes.
Authors: The abstract provides a concise overview of the methods. Full technical details on SASP's leakage measurement and reduction approach, class balance preservation strategy, the CDRO curriculum schedule, and robustness radius are specified in the methodology sections, along with discussion of how these elements reveal hidden failure modes through the reported experiments. revision: no
Circularity Check
No significant circularity identified
full rationale
The paper introduces SASP partitioning and CDRO training as new algorithmic proposals for spatially correlated domains, with performance claims resting on empirical benchmarks rather than any closed-form derivation or self-referential fitting. No equations, uniqueness theorems, or self-citations appear in the supplied text that could reduce a central result to its own inputs by construction. The framework is therefore self-contained against external benchmarks, consistent with the reader's assessment of score 2.0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Random dataset splits produce i.i.d. subsets in spatiotemporally correlated domains
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, L ´eon Bottou, Ishaan Gul- rajani, and David Lopez-Paz. Invari- ant risk minimization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
Why do deep convolutional networks generalize so poorly to small image transformations?Journal of Machine Learning Research, 20(184):1–25, 2019
Aharon Azulay and Yair Weiss. Why do deep convolutional networks generalize so poorly to small image transformations?Journal of Machine Learning Research, 20(184):1–25, 2019
2019
-
[3]
Emerging properties in self-supervised vision trans- formers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J ´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision trans- formers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[4]
An empirical study of training self- supervised vision transformers
Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self- supervised vision transformers. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[5]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Ro- drigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[6]
Environment inference for invariant learning
Elliot Creager, J ¨orn-Henrik Jacobsen, and Richard Zemel. Environment inference for invariant learning. InInternational Confer- ence on Machine Learning (ICML), 2021
2021
-
[7]
Badhon, et al
Etienne David, Simon Madec, Pouria Sadeghi-Tehran, Helge Aasen, Bangyou Zheng, Shouyang Liu, Norbert Kirchgessner, Goro Ishikawa, Koichi Nagasawa, Min- hajul A. Badhon, et al. Global wheat head detection (gwhd) dataset: A large and di- verse dataset of high-resolution rgb-labelled images to develop and benchmark wheat head detection methods.Plant Phenomic...
2020
-
[8]
Failure modes of domain general- ization algorithms
Tigran Galstyan, Hrayr Harutyunyan, Hrant Khachatrian, Greg Ver Steeg, and Aram Gal- styan. Failure modes of domain general- ization algorithms. InProceedings of the 9 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[9]
In search of lost domain generalization
Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization. InIn- ternational Conference on Learning Represen- tations (ICLR), 2021
2021
-
[10]
On feature learning in the presence of spurious correla- tions
Pavel Izmailov, Polina Kirichenko, Nate Gru- ver, and Andrew Gordon Wilson. On feature learning in the presence of spurious correla- tions. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2022
2022
-
[11]
Large-scale video classifica- tion with convolutional neural networks
Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classifica- tion with convolutional neural networks. In Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2014
2014
-
[12]
Wilds: A benchmark of in-the-wild dis- tribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Mark- lund, Sang Michael Xie, Marvin Zhang, Ak- shay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild dis- tribution shifts. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[13]
Winning solution to the global wheat head detection challenge
ksnxr. Winning solution to the global wheat head detection challenge. https://github.com/ksnxr/GWC solution, 2020. GitHub repository. Accessed: 2026-01
2020
-
[14]
Duchi, and Aaron Sidford
Daniel Levy, Yair Carmon, John C. Duchi, and Aaron Sidford. Large-scale methods for distributionally robust optimization. InAd- vances in Neural Information Processing Sys- tems (NeurIPS), 2020
2020
-
[15]
Liu, Behzad Haghgoo, Annie S
Evan Z. Liu, Behzad Haghgoo, Annie S. Chen, Aditi Raghunathan, Pang Wei Koh, Sh- iori Sagawa, Percy Liang, and Chelsea Finn. Just train twice: Improving group robustness without training group information. InIn- ternational Conference on Machine Learning (ICML), 2021
2021
-
[16]
Hid- den stratification causes clinically meaning- ful failures in machine learning for medical imaging
Luke Oakden-Rayner, Jared Dunnmon, Gus- tavo Carneiro, and Christopher R ´e. Hid- den stratification causes clinically meaning- ful failures in machine learning for medical imaging. InProceedings of the ACM Con- ference on Health, Inference, and Learning (CHIL), 2020
2020
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haz- iza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual fea- tures without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Spatial validation reveals poor predictive performance of large-scale eco- logical mapping models.Nature Communi- cations, 11(1):4540, 2020
Pierre Ploton, Fr ´ed´eric Mortier, Maxime R´ejou-M´echain, Nicolas Barbier, Nicolas Pi- card, Vivien Rossi, Carsten Dormann, Guil- laume Cornu, Ga ¨elle Viennois, Nicolas Bayol, et al. Spatial validation reveals poor predictive performance of large-scale eco- logical mapping models.Nature Communi- cations, 11(1):4540, 2020
2020
-
[19]
Roberts, Volker Bahn, Simone Ciuti, Mark S
David R. Roberts, Volker Bahn, Simone Ciuti, Mark S. Boyce, Jane Elith, Gurutzeta Guillera-Arroita, Severin Hauenstein, Jos´e J. Lahoz-Monfort, Boris Schr ¨oder, Wilfried Thuiller, et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure.Ecography, 40(8): 913–929, 2017
2017
-
[20]
The risks of invariant risk minimization
Elan Rosenfeld, Pradeep Ravikumar, and An- drej Risteski. The risks of invariant risk minimization. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[21]
Hashimoto, and Percy Liang
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distribu- tionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. InInterna- tional Conference on Learning Representations (ICLR), 2020
2020
-
[22]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Doti- walla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[23]
Measuring robustness to natu- ral distribution shifts in image classification
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Lud- 10 wig Schmidt. Measuring robustness to natu- ral distribution shifts in image classification. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[24]
Antonio Torralba and Alexei A. Efros. Un- biased look at dataset bias. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011
2011
-
[25]
Open-set recognition: A good closed-set classifier is all you need? InInternational Conference on Learning Rep- resentations (ICLR), 2022
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisserman. Open-set recognition: A good closed-set classifier is all you need? InInternational Conference on Learning Rep- resentations (ICLR), 2022
2022
-
[26]
Alexandre M. J.-C. Wadoux, Gerard B. M. Heuvelink, Sytze de Bruin, and Dick J. Brus. Spatial cross-validation is not the right way to evaluate map accuracy.Ecological Mod- elling, 457:109692, 2021
2021
-
[27]
Examining and com- bating spurious features under distribution shift
Chunting Zhou, Xuezhe Ma, Paul Michel, and Graham Neubig. Examining and com- bating spurious features under distribution shift. InInternational Conference on Machine Learning (ICML), 2021
2021
-
[28]
Vision Meets Drones: A Challenge
Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Ling, and Qinghua Hu. Vision meets drones: A challenge.arXiv preprint arXiv:1804.07437, 2018. 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.