VIPaint: Image Inpainting with Pre-Trained Diffusion Models via Variational Inference
Pith reviewed 2026-05-23 17:25 UTC · model grok-4.3
The pith
A hierarchical variational inference method approximates the diffusion posterior to enable inpainting with pre-trained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
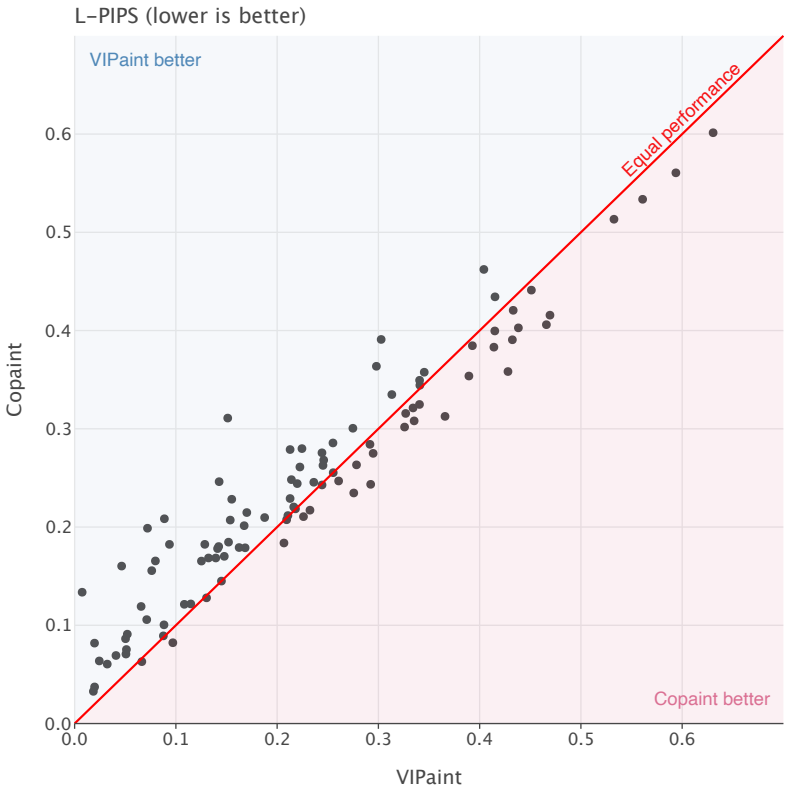
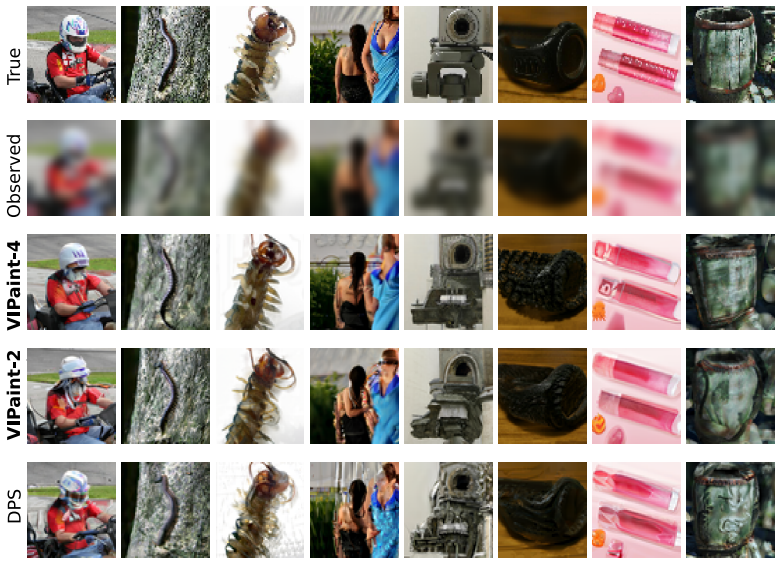
VIPaint introduces a hierarchical variational inference algorithm that optimizes a non-Gaussian Markov approximation of the true diffusion posterior, enabling pre-trained diffusion models to generate diverse high-quality imputations for masked images and other inverse problems, outperforming prior approaches especially on large masks and latent diffusion models.
What carries the argument
Hierarchical variational inference that optimizes a non-Gaussian Markov approximation to the true conditional diffusion posterior
If this is right
- Produces diverse high-quality imputations for inpainting tasks with pre-trained diffusion models.
- Works with state-of-the-art text-conditioned latent diffusion models without modification.
- Extends directly to other inverse problems such as deblurring and superresolution.
- Avoids the need to retrain or fine-tune the underlying diffusion model for each new conditioning task.
Where Pith is reading between the lines
- The same variational approximation could be applied to condition diffusion models on other forms of partial data such as sparse measurements or low-resolution inputs.
- Tighter variational families or more steps in the hierarchy might further reduce the gap to the true posterior on challenging masks.
- Because the method operates on the latent space of existing models, it could transfer to video or 3-D diffusion models with only minor changes to the Markov structure.
Load-bearing premise
The hierarchical variational inference procedure produces a sufficiently accurate non-Gaussian Markov approximation to the true conditional diffusion posterior for the inpainting and inverse-problem tasks considered.
What would settle it
A controlled experiment on small images where the true conditional posterior can be sampled exactly, showing whether VIPaint samples match that posterior more closely than baselines or diverge on large masks.
Figures

















read the original abstract
Diffusion probabilistic models learn to remove noise added during training, generating novel data (e.g., images) from Gaussian noise through sequential denoising. However, conditioning the generative process on corrupted or masked images is challenging. While various methods have been proposed for inpainting masked images with diffusion priors, they often fail to produce samples from the true conditional distribution, especially for large masked regions. Many baselines also cannot be applied to latent diffusion models which generate high-quality images with much lower computational cost. We propose a hierarchical variational inference algorithm that optimizes a non-Gaussian Markov approximation of the true diffusion posterior. Our VIPaint method outperforms existing approaches to inpainting, producing diverse high-quality imputations even for state-of-the-art text-conditioned latent diffusion models, and is also effective for other inverse problems like deblurring and superresolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VIPaint, a hierarchical variational inference algorithm that constructs a non-Gaussian Markov approximation to the conditional diffusion posterior. The method is applied to image inpainting with pre-trained diffusion models (including latent ones) and extended to other inverse problems such as deblurring and super-resolution. The central claim is that this procedure yields diverse, high-quality samples that outperform prior inpainting baselines while remaining applicable to state-of-the-art text-conditioned latent diffusion models.
Significance. If the reported quantitative gains hold, the work supplies an explicit ELBO, variational family, and optimization schedule for posterior sampling in diffusion models, together with reproducible experiments across pixel-space and latent backbones. This constitutes a practical advance for conditioning diffusion priors on corrupted observations without retraining.
major comments (2)
- [§3] §3 (hierarchical variational procedure): the claim that the Markov factorization yields a sufficiently accurate approximation to the true conditional posterior for large masked regions is load-bearing for the outperformance statement, yet the manuscript provides no quantitative bound or diagnostic on the approximation error as a function of mask size.
- [Experimental section] Experimental section: while quantitative gains are reported on inpainting, deblurring, and super-resolution, the choice of baselines and the precise protocol for sampling from the variational posterior (number of optimization steps, temperature, etc.) must be stated explicitly to allow reproduction of the diversity and quality claims.
minor comments (3)
- [Abstract] The abstract states outperformance without any numbers or baselines; a one-sentence summary of the key quantitative result should be added.
- [Method] Notation for the variational parameters and the diffusion timestep indexing should be unified between the method derivation and the algorithm box.
- [Figures] Figure captions for the qualitative results should indicate the mask ratio and the backbone model used in each panel.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (hierarchical variational procedure): the claim that the Markov factorization yields a sufficiently accurate approximation to the true conditional posterior for large masked regions is load-bearing for the outperformance statement, yet the manuscript provides no quantitative bound or diagnostic on the approximation error as a function of mask size.
Authors: We agree that a quantitative assessment of the approximation quality would strengthen the presentation. Deriving a rigorous theoretical bound on the KL divergence for arbitrary mask sizes is intractable given the dimensionality and intractability of the true posterior. In the revision we will add empirical diagnostics, including ELBO values and sample-quality metrics plotted against mask size, together with a small-scale comparison against MCMC reference samples on synthetic data. revision: yes
-
Referee: [Experimental section] Experimental section: while quantitative gains are reported on inpainting, deblurring, and super-resolution, the choice of baselines and the precise protocol for sampling from the variational posterior (number of optimization steps, temperature, etc.) must be stated explicitly to allow reproduction of the diversity and quality claims.
Authors: We thank the referee for highlighting this reproducibility issue. The revised manuscript will explicitly list all baselines, the precise number of variational optimization steps, the temperature schedule, the optimizer settings, and the full sampling protocol used to generate the reported results. revision: yes
Circularity Check
No significant circularity; derivation is a standard variational construction
full rationale
The paper introduces a hierarchical variational inference procedure to approximate the conditional posterior of a pre-trained diffusion model for inpainting and related inverse problems. The abstract and method description present this as an explicit algorithmic construction with a non-Gaussian Markov variational family, an ELBO objective, and an optimization schedule supplied in the full text. No equations or claims reduce by construction to fitted inputs, self-citations, or renamed empirical patterns; the approximation quality is treated as an empirical modeling choice whose adequacy is assessed via downstream task performance rather than internal redefinition. The central performance claims rest on reproducible experiments across pixel and latent diffusion backbones, not on any load-bearing self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[2]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[3]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
-
[4]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 6840--6851. Curran Associates, Inc., 2020 a . URL https://proceedings.neurips.cc/paper_files/paper/2020/file/4c5bcfec8584af0d967...
work page 2020
-
[5]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021 a . URL https://openreview.net/forum?id=PxTIG12RRHS
work page 2021
-
[6]
Improved denoising diffusion probabilistic models
Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8162--8171. PMLR, 18--24 Jul 2021. URL https://proceedings.mlr.press/v139/nichol21a.html
work page 2021
-
[7]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alch\' e -Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/300...
work page 2019
-
[8]
Very deep \ vae \ s generalize autoregressive models and can outperform them on images
Rewon Child. Very deep \ vae \ s generalize autoregressive models and can outperform them on images. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=RLRXCV6DbEJ
work page 2021
-
[9]
NVAE : A deep hierarchical variational autoencoder
Arash Vahdat and Jan Kautz. NVAE : A deep hierarchical variational autoencoder. In Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[10]
Ladder Variational Autoencoders
Casper Kaae S nderby, Tapani Raiko, Lars Maal e, S ren Kaae S nderby, and Ole Winther. Ladder Variational Autoencoders . In Advances in Neural Information Processing Systems , 2016. URL https://proceedings.neurips.cc/paper/2016/file/6ae07dcb33ec3b7c814df797cbda0f87-Paper.pdf
work page 2016
-
[11]
Diffusion models beat GAN s on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GAN s on image synthesis. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=AAWuCvzaVt
work page 2021
-
[12]
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models. In Advances in Neural Information Processing Systems, 2021 a
work page 2021
-
[13]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Proc. NeurIPS, 2022
work page 2022
-
[14]
An introduction to variational autoencoders
Diederik P Kingma and Max Welling. An introduction to variational autoencoders. Foundations and Trends in Machine Learning, 12 0 (4): 0 307--392, 2019
work page 2019
-
[15]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 a . URL https://github.com/CompVis/latent-diffusionhttps://arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Score-based generative modeling in latent space
Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space. In Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[17]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
Zero-shot image restoration using denoising diffusion null-space model
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot image restoration using denoising diffusion null-space model. In The Eleventh International Conference on Learning Representations, 2023 a . URL https://openreview.net/forum?id=mRieQgMtNTQ
work page 2023
-
[19]
Denoising diffusion restoration models
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[20]
Improving diffusion models for inverse problems using manifold constraints
Hyungjin Chung, Byeongsu Sim, Dohoon Ryu, and Jong Chul Ye. Improving diffusion models for inverse problems using manifold constraints. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022 a . URL https://openreview.net/forum?id=nJJjv0JDJju
work page 2022
-
[21]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andr \'e s Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11451--11461, 2022. URL https://api.semanticscholar.org/CorpusID:246240274
work page 2022
-
[22]
Monte carlo guided denoising diffusion models for bayesian linear inverse problems
Gabriel Cardoso, Yazid Janati el idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided denoising diffusion models for bayesian linear inverse problems. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=nHESwXvxWK
work page 2024
-
[23]
Feng, Jamie Smith, Michael Rubinstein, Huiwen Chang, Katherine L
Berthy T. Feng, Jamie Smith, Michael Rubinstein, Huiwen Chang, Katherine L. Bouman, and William T. Freeman. Score-based diffusion models as principled priors for inverse imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10520--10531, October 2023
work page 2023
-
[24]
Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi S
Brian L. Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi S. Jaakkola. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=6TxBxqNME1Y
work page 2023
-
[25]
Diffusion posterior sampling for linear inverse problem solving: A filtering perspective
Zehao Dou and Yang Song. Diffusion posterior sampling for linear inverse problem solving: A filtering perspective. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=tplXNcHZs1
work page 2024
-
[26]
Stochastic solutions for linear inverse problems using the prior implicit in a denoiser
Zahra Kadkhodaie and Eero Simoncelli. Stochastic solutions for linear inverse problems using the prior implicit in a denoiser. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 13242--13254. Curran Associates, Inc., 2021. URL https://proceedings.neuri...
work page 2021
-
[27]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. In International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=9_gsMA8MRKQ
work page 2023
-
[28]
Diffusion models as plug-and-play priors
Alexandros Graikos, Nikolay Malkin, Nebojsa Jojic, and Dimitris Samaras. Diffusion models as plug-and-play priors. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=yhlMZ3iR7Pu
work page 2022
-
[29]
A variational perspective on solving inverse problems with diffusion models, 2023
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models, 2023
work page 2023
-
[30]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=OnD9zGAGT0k
work page 2023
-
[31]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18208--18218, June 2022
work page 2022
-
[32]
Solving linear inverse problems provably via posterior sampling with latent diffusion models
Litu Rout, Negin Raoof, Giannis Daras, Constantine Caramanis, Alex Dimakis, and Sanjay Shakkottai. Solving linear inverse problems provably via posterior sampling with latent diffusion models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=XKBFdYwfRo
work page 2023
- [33]
-
[34]
Solving inverse problems with latent diffusion models via hard data consistency
Bowen Song, Soo Min Kwon, Zecheng Zhang, Xinyu Hu, Qing Qu, and Liyue Shen. Solving inverse problems with latent diffusion models via hard data consistency. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=j8hdRqOUhN
work page 2024
-
[35]
M. J. Wainwright and M. I. Jordan. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning, 1: 0 1--305, 2008
work page 2008
-
[36]
Variational inference: A review for statisticians
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American statistical Association, 112 0 (518): 0 859--877, 2017
work page 2017
-
[37]
From patches to images: A nonparametric generative model
Geng Ji, Michael C Hughes, and Erik B Sudderth. From patches to images: A nonparametric generative model. In International Conference on Machine Learning, pages 1675--1683. PMLR, 2017
work page 2017
-
[38]
Sakshi Agarwal, Gabriel Hope, Ali Younis, and Erik B. Sudderth. A decoder suffices for query-adaptive variational inference. In Robin J. Evans and Ilya Shpitser, editors, Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, volume 216 of Proceedings of Machine Learning Research, pages 33--44. PMLR, 31 Jul--04 Aug 2023. URL...
work page 2023
-
[39]
Image inpainting via tractable steering of diffusion models
Anji Liu, Mathias Niepert, and Guy Van den Broeck. Image inpainting via tractable steering of diffusion models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=NSIVHTbZBR
work page 2024
-
[40]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. In ACM SIGGRAPH 2022 Conference Proceedings, SIGGRAPH '22, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450393379. doi:10.1145/3528233.3530757. URL https://doi.org/10.1145...
-
[41]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models, 2022
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models, 2022
work page 2022
-
[42]
Hyungjin Chung, Byeongsu Sim, and Jong Chul Ye. Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12413--12422, June 2022 b
work page 2022
-
[43]
On density estimation with diffusion models
Diederik P Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. On density estimation with diffusion models. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021 b . URL https://openreview.net/forum?id=2LdBqxc1Yv
work page 2021
-
[44]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 6840--6851. Curran Associates, Inc., 2020 b . URL https://proceedings.neurips.cc/paper_files/paper/2020/file/4c5bcfec8584af0d967...
work page 2020
-
[45]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Francis Bach and David Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 2256--2265, Lille, France, 07--09 Jul 2015. P...
work page 2015
-
[46]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2015, pages 234--241, Cham, 2015. Springer International Publishing. ISBN 978-3-319-24574-4
work page 2015
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018
work page 2018
-
[48]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj\"orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684--10695, June 2022 b
work page 2022
-
[49]
Solving inverse problems in medical imaging with score-based generative models
Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in medical imaging with score-based generative models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=vaRCHVj0uGI
work page 2022
-
[50]
Zero-shot image restoration using denoising diffusion null-space model
Yinhuai Wang, Jiwen Yu, and Jian Zhang. Zero-shot image restoration using denoising diffusion null-space model. The Eleventh International Conference on Learning Representations, 2023 b
work page 2023
-
[51]
Guanhua Zhang, Jiabao Ji, Yang Zhang, Mo Yu, Tommi S. Jaakkola, and Shiyu Chang. Towards coherent image inpainting using denoising diffusion implicit models. CoRR, abs/2304.03322, 2023. URL https://doi.org/10.48550/arXiv.2304.03322
-
[52]
Freedom: Training-free energy-guided conditional diffusion model
Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: Training-free energy-guided conditional diffusion model. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[53]
Lipschitz singularities in diffusion models
Zhantao Yang, Ruili Feng, Han Zhang, Yujun Shen, Kai Zhu, Lianghua Huang, Yifei Zhang, Yu Liu, Deli Zhao, Jingren Zhou, and Fan Cheng. Lipschitz singularities in diffusion models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WNkW0cOwiz
work page 2024
-
[54]
beta- VAE : Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta- VAE : Learning basic visual concepts with a constrained variational framework. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=Sy2fzU9gl
work page 2017
-
[55]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[56]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248--255. Ieee, 2009
work page 2009
-
[57]
Large scale image completion via co-modulated generative adversarial networks
Shengyu Zhao, Jonathan Cui, Yilun Sheng, Yue Dong, Xiao Liang, Eric I Chang, and Yan Xu. Large scale image completion via co-modulated generative adversarial networks. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[58]
Sutherland, Michael Arbel, and Arthur Gretton
Mikołaj Bińkowski, Dougal J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD GAN s. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=r1lUOzWCW
work page 2018
-
[59]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021 b . URL https://openreview.net/forum?id=St1giarCHLP
work page 2021
-
[60]
Prompt-tuning latent diffusion models for inverse problems, 2024
Hyungjin Chung, Jong Chul Ye, Peyman Milanfar, and Mauricio Delbracio. Prompt-tuning latent diffusion models for inverse problems, 2024. URL https://openreview.net/forum?id=ckzglrAMsh
work page 2024
-
[61]
A variational perspective on solving inverse problems with diffusion models
Morteza Mardani, Jiaming Song, Jan Kautz, and Arash Vahdat. A variational perspective on solving inverse problems with diffusion models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=1YO4EE3SPB
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.