Perturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP
Pith reviewed 2026-05-23 08:15 UTC · model grok-4.3
The pith
A fine-tuning procedure called PAR removes backdoors from CLIP models while preserving standard performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PAR is a fine-tuning mechanism that achieves high backdoor removal rates on poisoned CLIP models while maintaining good accuracy on clean inputs, and it remains effective when the fine-tuning data consists only of synthetic text-image pairs with no access to the poisoned dataset or trigger details.
What carries the argument
The Perturb and Recover (PAR) fine-tuning procedure, which applies targeted perturbations followed by recovery steps to overwrite backdoor behaviors.
If this is right
- Backdoored CLIP models can be cleaned after training without knowledge of the attack details.
- Synthetic image-text pairs are sufficient to remove backdoors in place of real training data.
- Standard performance on clean tasks is preserved during the backdoor removal process.
- The method applies across multiple model encoders and multiple types of structured backdoor attacks.
Where Pith is reading between the lines
- Deployment pipelines for web-sourced vision-language models could include PAR as a post-training sanitization step.
- Similar perturbation-and-recovery patterns might extend to removing unwanted behaviors in other large multimodal models.
- The success with synthetic data suggests backdoors may be encoded in ways that are easy to overwrite without the original trigger distribution.
- Repeated application of PAR could be tested to determine whether it prevents re-poisoning during later fine-tuning stages.
Load-bearing premise
Fine-tuning on synthetic or clean data can reliably erase backdoor associations created by unknown structured triggers.
What would settle it
An experiment in which PAR is applied to a backdoored CLIP model using synthetic data and the backdoor attack success rate on triggered inputs stays above 80 percent while clean accuracy remains unchanged.
Figures









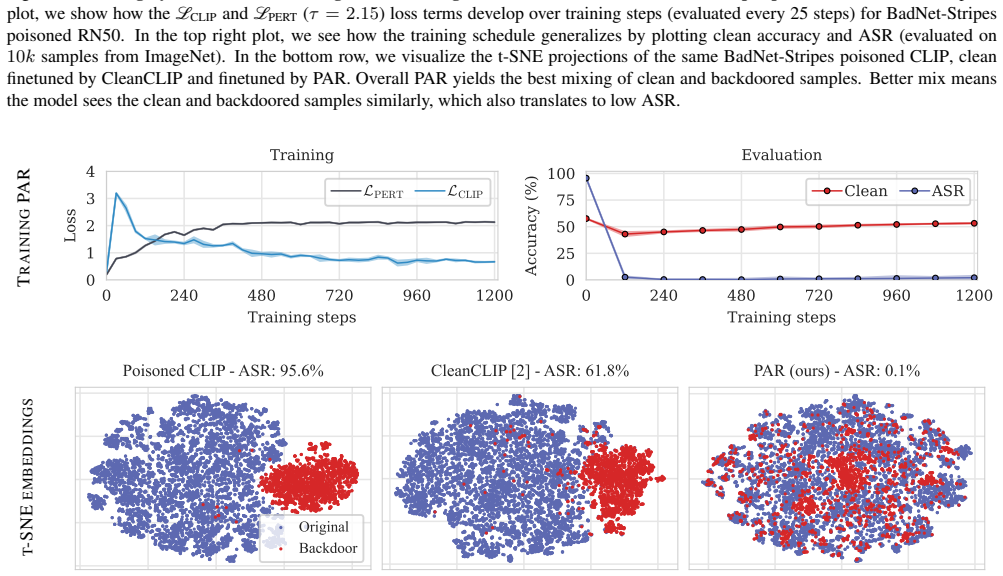
read the original abstract
Vision-Language models like CLIP have been shown to be highly effective at linking visual perception and natural language understanding, enabling sophisticated image-text capabilities, including strong retrieval and zero-shot classification performance. Their widespread use, as well as the fact that CLIP models are trained on image-text pairs from the web, make them both a worthwhile and relatively easy target for backdoor attacks. As training foundational models, such as CLIP, from scratch is very expensive, this paper focuses on cleaning potentially poisoned models via fine-tuning. We first show that existing cleaning techniques are not effective against simple structured triggers used in Blended or BadNet backdoor attacks, exposing a critical vulnerability for potential real-world deployment of these models. Then, we introduce PAR, Perturb and Recover, a surprisingly simple yet effective mechanism to remove backdoors from CLIP models. Through extensive experiments across different encoders and types of backdoor attacks, we show that PAR achieves high backdoor removal rate while preserving good standard performance. Finally, we illustrate that our approach is effective even only with synthetic text-image pairs, i.e. without access to real training data. The code and models are available on \href{https://github.com/nmndeep/PerturbAndRecover}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing backdoor cleaning methods fail against structured triggers (Blended, BadNet) in CLIP models, and introduces Perturb and Recover (PAR), a fine-tuning procedure that achieves high backdoor removal rates while preserving standard performance. It further claims effectiveness even when fine-tuning uses only synthetic image-text pairs, without access to the original poisoned dataset or trigger knowledge. These claims are supported by experiments across multiple encoders and attack types.
Significance. If the results hold, PAR provides a practical post-training defense for widely deployed CLIP models whose training data cannot be audited, addressing a real deployment risk at far lower cost than retraining. The public release of code and models on GitHub is a clear strength that supports reproducibility and follow-up work.
major comments (2)
- [Abstract] Abstract (paragraph on PAR and synthetic data experiments): the central claim that PAR severs backdoor associations for structured triggers using only synthetic data rests on the unexamined assumption that the perturb-and-recover process breaks the trigger mapping rather than merely suppressing it on the evaluated test triggers; no mechanistic analysis or ablation is supplied to distinguish these outcomes, even though the paper itself shows prior methods fail precisely on these triggers.
- [Experiments] Experiments section (synthetic-data results): the reported high removal rates on synthetic pairs do not include controls that would rule out the possibility that the synthetic distribution simply avoids the trigger manifold, leaving open whether the method generalizes when the backdoor is encoded in a manner that survives clean fine-tuning.
minor comments (2)
- [Abstract] The abstract describes PAR as 'surprisingly simple' without indicating the precise form of the perturbation operator or the recover objective; a short equation or pseudocode in the method section would improve clarity.
- Table or figure captions for the main results should explicitly state the number of runs and any statistical significance tests performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that revisions are warranted to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on PAR and synthetic data experiments): the central claim that PAR severs backdoor associations for structured triggers using only synthetic data rests on the unexamined assumption that the perturb-and-recover process breaks the trigger mapping rather than merely suppressing it on the evaluated test triggers; no mechanistic analysis or ablation is supplied to distinguish these outcomes, even though the paper itself shows prior methods fail precisely on these triggers.
Authors: We agree that a mechanistic distinction between severing the trigger association versus suppressing it on the specific evaluated triggers would strengthen the central claim. While our results show PAR succeeding where prior methods fail on structured triggers, we did not include ablations on trigger variations or embedding analyses. In revision we will add such an ablation (testing modified trigger patterns and comparing embedding shifts) to provide direct evidence that the mapping is disrupted. revision: yes
-
Referee: [Experiments] Experiments section (synthetic-data results): the reported high removal rates on synthetic pairs do not include controls that would rule out the possibility that the synthetic distribution simply avoids the trigger manifold, leaving open whether the method generalizes when the backdoor is encoded in a manner that survives clean fine-tuning.
Authors: This is a valid concern. The synthetic pairs were generated to approximate the diversity of the original data, yet we did not explicitly compare against standard fine-tuning on the identical synthetic distribution. In the revised manuscript we will add this control experiment to demonstrate that standard fine-tuning on the synthetic pairs leaves the backdoor largely intact while PAR removes it, thereby showing the removal is attributable to the perturb-and-recover procedure. revision: yes
Circularity Check
No circularity: empirical method validated by direct experiments
full rationale
The paper introduces PAR as a fine-tuning procedure and reports its performance via experiments on multiple encoders, attack types, and data regimes (including synthetic pairs). No equations, derivations, or first-principles predictions are claimed; the central results are measured outcomes on held-out test sets rather than quantities forced by construction from fitted parameters or self-referential definitions. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuning on clean or synthetic data can unlearn backdoor triggers without access to the original poisoned dataset.
Reference graph
Works this paper leans on
-
[1]
How to backdoor federated learning
Eugene Bagdasaryan, Andreas Veit, Yiqing Hua, Deborah Estrin, and Vitaly Shmatikov. How to backdoor federated learning. In AISTATS, 2020. 2
work page 2020
-
[2]
Cleanclip: Mitigating data poi- soning attacks in multimodal contrastive learning
Hritik Bansal, Nishad Singhi, Yu Yang, Fan Yin, Aditya Grover, and Kai-Wei Chang. Cleanclip: Mitigating data poi- soning attacks in multimodal contrastive learning. In ICCV,
-
[3]
A new backdoor attack in cnns by training set corruption without label poisoning
Mauro Barni, Kassem Kallas, and Benedetta Tondi. A new backdoor attack in cnns by training set corruption without label poisoning. In 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019. 2, 1
work page 2019
-
[4]
Strong data augmentation sanitizes poi- soning and backdoor attacks without an accuracy tradeoff
Eitan Borgnia, Valeriia Cherepanova, Liam Fowl, Amin Ghiasi, Jonas Geiping, Micah Goldblum, Tom Goldstein, and Arjun Gupta. Strong data augmentation sanitizes poi- soning and backdoor attacks without an accuracy tradeoff. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE,
work page 2021
-
[5]
Coyo-700m: Image-text pair dataset
Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, and Saehoon Kim. Coyo-700m: Image-text pair dataset. https://github.com/kak aobrain/coyo-dataset, 2022. 3
work page 2022
-
[6]
Poisoning and back- dooring contrastive learning
Nicholas Carlini and Andreas Terzis. Poisoning and back- dooring contrastive learning. In ICLR, 2022. 2
work page 2022
-
[7]
Poisoning web-scale training datasets is practical
Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum An- derson, Andreas Terzis, Kurt Thomas, and Florian Tram `er. Poisoning web-scale training datasets is practical. In 2024 IEEE Symposium on Security and Privacy (SP). IEEE Com- puter Society, 2024. 1, 2, 3
work page 2024
-
[8]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv preprint arXiv:1712.05526 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhang- hao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yong- hao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023. 1
work page 2023
-
[10]
Autoaugment: Learning augmentation strategies from data
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasude- van, and Quoc V Le. Autoaugment: Learning augmentation strategies from data. In CVPR, 2019. 2, 4
work page 2019
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 1
work page 2009
-
[12]
Improved Regularization of Convolutional Neural Networks with Cutout
Terrance DeVries. Improved regularization of convo- lutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017. 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Defend- ing backdoor attacks on vision transformer via patch process- ing
Khoa D Doan, Yingjie Lao, Peng Yang, and Ping Li. Defend- ing backdoor attacks on vision transformer via patch process- ing. In AAAI, 2023. 2
work page 2023
-
[14]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Dat- acomp: In search of the next generation of multimodal datasets
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Dat- acomp: In search of the next generation of multimodal datasets. In NeurIPS, 2024. 1
work page 2024
-
[16]
Backdoor defense via adaptively splitting poisoned dataset
Kuofeng Gao, Yang Bai, Jindong Gu, Yong Yang, and Shu- Tao Xia. Backdoor defense via adaptively splitting poisoned dataset. In CVPR, 2023. 3
work page 2023
-
[17]
Watermarking pre- trained language models with backdooring
Chenxi Gu, Chengsong Huang, Xiaoqing Zheng, Kai- Wei Chang, and Cho-Jui Hsieh. Watermarking pre- trained language models with backdooring. arXiv preprint arXiv:2210.07543, 2022. 2
-
[18]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Bad- nets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733, 2017. 1, 2, 3, 4, 6, 7, 8, 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Badnets: Evaluating backdooring attacks on deep neu- ral networks
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neu- ral networks. IEEE Access, 7, 2019. 2
work page 2019
-
[20]
Hasan Abed Al Kader Hammoud, Hani Itani, Fabio Pizzati, Adel Bibi, and Bernard Ghanem. Synthclip: Are we ready for a fully synthetic clip training? In Synthetic Data for Computer Vision Workshop@ CVPR, 2024. 8, 1
work page 2024
-
[21]
Defending our privacy with backdoors
Dominik Hintersdorf, Lukas Struppek, Daniel Neider, and Kristian Kersting. Defending our privacy with backdoors. In NeurIPS 2023 Workshop on Backdoors in Deep Learning - The Good, the Bad, and the Ugly, 2024. 2
work page 2023
-
[22]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. 1
work page 2021
-
[23]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021. 1
work page 2021
-
[24]
Baden- coder: Backdoor attacks to pre-trained encoders in self- supervised learning
Jinyuan Jia, Yupei Liu, and Neil Zhenqiang Gong. Baden- coder: Backdoor attacks to pre-trained encoders in self- supervised learning. In 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022. 2 9
work page 2022
-
[25]
Adversarial backdoor defense in clip
Junhao Kuang, Siyuan Liang, Jiawei Liang, Kuanrong Liu, and Xiaochun Cao. Adversarial backdoor defense in clip. arXiv preprint arXiv:2409.15968, 2024. 3
-
[26]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML,
-
[27]
Invisible backdoor attacks on deep neural networks via steganography and regularization
Shaofeng Li, Minhui Xue, Benjamin Zi Hao Zhao, Haojin Zhu, and Xinpeng Zhang. Invisible backdoor attacks on deep neural networks via steganography and regularization. IEEE Transactions on Dependable and Secure Computing , 18(5),
-
[29]
Neural attention distillation: Erasing back- door triggers from deep neural networks
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma. Neural attention distillation: Erasing back- door triggers from deep neural networks. In ICLR, 2021. 2
work page 2021
-
[30]
Badclip: Dual- embedding guided backdoor attack on multimodal con- trastive learning
Siyuan Liang, Mingli Zhu, Aishan Liu, Baoyuan Wu, Xiaochun Cao, and Ee-Chien Chang. Badclip: Dual- embedding guided backdoor attack on multimodal con- trastive learning. In CVPR, 2024. 1, 2, 5, 6, 7, 8, 4
work page 2024
-
[31]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In CVPR, 2024. 1, 4
work page 2024
-
[32]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 1
work page 2014
-
[33]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In CVPR,
-
[34]
Re- flection backdoor: A natural backdoor attack on deep neural networks
Yunfei Liu, Xingjun Ma, James Bailey, and Feng Lu. Re- flection backdoor: A natural backdoor attack on deep neural networks. In ECCV, 2020. 2
work page 2020
-
[35]
Wanet - impercepti- ble warping-based backdoor attack
Tuan Anh Nguyen and Anh Tuan Tran. Wanet - impercepti- ble warping-based backdoor attack. In ICLR, 2021. 2, 6, 7, 1
work page 2021
-
[36]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In ICML, 2021. 1, 4, 6
work page 2021
-
[37]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. In CVPR, 2022. 8
work page 2022
-
[38]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. In NeurIPS, 2022. 1, 3
work page 2022
-
[39]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. In ACL,
- [40]
-
[41]
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9 (86), 2008. 6
work page 2008
-
[42]
Haonan Wang, Qianli Shen, Yao Tong, Yang Zhang, and Kenji Kawaguchi. The stronger the diffusion model, the eas- ier the backdoor: Data poisoning to induce copyright breach- eswithout adjusting finetuning pipeline. In ICML, 2024. 2
work page 2024
-
[43]
CogVLM: Visual Expert for Pretrained Language Models
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Yifei Wang, Wenhan Ma, Stefanie Jegelka, and Yisen Wang. How to craft backdoors with unlabeled data alone? In ICLR 2024 Workshop on Navigating and Addressing Data Prob- lems for Foundation Models, 2024. 2
work page 2024
-
[45]
Eda: Easy data augmentation tech- niques for boosting performance on text classification tasks
Jason Wei and Kai Zou. Eda: Easy data augmentation tech- niques for boosting performance on text classification tasks. In ACL, 2019. 4
work page 2019
-
[46]
Adversarial neuron pruning purifies backdoored deep models
Dongxian Wu and Yisen Wang. Adversarial neuron pruning purifies backdoored deep models. In NeurIPS, 2021. 2
work page 2021
-
[47]
Robust contrastive language-image pretraining against data poisoning and backdoor attacks
Wenhan Yang, Jingdong Gao, and Baharan Mirzasoleiman. Robust contrastive language-image pretraining against data poisoning and backdoor attacks. In NeurIPS, 2023. 1, 2, 3, 7
work page 2023
-
[48]
Better safe than sorry: Pre-training clip against targeted data poisoning and backdoor attacks
Wenhan Yang, Jingdong Gao, and Baharan Mirzasoleiman. Better safe than sorry: Pre-training clip against targeted data poisoning and backdoor attacks. In ICML, 2024. 2, 3
work page 2024
-
[49]
Data poisoning attacks against multimodal encoders
Ziqing Yang, Xinlei He, Zheng Li, Michael Backes, Mathias Humbert, Pascal Berrang, and Yang Zhang. Data poisoning attacks against multimodal encoders. In ICML, 2023. 2
work page 2023
-
[50]
Enhancing fine-tuning based backdoor defense with sharpness-aware minimization
Mingli Zhu, Shaokui Wei, Li Shen, Yanbo Fan, and Baoyuan Wu. Enhancing fine-tuning based backdoor defense with sharpness-aware minimization. In ICCV, 2023. 2
work page 2023
-
[51]
Neural polarizer: A lightweight and effective backdoor de- fense via purifying poisoned features
Mingli Zhu, Shaokui Wei, Hongyuan Zha, and Baoyuan Wu. Neural polarizer: A lightweight and effective backdoor de- fense via purifying poisoned features. In NeurIPS, 2024. 2, 3 10 Perturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP Supplementary Material Contents
work page 2024
-
[52]
App. A . . . Experimental details and discussions
-
[53]
App. B . . . Additional experiments
-
[54]
App. C . . . More visualizations A. Experimental Details and Discussions In this section we detail the setup related to all the ex- periments conducted in this work. We detail how we se- lect training hyperparameters like batch size (BS), learning rate (LR), datasets used, optimizer, etc., for poisoning and cleaning across methods and models. All experime...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.