Adversarial Regularization for Visual Question Answering: Strengths, Shortcomings, and Side Effects
Pith reviewed 2026-05-25 20:08 UTC · model grok-4.3
The pith
Adversarial regularization reduces language bias in VQA models but produces unstable gradients and sharply lower accuracy on standard data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
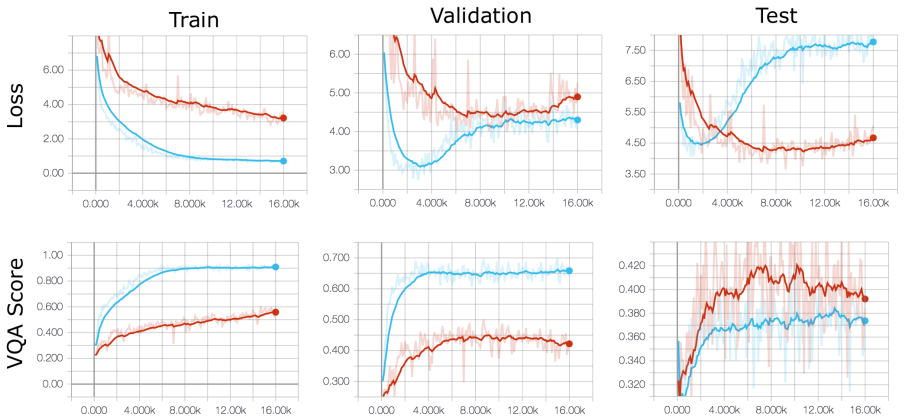
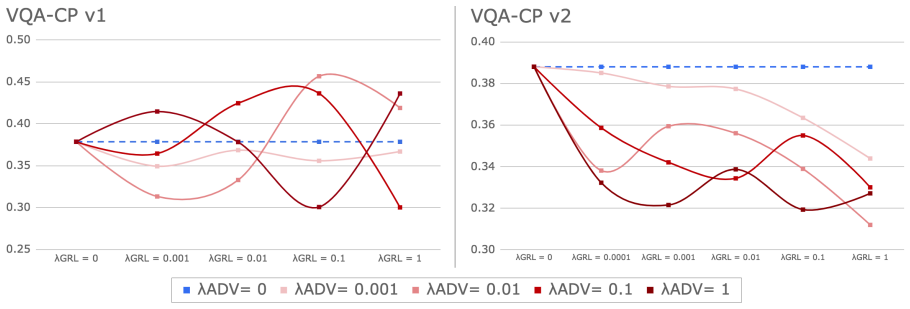
Adversarial regularization encourages bias-free question representations via an adversary sub-network. On VQA-CP it reaches state-of-the-art, yet produces unstable gradients, sharply lower in-domain accuracy, better binary-question generalization but worse results on heterogeneous answer distributions, and a tendency to ignore linguistic cues in favor of visual features. Gradual introduction of the regularizer lessens but does not eliminate the side effects.
What carries the argument
An adversary sub-network that penalizes the main model for learning bias-prone representations of the question.
If this is right
- Regularized models generalize better on binary questions but worse on questions with heterogeneous answer distributions.
- Training gradients become markedly less stable.
- Accuracy falls sharply on standard in-domain test sets.
- Models shift toward over-reliance on visual features while discarding helpful linguistic information in the question.
- Gradual ramp-up of regularization strength reduces but does not remove the side effects.
Where Pith is reading between the lines
- The same training schedule without the adversary could be run to isolate whether the side effects truly require the adversarial term.
- The pattern of improved binary-question performance and degraded heterogeneous-answer performance may appear in other bias-mitigation methods that alter representation balance.
- Refinements could combine the adversary with an auxiliary term that preserves selected linguistic features.
- The observed visual over-reliance suggests testing whether the same regularization harms performance on tasks where language cues are the dominant signal.
Load-bearing premise
The observed performance drops on in-domain data and the over-reliance on visual features are caused by the adversarial component itself rather than by other training choices such as learning-rate schedules or the gradual ramp-up of regularization strength.
What would settle it
Retrain the identical VQA model with the same learning-rate schedule and ramp-up schedule but without the adversary sub-network, then measure whether in-domain accuracy still falls and visual over-reliance still appears.
Figures






read the original abstract
Visual question answering (VQA) models have been shown to over-rely on linguistic biases in VQA datasets, answering questions "blindly" without considering visual context. Adversarial regularization (AdvReg) aims to address this issue via an adversary sub-network that encourages the main model to learn a bias-free representation of the question. In this work, we investigate the strengths and shortcomings of AdvReg with the goal of better understanding how it affects inference in VQA models. Despite achieving a new state-of-the-art on VQA-CP, we find that AdvReg yields several undesirable side-effects, including unstable gradients and sharply reduced performance on in-domain examples. We demonstrate that gradual introduction of regularization during training helps to alleviate, but not completely solve, these issues. Through error analyses, we observe that AdvReg improves generalization to binary questions, but impairs performance on questions with heterogeneous answer distributions. Qualitatively, we also find that regularized models tend to over-rely on visual features, while ignoring important linguistic cues in the question. Our results suggest that AdvReg requires further refinement before it can be considered a viable bias mitigation technique for VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates adversarial regularization (AdvReg) as a technique to mitigate linguistic biases in VQA models. It reports that AdvReg achieves a new state-of-the-art on VQA-CP while also producing side-effects including unstable gradients and sharply reduced in-domain accuracy; gradual ramp-up of the regularization strength partially alleviates but does not eliminate these issues. Error analyses show gains on binary questions but losses on questions with heterogeneous answer distributions, and qualitative inspection indicates over-reliance on visual features at the expense of linguistic cues.
Significance. If the causal attribution of the reported side-effects holds, the work is significant for the VQA bias-mitigation literature: it supplies a detailed empirical map of AdvReg's effects on training dynamics, in-domain vs. out-of-domain generalization, and question-type-specific performance. The observation that a bias-mitigation method can induce over-reliance on the opposite modality is a useful cautionary finding.
major comments (2)
- [§4] §4 and training-details appendix: the central claim that AdvReg produces unstable gradients and sharply reduced in-domain accuracy rests on the assumption that these phenomena are caused by the adversarial term. No control runs are reported that apply the identical learning-rate schedule, ramp-up schedule, and optimizer to a non-adversarial baseline. Without such matched ablations the observed degradation could be produced by the altered optimization trajectory rather than by the adversary sub-network itself.
- [Abstract] Abstract and §4: the manuscript states experimental outcomes (unstable gradients, performance drops) but supplies no details on statistical tests, number of random seeds, or variance across runs. This weakens the reliability of the side-effect claims.
minor comments (2)
- [training details] The description of how gradient instability was quantified (e.g., gradient-norm statistics, frequency of NaNs) should be added to the training-details section for reproducibility.
- Table or figure captions should explicitly state whether reported accuracies are means over multiple seeds or single-run results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 and training-details appendix: the central claim that AdvReg produces unstable gradients and sharply reduced in-domain accuracy rests on the assumption that these phenomena are caused by the adversarial term. No control runs are reported that apply the identical learning-rate schedule, ramp-up schedule, and optimizer to a non-adversarial baseline. Without such matched ablations the observed degradation could be produced by the altered optimization trajectory rather than by the adversary sub-network itself.
Authors: We agree that the manuscript lacks explicit matched control experiments that apply the same learning-rate schedule, ramp-up, and optimizer to a non-adversarial baseline. Our existing comparisons used standard baseline training procedures, which leaves open the possibility that some observed effects stem from optimization differences rather than the adversary itself. We will add these control runs to the revised manuscript to strengthen the causal attribution of the side-effects. revision: yes
-
Referee: [Abstract] Abstract and §4: the manuscript states experimental outcomes (unstable gradients, performance drops) but supplies no details on statistical tests, number of random seeds, or variance across runs. This weakens the reliability of the side-effect claims.
Authors: The current results are reported from single runs without variance estimates, multiple seeds, or statistical tests. This is a genuine limitation that reduces the strength of the side-effect claims. We will rerun the key experiments with multiple random seeds, report means and standard deviations, and include statistical significance information where appropriate in the revised version. revision: yes
Circularity Check
No circularity: purely empirical study with no derivation chain
full rationale
The paper is an empirical investigation reporting observed effects of AdvReg on VQA models via performance metrics, gradient behavior, error analyses, and qualitative examples. No mathematical derivations, first-principles predictions, or parameter fittings are claimed; all results stem from direct experimental comparisons. No steps match the enumerated circularity patterns, as there are no self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations that reduce claims to inputs by construction. The work is self-contained as an experimental report.
Axiom & Free-Parameter Ledger
free parameters (1)
- adversary regularization coefficient
axioms (1)
- domain assumption An adversary sub-network can be trained to detect and penalize reliance on linguistic shortcuts in the question encoder.
Reference graph
Works this paper leans on
-
[1]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. 2016. Analyzing the Behavior of Visual Question Answering Models . In EMNLP, pages 1955--1960
work page 2016
-
[4]
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. 2018. Don't Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering . In CVPR, pages 4971--4980
work page 2018
-
[5]
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. 2018. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering . In CVPR, volume 3, page 6
work page 2018
-
[6]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. 2015. VQA: Visual Question Answering . In ICCV , pages 2425--2433
work page 2015
-
[7]
Shieber, Benjamin Van Durme, and Alexander Rush
Yonatan Belinkov, Adam Poliak, Stuart M. Shieber, Benjamin Van Durme, and Alexander Rush. 2019. On Adversarial Removal of Hypothesis-only Bias in Natural Language Inference . In The Eighth Joint Conference on Lexical and Computational Semantics (*SEM)
work page 2019
-
[8]
Wei-Lun Chao, Hexiang Hu, and Fei Sha. 2018. Being Negative but Constructively: Lessons Learnt from Creating Better Visual Question Answering Datasets . In NAACL-HLT, volume 1, pages 431--441
work page 2018
-
[9]
Prithvijit Chattopadhyay, Ramakrishna Vedantam, Ramprasaath R Selvaraju, Dhruv Batra, and Devi Parikh. 2017. Counting Everyday Objects in Everyday Scenes . In CVPR, pages 1135--1144
work page 2017
-
[10]
Carsten Eickhoff. 2018. Cognitive Biases in Crowdsourcing . In WSDM, pages 162--170. ACM
work page 2018
-
[11]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, Fran c ois Laviolette, Mario Marchand, and Victor Lempitsky. 2016. Domain-Adversarial Training of Neural Networks . JMLR, 17(1):2096--2030
work page 2016
-
[12]
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2017. Making the V in VQA matter: Elevating the Role of Image Understanding in Visual Question Answering . In CVPR, pages 6904--6913
work page 2017
-
[13]
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. 2018. http://www.aclweb.org/anthology/N18-2017 Annotation Artifacts in Natural Language Inference Data . In NAACL-HLT, pages 107--112, New Orleans, Louisiana. Association for Computational Linguistics
work page 2018
-
[14]
Lisa Anne Hendricks, Kaylee Burns, Kate Saenko, Trevor Darrell, and Anna Rohrbach. 2018. Women also Snowboard: Overcoming Bias in Captioning Models . In ECCV, pages 771--787
work page 2018
-
[15]
Allan Jabri, Armand Joulin, and Laurens van der Maaten. 2016. Revisiting Visual Question Answering Baselines . In ECCV , pages 727--739. Springer
work page 2016
-
[16]
Yu Jiang, Vivek Natarajan, Xinlei Chen, Marcus Rohrbach, Dhruv Batra, and Devi Parikh. 2018 a . Pythia. https://github.com/facebookresearch/pythia
work page 2018
-
[17]
Yu Jiang, Vivek Natarajan, Xinlei Chen, Marcus Rohrbach, Dhruv Batra, and Devi Parikh. 2018 b . Pythia v0.1: The Winning Entry to the VQA Challenge 2018 . arXiv preprint arXiv:1807.09956
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. 2017. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning . In CVPR, pages 1988--1997. IEEE
work page 2017
-
[19]
Divyansh Kaushik and Zachary C. Lipton. 2018. http://www.aclweb.org/anthology/D18-1546 How Much Reading Does Reading Comprehension Require? A Critical Investigation of Popular Benchmarks . In EMNLP, pages 5010--5015, Brussels, Belgium. ACL
work page 2018
-
[20]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \'a r, and C Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context . In ECCV , pages 740--755. Springer
work page 2014
-
[21]
Emiel van Miltenburg. 2016. Stereotyping and Bias in the Flickr30k Dataset . arXiv preprint arXiv:1605.06083
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Ishan Misra, C Lawrence Zitnick, Margaret Mitchell, and Ross Girshick. 2016. Seeing Through the Human Reporting Bias: Visual Classifiers from Noisy Human-Centric Labels . In CVPR, pages 2930--2939
work page 2016
-
[23]
Adam Poliak, Jason Naradowsky, Aparajita Haldar, Rachel Rudinger, and Benjamin Van Durme. 2018. http://www.aclweb.org/anthology/S18-2023 Hypothesis Only Baselines in Natural Language Inference . In *SEM, pages 180--191, New Orleans, Louisiana. ACL
work page 2018
-
[24]
Sainandan Ramakrishnan, Aishwarya Agrawal, and Stefan Lee. 2018. Overcoming Language Priors in Visual Question Answering with Adversarial Regularization . In NIPS, pages 1548--1558
work page 2018
-
[25]
Roy Schwartz, Maarten Sap, Ioannis Konstas, Leila Zilles, Yejin Choi, and Noah A. Smith. 2017. Story Cloze Task: UW NLP System . In LSDSem
work page 2017
-
[26]
Damien Teney, Peter Anderson, Xiaodong He, and Anton van den Hengel. 2018. Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge . In CVPR, pages 4223--4232
work page 2018
-
[27]
Jesse Thomason, Daniel Gordon, and Yonatan Bisk. 2019. Shifting the baseline: Single modality performance on visual navigation & qa. In Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
work page 2019
-
[28]
Alexander Trott, Caiming Xiong, and Richard Socher. 2018. https://openreview.net/forum?id=S1J2ZyZ0Z Interpretable Counting for Visual Question Answering . In ICLR
work page 2018
-
[29]
Masatoshi Tsuchiya. 2018. Performance Impact Caused by Hidden Bias of Training Data for Recognizing Textual Entailment . In LREC
work page 2018
-
[30]
Peng Zhang, Yash Goyal, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. 2016. Yin and Yang: Balancing and Answering Binary Visual Questions . In CVPR, pages 5014--5022. IEEE
work page 2016
-
[31]
Yan Zhang, Jonathon Hare, and Adam Prügel-Bennett. 2018. https://openreview.net/forum?id=B12Js_yRb Learning to Count Objects in Natural Images for Visual Question Answering . In ICLR
work page 2018
-
[32]
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. 2017. Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints . In EMNLP
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.