AbsoluteDegradation: A Physics-Inspired Synthetic Film-Degradation Pipeline and Archival Film Restoration Benchmark
Pith reviewed 2026-07-03 15:30 UTC · model grok-4.3
The pith
A physics-inspired modular pipeline for film degradations lets restoration models generalize better to real archival footage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
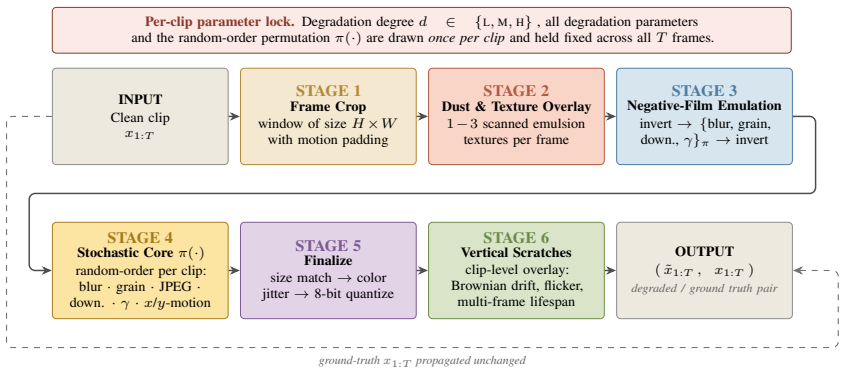
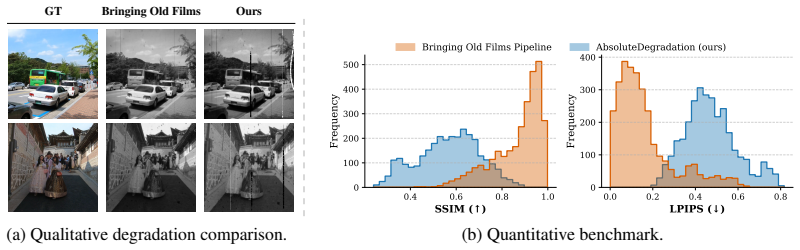
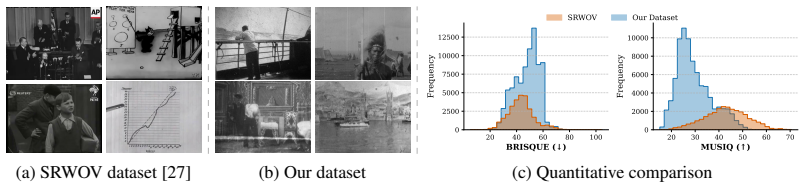
AbsoluteDegradation models the analog-to-digital process as a structured composition of artifact families that includes signal-dependent grain, parametric scratches, and temporally coherent camera motion. This composition supports controlled generation of diverse degradation regimes. When used for training, the resulting models generalize better to real-world archival footage. The accompanying benchmark of 81,576 curated high-resolution frames from real deteriorated film enables consistent evaluation and exposes failure modes that prior small or inaccessible datasets could not reveal.
What carries the argument
The AbsoluteDegradation pipeline, a modular composition of artifact families that models the analog-to-digital transition and generates controlled, temporally coherent degradations.
If this is right
- Models trained with the pipeline outperform prior synthetic-data approaches on real archival footage.
- The benchmark dataset supports standardized, reproducible comparison across restoration methods.
- Systematic failure modes of existing architectures become measurable under controlled real-world conditions.
- Controlled variation of individual artifact families allows targeted study of which degradations are hardest to restore.
- A unified training-and-evaluation framework reduces reliance on scarce paired real data.
Where Pith is reading between the lines
- The modular structure could be adapted to simulate degradations in other imaging domains that involve similar physical processes, such as old photographs or medical scans.
- Parameter sweeps over the artifact families might allow matching the pipeline to the specific characteristics of particular film stocks or eras.
- Adding explicit chemical or mechanical simulation steps for each artifact could further close the remaining gap to real footage.
- The benchmark could serve as a fixed test set for comparing restoration methods across independent research groups without data-access issues.
Load-bearing premise
The modular composition of separate artifact families accurately reproduces the complex, temporally coherent degradations present in real archival film.
What would settle it
An experiment in which models trained on AbsoluteDegradation show no improvement over models trained on earlier synthetic degradations when both are tested on the 81,576-frame real archival benchmark.
Figures







read the original abstract
Restoring archival film remains a fundamentally challenging problem due to the absence of paired training data and the lack of standardized evaluation benchmarks. Pristine versions of deteriorated footage are physically unrecoverable, requiring supervised methods to rely on synthetic data that often fail to capture the complex, temporally coherent nature of real film degradation. At the same time, existing real-world datasets are limited in scale, quality, and accessibility, hindering reliable evaluation and fair comparison across methods. We address both limitations with AbsoluteDegradation, a physics-inspired, modular pipeline for synthesizing realistic film degradations, and a new large-scale archival benchmark. The proposed pipeline models the analog-to-digital process as a structured composition of artifact families, incorporating signal-dependent grain, parametric scratches, and temporally coherent camera motion, enabling controlled generation of diverse degradation regimes. In parallel, we introduce a curated dataset of 81,576 high-resolution frames sourced from real archival footage, designed for consistent evaluation under real-world conditions. Together, these contributions provide a unified framework for training and benchmarking restoration models. Extensive experiments across multiple architectures show that models trained with AbsoluteDegradation generalize better to real-world footage, while the proposed benchmark reveals systematic failure modes of current methods. We hope this work establishes a foundation for reproducible and domain-authentic evaluation in archival film restoration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AbsoluteDegradation, a physics-inspired modular pipeline for synthesizing film degradations via composition of artifact families (signal-dependent grain, parametric scratches, temporally coherent camera motion) and a new benchmark of 81,576 high-resolution real archival frames. Experiments across architectures claim that training on the synthetic data yields improved generalization to real footage while the benchmark exposes systematic failure modes of existing methods.
Significance. If the synthetic pipeline's modular outputs are shown to match the joint statistics and temporal correlations of real archival degradations, the work would address the core paired-data scarcity problem and supply a large-scale, accessible benchmark for reproducible evaluation in archival film restoration. The controlled, physics-inspired generation of diverse regimes is a clear strength that could support systematic ablation studies.
major comments (2)
- [Abstract] Abstract: The central claim that models trained with AbsoluteDegradation generalize better to real-world footage is load-bearing on the unverified assumption that the modular artifact families reproduce the complex, temporally coherent degradations of real film; no quantitative distribution matching, statistical tests, or perceptual validation against real data is referenced.
- [Experiments] Experiments section: The reported generalization improvements lack controls (e.g., comparison against simpler synthetic baselines or ablations isolating higher-order interactions such as grain-scratch coupling under motion) that would isolate the contribution of pipeline fidelity from other factors such as data volume.
minor comments (2)
- [Abstract] The abstract would benefit from naming the specific architectures and loss functions used in the experiments to allow immediate assessment of the scope of the generalization results.
- Consider adding a supplementary table or figure that tabulates key pipeline parameters and their physical motivation for each artifact family.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in quantitative validation of the synthetic pipeline and in experimental controls. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that models trained with AbsoluteDegradation generalize better to real-world footage is load-bearing on the unverified assumption that the modular artifact families reproduce the complex, temporally coherent degradations of real film; no quantitative distribution matching, statistical tests, or perceptual validation against real data is referenced.
Authors: We acknowledge that the manuscript does not reference quantitative distribution matching, statistical tests, or perceptual validation of the synthetic degradations against real data. Validation in the current version rests on the physics-inspired modular design and qualitative visual results. We will add Fréchet Inception Distance (FID) comparisons between synthetic and real degraded frame distributions, along with statistical tests on artifact statistics and a small-scale perceptual study, to the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section: The reported generalization improvements lack controls (e.g., comparison against simpler synthetic baselines or ablations isolating higher-order interactions such as grain-scratch coupling under motion) that would isolate the contribution of pipeline fidelity from other factors such as data volume.
Authors: We agree that the reported gains would be more convincingly attributed to pipeline fidelity with additional controls. The current experiments compare AbsoluteDegradation-trained models against existing methods but omit direct baselines using simpler non-modular synthetics or ablations on coupled artifacts. In revision we will include (i) a simpler synthetic baseline with independent artifact addition and (ii) targeted ablations on grain-scratch-motion interactions, while controlling for training data volume. revision: yes
Circularity Check
No circularity: pipeline and benchmark are independently constructed
full rationale
The paper defines AbsoluteDegradation as an explicit modular composition of signal-dependent grain, parametric scratches, and temporally coherent motion, then evaluates generalization on a separate curated set of 81,576 real archival frames. No equation or claim reduces a prediction to a fitted parameter by construction, no self-citation is invoked as a uniqueness theorem, and the benchmark is external real footage rather than synthetic outputs. The derivation chain therefore remains self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
V . Bruni and D. Vitulano. A generalized model for scratch detection.IEEE Transactions on Image Processing, 13(1):44–50, 2004. doi: 10.1109/tip.2003.817231
-
[2]
K. C. Chan, X. Wang, K. Yu, C. Dong, and C. C. Loy. BasicVSR: The search for essential components in video super-resolution and beyond. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4947–4956, 2021
2021
-
[3]
K. C. Chan, S. Zhou, X. Xu, and C. C. Loy. BasicVSR++: Improving video super-resolution with enhanced propagation and alignment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5972–5981, 2022
2022
-
[4]
Chang, Y .-L
R.-C. Chang, Y .-L. Sie, S.-M. Chou, and T. K. Shih. Photo defect detection for image inpainting. InProceedings of the IEEE International Symposium on Multimedia (ISM), pages 403–407,
-
[5]
doi: 10.1109/ISM.2005.91
-
[6]
Claus and J
M. Claus and J. van Gemert. ViDeNN: Deep blind video denoising. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1843–1852, 2019
2019
-
[7]
J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei. Deformable convolutional networks. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 764–773, 2017
2017
-
[8]
DeTone, T
D. DeTone, T. Malisiewicz, and A. Rabinovich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018
2018
-
[9]
IEEE Transactions on Image Processing , year =
M. Elad and M. Aharon. Image denoising via sparse and redundant representations over learned dictionaries.IEEE Transactions on Image Processing, 15(12):3736–3745, 2006. doi: 10.1109/TIP.2006.881969
-
[10]
I. Giakoumis, N. Nikolaidis, and I. Pitas. Digital image processing techniques for the detection and removal of cracks in digitized paintings.IEEE Transactions on Image Processing, 15(1): 178–188, 2006. doi: 10.1109/TIP.2005.860311
-
[11]
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia. MambaIR: A simple baseline for image restoration with state-space model. InEuropean Conference on Computer Vision (ECCV), pages 222–241, 2024. doi: 10.1007/978-3-031-72649-1_13
-
[12]
H. Guo, Y . Guo, Y . Zha, Y . Zhang, W. Li, T. Dai, S.-T. Xia, and Y . Li. MambaIRv2: Attentive state space restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28124–28133, 2025
2025
-
[13]
Haris, G
M. Haris, G. Shakhnarovich, and N. Ukita. Recurrent back-projection network for video super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[14]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[15]
Z. Huang, X. Shi, C. Zhang, Q. Wang, K. C. Cheung, H. Qin, J. Dai, and H. Li. FlowFormer: A transformer architecture for optical flow. InEuropean Conference on Computer Vision (ECCV), pages 668–685, 2022. doi: 10.1007/978-3-031-19790-1_40
-
[16]
S. Iizuka and E. Simo-Serra. DeepRemaster: Temporal source-reference attention networks for comprehensive video enhancement.ACM Transactions on Graphics (TOG), 38(6):176:1– 176:13, 2019. doi: 10.1145/3355089.3356570
-
[17]
Ivanova, J
D. Ivanova, J. Williamson, and P. Henderson. Simulating analogue film damage to analyse and improve artefact restoration on high-resolution scans.Computer Graphics Forum, 42(2): 133–148, 2023. 11
2023
-
[18]
Johnson, A
J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super- resolution. InEuropean Conference on Computer Vision (ECCV), pages 694–711, 2016
2016
-
[19]
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang. MUSIQ: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5148–5157, 2021. doi: 10.1109/ICCV48922.2021.00510
-
[20]
D. Kim, S. Woo, J.-Y . Lee, and I. S. Kweon. Deep video inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5792–5801, 2019
2019
-
[21]
Lefkimmiatis
S. Lefkimmiatis. Universal denoising networks: A novel CNN architecture for image denoising. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3204–3213, 2018
2018
-
[22]
Liang, J
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte. SwinIR: Image restoration using swin transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1833–1844, 2021
2021
-
[23]
Liang, Y
J. Liang, Y . Fan, X. Xiang, R. Ranjan, E. Ilg, S. Green, J. Cao, K. Zhang, R. Timofte, and L. Van Gool. Recurrent video restoration transformer with guided deformable attention. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
2022
-
[24]
J. Liang, J. Cao, Y . Fan, K. Zhang, R. Ranjan, Y . Li, R. Timofte, and L. Van Gool. VRT: A video restoration transformer.IEEE Transactions on Image Processing, 33:2171–2182, 2024. doi: 10.1109/TIP.2024.3372454
-
[25]
Lin and E
S. Lin and E. Simo-Serra. Restoring degraded old films with recursive recurrent transformer networks. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6718–6728, 2024
2024
-
[26]
Lindenberger, P.-E
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys. Lightglue: Local feature matching at light speed. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17627–17638, October 2023
2023
-
[27]
Q. Liu, Y . Liu, L. Wang, F. Yan, Q. Zhang, and H. Ju. Restoration of archival film with large areas of structural damage.npj Heritage Science, 14:272, 2026. doi: 10.1038/s40494-025-02235-3
-
[28]
Y . Mao, H. Luo, Z. Zhong, P. Chen, Z. Zhang, and S. Wang. Making old film great again: Degradation-aware state space model for old film restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28039–28049, 2025. doi: 10.1109/CVPR52734.2025.02611
-
[29]
A. Mittal, A. K. Moorthy, and A. C. Bovik. No-reference image quality assessment in the spatial domain.IEEE Transactions on Image Processing, 21(12):4695–4708, 2012. doi: 10.1109/TIP.2012.2214050
-
[30]
S. Nah, S. Baik, S. Hong, G. Moon, S. Son, R. Timofte, and K. M. Lee. NTIRE 2019 challenge on video deblurring and super-resolution: Dataset and study. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1996– 2005, 2019
2019
-
[31]
B. T. Oh, S.-m. Lei, and C.-C. J. Kuo. Advanced film grain noise extraction and synthesis for high-definition video coding.IEEE Transactions on Circuits and Systems for Video Technology, 19(12):1717–1728, 2009. doi: 10.1109/TCSVT.2009.2026974
-
[32]
Ranjan and M
A. Ranjan and M. J. Black. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4161– 4170, 2017
2017
-
[33]
Salmona, L
A. Salmona, L. Bouza, and J. Delon. DeOldify: A review and implementation of an automatic colorization method.Image Processing On Line (IPOL), 12:347–368, 2022. 12
2022
-
[34]
M. Seitzer. pytorch-fid: FID Score for PyTorch. https://github.com/mseitzer/ pytorch-fid, August 2020. Version 0.3.0
2020
-
[35]
F. Stanco, G. Ramponi, and A. De Polo. Towards the automated restoration of old photographic prints: A survey. InIEEE Region 8 EUROCON 2003: Computer as a Tool, volume B, pages 370–374, 2003. doi: 10.1109/EURCON.2003.1248221
-
[36]
Stephenson and A
I. Stephenson and A. Saunders. Simulating film grain using the noise-power spectrum. In Theory and Practice of Computer Graphics (TPCG). Eurographics Association, 2007
2007
-
[37]
S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang. Deep video deblurring for hand-held cameras. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1279–1288, 2017
2017
-
[38]
Suganuma, X
M. Suganuma, X. Liu, and T. Okatani. Attention-based adaptive selection of operations for image restoration in the presence of unknown combined distortions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[39]
J. Sun, W. Cao, Z. Xu, and J. Ponce. Learning a convolutional neural network for non-uniform motion blur removal. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 769–777, 2015. doi: 10.1109/CVPR.2015.7298677
-
[40]
Suvorov, E
R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V . Lempitsky. Resolution-robust large mask inpainting with Fourier convolutions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2149–2159, 2022
2022
-
[41]
Szegedy, V
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception archi- tecture for computer vision. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[42]
Tassano, J
M. Tassano, J. Delon, and T. Veit. FastDVDnet: Towards real-time deep video denoising without flow estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1354–1363, 2020
2020
-
[43]
Teed and J
Z. Teed and J. Deng. RAFT: Recurrent all-pairs field transforms for optical flow. InEuropean Conference on Computer Vision (ECCV), pages 402–419, 2020
2020
-
[44]
R. A. Ulichney. Dithering with blue noise.Proceedings of the IEEE, 76(1):56–79, 1988. doi: 10.1109/5.3288
-
[45]
Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, and F. Wen. Bringing old photos back to life. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2747–2757, 2020
2020
-
[46]
Z. Wan, B. Zhang, D. Chen, and J. Liao. Bringing old films back to life. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17694–17703, 2022. doi: 10.1109/CVPR52688.2022.01717
-
[47]
J. Wang, K. C. Chan, and C. C. Loy. Exploring CLIP for assessing the look and feel of images. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 2555–2563,
-
[48]
doi: 10.1609/aaai.v37i2.25353
-
[49]
X. Wang, K. C. Chan, K. Yu, C. Dong, and C. C. Loy. EDVR: Video restoration with enhanced deformable convolutional networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1954–1963, 2019
1954
-
[50]
X. Wang, L. Xie, C. Dong, and Y . Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF International Conference on Com- puter Vision Workshops (ICCVW), pages 1905–1914, 2021. doi: 10.1109/ICCVW54120.2021. 00217
-
[51]
Y . Weiss and W. T. Freeman. What makes a good model of natural images? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2007. doi: 10.1109/CVPR.2007.383092. 13
-
[52]
L. Xu, J. S. Ren, C. Liu, and J. Jia. Deep convolutional neural network for image deconvolution. InAdvances in Neural Information Processing Systems (NeurIPS), volume 27, 2014
2014
-
[53]
R. Xu, X. Li, B. Zhou, and C. C. Loy. Deep flow-guided video inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3723–3732, 2019
2019
-
[54]
S. Yang, T. Wu, S. Shi, S. Lao, Y . Gong, M. Cao, J. Wang, and Y . Yang. MANIQA: Multi- dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1191–1200, 2022. doi: 10.1109/CVPRW56347.2022.00126
-
[55]
G. Youk, J. Oh, and M. Kim. FMA-Net: Flow-guided dynamic filtering and iterative feature refinement with multi-attention for joint video super-resolution and deblurring. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 44–55, 2024
2024
-
[56]
J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang. Free-form image inpainting with gated convolution. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4471–4480, 2019
2019
-
[57]
K. Yu, C. Dong, L. Lin, and C. C. Loy. Crafting a toolchain for image restoration by deep reinforcement learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2443–2452, 2018
2018
-
[58]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.-H. Yang. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5728–5739, 2022
2022
-
[59]
Zhang, Y
H. Zhang, Y . Wu, and Z. Kuang. An efficient scratches detection and inpainting algorithm for old film restoration. In2009 International Conference on Information Technology and Computer Science (ITCS), volume 1, pages 75–78. IEEE, 2009
2009
-
[60]
IEEE Transactions on Image Processing , year =
K. Zhang, W. Zuo, Y . Chen, D. Meng, and L. Zhang. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising.IEEE Transactions on Image Processing, 26(7): 3142–3155, 2017. doi: 10.1109/TIP.2017.2662206
-
[61]
K. Zhang, W. Zuo, and L. Zhang. FFDNet: Toward a fast and flexible solution for CNN-based image denoising.IEEE Transactions on Image Processing, 27(9):4608–4622, 2018. doi: 10.1109/TIP.2018.2839891
-
[62]
Zhang, J
K. Zhang, J. Liang, L. Van Gool, and R. Timofte. Designing a practical degradation model for deep blind image super-resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4791–4800, 2021
2021
-
[63]
H. Zhao, L. Tian, X. Xiao, P. Hu, Y . Gou, and X. Peng. AverNet: All-in-one video restoration for time-varying unknown degradations. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
2024
-
[64]
out of memory
K. Zhou, W. Li, L. Lu, X. Han, and J. Lu. Revisiting temporal alignment for video restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6053–6062, 2022. 14 A Related Work A.1 Restoration Methods: From Images to Video Image restoration has evolved from model-based priors over natural image statistics...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.