P-JEPA: Procedural Video Representation Learning via Joint Embedding Predictive Architecture
Pith reviewed 2026-06-26 08:48 UTC · model grok-4.3
The pith
P-JEPA learns long procedural video representations by predicting pooled masked latent vectors in a dense frame-aligned action space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
P-JEPA is a backbone-agnostic approach that learns long-duration video representations by reducing the problem to a dense, frame-aligned action space and predicting pooled masked latent vectors. This allows ingestion of videos over 30 minutes long for effective long-form understanding of procedural steps.
What carries the argument
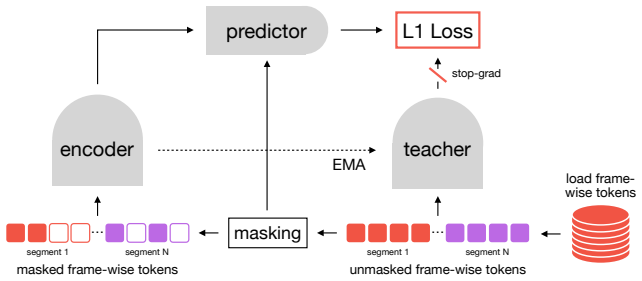
The Procedural Joint Embedding Predictive Architecture (P-JEPA), which predicts pooled masked latent vectors to capture long-range dependencies without self-attention.
If this is right
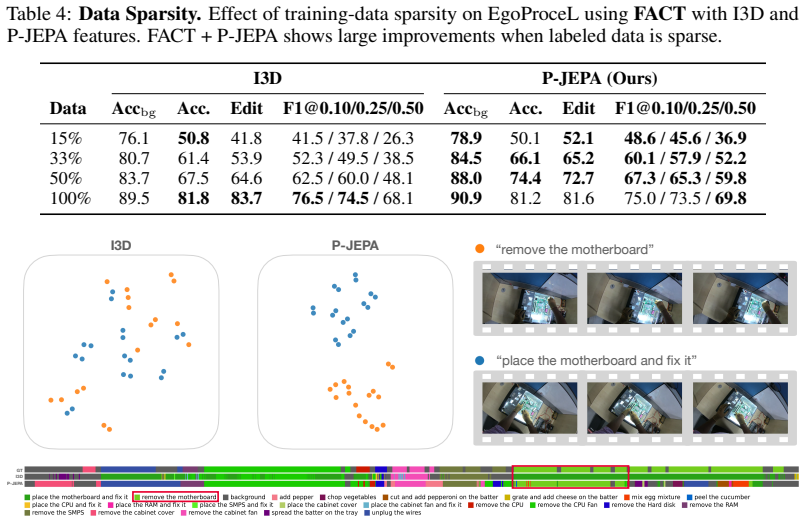
- It improves linear separability, streaming inference, and temporal action segmentation performance across EgoExo4D, EgoProceL, and Assembly101.
- It reaches state-of-the-art results on EgoExo4D fine-grained action classification.
- It uses an order of magnitude fewer parameters than LLM-based methods while running in real time.
Where Pith is reading between the lines
- The frame-aligned prediction strategy may generalize to other long-sequence modalities where quadratic attention becomes prohibitive.
- Because the method is backbone-agnostic, it could be paired with future video encoders to extend real-time procedural assistance.
- Real-time operation on long videos supports online systems that give step-by-step guidance during complex tasks.
Load-bearing premise
That reducing the problem to a dense frame-aligned action space and predicting pooled masked latent vectors is enough to capture long-range dependencies between visually similar but procedurally distinct actions.
What would settle it
Evaluation on a dataset of procedural videos exceeding 30 minutes where P-JEPA does not improve fine-grained action classification accuracy over attention-based baselines.
Figures



read the original abstract
The increasing maturity of embodied AI platforms has driven a growing interest in procedural video representation learning to support intelligent assistance systems for complex, multi-step tasks. Leveraging large-scale latent predictive training, video foundation models capture video dynamics, enabling downstream tasks such as activity understanding, spatiotemporal localization, and predictive control. However, procedural videos include actions with long-range dependencies that these models do not support, due to the quadratic complexity of self-attention. Distinct actions, for example, may be visually similar despite appearing at different points in the procedure, such as turning the stove on versus off. Here, we propose a backbone-agnostic approach that learns long-duration video representations by reducing the problem to a dense, frame-aligned action space and predicting pooled masked latent vectors. This approach allows our Procedural Joint Embedding Predictive Architecture (P-JEPA) to ingest videos over 30 minutes long, enabling effective long-form understanding of procedural steps. We evaluate P-JEPA using features extracted with VJEPA2.1, TSM, and I3D over the EgoExo4D, EgoProceL, and Assembly101 datasets, finding that it consistently improves linear separability, streaming inference, and temporal action segmentation performance, achieving state-of-the-art results on EgoExo4D fine-grained action classification while using an order of magnitude fewer parameters than LLM-based methods and running in real time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes P-JEPA, a backbone-agnostic Joint Embedding Predictive Architecture for procedural video representation learning. It reduces the problem to predicting pooled masked latent vectors in a dense frame-aligned action space to handle long videos (>30 min) and long-range dependencies without self-attention. Evaluations on EgoExo4D, EgoProceL, and Assembly101 using VJEPA2.1, TSM, and I3D features claim consistent improvements in linear separability, streaming inference, and temporal action segmentation, with SOTA on EgoExo4D fine-grained action classification using fewer parameters and real-time performance.
Significance. If the empirical claims hold, the work could offer a scalable and efficient method for long-form procedural video understanding, addressing limitations of attention-based models in embodied AI applications. The backbone-agnostic nature and focus on procedural steps are notable strengths.
major comments (1)
- [Abstract] Abstract: The central claims of consistent improvements, SOTA results on EgoExo4D fine-grained action classification, order-of-magnitude parameter reduction versus LLM methods, and real-time performance are stated without any quantitative metrics, baselines, error bars, ablation studies, or dataset-specific numbers. This absence prevents verification of the key sufficiency claim that the pooled-masked-latent approach captures long-range procedural dependencies.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to clarify the presentation of our results. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of consistent improvements, SOTA results on EgoExo4D fine-grained action classification, order-of-magnitude parameter reduction versus LLM methods, and real-time performance are stated without any quantitative metrics, baselines, error bars, ablation studies, or dataset-specific numbers. This absence prevents verification of the key sufficiency claim that the pooled-masked-latent approach captures long-range procedural dependencies.
Authors: We agree that the abstract would be strengthened by including key quantitative results to support the stated claims. The body of the manuscript reports these details, including specific accuracy gains on EgoExo4D, parameter comparisons (order-of-magnitude reduction relative to LLM baselines), real-time inference speeds, and ablations with error bars across EgoExo4D, EgoProceL, and Assembly101. To directly address the concern, we will revise the abstract to incorporate representative numerical results, mention of the baselines used, and a brief reference to the ablation studies. The experiments section further substantiates the long-range dependency claim by evaluating on videos exceeding 30 minutes with the pooled masked latent prediction mechanism. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The abstract and description present P-JEPA as an independent backbone-agnostic architecture that reduces procedural video modeling to predicting pooled masked latent vectors in a dense frame-aligned action space. No equations, self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations are exhibited in the provided material. The central claim of handling long videos without quadratic self-attention is framed as a direct architectural choice rather than derived from prior fitted results or author-specific uniqueness theorems. This matches the reader's 0.0 assessment and qualifies as a normal non-finding of circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vivit: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Luˇci´c, and Cordelia Schmid. Vivit: A video vision transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6836–6846, October 2021
2021
-
[2]
Hiervl: Learning hierarchical video-language embeddings
Kumar Ashutosh, Rohit Girdhar, Lorenzo Torresani, and Kristen Grauman. Hiervl: Learning hierarchical video-language embeddings. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23066–23078, 2023
2023
-
[3]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[4]
How much temporal long-term context is needed for action segmentation? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10351–10361, 2023
Emad Bahrami, Gianpiero Francesca, and Juergen Gall. How much temporal long-term context is needed for action segmentation? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10351–10361, 2023
2023
-
[5]
My view is the best view: Procedure learning from egocentric videos
Siddhant Bansal, Chetan Arora, and CV Jawahar. My view is the best view: Procedure learning from egocentric videos. InEuropean Conference on Computer Vision, pages 657–675. Springer, 2022
2022
-
[6]
United we stand, divided we fall: Unitygraph for unsupervised procedure learning from videos
Siddhant Bansal, Chetan Arora, and CV Jawahar. United we stand, divided we fall: Unitygraph for unsupervised procedure learning from videos. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6509–6519, 2024
2024
-
[7]
Revisiting feature prediction for learning visual representations from video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471, 2024
Pith/arXiv arXiv 2024
-
[8]
Unified fully and timestamp supervised temporal action segmentation via sequence to sequence translation
Nadine Behrmann, S Alireza Golestaneh, Zico Kolter, Juergen Gall, and Mehdi Noroozi. Unified fully and timestamp supervised temporal action segmentation via sequence to sequence translation. InEuropean conference on computer vision, pages 52–68. Springer, 2022
2022
-
[9]
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InProceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 813–824, 2021
2021
-
[10]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
2017
-
[11]
Streaming videollms for real-time procedural video understanding
Dibyadip Chatterjee, Edoardo Remelli, Yale Song, Bugra Tekin, Abhay Mittal, Bharat Bhatnagar, Necati Ci- han Camgoz, Shreyas Hampali, Eric Sauser, Shugao Ma, et al. Streaming videollms for real-time procedural video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22586–22598, 2025. 10
2025
-
[12]
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl-jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
arXiv 2025
-
[13]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024
2024
-
[14]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[15]
Unsupervised procedure learning via joint dynamic summarization
Ehsan Elhamifar and Zwe Naing. Unsupervised procedure learning via joint dynamic summarization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6341–6350, 2019
2019
-
[16]
Multiscale vision transformers
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6824–6835, October 2021
2021
-
[17]
Ms-tcn: Multi-stage temporal convolutional network for action segmentation
Yazan Abu Farha and Jurgen Gall. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3575–3584, 2019
2019
-
[18]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025
2025
-
[19]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[20]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13504– 13514, 2024
2024
-
[21]
Chi-Hsi Kung, Frangil Ramirez, Juhyung Ha, Yi-Ting Chen, David Crandall, and Yi-Hsuan Tsai. What changed and what could have changed? state-change counterfactuals for procedure-aware video representa- tion learning.arXiv preprint arXiv:2503.21055, 2025
arXiv 2025
-
[22]
Video token merging for long video understanding.Advances in Neural Information Processing Systems, 37:13851–13871, 2024
Seon-Ho Lee, Jue Wang, Zhikang Zhang, David Fan, and Xinyu Li. Video token merging for long video understanding.Advances in Neural Information Processing Systems, 37:13851–13871, 2024
2024
-
[23]
Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024
Lei Li, Yuanxin Liu, Linli Yao, Peiyuan Zhang, Chenxin An, Lean Wang, Xu Sun, Lingpeng Kong, and Qi Liu. Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024
arXiv 2024
-
[24]
Shi-Jie Li, Yazan AbuFarha, Yun Liu, Ming-Ming Cheng, and Juergen Gall. Ms-tcn++: Multi-stage temporal convolutional network for action segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2020. doi: 10.1109/TPAMI.2020.3021756
-
[25]
Tsm: Temporal shift module for efficient video understanding
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7083–7093, 2019
2019
-
[26]
Tempcompass: Do video llms really understand videos?arXiv preprint arXiv:2403.00476, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos?arXiv preprint arXiv:2403.00476, 2024
Pith/arXiv arXiv 2024
-
[27]
Video swin transformer
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3202–3211, June 2022
2022
-
[28]
Fact: Frame-action cross-attention temporal modeling for efficient action segmentation
Zijia Lu and Ehsan Elhamifar. Fact: Frame-action cross-attention temporal modeling for efficient action segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18175–18185, 2024. 11
2024
-
[29]
Streamer: Streaming representation learning and event segmentation in a hierarchical manner.Advances in Neural Information Processing Systems, 36: 45694–45715, 2023
Ramy Mounir, Sujal Vijayaraghavan, and Sudeep Sarkar. Streamer: Streaming representation learning and event segmentation in a hierarchical manner.Advances in Neural Information Processing Systems, 36: 45694–45715, 2023
2023
-
[30]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
Pith/arXiv arXiv 2026
-
[31]
Video transformer network
Daniel Neimark, Omri Bar, Maya Zohar, and Dotan Asselmann. Video transformer network. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 3163–3172, October 2021
2021
-
[32]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[33]
Hiero: understanding the hierarchy of human behavior enhances reasoning on egocentric videos
Simone Alberto Peirone, Francesca Pistilli, and Giuseppe Averta. Hiero: understanding the hierarchy of human behavior enhances reasoning on egocentric videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19862–19871, 2025
2025
-
[34]
Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos
Chiara Plizzari, Alessio Tonioni, Yongqin Xian, Achin Kulshrestha, and Federico Tombari. Omnia de egotempo: Benchmarking temporal understanding of multi-modal llms in egocentric videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24129–24138, 2025
2025
-
[35]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5285–5297, 2023
2023
-
[36]
Learning from untrimmed videos: Self-supervised video representation learning with hierarchical consistency
Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Yi Xu, Xiang Wang, Mingqian Tang, Changxin Gao, Rong Jin, and Nong Sang. Learning from untrimmed videos: Self-supervised video representation learning with hierarchical consistency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13821–13831, 2022
2022
-
[37]
Understanding long videos with multimodal language models.arXiv preprint arXiv:2403.16998, 2024
Kanchana Ranasinghe, Xiang Li, Kumara Kahatapitiya, and Michael S Ryoo. Understanding long videos with multimodal language models.arXiv preprint arXiv:2403.16998, 2024
arXiv 2024
-
[38]
Timechat: A time-sensitive multimodal large language model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14313–14323, 2024
2024
-
[39]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21096– 21106, 2022
2022
-
[40]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26160–26169, 2025
2025
-
[41]
C2f-tcn: A framework for semi-and fully-supervised temporal action segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10): 11484–11501, 2023
Dipika Singhania, Rahul Rahaman, and Angela Yao. C2f-tcn: A framework for semi-and fully-supervised temporal action segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10): 11484–11501, 2023
2023
-
[42]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
2024
-
[43]
Moviechat+: Question- aware sparse memory for long video question answering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang. Moviechat+: Question- aware sparse memory for long video question answering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[44]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[45]
Koala: Key frame-conditioned long video-llm
Reuben Tan, Ximeng Sun, Ping Hu, Jui-hsien Wang, Hanieh Deilamsalehy, Bryan A Plummer, Bryan Russell, and Kate Saenko. Koala: Key frame-conditioned long video-llm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13581–13591, 2024. 12
2024
-
[46]
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35: 10078–10093, 2022
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.Advances in neural information processing systems, 35: 10078–10093, 2022
2022
-
[47]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[48]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37: 28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37: 28828–28857, 2024
2024
-
[49]
Videollm-mod: Efficient video-language streaming with mixture- of-depths vision computation.Advances in Neural Information Processing Systems, 37:109922–109947, 2024
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, and Mike Zheng Shou. Videollm-mod: Efficient video-language streaming with mixture- of-depths vision computation.Advances in Neural Information Processing Systems, 37:109922–109947, 2024
2024
-
[50]
Hierarchical self-supervised representation learning for movie understanding
Fanyi Xiao, Kaustav Kundu, Joseph Tighe, and Davide Modolo. Hierarchical self-supervised representation learning for movie understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9727–9736, 2022
2022
-
[51]
Asformer: Transformer for action segmentation.arXiv preprint arXiv:2110.08568, 2021
Fangqiu Yi, Hongyu Wen, and Tingting Jiang. Asformer: Transformer for action segmentation.arXiv preprint arXiv:2110.08568, 2021
arXiv 2021
-
[52]
Learning procedure-aware video representation from instructional videos and their narrations
Yiwu Zhong, Licheng Yu, Yang Bai, Shangwen Li, Xueting Yan, and Yin Li. Learning procedure-aware video representation from instructional videos and their narrations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14825–14835, 2023
2023
-
[53]
Procedure-aware pretraining for instructional video understanding
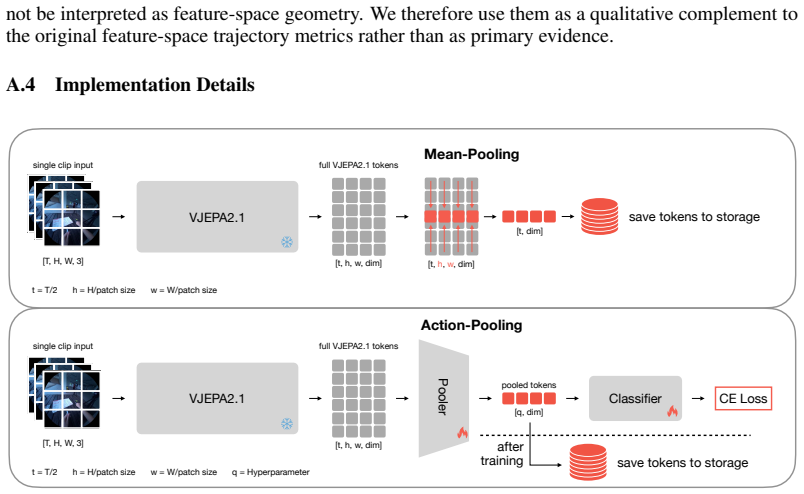
Honglu Zhou, Roberto Martín-Martín, Mubbasir Kapadia, Silvio Savarese, and Juan Carlos Niebles. Procedure-aware pretraining for instructional video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10727–10738, 2023. 13 A Supplementary Material In this supplementary material we first discuss the broa...
2023
-
[54]
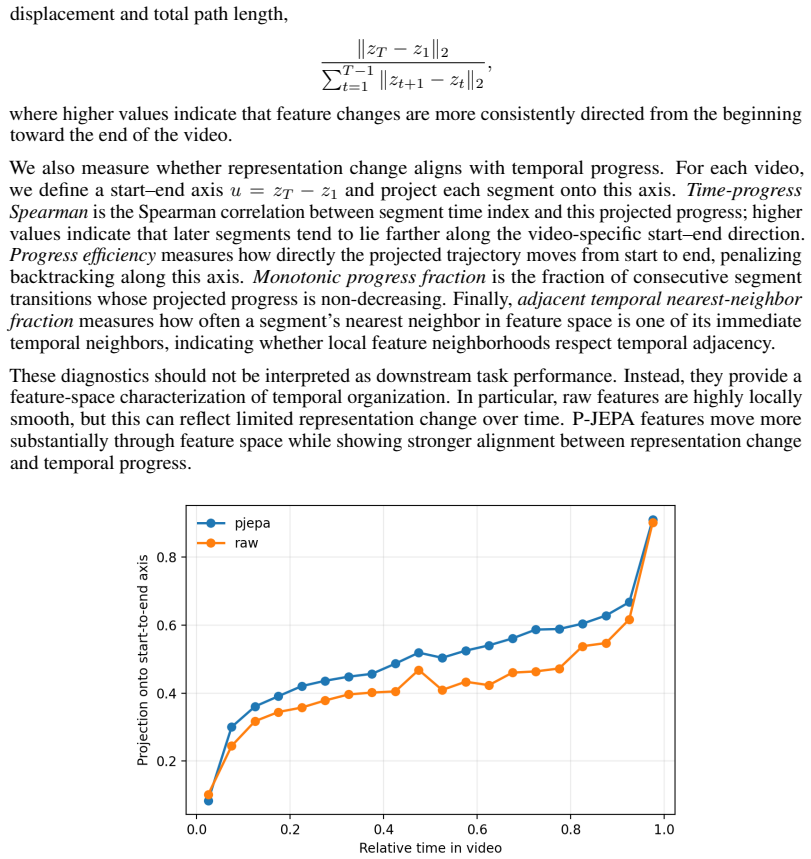
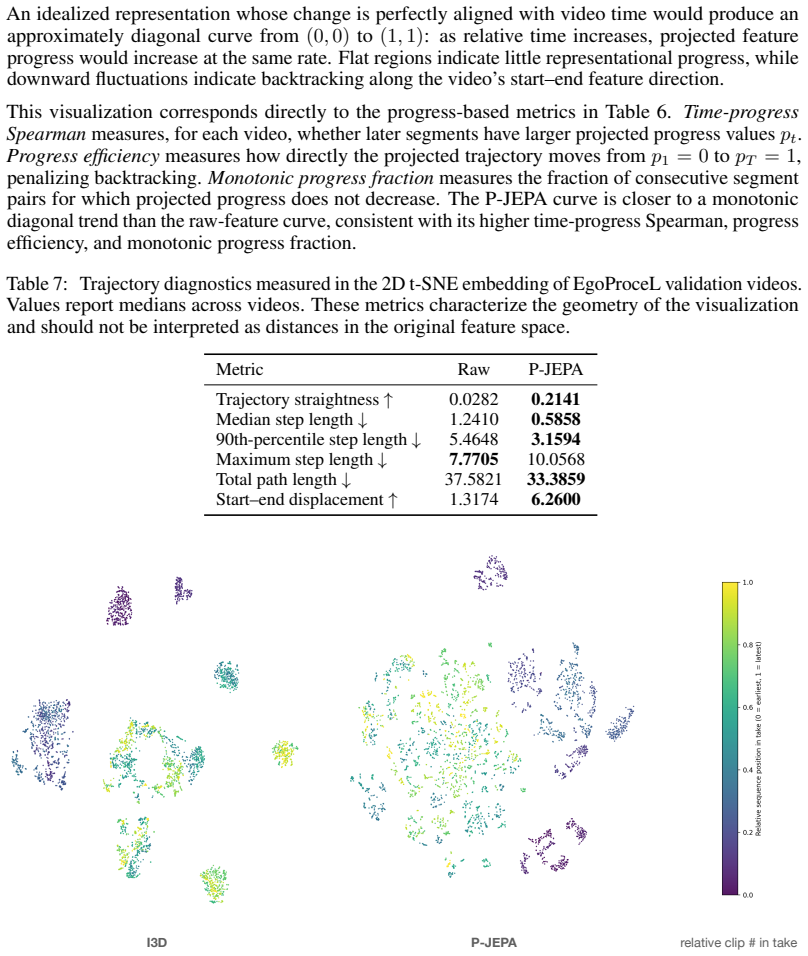
Then we perform a similar analysis in the reduced dimensionality space of the t-SNE as shown in Figure 7, where the path metrics were computed in this reduced space (Table 7). A.1 Broader Impact Embodied AI and personalized assistants have a large upside, promising to take over menial tasks and increase productivity, making life easier for the majority of...
arXiv 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.