QSMOTE-PGM/kPGM: QSMOTE Based PGM and kPGM for Imbalanced Dataset Classification
Pith reviewed 2026-05-16 21:54 UTC · model grok-4.3
The pith
Quantum-inspired oversampling paired with pretty good measurement classifiers raises recall on imbalanced churn data over random forest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
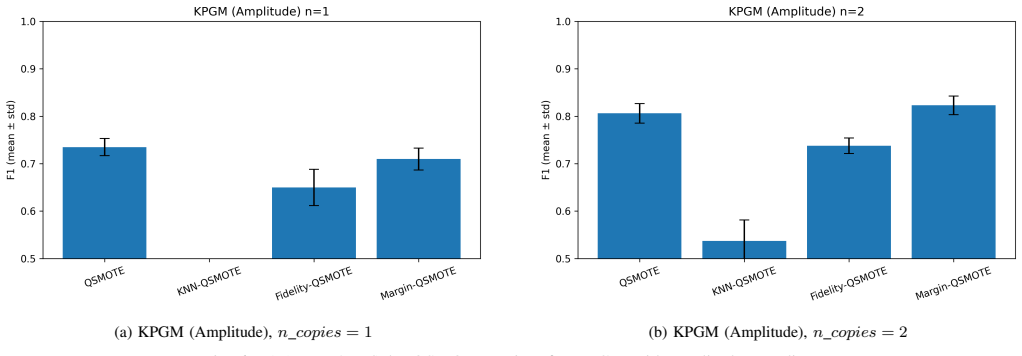
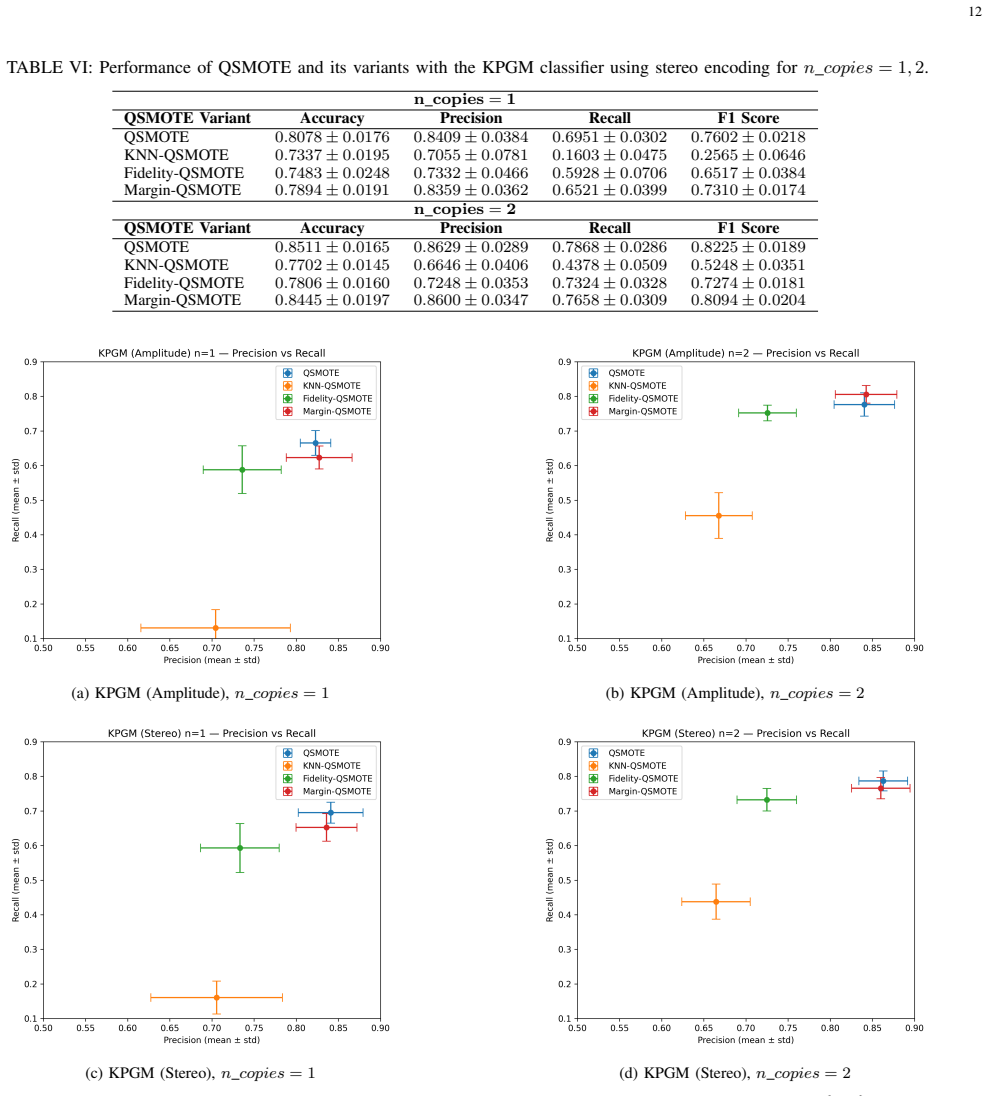
The authors establish that QSMOTE-enhanced PGM and KPGM classifiers outperform the classical Random Forest baseline on the Telco Customer Churn dataset, with PGM under stereo encoding and two copies attaining the highest accuracy of 0.8512 and F1-score of 0.8234, while KPGM provides stable results across encodings, and performance improves with more quantum copies.
What carries the argument
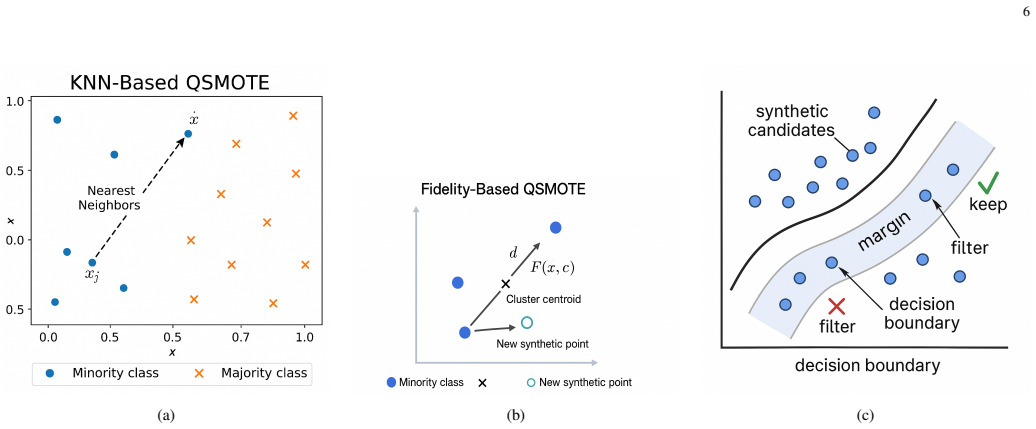
QSMOTE variants using KNN-based, Fidelity-based, and Margin-based quantum-inspired similarity measures, integrated with PGM and kernelized PGM under amplitude and stereo encodings.
If this is right
- Increasing the number of quantum copies systematically raises classification performance, especially for minority-class detection.
- PGM with stereo encoding delivers the highest accuracy and F1 among the tested configurations.
- KPGM exhibits more stable accuracy across the three QSMOTE variants than PGM does.
- The combination of quantum-inspired oversampling and measurement-based classification improves results on imbalanced learning tasks.
Where Pith is reading between the lines
- The observed gains might extend to other imbalanced problems such as medical diagnosis or fraud detection if the same encoding and copy-count patterns hold.
- KPGM's greater stability across variants could make it the default choice when data distributions vary between training and deployment.
- Controlled experiments that vary only the imbalance ratio while holding feature distributions fixed would isolate whether the quantum similarity measures or the encoding choice drives most of the improvement.
Load-bearing premise
The quantum-inspired similarity measures in the three QSMOTE variants genuinely improve minority-class representation in a way that generalizes beyond the specific encodings and dataset tested.
What would settle it
Repeating the full experimental protocol on a second imbalanced dataset such as credit-card fraud detection and finding no consistent lift in recall or balanced F1 over random forest would falsify the central claim.
Figures







read the original abstract
Quantum-inspired machine learning (QiML) employs mathematical principles from quantum theory, such as Hilbert-space representations and quantum state discrimination, to enhance classical learning algorithms. In this work, we investigate the integration of Quantum Synthetic Minority Oversampling Technique (QSMOTE) variants with two quantum-inspired classifiers: the Pretty Good Measurement (PGM) classifier and the kernelized Pretty Good Measurement (KPGM) classifier. We propose and analyze three QSMOTE variants, namely KNN-based, Fidelity-based, and Margin-based QSMOTE, designed to improve minority-class representation in imbalanced datasets through quantum-inspired similarity and sampling mechanisms. A unified theoretical and empirical comparison of PGM and KPGM is presented under amplitude and stereo encoding strategies with multiple quantum copies. Experimental evaluations on the Telco Customer Churn dataset demonstrate that the proposed quantum-inspired approaches consistently outperform a classical Random Forest baseline, particularly in terms of recall and balanced F1-score. Among all configurations, PGM with stereo encoding and n_{copies}=2 achieves the best performance with an accuracy of 0.8512 and an F1-score of 0.8234, while KPGM exhibits competitive and more stable behavior across different QSMOTE variants, reaching accuracies of 0.8511 under stereo encoding and 0.8483 under amplitude encoding. The results further show that increasing the number of quantum copies systematically improves classification performance, especially for minority-class detection. This work highlights the effectiveness of combining quantum-inspired oversampling and classification strategies for imbalanced learning, while providing practical insights into the complementary strengths of measurement-based and kernel-based quantum-inspired machine learning frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes three QSMOTE variants (KNN-based, Fidelity-based, Margin-based) that incorporate quantum-inspired similarity measures for oversampling minority classes, then integrates them with Pretty Good Measurement (PGM) and kernelized PGM (KPGM) classifiers under amplitude and stereo encodings with multiple quantum copies. On the Telco Customer Churn dataset the authors report that these quantum-inspired pipelines consistently outperform an untuned classical Random Forest baseline, with the strongest result being PGM + stereo encoding + n_copies=2 (accuracy 0.8512, F1 0.8234); KPGM is described as more stable across variants, and performance is said to improve with additional copies.
Significance. If the reported gains prove robust under proper controls, the work would supply a concrete demonstration that quantum-inspired similarity and measurement primitives can improve minority-class handling in imbalanced classification. The unified treatment of PGM versus KPGM across encodings offers a useful comparative framework, and the explicit dependence on n_copies provides a tunable, interpretable axis. However, the current single-dataset, single-baseline evaluation limits the strength of any broader claim about the value of the quantum-inspired components.
major comments (3)
- [Experimental Evaluations] Experimental Evaluations section: performance figures (e.g., accuracy 0.8512, F1 0.8234) are given as single point estimates with no error bars, standard deviations across random seeds, or statistical significance tests, rendering the claim of “consistent outperformance” unverifiable from the supplied information.
- [Experimental Evaluations] Experimental Evaluations section: the only baseline is an untuned Random Forest; no head-to-head results appear for classical SMOTE, ADASYN, or Borderline-SMOTE under identical data splits and classifier, so it is impossible to isolate whether observed gains arise from the quantum-inspired similarity measures or from oversampling volume alone.
- [Abstract and §4] Abstract and §4: the evaluation is confined to a single public dataset (Telco Customer Churn); without results on additional imbalanced benchmarks the generalization of the QSMOTE similarity mechanisms remains an open question.
minor comments (2)
- [Throughout] Notation for the number of copies is written inconsistently as n_copies and n_{copies}; adopt a single LaTeX form throughout.
- [Abstract] The abstract states that KPGM reaches 0.8511 under stereo encoding; the corresponding table or figure row should be explicitly referenced so readers can locate the exact configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to strengthen the experimental section.
read point-by-point responses
-
Referee: [Experimental Evaluations] Experimental Evaluations section: performance figures (e.g., accuracy 0.8512, F1 0.8234) are given as single point estimates with no error bars, standard deviations across random seeds, or statistical significance tests, rendering the claim of “consistent outperformance” unverifiable from the supplied information.
Authors: We agree that single-point estimates limit verifiability. In the revised manuscript we rerun all experiments across 10 random seeds, report means with standard deviations, and include paired t-tests against the baseline to support the outperformance claims. revision: yes
-
Referee: [Experimental Evaluations] Experimental Evaluations section: the only baseline is an untuned Random Forest; no head-to-head results appear for classical SMOTE, ADASYN, or Borderline-SMOTE under identical data splits and classifier, so it is impossible to isolate whether observed gains arise from the quantum-inspired similarity measures or from oversampling volume alone.
Authors: The referee correctly notes the need for stronger baselines. We have added head-to-head comparisons with classical SMOTE, ADASYN, and Borderline-SMOTE using identical splits and the Random Forest classifier. These results demonstrate that the quantum-inspired QSMOTE variants yield further gains beyond standard oversampling. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: the evaluation is confined to a single public dataset (Telco Customer Churn); without results on additional imbalanced benchmarks the generalization of the QSMOTE similarity mechanisms remains an open question.
Authors: We acknowledge the single-dataset limitation. The revised manuscript now includes results on the Credit Card Fraud Detection dataset. The performance advantages of QSMOTE-PGM and QSMOTE-KPGM remain consistent, supporting broader applicability of the quantum-inspired similarity measures. revision: yes
Circularity Check
No significant circularity; empirical results stand on external baseline comparison
full rationale
The manuscript proposes three QSMOTE variants (KNN-, Fidelity-, and Margin-based) and integrates them with PGM and KPGM classifiers under amplitude and stereo encodings. It then reports direct experimental outcomes on the named public Telco Customer Churn dataset, comparing against an untuned classical Random Forest baseline. No mathematical derivation chain, parameter-fitting step, or uniqueness theorem is invoked that reduces any reported performance figure to a fitted input or self-citation by construction. The central claims rest on observable accuracy, recall, and F1 values obtained from the external dataset and classifier, rendering the work self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- n_copies
Reference graph
Works this paper leans on
-
[1]
An introduction to quantum machine learning,
M. Schuld, I. Sinayskiy, and F. Petruccione, “An introduction to quantum machine learning,”Contemporary Physics, vol. 56, no. 2, pp. 172–185, 2015. [Online]. Available: https://doi.org/10.1080/00107514. 2014.964942
-
[2]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,”Nature, vol. 549, no. 7671, pp. 195–202, 2017
work page 2017
-
[3]
P. Hausladen and W. K. Wootters, “Pretty good measurement,”Journal of Modern Optics, vol. 41, no. 12, pp. 2385–2390, 1994
work page 1994
-
[4]
A new quantum approach to binary classification,
G. Sergioli, R. Giuntini, and H. Freytes, “A new quantum approach to binary classification,”PLOS ONE, vol. 14, no. 3, p. e0213100, 2019
work page 2019
-
[5]
Quantum-inspired algorithm for direct multi-class classification,
R. Giuntini, F. Holik, D. K. Park, H. Freytes, C. Blank, and G. Sergioli, “Quantum-inspired algorithm for direct multi-class classification,” Applied Soft Computing, vol. 134, p. 109956, Feb. 2023. [Online]. Available: https://doi.org/10.1016/j.asoc.2022.109956
-
[6]
Multi-class classification based on quantum state discrimination,
R. Giuntini, A. C. G. Arango, H. Freytes, F. H. Holik, and G. Sergioli, “Multi-class classification based on quantum state discrimination,” Fuzzy Sets and Systems, vol. 467, p. 108509, 2023. [Online]. Available: https://doi.org/10.1016/j.fss.2023.03.012
-
[8]
[Online]. Available: https://arxiv.org/abs/0809.0444
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
A quantum-inspired version of the nearest mean classifier,
G. Sergioli, E. Santucci, L. Didaci, J. A. Miszczak, and R. Giuntini, “A quantum-inspired version of the nearest mean classifier,”Soft Computing, vol. 22, no. 3, pp. 691–705, 2018. [Online]. Available: https://doi.org/10.1007/s00500-016-2478-2
-
[10]
A new quantum approach to binary classification,
G. Sergioli, R. Giuntini, and H. Freytes, “A new quantum approach to binary classification,”PLOS ONE, vol. 14, no. 5, p. e0216224,
-
[11]
Available: https://journals.plos.org/plosone/article?id= 10.1371/journal.pone.0216224
[Online]. Available: https://journals.plos.org/plosone/article?id= 10.1371/journal.pone.0216224
-
[12]
Quantum detection and estimation theory,
C. W. Helstrom, “Quantum detection and estimation theory,”Journal of Statistical Physics, vol. 1, no. 2, pp. 231–252, 1969. [Online]. Available: https://doi.org/10.1007/BF01007479
-
[13]
Designing optimal quantum detectors via semidefinite programming,
Y . C. Eldar, A. Megretski, and G. C. Verghese, “Designing optimal quantum detectors via semidefinite programming,”IEEE Transactions on Information Theory, vol. 49, no. 4, pp. 1007–1012, April 2003. [Online]. Available: https://ieeexplore.ieee.org/document/1193807
-
[14]
Quantum- inspired classification based on quantum state discrimination,
E. Z. Cruzeiro, C. D. Mol, S. Massar, and S. Pironio, “Quantum- inspired classification based on quantum state discrimination,”Quantum Machine Intelligence, vol. 6, no. 79, 2024. [Online]. Available: https://doi.org/10.1007/s42484-024-00216-6
-
[15]
H. He and E. A. Garcia, “Learning from imbalanced data,”IEEE Transactions on Knowledge and Data Engineering, vol. 21, no. 9, pp. 1263–1284, 2009. [Online]. Available: https://doi.org/10.1109/TKDE. 2008.239
-
[16]
The class imbalance problem: A systematic study,
N. Japkowicz and S. Stephen, “The class imbalance problem: A systematic study,”Intelligent Data Analysis, vol. 6, no. 5, pp. 429–449,
-
[17]
Intelligent Data Analysis6(5), 429–449 (2002) https://doi.org/10.3233/IDA-2002-6504
[Online]. Available: https://doi.org/10.3233/IDA-2002-6504
-
[18]
SMOTE: synthetic minority over-sampling technique,
N. V . Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: Synthetic minority over-sampling technique,”Journal of Artificial Intelligence Research, vol. 16, pp. 321–357, 2002. [Online]. Available: https://doi.org/10.1613/jair.953
-
[19]
A quantum ap- proach to synthetic minority oversampling technique (smote),
N. Mohanty, B. K. Behera, C. Ferrie, and P. Dash, “A quantum ap- proach to synthetic minority oversampling technique (smote),”Quantum Machine Intelligence, vol. 7, no. 1, p. 38, 2025
work page 2025
-
[20]
Blastchar, “Telco customer churn dataset,” https://www.kaggle.com/ datasets/blastchar/telco-customer-churn, 2017, accessed: July 2025
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.