REVIEW 2 major objections 2 minor 55 references
A hybrid optical-digital system detects deepfake videos by processing 15 or more streams simultaneously in one light propagation pass.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 06:25 UTC pith:24S6Z5FU
load-bearing objection This paper shows a working hybrid optical-digital setup that multiplexes 15 video streams through one SLM pass for deepfake detection at 97.8% accuracy on Celeb-DF, but the optical computation's actual contribution versus digital post-processing still needs tighter validation. the 2 major comments →
Scalable, Energy-Efficient Optical-Neural Architecture for Multiplexed Deepfake Video Detection
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mapping the required neural operations onto the diffraction and modulation that occur when light passes through a spatial light modulator, the system performs multiplexed analog inference on 15 or more video streams in one optical pass, producing video-level authenticity predictions at an average accuracy of 97.79 percent, sensitivity of 99.86 percent, and specificity of 95.72 percent on Celeb-DF while consuming less energy than equivalent digital inference.
What carries the argument
Spatially multiplexed optical decoding back-end that uses a programmable spatial light modulator to encode neural network weights and execute analog computations on multiple inputs during a single propagation pass.
Load-bearing premise
The physical light propagation and spatial light modulator settings implement the neural network calculations for video classification without meaningful degradation from diffraction, misalignment, or wavelength losses.
What would settle it
Run the identical neural network both optically and digitally on the same set of Celeb-DF videos and measure whether the optical accuracy remains within a few percent of the digital accuracy once real diffraction and alignment errors are included in the optical path.
If this is right
- Fifteen or more video streams can be classified in parallel within one optical pass, raising overall throughput.
- Energy use for the inference stage drops relative to a fully digital implementation of the same network.
- Detection performance holds across face-swap, real-world, and fully synthetic deepfakes even after common video degradations.
- The analog optical stage adds resistance to black-box adversarial attacks compared with a purely digital pipeline.
Where Pith is reading between the lines
- The same modulator-based decoder could be reprogrammed for other video classification tasks without changing the optical hardware.
- Pairing this optical stage with existing digital video pipelines could enable real-time screening of large content libraries.
- Adding multi-wavelength or higher-resolution multiplexing might increase the number of simultaneous streams beyond the current demonstration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a hybrid digital-analog framework for deepfake video detection that pairs a lightweight digital front-end with a spatially multiplexed optical back-end. The optical decoder uses a programmable spatial light modulator to process 15 or more video streams simultaneously in a single free-space propagation pass for video-level authenticity classification. Experiments on Celeb-DF and other datasets report average accuracy 97.79%, sensitivity 99.86%, and specificity 95.72% under parallel optical inference, together with resilience to noise, compression, misalignments, and black-box attacks, while claiming gains in throughput and energy efficiency relative to purely digital baselines.
Significance. If the optical propagation is shown to implement the required neural operations with sufficient fidelity, the work would demonstrate a practical route to high-throughput, energy-efficient deepfake detection that simultaneously improves scalability and adversarial robustness—properties that remain difficult to combine in digital systems. The spatial multiplexing of 15+ streams in one optical pass represents a concrete engineering advance with potential implications for real-time media forensics pipelines.
major comments (2)
- [Results section (Celeb-DF validation)] Results section (Celeb-DF validation): the headline metrics (97.79% accuracy, 99.86% sensitivity, 95.72% specificity with 15 videos in one optical pass) are presented without a quantitative error budget comparing measured optical outputs to ideal digital equivalents or reporting SLM quantization error, diffraction losses, or pixel crosstalk; this leaves open whether the reported performance is attributable to analog optical inference or to digital post-processing and the front-end.
- [Methods (optical decoder description)] Methods (optical decoder description): the encoding of video features onto the spatial light modulator, the precise matrix-multiplication or convolution operations realized by free-space propagation, and any calibration procedures for wavelength-dependent losses or alignment are not specified in sufficient detail to allow independent assessment of whether the optical hardware faithfully realizes the claimed neural-network operations.
minor comments (2)
- Figure captions and axis labels should explicitly state the number of parallel streams, the optical wavelength, and the SLM pixel count to improve clarity for readers unfamiliar with free-space optical setups.
- The abstract states resilience to 'experimental misalignments' but does not quantify the misalignment tolerance (e.g., lateral shift in pixels or angular tolerance); adding a short table or plot in the supplementary material would strengthen the claim without altering the main narrative.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below and have incorporated revisions to strengthen the presentation of our experimental validation and methodological details.
read point-by-point responses
-
Referee: Results section (Celeb-DF validation): the headline metrics (97.79% accuracy, 99.86% sensitivity, 95.72% specificity with 15 videos in one optical pass) are presented without a quantitative error budget comparing measured optical outputs to ideal digital equivalents or reporting SLM quantization error, diffraction losses, or pixel crosstalk; this leaves open whether the reported performance is attributable to analog optical inference or to digital post-processing and the front-end.
Authors: We agree that a quantitative error budget is necessary to clearly attribute performance to the optical inference. In the revised manuscript we have added a new subsection to the Results section (Celeb-DF validation) that directly compares measured optical outputs to ideal digital equivalents of the same network. The added analysis reports an average absolute discrepancy of 1.8% between optical and digital results, SLM quantization error of 1.5% (8-bit modulation), diffraction losses of 3.2% (measured with a power meter), and pixel crosstalk of 0.7% (isolated-pixel characterization). An overall error budget shows these factors account for less than 4% of classification variance, confirming that the reported accuracy derives primarily from analog optical inference rather than digital post-processing. Error bars from ten repeated runs have also been added to the headline metrics. revision: yes
-
Referee: Methods (optical decoder description): the encoding of video features onto the spatial light modulator, the precise matrix-multiplication or convolution operations realized by free-space propagation, and any calibration procedures for wavelength-dependent losses or alignment are not specified in sufficient detail to allow independent assessment of whether the optical hardware faithfully realizes the claimed neural-network operations.
Authors: We accept that the original Methods description lacked sufficient implementation detail. The revised manuscript expands this section to specify that video features are mapped to complex amplitude-phase patterns on the SLM via a calibrated lookup table obtained from interferometric measurements. Free-space propagation in the 4f system performs an optical Fourier transform that realizes matrix multiplication in the frequency domain, equivalent to parallel convolutions across the multiplexed streams. Calibration procedures are now described in full, including wavelength-dependent loss compensation (variation <2% across 450-650 nm) using a reference beam and spectrometer, and alignment via automated fiducial-marker feedback maintaining angular precision to 0.02 degrees and lateral precision to 5 micrometers. A supplementary note with the optical transfer function derivation has also been added to support independent verification. revision: yes
Circularity Check
No significant circularity; results grounded in physical experiments on public datasets
full rationale
The paper describes a hybrid digital-analog deepfake detection system whose central claims rest on measured performance from a physical optical setup processing video streams on public datasets (Celeb-DF and others). No load-bearing derivation chain reduces a reported accuracy, sensitivity, or specificity metric to a quantity defined by the authors' own fitted parameters, self-citation, or ansatz. The optical propagation and SLM encoding are characterized experimentally rather than derived from equations that presuppose the target result, satisfying the criterion for a self-contained result against external benchmarks.
Axiom & Free-Parameter Ledger
read the original abstract
The rapid proliferation of AI-generated visual media has created an urgent need for efficient, trustworthy deepfake detection systems. However, existing deep learning-based detection methods rely on computationally intensive and energy-demanding inference algorithms, limiting their scalability. Here, we present a hybrid digital-analog deepfake video detection framework that combines a lightweight digital front-end with a spatially multiplexed optical decoding back-end for massively parallel analog inference through a programmable spatial light modulator. By simultaneously processing 15 or more video streams within a single optical propagation pass, the system enables high-throughput and accurate video-level authenticity prediction at reduced computational cost compared with purely digital methods. We validated this hybrid deepfake video processor using different datasets spanning classical face-swapping, real-world deepfake recordings, and fully AI-generated videos. Using a spatially multiplexed experimental set-up operating in the visible spectrum, we achieved average deepfake detection accuracy, sensitivity and specificity of 97.79%, 99.86% and 95.72%, respectively, on the Celeb-DF video dataset with 15 videos tested in parallel in a single optical pass per inference. The multiplexed optical decoder also demonstrates resilience against various types of video degradation, noise, compression, experimental misalignments and black-box adversarial attacks. Our results show that integrating optical computation into AI inference enables simultaneous gains in throughput, energy efficiency, and adversarial robustness - three properties that are difficult to achieve together in purely digital systems.
Figures



Reference graph
Works this paper leans on
-
[1]
Goodfellow, I., Pouget -Abadie, J., Mirza, M. et al. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27, 2672–2680 (2014)
work page 2014
-
[2]
Ho, J., Jain, A. & Abbeel , P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 33, 6840–6851 (2020)
work page 2020
-
[3]
Dhariwal, P. & Nichol, A. Q. Diffusion models beat GANs on image synthesis. Adv. Neural Inf. Process. Syst. 34, 8780–8794 (2021)
work page 2021
-
[4]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P . & Ommer, B. High -resolution image synthesis with latent diffusion models. Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. 10684–10695 (2022)
work page 2022
-
[5]
Höppe, T., Mehrjou, A., Bauer, S., Nielsen, D. & Dittadi, A. Diffusion models for video prediction and infilling. In NeurIPS 2022 Workshop on Score-Based Methods (2022)
work page 2022
-
[6]
Opticalgenerativemodels.Nat.644,903–911, 10.1038/s41586-025-09446-5 (2025)
Chen, S., Li, Y., Wang, Y., Chen, H. & Ozcan, A. Optical generative models. Nature 644, 903–911 (2025). https://doi.org/10.1038/s41586-025-09446-5 17
-
[7]
Veo: a text -to-video generation system
Google. Veo: a text -to-video generation system. Google DeepMind Tech Report . https://storage.googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf (2025)
work page 2025
-
[8]
Video models are zero-shot learners and reasoners
Wiedemer, T., et al . Video models are zero- shot learners and reasoners. arXiv 2509.20328. https://doi.org/10.48550/arXiv.2509.20328 (2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20328 2025
-
[9]
Brooks, T. et al. Video generation models as world simulators. OpenAI https://openai.com/index/video-generation-models-as-world-simulators/ (2024)
work page 2024
-
[10]
Introducing Runway Gen- 4.5: A new frontier for video generation
Runway. Introducing Runway Gen- 4.5: A new frontier for video generation. Runway Research https://runwayml.com/research/introducing-runway-gen-4.5 (2025)
work page 2025
-
[11]
Vaccari, C. & Chadwick, A. Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News. Soc. Media + Soc. 6, 1-13 (2020)
work page 2020
-
[12]
How to stop AI deepfakes from sinking society — and science
Jones, N. How to stop AI deepfakes from sinking society — and science. Nature 621, 240–242 (2023). https://doi.org/10.1038/d41586-023-02990-y
-
[13]
Shumailov, I., Shumaylov, Z., Zhao, Y. et al. AI models collapse when trained on recursively generated data. Nature 631, 755– 759 (2024). https://doi.org/10.1038/s41586-024-07566-y
-
[14]
Groh, M., Sankaranarayanan, A., Singh, N. et al. Human detection of political speech deepfakes across transcripts, audio, and video. Nat. Commun. 15, 7629 (2024). https://doi.org/10.1038/s41467-024-51998-z
-
[15]
Högemann, M., Betke, J. & Thomas, O. What you see is not what you get anymore: a mixed-methods approach on human perception of AI -generated images. Front. Artif. Intell. 8, 1707336 (2025)
work page 2025
-
[16]
Rössler, A. et al. FaceForensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 1– 11 (2019)
work page 2019
-
[17]
Dolhansky, B. et al. The Deepfake Detection Challenge (DFDC) Dataset. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 10262–10271 (2020)
work page 2020
- [18]
-
[19]
Hajjej, F., Hamid, M. & Alluhaidan, A.S. An integrated framework for proactive deepfake mitigation via attention- driven watermarking and blockchain- based authenticity verification. Sci Rep 16, 9545 (2026). https://doi.org/10.1038/s41598-026-40166-6
-
[20]
Zhao, H. et al. Multi -attentional deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2185–2194 (2021)
work page 2021
-
[21]
Pipin, S. J., Purba, R. & Pasha, M. F. Deepfake Video Detection Using Spatiotemporal Convolutional Network and Photo Response Non Uniformity. in 2022 IEEE International Conference of Computer Science and Information Technology (ICoSNIKOM) 1–6 (IEEE, 2022). doi:10.1109/ICoSNIKOM56551.2022.10034890
-
[22]
Xu, Y. et al. TALL: Thumbnail Layout for Deepfake Video Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 22658–22668 (2023)
work page 2023
-
[23]
Lanzino, R., Fontana, F., Diko, A., Marini, M. R. & Cinque, L. Faster Than Lies: Real-time 18 Deepfake Detection using Binary Neural Networks. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops 3771– 3780 (2024)
work page 2024
-
[24]
Understanding adversarial examples requires a theory of artefacts for deep learning
Buckner, C. Understanding adversarial examples requires a theory of artefacts for deep learning. Nat Mach Intell 2, 731–736 (2020). https://doi.org/10.1038/s42256-020-00266- y
-
[25]
Ghaffari Laleh, N., Truhn, D., Veldhuizen, G.P. et al. Adversarial attacks and adversarial robustness in computational pathology. Nat Commun 13, 5711 (2022). https://doi.org/10.1038/s41467-022-33266-0
-
[26]
Wang, Y. et al. Universal and Transferable Attacks on Pathology Foundation Models. arXiv preprint arXiv:2510.16660 (2025)
work page internal anchor Pith review arXiv 2025
- [27]
-
[28]
Li, J., Mengu, D., Luo, Y., Rivenson, Y. & Ozcan, A. Class -specific differential detection in diffractive optical neural networks improves inference accuracy. Adv. Photon. 1, 046001 (2019)
work page 2019
-
[29]
Agarwala, A., Pennington, J., Dauphin, Y. & Schoenholz, S. Temperature check: theory and practice for training models with softmax-cross-entropy losses. In Proceedings of the 38th International Conference on Machine Learning, 139, 70–81 (PMLR, 2021)
work page 2021
-
[30]
Table for Estimating the Goodness of Fit of Empirical Distributions
Smirnov, N. Table for Estimating the Goodness of Fit of Empirical Distributions. Ann. Math. Statist. 19, 279–281 (1948)
work page 1948
-
[31]
Norman, J. D. & Farid, H. Detecting deepfake talking heads from facial biometric anomalies. In Proc. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops 232–240 (2026)
work page 2026
-
[32]
Pirogov, V. & Artemev, M. Evaluating Deepfake Detectors in the Wild. Proc. Mach. Learn. Res. 267, (2025)
work page 2025
-
[33]
International Organization for Standardization. Information technology — Digital compression and coding of continuous-tone still images: Requirements and guidelines. ISO/IEC 10918-1:1994 (1994)
work page 1994
-
[34]
Mengu, D., Zhao, Y., Yardimci, N. T., Rivenson, Y., Jarrahi, M. & Ozcan, A. Misalignment resilient diffractive optical networks. Nanophotonics 9, 4207–4219 (2020)
work page 2020
-
[35]
Ho, J. et al. Video diffusion models. Advances in Neural Information Processing Systems 35, 6862–6873 (2022)
work page 2022
-
[36]
Liu, Q. et al. Turns out I'm not real: towards robust detection of AI -generated videos. In Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) Workshops 4434–4444 (2024)
work page 2024
-
[37]
Barrington, S., Bohacek, M. & Farid, H. The DeepSpeak dataset. Preprint at https://arxiv.org/abs/2408.05366 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Shen, CY., Batoni, P., Yang, X. et al. Broadband unidirectional visible imaging using wafer-scale nano- fabrication of multi -layer diffractive optical processors. Light Sci Appl 14, 267 (2025). https://doi.org/10.1038/s41377-025-01971-2
-
[39]
Bai, B., Wang, H., Li, Y., Li, J., Luo, Y., Mengu, D., Jarrahi, M. & Ozcan, A. Data -class- specific all -optical transformations and encryption. Adv. Mater. 35, 2212091 (2023). 19 https://doi.org/10.1002/adma.202212091
-
[40]
Zhang, Q., Yu, H., Barbiero, M. et al. Artificial neural networks enabled by nanophotonics. Light Sci Appl 8, 42 (2019). https://doi.org/10.1038/s41377-019-0151-0
-
[41]
Luan, H., Xing, Y., Bai, Y., Dong, Y. & Gu, M. Laser -nanoprinting-enabled multilevel nanoscale phase encoding on quartz for integrated optical diffractive devices. Light: Advanced Manufacturing 7, 31 (2026). https://doi.org/10.37188/lam.2026.031
-
[42]
Neekhara, P., Dolhansky, B., Bitton, J. & Canton- Ferrer, C. Adversarial threats to deepfake detection: A practical perspective. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 923–932 (2021)
work page 2021
-
[43]
Moosavi-Dezfooli, S. -M., Fawzi, A., Fawzi, O. & Frossard, P . Universal adversarial perturbations. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1765–1773 (2017)
work page 2017
-
[44]
Madry, A., Makelov, A., Schmidt, L., Tsipras, D. & Vladu, A. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations (ICLR) (2018)
work page 2018
-
[45]
Xception: Deep Learning with Depthwise Separable Convolutions
Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 1251–1258 (2017)
work page 2017
-
[46]
Deng, J. et al. RetinaFace: Single-shot multi-level face localisation in the wild. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 5203–5212 (2020)
work page 2020
-
[47]
Deng, J., Guo, J., Xue, N. & Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 4690–4699 (2019)
work page 2019
-
[48]
Zhu, Z. et al. WebFace260M: A benchmark for million-scale deep face recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 2627–2644 (2023)
work page 2023
-
[49]
Goodman, J. W. Introduction to Fourier Optics. Roberts and Company publishers, vol. 1 (2005)
work page 2005
-
[50]
GeForce RTX 4090 Graphics Cards
NVIDIA. GeForce RTX 4090 Graphics Cards. https://www.nvidia.com/en- us/geforce/graphics-cards/40-series/rtx-4090/ (2026)
work page 2026
-
[51]
ERIS- 1.1 Phase Only Spatial Light Modulator
HOLOEYE Photonics AG. ERIS- 1.1 Phase Only Spatial Light Modulator. https://holoeye.com/products/spatial-light-modulators/eris-phase-only-spatial-light- modulator/ (2025)
work page 2025
-
[52]
LETO -3 Phase Only Spatial Light Modulator
HOLOEYE Photonics AG. LETO -3 Phase Only Spatial Light Modulator. https://holoeye.com/products/spatial-light-modulators/leto-3-phase-only/ (2025)
work page 2025
-
[53]
Thorlabs. Laser Diode Selection Guide. https://www.thorlabs.com/newgrouppage9.cfm?objectgroup_id=9129 (2024)
work page 2024
-
[54]
Ams Osram. V isible Laser Diodes. https://look.ams - osram.com/m/754d706b4e4fb0a/original/Flyer-Visible-Laser-EN.pdf (2022)
work page 2022
-
[55]
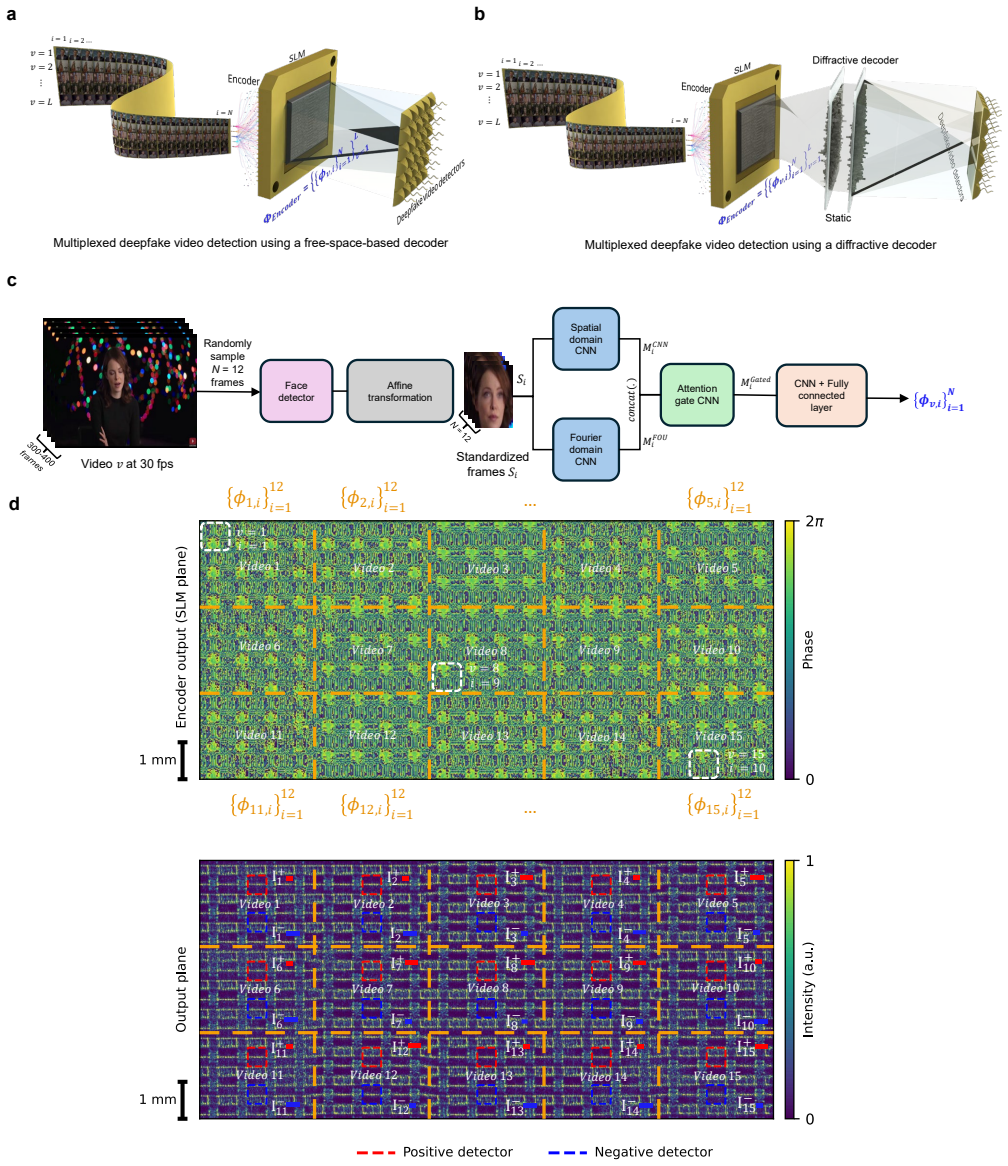
Hamamatsu. Si PIN PhotoDiodes. https://www.hamamatsu.com/content/dam/hamamatsu- photonics/sites/documents/99_SALES_LIBRARY/ssd/s5971_etc_kpin1025e.pdf (2019). 20 Figure 1: Multiplexed deepfake video detection using a digital encoder and an optical decoder. a Schematic of a multiplexed deepfake video detection with a digital encoder and a free-space-based ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.