Multilingual Coreference Resolution via Cycle-Consistent Machine Translation
Pith reviewed 2026-06-28 05:49 UTC · model grok-4.3
The pith
Machine translation with back-translation validation generates usable coreference training data for low-resource languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
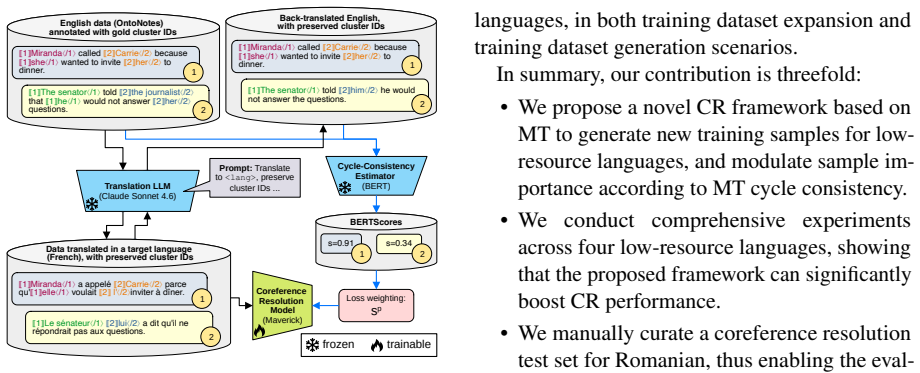
The authors claim that a pipeline which translates English coreference-annotated text to a low-resource language, back-translates it, scores the round-trip fidelity via BERT cosine similarity, and weights each training instance by that score produces a model whose coreference performance on the target language improves substantially over direct transfer or unweighted translation baselines.
What carries the argument
Cycle-consistency weighting: back-translation followed by BERT-space cosine similarity used as a continuous weight inside the loss to down-weight noisy machine-translated coreference chains.
If this is right
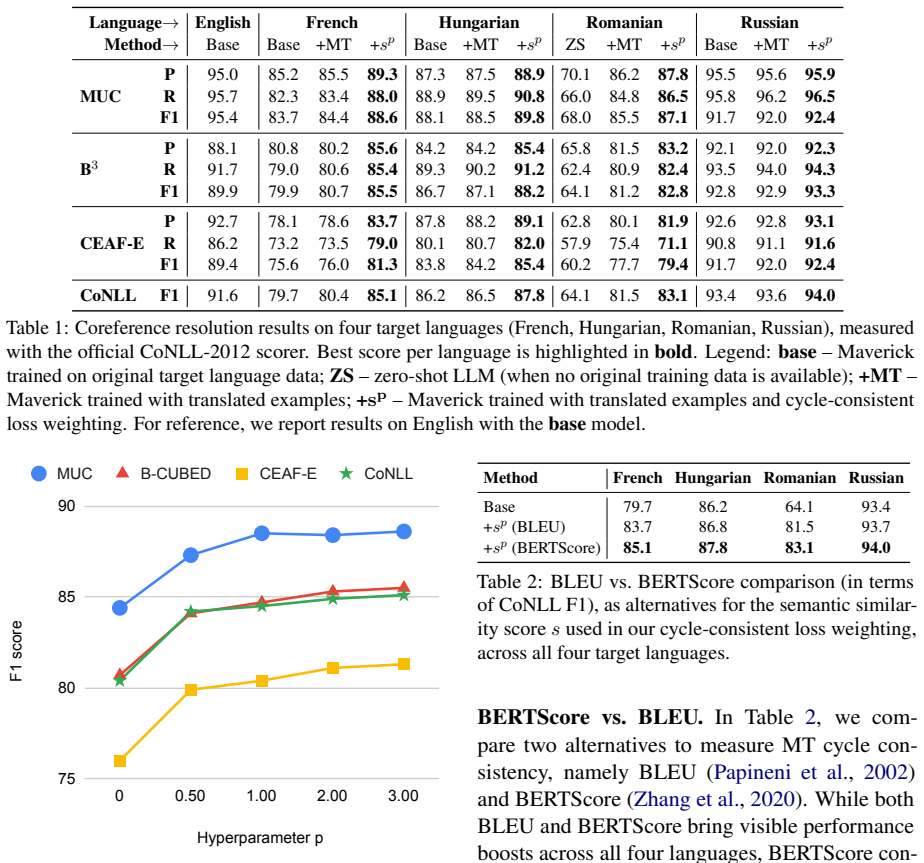
- Significant F1 gains on four low-resource languages.
- Working coreference systems become available for languages that had no prior annotated corpora.
- The similarity-weighted loss can be applied whenever English data is machine-translated for any sequence-labeling task.
- The same back-translation check can serve as an automatic filter before any human review of translated annotations.
Where Pith is reading between the lines
- The same weighting idea could be tested on other cross-lingual transfer tasks such as named-entity recognition or dependency parsing where annotation transfer is also the bottleneck.
- If the BERT similarity correlates with human judgments of coreference fidelity, the method supplies a cheap way to rank or filter any machine-translated corpus without new human labels.
- An iterative loop could be formed by using the resulting coreference model to correct or re-rank the translated chains and then retrain.
- The approach implicitly assumes that coreference structure is largely language-independent once lexical items are aligned, which may break for languages with very different pronoun or zero-anaphora systems.
Load-bearing premise
That the cosine similarity between an original English sentence and its back-translation in BERT space is a faithful proxy for whether the coreference links survived the forward translation intact.
What would settle it
Train the weighted model on the four reported languages and measure whether F1 on held-out native test sets falls below the unweighted translation baseline or the English-only baseline.
Figures
read the original abstract
Coreference resolution is a core NLP task, having a broad range of downstream applications, e.g.~machine translation, question answering, document summarization, etc. While the task is well-studied in English, comparatively less attention is dedicated to coreference resolution in other languages, especially low-resource ones. To mitigate this gap, we propose a novel coreference resolution pipeline that harnesses machine translation (MT) from English to a target low-resource language, to generate or expand training data. To automatically validate the quality of the translated samples, we back-translate the samples and assess the similarity with the original English samples via cosine similarity in the latent space of a BERT model. The resulting similarity scores are integrated into the loss function to weight training samples according to their MT cycle consistency. Extensive experiments on four low-resource languages show that our pipeline brings significant performance gains in coreference resolution. Moreover, our pipeline enables accurate coreference resolution in languages where no previous corpora were available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a pipeline for multilingual coreference resolution that translates English-annotated data to low-resource target languages via MT, back-translates the outputs, computes cycle-consistency scores as BERT cosine similarity between originals and back-translations, and weights training samples in the loss by these scores. It claims this yields significant performance gains on four low-resource languages and enables accurate coreference resolution in languages lacking prior corpora.
Significance. If the empirical claims hold after validation of the weighting proxy, the method could offer a practical route to bootstrap coreference data for low-resource languages using existing English resources and MT. No machine-checked proofs, reproducible code, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the central claim of 'significant performance gains' and 'accurate' coreference resolution supplies no quantitative results, baselines, specific languages, metrics, or error analysis, leaving the empirical contribution unverifiable from the text.
- [pipeline description] Weighting mechanism (pipeline description): cosine similarity in BERT latent space is used to weight samples on the assumption that it proxies fidelity of translated coreference chains (entity clusters and mention boundaries), but no validation, ablation, or correlation analysis with annotation preservation is provided; this assumption is load-bearing because weak correlation would mean the weighting selects clean samples by chance rather than via the cycle-consistency mechanism.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the four low-resource languages and reported at least one concrete metric (e.g., CoNLL F1 delta).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'significant performance gains' and 'accurate' coreference resolution supplies no quantitative results, baselines, specific languages, metrics, or error analysis, leaving the empirical contribution unverifiable from the text.
Authors: We agree that the abstract is high-level and would benefit from concrete details to allow immediate verification of the claims. The body of the manuscript reports experiments on four low-resource languages with quantitative gains (using standard coreference metrics such as CoNLL F1) over relevant baselines. We will revise the abstract to incorporate the specific languages, metrics, and performance numbers. revision: yes
-
Referee: [pipeline description] Weighting mechanism (pipeline description): cosine similarity in BERT latent space is used to weight samples on the assumption that it proxies fidelity of translated coreference chains (entity clusters and mention boundaries), but no validation, ablation, or correlation analysis with annotation preservation is provided; this assumption is load-bearing because weak correlation would mean the weighting selects clean samples by chance rather than via the cycle-consistency mechanism.
Authors: This is a fair observation; the weighting mechanism rests on an unvalidated proxy in the submitted version. We will add an ablation comparing weighted versus unweighted training and a correlation analysis (including manual inspection of high- and low-scoring samples for mention and cluster fidelity) to directly test the assumption. revision: yes
Circularity Check
No significant circularity; pipeline uses external BERT proxy without self-referential reduction
full rationale
The core method generates coreference training data via MT from English, then weights samples by cosine similarity of original and back-translated sentences in a pre-trained BERT embedding space. This weighting step depends on an independent external model and does not reduce the final OntoNotes-style metrics to any quantity defined by parameters fitted inside the pipeline. No self-definitional equations, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the derivation. The reported gains on four low-resource languages rest on external benchmarks rather than tautological construction, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Back-translation similarity in BERT space correlates with the quality of machine-translated coreference annotations
Reference graph
Works this paper leans on
-
[2]
2026 , url =
Claude Sonnet 4.6 Model Card , author =. 2026 , url =
2026
-
[3]
BLEU: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle=. BLEU: a method for automatic evaluation of machine translation
-
[4]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Banerjee, Satanjeev and Lavie, Alon , booktitle=. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
-
[5]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[6]
Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
COMET-22: Unbabel-IST 2022 submission for the metrics shared task , author=. Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
2022
-
[7]
, author=
LoRA: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[8]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[9]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[10]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[11]
arXiv preprint arXiv:2309.11674 , year=
A paradigm shift in machine translation: Boosting translation performance of large language models , author=. arXiv preprint arXiv:2309.11674 , year=
-
[12]
arXiv preprint arXiv:2502.02481 , year=
Multilingual machine translation with open large language models at practical scale: An empirical study , author=. arXiv preprint arXiv:2502.02481 , year=
-
[13]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[14]
Proceedings of the 41st International Conference on Machine Learning(ICML) , articleno =
Xu, Haoran and Sharaf, Amr and Chen, Yunmo and Tan, Weiting and Shen, Lingfeng and Van Durme, Benjamin and Murray, Kenton and Kim, Young Jin , title =. Proceedings of the 41st International Conference on Machine Learning(ICML) , articleno =. 2024 , publisher =
2024
-
[15]
arXiv preprint arXiv:2410.03115 , year=
X-alma: Plug & play modules and adaptive rejection for quality translation at scale , author=. arXiv preprint arXiv:2410.03115 , year=
-
[16]
Proceedings of the 26th annual international conference on machine learning , pages=
Curriculum learning , author=. Proceedings of the 26th annual international conference on machine learning , pages=
-
[17]
2012 , author =
A unifying view on dataset shift in classification , journal =. 2012 , author =
2012
-
[18]
ACM Computing Surveys , volume=
Open-world machine learning: applications, challenges, and opportunities , author=. ACM Computing Surveys , volume=
-
[19]
arXiv preprint arXiv:2403.01759 , year=
Open-world machine learning: A review and new outlooks , author=. arXiv preprint arXiv:2403.01759 , year=
-
[20]
, isbn =
Vapnik, Vladimir N. , isbn =. The nature of statistical learning theory , isbn =. 1995 , address =
1995
-
[21]
Recent Advances in Open Set Recognition: A Survey , year=
Geng, Chuanxing and Huang, Sheng-Jun and Chen, Songcan , journal=. Recent Advances in Open Set Recognition: A Survey , year=
-
[22]
Transactions on Machine Learning Research , issn=
A Unified Survey on Anomaly, Novelty, Open-Set, and Out of-Distribution Detection: Solutions and Future Challenges , author=. Transactions on Machine Learning Research , issn=
-
[23]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Open-Set Recognition: A Good Closed-Set Classifier is All You Need , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[24]
International Journal of Computer Vision , volume =
Jingkang Yang and Kaiyang Zhou and Yixuan Li and Ziwei Liu , title =. International Journal of Computer Vision , volume =
-
[25]
Reducing Network Agnostophobia , doi =
Dhamija, Akshay Raj and Günther, Manuel and Boult, Terrance , booktitle =. Reducing Network Agnostophobia , doi =
-
[26]
Journal of Computational and Applied Mathematics , author =
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=. doi:https://doi.org/10.1016/0377-0427(87)90125-7 , pages=
-
[27]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Automated essay scoring with string kernels and word embeddings , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[28]
Inference with the Universum
Weston, Jason and Collobert, Ronan and Sinz, Fabian and Bottou, L\'. Inference with the Universum. 2006 , booktitle =
2006
-
[29]
Top2Label: Explainable zero shot topic labelling using knowledge graphs
Chaudhary, Akhil and Milios, Evangelos and Rajabi, Enayat , journal =. Top2Label: Explainable zero shot topic labelling using knowledge graphs
-
[30]
Pourpanah, Farhad and Abdar, Moloud and Luo, Yuxuan and Zhou, Xinlei and Wang, Ran and Lim, Chee Peng and Wang, Xi-Zhao and Wu, Q. M. Jonathan , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[31]
Towards Open-Set Object Detection and Discovery , year=
Zheng, Jiyang and Li, Weihao and Hong, Jie and Petersson, Lars and Barnes, Nick , booktitle=. Towards Open-Set Object Detection and Discovery , year=
-
[32]
OpenGAN: Open-Set Recognition via Open Data Generation
Kong, Shu and Ramanan, Deva , booktitle =. OpenGAN: Open-Set Recognition via Open Data Generation. 2021 , pages =
2021
-
[33]
Deep Metric Learning for Open World Semantic Segmentation , year=
Cen, Jun and Yun, Peng and Cai, Junhao and Yu Wang, Michael and Liu, Ming , booktitle=. Deep Metric Learning for Open World Semantic Segmentation , year=
-
[34]
Oliveira, Hugo and Silva, Caio and Machado, Gabriel L. S. and Nogueira, Keiller and dos Santos, Jefersson A. , title =. Machine Learning , pages =. 2021 , volume =
2021
-
[35]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages =
The Overlooked Elephant of Object Detection: Open Set , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages =
-
[36]
Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection
Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Jiang, Qing and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and Zhang, Lei. Grounding DINO: Marrying DINO with Grounded Pre-training for Open-Set Object Detection. Proceedings of European Conference on Computer Vision (ECCV). 2024
2024
-
[37]
UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection
Acsintoae, Andra and Florescu, Andrei and Georgescu, Mariana-Iuliana and Mare, Tudor and Sumedrea, Paul and Ionescu, Radu Tudor and Khan, Fahad Shahbaz and Shah, Mubarak , booktitle=. UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. 2022 , pages=
2022
-
[38]
Open-Vocabulary Video Anomaly Detection , year=
Wu, Peng and Zhou, Xuerong and Pang, Guansong and Sun, Yujia and Liu, Jing and Wang, Peng and Zhang, Yanning , booktitle=. Open-Vocabulary Video Anomaly Detection , year=
-
[39]
Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages =
Breaking the Closed World Assumption in Text Classification , author =. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages =
2016
-
[40]
A Comprehensive Survey of Continual Learning: Theory, Method and Application , year=
Wang, Liyuan and Zhang, Xingxing and Su, Hang and Zhu, Jun , journal=. A Comprehensive Survey of Continual Learning: Theory, Method and Application , year=
-
[41]
and Ramanan, Deva and Fatahalian, Kayvon , booktitle=
Mullapudi, Ravi Teja and Poms, Fait and Mark, William R. and Ramanan, Deva and Fatahalian, Kayvon , booktitle=. Background Splitting: Finding Rare Classes in a Sea of Background. 2021 , pages=
2021
-
[42]
Energy-based Out-of-distribution Detection , volume =
Liu, Weitang and Wang, Xiaoyun and Owens, John and Li, Yixuan , booktitle =. Energy-based Out-of-distribution Detection , volume =. 2020 , url=
2020
-
[43]
2019 , booktitle=
Deep Anomaly Detection with Outlier Exposure , author=. 2019 , booktitle=
2019
-
[44]
Proceedings of the International Conference on Learning Representations (ICLR) , doi =
Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples , author=. Proceedings of the International Conference on Learning Representations (ICLR) , doi =
-
[45]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Closed Boundary Learning for Classification Tasks with the Universum Class , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[46]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , pages=
Uncertainty-aware reliable text classification , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , pages=
-
[47]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , author =
Benchmarking Zero-Shot Text Classification:. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP) , author =. 2019 , pages =
2019
-
[48]
Generating
Meng, Yu and Huang, Jiaxin and Zhang, Yu and Han, Jiawei , year =. Generating. Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS) , volume =
-
[49]
Meng, Yu and Zhang, Yunyi and Huang, Jiaxin and Xiong, Chenyan and Ji, Heng and Zhang, Chao and Han, Jiawei , year =. Text. Proceedings of the 2020. doi:10.18653/v1/2020.emnlp-main.724 , pages =
-
[50]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Zero-Shot Text Classification with Self-Training , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2022 , doi =
2022
-
[51]
, year =
Hu, Zhiting and Yang, Zichao and Liang, Xiaodan and Salakhutdinov, Ruslan and Xing, Eric P. , year =. Toward Controlled Generation of Text , booktitle =
-
[52]
Findings of the Association for Computational Linguistics: ACL 2023 , author =
R e G en: Zero-Shot Text Classification via Training Data Generation with Progressive Dense Retrieval. Findings of the Association for Computational Linguistics: ACL 2023 , author =. 2023 , pages =
2023
-
[53]
Instruction Tuning for Large Language Models: A Survey
Zhang, Shengyu and Dong, Linfeng and Li, Xiaoya and Zhang, Sen and Sun, Xiaofei and Wang, Shuhe and Li, Jiwei and Hu, Runyi and Zhang, Tianwei and Wu, Fei and Wang, Guoyin , year =. Instruction Tuning for Large Language Models: A Survey. arXiv preprint arXiv:2308.10792 , url=
-
[54]
and Sutawika, Lintang and Alyafeai, Zaid and Chaffin, Antoine and Stiegler, Arnaud and Scao, Teven Le and Raja, Arun and Dey, Manan and Bari, M
Sanh, Victor and Webson, Albert and Raffel, Colin and Bach, Stephen H. and Sutawika, Lintang and Alyafeai, Zaid and Chaffin, Antoine and Stiegler, Arnaud and Scao, Teven Le and Raja, Arun and Dey, Manan and Bari, M. Saiful and Xu, Canwen and Thakker, Urmish and Sharma, Shanya Sharma and Szczechla, Eliza and Kim, Taewoon and Chhablani, Gunjan and Nayak, Ni...
-
[55]
and Guu, Kelvin and Yu, Adams Wei and Lester, Brian and Du, Nan and Dai, Andrew M
Wei, Jason and Bosma, Maarten and Zhao, Vincent Y. and Guu, Kelvin and Yu, Adams Wei and Lester, Brian and Du, Nan and Dai, Andrew M. and Le, Quoc V. , year =. Finetuned Language Models Are Zero-Shot Learners , booktitle =
-
[56]
Z ero G en: Efficient Zero-shot Learning via Dataset Generation
Ye, Jiacheng and Gao, Jiahui and Li, Qintong and Xu, Hang and Feng, Jiangtao and Wu, Zhiyong and Yu, Tao and Kong, Lingpeng. Z ero G en: Efficient Zero-shot Learning via Dataset Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2022
2022
-
[57]
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
Xu, Hanwei and Chen, Yujun and Du, Yulun and Shao, Nan and Wang, Yanggang and Li, Haiyu and Yang, Zhilin , year =. ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization. Findings of the Association for Computational Linguistics:
-
[58]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Will Grathwohl and Kuan-Chieh Wang and Jörn-Henrik Jacobsen and David Duvenaud and Mohammad Norouzi and Kevin Swersky , title = ". Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[59]
1987 , howpublished =
Lewis, David , title =. 1987 , howpublished =
1987
-
[60]
2019 , author =
Continual lifelong learning with neural networks: A review , journal =. 2019 , author =
2019
-
[61]
2019 , booktitle=
Detecting Out-of-Distribution Inputs to Deep Generative Models Using Typicality , author=. 2019 , booktitle=
2019
-
[62]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , doi =
Open-Set Semi-Supervised Text Classification with Latent Outlier Softening , author =. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , doi =
-
[63]
Types of Out-of-Distribution Texts and How to Detect Them , booktitle =
Arora, Udit and Huang, William and He, He , editor =. Types of Out-of-Distribution Texts and How to Detect Them , booktitle =. 2021 , pages =
2021
-
[64]
Proceedings of the 61st Annual Meeting of the Association For Computational Linguistics Student Research Workshop (SRW) , year =
Classical Out-of-Distribution Detection Methods Benchmark in Text Classification Tasks , author =. Proceedings of the 61st Annual Meeting of the Association For Computational Linguistics Student Research Workshop (SRW) , year =
-
[65]
Aggarwal and Haesun Park , title =
Ramakrishnan Kannan and Hyenkyun Woo and Charu C. Aggarwal and Haesun Park , title =. Proceedings of the 2017 SIAM International Conference on Data Mining (SDM) , year =
2017
-
[66]
Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year =
Angle-Based Outlier Detection in High-Dimensional Data , author =. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year =
-
[67]
2020 , journal =
Efficient Outlier Detection in Text Corpus Using Rare Frequency and Ranking , author =. 2020 , journal =
2020
-
[68]
and de Rezende Rocha, Anderson and Sapkota, Arun and Boult, Terrance E
Scheirer, Walter J. and de Rezende Rocha, Anderson and Sapkota, Arun and Boult, Terrance E. , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[69]
2018 , journal =
Algorithm Based on Modified Angle-Based Outlier Factor for Open-Set Classification of Text Documents , author =. 2018 , journal =
2018
-
[70]
Proceedings of the International Conference on Artificial Intelligence and Soft Computing (ICAISC) , author =
Open Set Subject Classification of Text Documents in Polish by Doc-to-Vec and Local Outlier Factor. Proceedings of the International Conference on Artificial Intelligence and Soft Computing (ICAISC) , author =. 2019 , volume =
2019
-
[71]
Proceedings of the 32nd International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE) , author =
Distance Metrics in Open-Set Classification of Text Documents by Local Outlier Factor and Doc2Vec. Proceedings of the 32nd International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems (IEA/AIE) , author =. 2019 , pages =
2019
-
[72]
Utilizing Local Outlier Factor for Open-Set Classification in High-Dimensional Data--Case Study Applied for Text Documents , booktitle =
Walkowiak, Tomasz and Datko, Szymon and Maciejewski, Henryk , year =. Utilizing Local Outlier Factor for Open-Set Classification in High-Dimensional Data--Case Study Applied for Text Documents , booktitle =
-
[73]
Progress in Outlier Detection Techniques: A Survey , year=
Wang, Hongzhi and Bah, Mohamed Jaward and Hammad, Mohamed , journal=. Progress in Outlier Detection Techniques: A Survey , year=
-
[74]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , doi =
Open-Set Semi-Supervised Text Classification via Adversarial Disagreement Maximization , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , doi =. 2024 , pages =
2024
-
[75]
OSP-Class: Open Set Pseudo-labeling with Noise Robust Training for Text Classification
Kim, Dohyung and Koo, Jahwan and Kim, Ung-Mo , booktitle =. OSP-Class: Open Set Pseudo-labeling with Noise Robust Training for Text Classification. 2022 , pages =
2022
-
[76]
X -Class: Text Classification with Extremely Weak Supervision
Wang, Zihan and Mekala, Dheeraj and Shang, Jingbo. X -Class: Text Classification with Extremely Weak Supervision. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). 2021
2021
-
[77]
Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM) , year=
Discovering Coherent Topics Using General Knowledge , author =. Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM) , year=
-
[78]
CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
Li, Yukun and Pang, Guansong and Suo, Wei and Jing, Chenchen and Xi, Yuling and Liu, Lingqiao and Chen, Hao and Liang, Guoqiang and Wang, Peng , journal=. CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
-
[79]
Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
Neural Topic Modeling with Continual Lifelong Learning , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
-
[80]
Proceedings of the 31st International Conference on Machine Learning (ICML) , pages =
Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data , author =. Proceedings of the 31st International Conference on Machine Learning (ICML) , pages =
-
[81]
Continual Learning for Text Classification with Information Disentanglement Based Regularization
Huang, Yufan and Zhang, Yanzhe and Chen, Jiaao and Wang, Xuezhi and Yang, Diyi. Continual Learning for Text Classification with Information Disentanglement Based Regularization. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.