A Study of State Aliasing in Structured Prediction with RNNs
Pith reviewed 2026-05-25 18:38 UTC · model grok-4.3
The pith
Recurrent neural networks trained with policy gradient often fail to learn distinct state representations when multiple states share the same optimal action.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
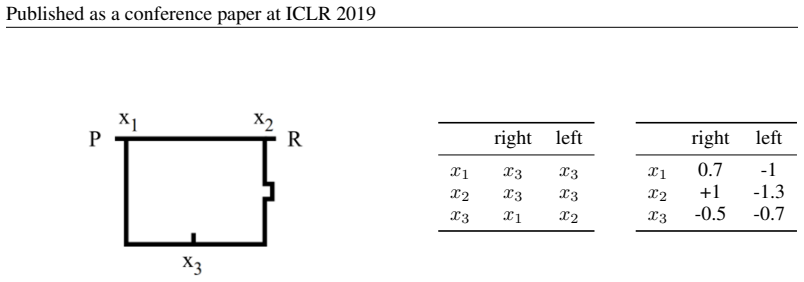
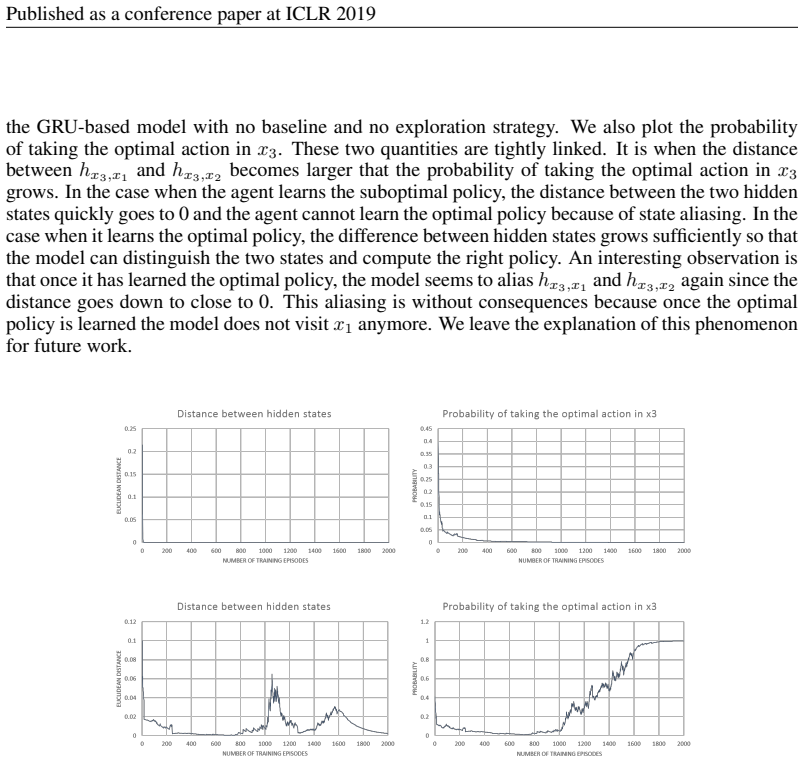
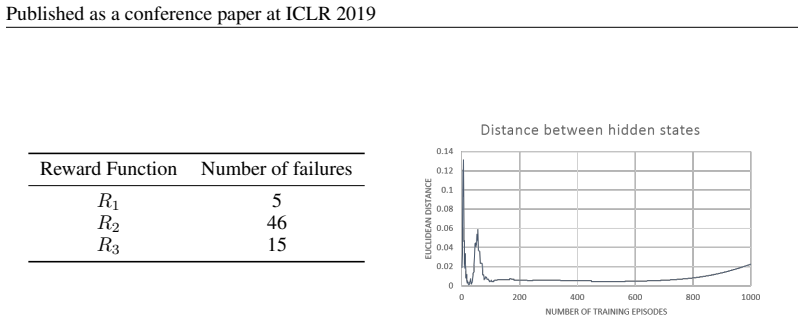
The authors demonstrate through experiments that state aliasing, the conflation of two or more distinct states in the representation space, occurs when several states share the same optimal action and the agent is trained via policy gradient. This produces RNN agents that fail to learn state representations leading to an optimal policy. The paper characterizes the phenomenon in a maze setting and a text-based game and contrasts it with value-based training.
What carries the argument
State aliasing, the conflation of distinct states in the representation space that occurs when those states share an optimal action under policy gradient training.
If this is right
- Policy gradient methods produce suboptimal policies for RNN agents in any environment where the same action is optimal at multiple distinct states.
- Value-based methods avoid the state aliasing that policy gradient induces in these settings.
- Training recommendations can be made to select or modify methods when RNNs are used for reinforcement learning in structured prediction.
- The aliasing effect can be reproduced and measured in both minimal maze tasks and richer text-game environments.
Where Pith is reading between the lines
- The same aliasing pattern could appear in other recurrent sequence tasks that involve repeated actions across different contexts.
- Auxiliary objectives that encourage state discrimination might reduce aliasing even under policy gradient training.
- The findings point toward preferring value-based updates when the task structure features repeated optimal actions.
Load-bearing premise
The observed failure in the maze and text-game experiments stems specifically from the interaction of policy gradient with shared optimal actions rather than other aspects of the RNN or training procedure.
What would settle it
An experiment in which an RNN trained with policy gradient on a task with repeated optimal actions across states nevertheless learns distinct representations for those states and reaches the optimal policy would falsify the central claim.
Figures
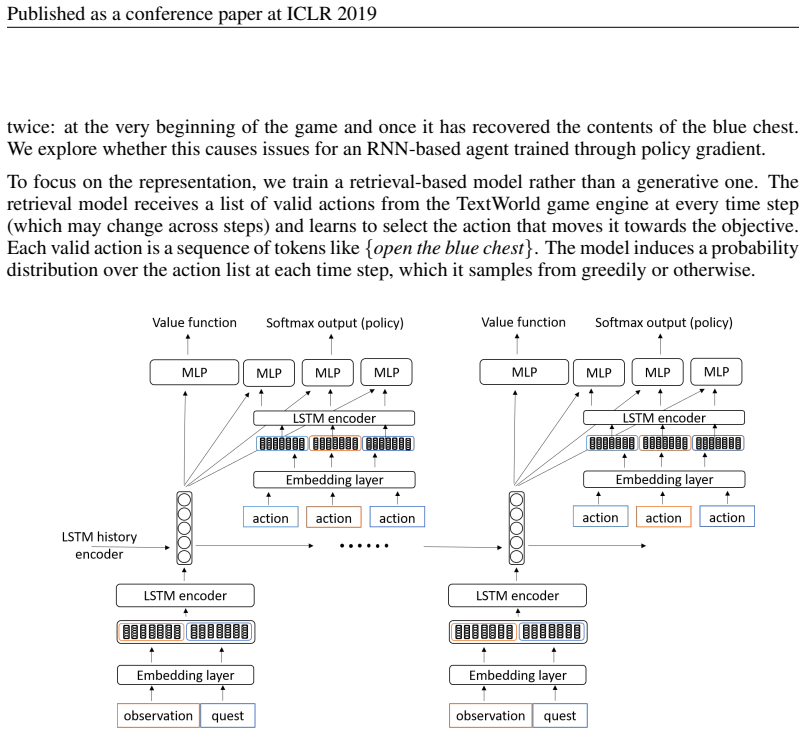
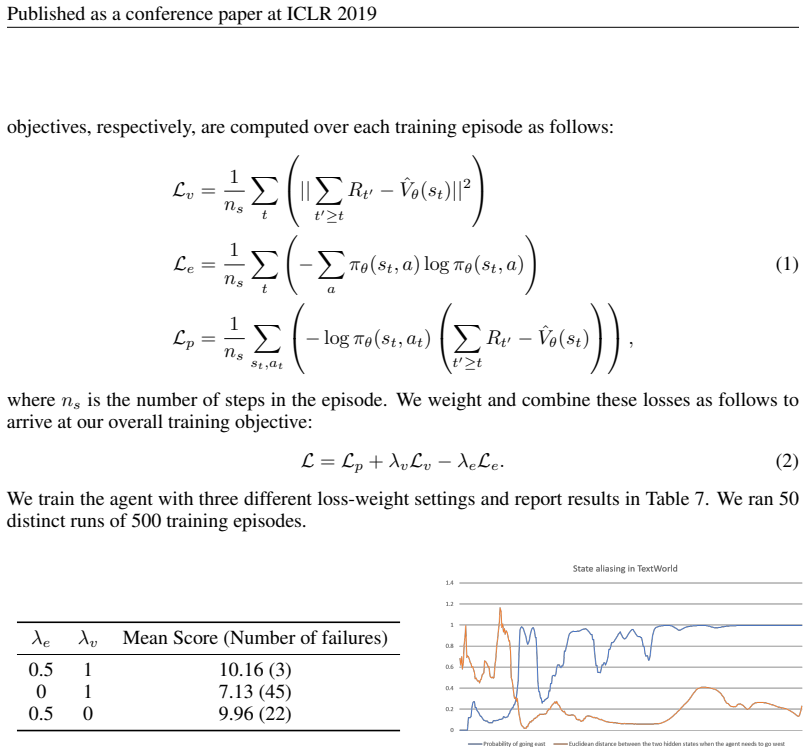
read the original abstract
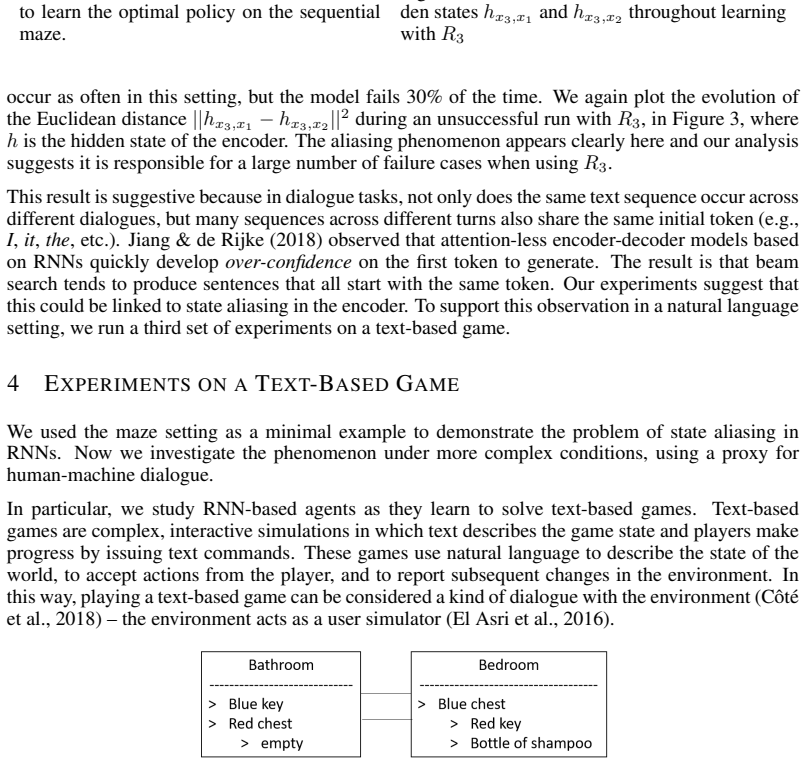
End-to-end reinforcement learning agents learn a state representation and a policy at the same time. Recurrent neural networks (RNNs) have been trained successfully as reinforcement learning agents in settings like dialogue that require structured prediction. In this paper, we investigate the representations learned by RNN-based agents when trained with both policy gradient and value-based methods. We show through extensive experiments and analysis that, when trained with policy gradient, recurrent neural networks often fail to learn a state representation that leads to an optimal policy in settings where the same action should be taken at different states. To explain this failure, we highlight the problem of state aliasing, which entails conflating two or more distinct states in the representation space. We demonstrate that state aliasing occurs when several states share the same optimal action and the agent is trained via policy gradient. We characterize this phenomenon through experiments on a simple maze setting and a more complex text-based game, and make recommendations for training RNNs with reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RNN-based RL agents trained with policy gradient methods often fail to learn distinct state representations when different states require the same optimal action, resulting in state aliasing and suboptimal policies. This is shown through experiments on a maze setting and a text-based game, where policy gradient leads to suboptimal policies unlike value-based methods. The work provides analysis and recommendations for training such agents.
Significance. If the findings hold, this empirical study is significant for understanding limitations in training RNNs with policy gradients in structured prediction tasks common in dialogue and similar domains. By contrasting with value-based methods and using both simple and complex environments, it offers practical insights. The identification of state aliasing as a specific issue when optimal actions are shared is a useful contribution.
minor comments (2)
- The abstract mentions 'extensive experiments and analysis' but does not summarize any specific quantitative results, metrics, or performance numbers; including a brief mention of key findings would improve clarity for readers.
- Experimental figures and tables should report results over multiple random seeds with error bars or standard deviations to allow assessment of variability and robustness of the observed state aliasing effect.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and recommendation for minor revision. The summary correctly captures the core claim that policy-gradient training of RNN agents leads to state aliasing when multiple states share the same optimal action, in contrast to value-based methods, with supporting experiments in both simple and complex environments.
Circularity Check
No significant circularity
full rationale
This is an empirical study whose central claims rest on experimental comparisons between policy-gradient and value-based training of RNN agents in maze and text-game environments. No derivations, first-principles predictions, or fitted parameters are presented that could reduce to their own inputs by construction. The reported failure mode (state aliasing under shared optimal actions) is characterized directly from observed outcomes rather than from any self-referential definition or self-citation chain. The work therefore contains no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
An Actor - Critic Algorithm for Sequence Prediction
Dzmitry Bahdanau, Philemon Brakel, Kelvin Xu, Anirudh Goyal, Ryan Lowe, Joelle Pineau, Aaron Courville, and Yoshua Bengio. An Actor - Critic Algorithm for Sequence Prediction . In Proceedings of the International Conference on Learning Representations, 2017
work page 2017
-
[3]
Kyunghyun Cho, Bart van Merri \" e nboer, C ağlar G \" u l c ehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder--decoder for statistical machine translation. In In Proceedings of Empirical Methods in Natural Language Processing, 2014
work page 2014
-
[4]
Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew J
Marc-Alexandre C \^o t \'e , \'A kos K \'a d \'a r, Xingdi Yuan, Ben A. Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew J. Hausknecht, Layla El Asri, Mahmoud Adada, Wendy Tay, and Adam Trischler. Textworld: A learning environment for text-based games. In Proceedings of the Computer Games Workshop at ICML/IJCAI, 2018
work page 2018
-
[5]
Abhishek Das, Satwik Kottur, Jos \'e M. F. Moura, Stefan Lee, and Dhruv Batra. Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning . In Proceedings of the International Conference on Computer Vision, 2017
work page 2017
-
[6]
A sequence-to-sequence model for user simulation in spoken dialogue systems
Layla El Asri, Jing He, and Kaheer Suleman. A sequence-to-sequence model for user simulation in spoken dialogue systems. In Proceedings of Interspeech, 2016
work page 2016
-
[7]
Deep reinforcement learning with a natural language action space
Ji He, Jianshu Chen, Xiaodong He, Jianfeng Gao, Lihong Li, Li Deng, and Mari Ostendorf. Deep reinforcement learning with a natural language action space. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016
work page 2016
-
[8]
Sepp Hochreiter and J\" u rgen Schmidhuber. Long short-term memory. Neural Computation, 9 0 (8): 0 1735--1780, 1997
work page 1997
-
[9]
Why are sequence-to-sequence models so dull? understanding the low-diversity problem of chatbots
Shaojie Jiang and Maarten de Rijke. Why are sequence-to-sequence models so dull? understanding the low-diversity problem of chatbots. In Proceedings of the EMNLP Search-Oriented Conversational AI Workshop, 2018
work page 2018
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
Deep Reinforcement Learning for Dialogue Generation
Jiwei Li, Will Monroe, Alan Ritter, Michel Galley, Jianfeng Gao, and Dan Jurafsky. Deep Reinforcement Learning for Dialogue Generation . In Proceeding of the Conference on Empirical Methods on Natural Language Processing, 2016
work page 2016
-
[12]
Reinforcement Learning with Selective Perception and Hidden State
Andrew Kachites McCallum. Reinforcement Learning with Selective Perception and Hidden State. PhD thesis, 1996
work page 1996
- [13]
-
[14]
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Ranking sentences for extractive summarization with reinforcement learning. In Proceedings of the North American Chapter of the Annual Conference of the Association for Computational Linguistics, 2018
work page 2018
-
[15]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the Annual Conference of the Association for Computational Linguistics, 2002
work page 2002
-
[16]
Sequence Level Training with Recurrent Neural Networks
Marc'Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Zaremba. Sequence Level Training with Recurrent Neural Networks . In Proceedings of the International Conference on Learning Representations, 2016
work page 2016
-
[17]
End-to-end optimization of goal-driven and visually grounded dialogue systems
Florian Strub, Harm de Vries, Jeremie Mary, Bilal Piot, Aaron Courville, and Olivier Pietquin. End-to-end optimization of goal-driven and visually grounded dialogue systems. In Proceedings of the International Joint Conference on Artificial Intelligence, 2017
work page 2017
-
[18]
T. Tieleman and G. Hinton. Lecture 6.5---RmsProp: Divide the gradient by a running average of its recent magnitude . COURSERA: Neural Networks for Machine Learning, 2012
work page 2012
- [19]
-
[20]
L. Wu , F. Tian , T. Qin , J. Lai , and T.-Y. Liu . A study of reinforcement learning for neural machine translation. In Proceeding of the Conference on Empirical Methods on Natural Language Processing, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.