Incremental Concept Learning via Online Generative Memory Recall
Pith reviewed 2026-05-25 01:58 UTC · model grok-4.3
The pith
A conditional GAN generates pseudo-samples of old concepts to prevent catastrophic forgetting during incremental class learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
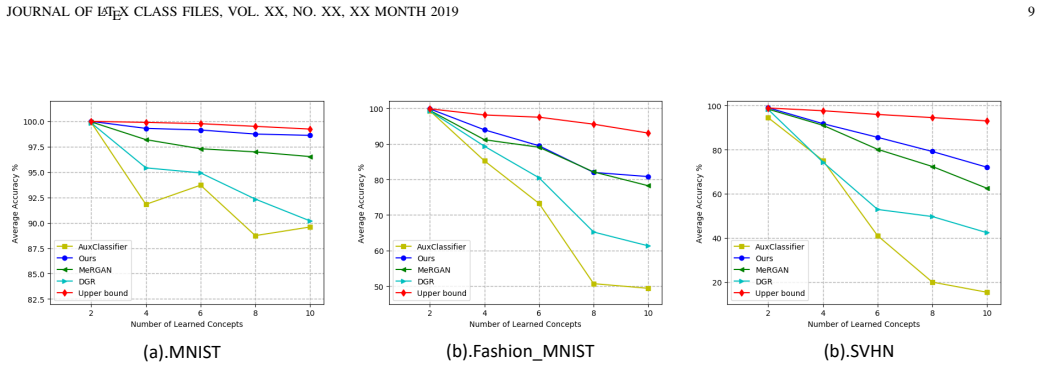
The central claim is that a conditional GAN can consolidate memory of old concepts by generating pseudo-samples, which are then used in a balanced online recall strategy together with a concept contrastive loss; this combination allows a neural network to learn new classes incrementally on MNIST, Fashion-MNIST, and SVHN while keeping performance on earlier classes high.
What carries the argument
The conditional generative adversarial network that produces pseudo-samples of past classes, combined with the balanced online memory recall strategy and the concept contrastive loss that limits weight drift.
If this is right
- Networks can add new classes sequentially while retaining accuracy on all previous classes without storing the original training data.
- The balanced recall strategy keeps the influence of old and new classes roughly equal during each training step.
- The concept contrastive loss reduces the magnitude of weight updates that would otherwise overwrite earlier concepts.
- The method shows measurable gains over other rehearsal baselines on the three evaluated image datasets.
Where Pith is reading between the lines
- If better conditional GANs become available, the same rehearsal idea could be tested on higher-resolution or more diverse image sets where distribution matching is harder.
- The pseudo-sample approach could be combined with parameter-isolation methods to further reduce interference between tasks.
- Memory savings from not storing raw past data would become more valuable as the number of incremental steps grows.
Load-bearing premise
The conditional GAN, trained only on the small set of past data available at each step, produces pseudo-samples whose distribution is close enough to the true old data that rehearsal on them stops forgetting without creating new biases.
What would settle it
Measure accuracy on old classes after incremental training using only the GAN-generated samples versus using the real old samples; if the gap is large and forgetting remains severe with the generated samples, the approach fails.
Figures






read the original abstract
The ability to learn more and more concepts over time from incrementally arriving data is essential for the development of a life-long learning system. However, deep neural networks often suffer from forgetting previously learned concepts when continually learning new concepts, which is known as catastrophic forgetting problem. The main reason for catastrophic forgetting is that the past concept data is not available and neural weights are changed during incrementally learning new concepts. In this paper, we propose a pseudo-rehearsal based class incremental learning approach to make neural networks capable of continually learning new concepts. We use a conditional generative adversarial network to consolidate old concepts memory and recall pseudo samples during learning new concepts and a balanced online memory recall strategy is to maximally maintain old memories. And we design a comprehensible incremental concept learning network as well as a concept contrastive loss to alleviate the magnitude of neural weights change. We evaluate the proposed approach on MNIST, Fashion-MNIST and SVHN datasets and compare with other rehearsal based approaches. The extensive experiments demonstrate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a pseudo-rehearsal approach for class-incremental learning that trains a conditional GAN on past data to generate pseudo-samples, employs a balanced online memory recall strategy during new-concept training, and introduces a concept contrastive loss within an incremental concept learning network to reduce catastrophic forgetting. Effectiveness is demonstrated via comparative experiments against other rehearsal-based methods on the MNIST, Fashion-MNIST, and SVHN datasets.
Significance. If the cGAN pseudo-samples faithfully approximate old-concept distributions, the method would provide a storage-efficient alternative to exemplar rehearsal for continual learning. The empirical comparisons on three standard benchmarks constitute a concrete contribution, but the absence of direct fidelity metrics or ablations leaves the practical significance dependent on unverified assumptions about sample quality.
major comments (2)
- [Experiments] The central claim (abstract and §3) that rehearsal on cGAN pseudo-samples prevents forgetting requires the generated distribution to remain close to the true old-concept distribution. No quantitative validation—such as FID scores, MMD distances, or per-increment distribution-shift measurements—is reported in the experimental section, leaving the key assumption untested on the evaluated datasets.
- [Method and Experiments] The balanced online memory recall strategy and concept contrastive loss each introduce a free weighting parameter (memory recall balance ratio; concept contrastive loss weighting coefficient). No sensitivity analysis or ablation removing either component is provided, so it is unclear whether reported gains are robust or attributable to these specific mechanisms rather than the base rehearsal setup.
minor comments (2)
- [Abstract] The abstract contains a sentence fragment beginning with a capitalized 'And'; this should be rephrased for grammatical consistency.
- [Method] Notation for the conditional GAN generator and the incremental network should be unified across equations to avoid ambiguity between G and the classifier f.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] The central claim (abstract and §3) that rehearsal on cGAN pseudo-samples prevents forgetting requires the generated distribution to remain close to the true old-concept distribution. No quantitative validation—such as FID scores, MMD distances, or per-increment distribution-shift measurements—is reported in the experimental section, leaving the key assumption untested on the evaluated datasets.
Authors: We agree that direct quantitative validation of cGAN sample fidelity would strengthen support for the central claim. In the revised manuscript we will report FID scores (and MMD where space permits) between generated pseudo-samples and held-out real samples from prior concepts at each incremental step on all three datasets. This addition will test the distribution-approximation assumption explicitly. revision: yes
-
Referee: [Method and Experiments] The balanced online memory recall strategy and concept contrastive loss each introduce a free weighting parameter (memory recall balance ratio; concept contrastive loss weighting coefficient). No sensitivity analysis or ablation removing either component is provided, so it is unclear whether reported gains are robust or attributable to these specific mechanisms rather than the base rehearsal setup.
Authors: We acknowledge that sensitivity analyses and component ablations are needed to isolate the contributions of the balance ratio and contrastive-loss weight. The revision will add (i) an ablation comparing the full model against variants that disable balanced recall and that disable the contrastive loss, and (ii) performance curves over a range of values for each hyper-parameter. These results will demonstrate robustness beyond the base rehearsal setup. revision: yes
Circularity Check
No circularity; empirical method with no load-bearing self-citations or fitted predictions
full rationale
The paper describes a pseudo-rehearsal method using a conditional GAN to generate samples for rehearsal, a balanced recall strategy, and a concept contrastive loss, then reports empirical results on MNIST-scale datasets. No derivation chain, equations, or self-cited uniqueness theorems appear in the text; the central claim rests on experimental comparisons rather than any step that reduces by construction to its own inputs or prior author work. This is the expected non-finding for an applied incremental-learning paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- memory recall balance ratio
- concept contrastive loss weighting coefficient
axioms (1)
- domain assumption A conditional GAN trained on past data can produce samples whose statistics are sufficiently close to the original concept distributions for effective rehearsal.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a conditional generative adversarial network to consolidate old concepts memory and recall pseudo samples during learning new concepts and a balanced online memory recall strategy...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design a comprehensible incremental concept learning network as well as a concept contrastive loss...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Continual lifelong learning with neural networks: A review,
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Continual lifelong learning with neural networks: A review,” Neural Networks, vol. 113, pp. 54–71, 2019
work page 2019
-
[2]
Catastrophic interference in connec- tionist networks: The sequential learning problem,
M. McCloskey and N. J. Cohen, “Catastrophic interference in connec- tionist networks: The sequential learning problem,” in Psychology of learning and motivation . Elsevier, 1989, vol. 24, pp. 109–165
work page 1989
-
[3]
J. L. McClelland, B. L. McNaughton, and R. C. O’reilly, “Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.” Psychological review, vol. 102, no. 3, p. 419, 1995
work page 1995
- [4]
-
[5]
Neural plasticity across the lifespan,
J. D. Power and B. L. Schlaggar, “Neural plasticity across the lifespan,” Wiley Interdisciplinary Reviews: Developmental Biology , vol. 6, no. 1, p. e216, 2017
work page 2017
-
[6]
M. Mermillod, A. Bugaiska, and P. Bonin, “The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects,” Frontiers in psychology , vol. 4, p. 504, 2013
work page 2013
-
[7]
Continual learning with deep generative replay,
H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,” in Advances in Neural Information Processing Systems, 2017, pp. 2990–2999
work page 2017
-
[8]
Deep Generative Dual Memory Network for Continual Learning
N. Kamra, U. Gupta, and Y . Liu, “Deep generative dual memory network for continual learning,” arXiv preprint arXiv:1710.10368 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Incremental Classifier Learning with Generative Adversarial Networks
Y . Wu, Y . Chen, L. Wang, Y . Ye, Z. Liu, Y . Guo, Z. Zhang, and Y . Fu, “Incremental classifier learning with generative adversarial networks,” arXiv preprint arXiv:1802.00853 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
A. Graves, G. Wayne, and I. Danihelka, “Neural turing machines,” arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
S. Sukhbaatar, J. Weston, R. Fergus et al. , “End-to-end memory net- works,” in Advances in neural information processing systems , 2015, pp. 2440–2448. JOURNAL OF LATEX CLASS FILES, VOL. XX, NO. XX, XX MONTH 2019 11
work page 2015
-
[12]
Recurrent neural networks with auxiliary memory units,
J. Wang, L. Zhang, Q. Guo, and Z. Yi, “Recurrent neural networks with auxiliary memory units,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 5, pp. 1652–1661, May 2018
work page 2018
-
[13]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in Advances in neural information processing systems , 2014, pp. 2672– 2680
work page 2014
-
[15]
Cosine normalization: Using cosine similarity instead of dot product in neural networks,
C. Luo, J. Zhan, X. Xue, L. Wang, R. Ren, and Q. Yang, “Cosine normalization: Using cosine similarity instead of dot product in neural networks,” in International Conference on Artificial Neural Networks . Springer, 2018, pp. 382–391
work page 2018
-
[16]
A discriminative feature learning approach for deep face recognition,
Y . Wen, K. Zhang, Z. Li, and Y . Qiao, “A discriminative feature learning approach for deep face recognition,” in European conference on computer vision . Springer, 2016, pp. 499–515
work page 2016
-
[17]
The mnist database of handwritten digits,
Y . LeCun, “The mnist database of handwritten digits,” http://yann. lecun. com/exdb/mnist/, 1998
work page 1998
-
[18]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng, “Reading digits in natural images with unsupervised feature learning,” in NIPS workshop on deep learning and unsupervised feature learning , 2011
work page 2011
-
[20]
Memory replay gans: learning to generate images from new categories without forgetting,
C. Wu, L. Herranz, X. Liu, Y . Wang, J. van de Weijer, and B. Raducanu, “Memory replay gans: learning to generate images from new categories without forgetting,” in Advances in Neural Information Processing Systems, 2018, pp. 5962–5972
work page 2018
-
[21]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al. , “Overcoming catastrophic forgetting in neural networks,” Pro- ceedings of the national academy of sciences , p. 201611835, 2017
work page 2017
-
[22]
Overcoming catastrophic forgetting by incremental moment matching,
S.-W. Lee, J.-H. Kim, J. Jun, J.-W. Ha, and B.-T. Zhang, “Overcoming catastrophic forgetting by incremental moment matching,” in Advances in Neural Information Processing Systems , 2017, pp. 4652–4662
work page 2017
-
[23]
Rotate your networks: Better weight consolidation and less catastrophic forgetting,
X. Liu, M. Masana, L. Herranz, J. van de Weijer, A. M. L ´opez, and A. D. Bagdanov, “Rotate your networks: Better weight consolidation and less catastrophic forgetting,” 24th International Conference on Pattern Recognition (ICPR), pp. 2262–2268, 2018
work page 2018
-
[24]
Z. Li and D. Hoiem, “Learning without forgetting,” IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017
work page 2017
-
[25]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” in NIPS workshop on deep learning and unsupervised feature learning, Montreal, Canada , 2014
work page 2014
-
[26]
Less-forgetting Learning in Deep Neural Networks
H. Jung, J. Ju, M. Jung, and J. Kim, “Less-forgetting learning in deep neural networks,” arXiv preprint arXiv:1607.00122 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
icarl: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” inProc. CVPR, 2017
work page 2017
-
[28]
Class-incremental learning via deep model consolidation,
J. Zhang, J. Zhang, S. Ghosh, D. Li, S. Tasci, L. Heck, H. Zhang, and C.- C. J. Kuo, “Class-incremental learning via deep model consolidation,” arXiv preprint arXiv:1903.07864 , 2019
-
[29]
A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,” arXiv preprint arXiv:1606.04671 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Lifelong Learning with Dynamically Expandable Networks
J. Lee, J. Yun, S. Hwang, and E. Yang, “Lifelong learning with dynamically expandable networks,” arXiv preprint arXiv:1708.01547 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Ensemble learning in fixed expansion layer networks for mitigating catastrophic forgetting,
R. Coop, A. Mishtal, and I. Arel, “Ensemble learning in fixed expansion layer networks for mitigating catastrophic forgetting,” IEEE Transac- tions on Neural Networks and Learning Systems , vol. 24, no. 10, pp. 1623–1634, Oct 2013
work page 2013
-
[32]
Gradient episodic memory for continual learning,
D. Lopez-Paz et al., “Gradient episodic memory for continual learning,” in Advances in Neural Information Processing Systems, 2017, pp. 6467– 6476
work page 2017
-
[33]
Generative replay with feedback connections as a general strategy for continual learning
G. M. van de Ven and A. S. Tolias, “Generative replay with feedback connections as a general strategy for continual learning,” arXiv preprint arXiv:1809.10635, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
An overview of gradient descent optimization algorithms
S. Ruder, “An overview of gradient descent optimization algorithms,” arXiv preprint arXiv:1609.04747 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,” arXiv preprint arXiv:1701.07875, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Improved training of wasserstein gans,
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. C. Courville, “Improved training of wasserstein gans,” in Advances in Neural Infor- mation Processing Systems , 2017, pp. 5767–5777
work page 2017
-
[37]
Least squares generative adversarial networks,
X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. Wang, and S. P. Smolley, “Least squares generative adversarial networks,” in Computer Vision (ICCV), 2017 IEEE International Conference on . IEEE, 2017, pp. 2813–2821
work page 2017
-
[38]
Automatic differentiation in pytorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” in NIPS-W, 2017
work page 2017
-
[39]
Self-Attention Generative Adversarial Networks
H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena, “Self-attention gen- erative adversarial networks,” arXiv preprint arXiv:1805.08318 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Spectral Normalization for Generative Adversarial Networks
T. Miyato, T. Kataoka, M. Koyama, and Y . Yoshida, “Spectral normalization for generative adversarial networks,” arXiv preprint arXiv:1802.05957, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[42]
Catastrophic forgetting, rehearsal and pseudorehearsal,
A. Robins, “Catastrophic forgetting, rehearsal and pseudorehearsal,” Connection Science, vol. 7, no. 2, pp. 123–146, 1995
work page 1995
-
[43]
Revisiting Distillation and Incremental Classifier Learning
K. Javed and F. Shafait, “Revisiting distillation and incremental classifier learning,” arXiv preprint arXiv:1807.02802 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
A. Brock, J. Donahue, and K. Simonyan, “Large scale gan training for high fidelity natural image synthesis,” arXiv preprint arXiv:1809.11096, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
High-fidelity image generation with fewer labels,
M. Lu ˇci´c, M. Tschannen, M. Ritter, X. Zhai, O. Bachem, and S. Gelly, “High-fidelity image generation with fewer labels,” in International Conference on Machine Learning , 2019, pp. 4183–4192
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.