Materialist: Physically Based Editing Using Single-Image Inverse Rendering
Pith reviewed 2026-05-23 05:41 UTC · model grok-4.3
The pith
Neural predictions initialize material properties that progressive differentiable rendering then optimizes to enable physically consistent edits from one image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
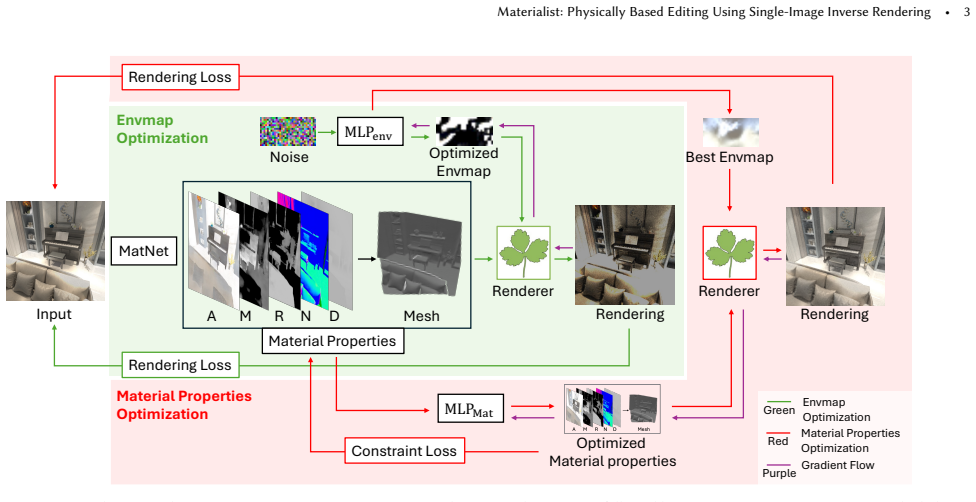
Materialist recovers material properties from a single image by first using neural networks to predict initial values and then rigorously optimizing them via progressive differentiable rendering, producing solutions that support material editing, object insertion, relighting, and ray-traced refraction edits without full scene geometry while also delivering competitive environment-map estimates.
What carries the argument
The progressive differentiable rendering optimization step that refines neural-initialized material properties to enforce physical consistency.
If this is right
- Material editing becomes possible with accurate shadows and refractions from only one view.
- Objects can be inserted into scenes while maintaining physical lighting consistency.
- Scenes can be relit using estimated environment maps without additional images.
- Material transparency can be edited via ray-traced refraction even when full scene geometry is unavailable.
- Environment-map estimation reaches competitive accuracy on both synthetic and real data.
Where Pith is reading between the lines
- The method implies that single-image inverse rendering can now address refraction effects that previously required multi-view data or explicit geometry.
- It suggests neural initialization may systematically reduce the solution space for otherwise ill-posed single-image problems when followed by physics constraints.
- Performance on out-of-domain images indicates the pipeline may generalize to consumer photographs taken under uncontrolled conditions.
Load-bearing premise
Neural network predictions supply initial material properties close enough to ground truth that progressive differentiable rendering optimization can converge to physically consistent solutions despite the inherent ambiguities of single-image inverse rendering.
What would settle it
If the final optimized materials, when used to re-render the input image under the recovered lighting, produce visible mismatches in shadow placement or refraction patterns compared with the original photograph, the physical-consistency claim would be falsified.
Figures


















read the original abstract
Achieving physically consistent image editing remains a significant challenge in computer vision. Existing image editing methods typically rely on neural networks, which struggle to accurately handle shadows and refractions. Conversely, physics-based inverse rendering often requires multi-view optimization, limiting its practicality in single-image scenarios. In this paper, we propose Materialist, a neural-initialized physically based rendering pipeline for single-image inverse rendering. Unlike previous hybrid methods that use physics to guide neural generation, our method leverages neural networks to predict initial material properties, which are then rigorously optimized via progressive differentiable rendering. Our approach enables a range of applications, including material editing, object insertion, and relighting, while also introducing an effective method for editing material transparency via ray-traced refraction without requiring full scene geometry. Furthermore, our envmap estimation method also achieves competitive performance, further enhancing the accuracy of image editing task. Experiments demonstrate strong performance across synthetic and real-world datasets, excelling even on challenging out-of-domain images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Materialist, a hybrid pipeline for single-image inverse rendering that first uses neural networks to predict initial material properties (albedo, roughness, etc.) and then refines them via progressive differentiable rendering optimization. This enables applications including material editing, object insertion, relighting, and an approximation for editing material transparency through ray-traced refraction that avoids explicit full-scene geometry reconstruction. The method also reports competitive performance on environment map estimation. Experiments are claimed on both synthetic and real-world datasets, including out-of-domain cases.
Significance. If the central claim holds—that neural initialization plus progressive optimization reliably recovers physically consistent parameters from a single image despite inherent ambiguities—the work would provide a practical bridge between neural image editing and physics-based rendering. The refraction-editing technique without full geometry and the envmap results would be notable contributions if supported by quantitative evidence of physical fidelity rather than visual plausibility alone.
major comments (3)
- [Method / Experiments] The central claim that progressive differentiable rendering optimization converges to physically consistent solutions (rather than visually plausible local minima) rests on the assumption that neural initialization lands sufficiently close to ground truth. No section provides an ablation or convergence analysis that isolates the effect of the progressive schedule versus standard joint optimization, nor quantifies residual albedo–illumination scale ambiguity on the reported datasets.
- [Applications / Transparency Editing] The refraction editing method claims to perform ray-traced refraction 'without requiring full scene geometry.' The approximation used to enable this (e.g., any proxy depth or normal handling) is load-bearing for the physical-consistency claim yet is not accompanied by error metrics against ground-truth refraction or a comparison to full-geometry baselines.
- [Experiments] Envmap estimation is stated to achieve 'competitive performance,' but the evaluation lacks a direct comparison table against recent single-image envmap methods on the same metrics and test splits, making it impossible to assess whether the improvement is incremental or substantial.
minor comments (2)
- [Method] Notation for material parameters (e.g., how roughness and metallic are jointly optimized) should be defined explicitly in the method section to avoid ambiguity with standard PBR conventions.
- [Figures] Figure captions for qualitative results should include the input image, source of ground truth (when available), and the specific editing operation performed.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method / Experiments] The central claim that progressive differentiable rendering optimization converges to physically consistent solutions (rather than visually plausible local minima) rests on the assumption that neural initialization lands sufficiently close to ground truth. No section provides an ablation or convergence analysis that isolates the effect of the progressive schedule versus standard joint optimization, nor quantifies residual albedo–illumination scale ambiguity on the reported datasets.
Authors: We agree that an explicit ablation isolating the progressive schedule from joint optimization would better support the central claim. The progressive schedule is motivated by gradually introducing rendering effects to avoid poor local minima, with neural initialization providing a physically plausible starting point that helps mitigate albedo-illumination ambiguity. We will add a dedicated ablation study and convergence analysis section, along with discussion of residual scale ambiguity on the evaluated datasets. revision: yes
-
Referee: [Applications / Transparency Editing] The refraction editing method claims to perform ray-traced refraction 'without requiring full scene geometry.' The approximation used to enable this (e.g., any proxy depth or normal handling) is load-bearing for the physical-consistency claim yet is not accompanied by error metrics against ground-truth refraction or a comparison to full-geometry baselines.
Authors: The refraction approximation relies on the single-image estimated depth and normals to simulate approximate ray paths for refraction effects. This design choice is deliberate for single-image practicality, as full scene geometry cannot be recovered. We will expand the methods section with a clearer description of the proxy depth and normal handling. Quantitative error metrics against ground-truth refraction are not feasible in the single-image setting without additional multi-view data, but we will add further qualitative comparisons to full-geometry baselines where synthetic data permits. revision: partial
-
Referee: [Experiments] Envmap estimation is stated to achieve 'competitive performance,' but the evaluation lacks a direct comparison table against recent single-image envmap methods on the same metrics and test splits, making it impossible to assess whether the improvement is incremental or substantial.
Authors: We acknowledge that a side-by-side comparison table is needed for proper assessment. Our envmap results are obtained as part of the joint inverse rendering optimization rather than as a standalone module. We will add a direct comparison table against recent single-image envmap estimation methods, using the same metrics and test splits reported in the literature. revision: yes
- Quantitative error metrics for refraction editing against ground-truth refraction, due to the inherent single-image constraint without full scene geometry.
Circularity Check
Neural-initialized progressive optimization pipeline has no circular reduction to inputs
full rationale
The described method uses an external neural network to supply initial material property predictions, followed by refinement via progressive differentiable rendering (an independent physics-based optimizer). No equations, parameters, or claims in the abstract or described pipeline reduce by construction to their own fitted values or self-citations. The refraction editing and envmap estimation are presented as applications of the same external rendering engine rather than self-definitional constructs. This matches the default case of a self-contained engineering pipeline without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
neural networks to predict initial material properties, which are then rigorously optimized via progressive differentiable rendering
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Single-Image Transparency Editing: ... without requiring complete geometry
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
PhysEditBench: A Protocol-Conditioned Benchmark for Dense Physical-Map Prediction with Image Editors
PhysEditBench is a protocol-conditioned benchmark evaluating image editors on dense prediction of depth, normal, albedo, roughness, and metallic maps from RGB images using curated data and fixed scoring rules.
Reference graph
Works this paper leans on
-
[1]
Dejan Azinovic, Tzu-Mao Li, Anton Kaplanyan, and Matthias Nießner. 2019. Inverse path tracing for joint material and lighting estimation. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 2447–2456
work page 2019
- [2]
-
[3]
Connelly Barnes, Eli Shechtman, Adam Finkelstein, and Dan B. Goldman. 2009. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Transactions on Graphics 28, 3 (2009), 24
work page 2009
-
[4]
Sean Bell, Kavita Bala, and Noah Snavely. 2014. Intrinsic Images in the Wild. ACM Transactions on Graphics 33, 4 (2014), 159
work page 2014
-
[5]
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias Müller
-
[6]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
ZoeDepth: Zero-shot transfer by combining relative and metric depth. arXiv:2302.12288 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. 2023. InstructPix2Pix: Learning to follow image editing instructions. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 18392–18402
work page 2023
-
[9]
Brent Burley. 2012. Physically-based shading at Disney. In Practical Physically Based Shading in Film and Game Production . ACM SIGGRAPH 2012 Courses
work page 2012
-
[10]
Brent Burley. 2015. Extending the Disney BRDF to a BSDF with integrated subsurface scattering. In Physically Based Shading in Theory and Practice . ACM SIGGRAPH 2015 Courses
work page 2015
-
[11]
Wenzheng Chen, Jun Gao, Huan Ling, Edward Smith, Jaakko Lehtinen, Alec Jacob- son, and Sanja Fidler. 2019. Learning to Predict 3D Objects with an Interpolation- based Differentiable Renderer. In Advances in Neural Information Processing Sys- tems 32 (NeurIPS 2019)
work page 2019
-
[12]
Wenzheng Chen, Joey Litalien, Jun Gao, Zian Wang, Clement Fuji Tsang, Sameh Khamis, Or Litany, and Sanja Fidler. 2021. DIB-R++: learning to predict light- ing and material with a hybrid differentiable renderer. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021)
work page 2021
-
[13]
JunYong Choi, SeokYeong Lee, Haesol Park, Seung-Won Jung, Ig-Jae Kim, and Junghyun Cho. 2023. MAIR: multi-view attention inverse rendering with 3d spatially-varying lighting estimation. In Proceedings of Computer Vision and Pat- tern Recognition (CVPR). IEEE, 8392–8401
work page 2023
-
[14]
Mohammad Reza Karimi Dastjerdi, Jonathan Eisenmann, Yannick Hold-Geoffroy, and Jean-François Lalonde. 2023. EverLight: Indoor-outdoor editable HDR lighting estimation. In Proceedings of International Conference on Computer Vision (ICCV) . IEEE, 7420–7429
work page 2023
-
[15]
Xi Deng, Fujun Luan, Bruce Walter, Kavita Bala, and Steve Marschner. 2022. Recon- structing translucent objects using differentiable rendering. In ACM SIGGRAPH 2022 Conference Proceedings. ACM, 38:1–38:10
work page 2022
-
[16]
David Eigen, Christian Puhrsch, and Rob Fergus. 2014. Depth map prediction from a single image using a multi-scale deep network. In Advances in Neural Information Processing Systems 27 (NeurIPS 2014) , Vol. 27
work page 2014
-
[17]
Yuto Enyo and Ko Nishino. 2024. Diffusion Reflectance Map: Single-Image Stochas- tic Inverse Rendering of Illumination and Reflectance. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 11873–11883
work page 2024
-
[18]
Antoine Guédon and Vincent Lepetit. 2024. Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5354–5363
work page 2024
-
[19]
Jon Hasselgren, Nikolai Hofmann, and Jacob Munkberg. 2022. Shape, light, and material decomposition from images using Monte Carlo rendering and denoising. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) (2022), 22856– 22869
work page 2022
-
[20]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2023. Prompt-to-Prompt Image Editing with Cross-Attention Control. In Proceedings of International Conference on Learning Representations (ICLR)
work page 2023
-
[21]
Wenzel Jakob, Sébastien Speierer, Nicolas Roussel, Merlin Nimier-David, Delio Vicini, Tizian Zeltner, Baptiste Nicolet, Miguel Crespo, Vincent Leroy, and Ziyi Zhang. 2022. Mitsuba 3 renderer. https://mitsuba-renderer.org
work page 2022
- [22]
-
[23]
Douglas Scott Kay and Donald Greenberg. 1979. Transparency for computer synthesized images. Computer Graphics (SIGGRAPH ’79) 13, 2 (1979), 158–164
work page 1979
-
[24]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
- [25]
-
[26]
Peter Kocsis, Vincent Sitzmann, and Matthias Nießner. 2024. Intrinsic Image Diffusion for Indoor Single-view Material Estimation. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 5198–5208
work page 2024
-
[27]
Zhengqin Li, Mohammad Shafiei, Ravi Ramamoorthi, Kalyan Sunkavalli, and Manmohan Chandraker. 2020. Inverse rendering for complex indoor scenes: Shape, spatially-varying lighting and SVBRDF from a single image. InProceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 2475–2484
work page 2020
-
[28]
Zhengqin Li, Jia Shi, Sai Bi, Rui Zhu, Kalyan Sunkavalli, Miloš Hašan, Zexiang Xu, Ravi Ramamoorthi, and Manmohan Chandraker. 2022. Physically-based editing of indoor scene lighting from a single image. InEuropean Conference on Computer Vision (ECCV). Springer, 555–572
work page 2022
-
[29]
Zhengqin Li, Kalyan Sunkavalli, and Manmohan Chandraker. 2018. Materials for masses: SVBRDF acquisition with a single mobile phone image. In Proceedings of the European Conference on Computer Vision (ECCV) . Springer, 72–87
work page 2018
-
[30]
Zhen Li, Lingli Wang, Mofang Cheng, Cihui Pan, and Jiaqi Yang. 2023. Multi- view inverse rendering for large-scale real-world indoor scenes. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 12499–12509
work page 2023
-
[31]
Zhengqin Li, Zexiang Xu, Ravi Ramamoorthi, Kalyan Sunkavalli, and Manmohan Chandraker. 2018. Learning to reconstruct shape and spatially-varying reflectance from a single image. ACM Transactions on Graphics 37, 6 (2018), 269
work page 2018
-
[32]
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu- Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, Sai Bi, Hong-Xing Yu, Zexiang Xu, Kalyan Sunkavalli, Milos Hasan, Ravi Ramamoorthi, and Manmohan Chandraker
-
[33]
In Proceedings of Computer Vision and Pattern Recognition (CVPR)
OpenRooms: An open framework for photorealistic indoor scene datasets. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 7190–7199
-
[34]
Ruofan Liang, Zan Gojcic, Huan Ling, Jacob Munkberg, Jon Hasselgren, Zhi-Hao Lin, Jun Gao, Alexander Keller, Nandita Vijaykumar, Sanja Fidler, et al . 2025. DiffusionRenderer: Neural Inverse and Forward Rendering with Video Diffusion Models. arXiv preprint arXiv:2501.18590 (2025)
-
[35]
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. 2024. SyncDreamer: Generating multiview-consistent images from a single-view image. In Proceedings of International Conference on Learning Representations (ICLR)
work page 2024
-
[36]
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. 2024. Wonder3D: Single image to 3D using cross-domain diffusion. InProceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 9970–9980
work page 2024
-
[37]
Fujun Luan, Shuang Zhao, Kavita Bala, and Zhao Dong. 2021. Unified shape and SVBRDF recovery using differentiable Monte Carlo rendering. Computer Graphics Forum 40, 4 (2021), 101–113
work page 2021
-
[38]
Jundan Luo, Duygu Ceylan, Jae Shin Yoon, Nanxuan Zhao, Julien Philip, Anna Frühstück, Wenbin Li, Christian Richardt, and Tuanfeng Wang. 2024. IntrinsicD- iffusion: joint intrinsic layers from latent diffusion models. In ACM SIGGRAPH 2024 Conference Papers. ACM, 74:1–74:11
work page 2024
-
[39]
Linjie Lyu, Ayush Tewari, Marc Habermann, Shunsuke Saito, Michael Zollhöfer, Thomas Leimkühler, and Christian Theobalt. 2023. Diffusion posterior illumina- tion for ambiguity-aware inverse rendering. ACM Transactions on Graphics 42, 6 (2023), 233. Materialist: Physically Based Editing Using Single-Image Inverse Rendering • 9
work page 2023
-
[40]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2021. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. In Proceedings of International Conference on Learning Representations (ICLR)
work page 2021
-
[41]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2021. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (2021), 99–106
work page 2021
-
[42]
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2023. Null-text inversion for editing real images using guided diffusion models. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 6038–6047
work page 2023
-
[43]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatu...
work page 2024
-
[44]
Xingang Pan, Ayush Tewari, Thomas Leimkühler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt. 2023. Drag your gan: Interactive point-based manipu- lation on the generative image manifold. In ACM SIGGRAPH 2023 Conference Proceedings. ACM, 78:1–78:11
work page 2023
-
[45]
Debevec, and Sean Ryan Fanello
Rohit Pandey, Sergio Orts-Escolano, Chloe Legendre, Christian Haene, Sofien Bouaziz, Christoph Rhemann, Paul E. Debevec, and Sean Ryan Fanello. 2021. Total relighting: learning to relight portraits for background replacement. ACM Transactions on Graphics 40, 4 (2021), 43
work page 2021
-
[46]
Jeong Joon Park, Aleksander Holynski, and Steven M Seitz. 2020. Seeing the world in a bag of chips. In Proceedings of Computer Vision and Pattern Recognition (CVPR). IEEE, 1417–1427
work page 2020
-
[47]
Steven G. Parker, James Bigler, Andreas Dietrich, Heiko Friedrich, Jared Hoberock, David Luebke, David McAllister, Morgan McGuire, Keith Morley, Austin Robison, and Martin Stich. 2010. OptiX: a general purpose ray tracing engine. ACM Transactions on Graphics 29, 4 (2010), 66
work page 2010
-
[48]
Pakkapon Phongthawee, Worameth Chinchuthakun, Nontaphat Sinsunthithet, Varun Jampani, Amit Raj, Pramook Khungurn, and Supasorn Suwajanakorn. 2024. Diffusionlight: Light probes for free by painting a chrome ball. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 98–108
work page 2024
-
[49]
Kris Popat and Rosalind W. Picard. 1993. Novel cluster-based probability model for texture synthesis, classification, and compression. In Visual Communications and Image Processing ’93, Vol. 2094. SPIE, 756–768
work page 1993
-
[50]
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. 2021. Vision Transformers for Dense Prediction. In Proceedings of International Conference on Computer Vision (ICCV). IEEE, 12179–12188
work page 2021
-
[51]
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. 2024. SAM 2: Segment Anything in Images and Videos. arXiv:2408.00714 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 10684– 10695
work page 2022
-
[53]
Shen Sang and Manmohan Chandraker. 2020. Single-shot neural relighting and SVBRDF estimation. In European Conference on Computer Vision (ECCV). Springer, 85–101
work page 2020
-
[54]
Ayush Sarkar, Hanlin Mai, Amitabh Mahapatra, Svetlana Lazebnik, David A Forsyth, and Anand Bhattad. 2024. Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry... for now. InProceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 28140–28149
work page 2024
-
[55]
Christophe Schlick. 1994. An inexpensive BRDF model for physically-based rendering. Computer Graphics Forum 13, 3 (1994), 233–246
work page 1994
-
[56]
Soumyadip Sengupta, Jinwei Gu, Kihwan Kim, Guilin Liu, David W. Jacobs, and Jan Kautz. 2019. Neural inverse rendering of an indoor scene from a single image. In Proceedings of International Conference on Computer Vision (ICCV) . IEEE, 8598–8607
work page 2019
-
[57]
Prafull Sharma, Varun Jampani, Yuanzhen Li, Xuhui Jia, Dmitry Lagun, Fredo Durand, Bill Freeman, and Mark Matthews. 2024. Alchemist: Parametric control of material properties with diffusion models. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 24130–24141
work page 2024
-
[58]
Ruoxi Shi, Hansheng Chen, Zhuoyang Zhang, Minghua Liu, Chao Xu, Xinyue Wei, Linghao Chen, Chong Zeng, and Hao Su. 2023. Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model. arXiv:2310.15110 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent YF Tan, and Song Bai. 2024. Dragdiffusion: Harnessing diffusion models for interactive point-based image editing. In Proceedings of Computer Vision and Pattern Recognition (CVPR). IEEE, 8839–8849
work page 2024
-
[60]
Cheng Sun, Guangyan Cai, Zhengqin Li, Kai Yan, Cheng Zhang, Carl Marshall, Jia-Bin Huang, Shuang Zhao, and Zhao Dong. 2023. Neural-PBIR reconstruction of shape, material, and illumination. In Proceedings of International Conference on Computer Vision (ICCV). IEEE, 18046–18056
work page 2023
-
[61]
Tristan Swedish, Connor Henley, and Ramesh Raskar. 2021. Objects as cam- eras: Estimating high-frequency illumination from shadows. In Proceedings of International Conference on Computer Vision (ICCV) . IEEE, 2593–2602
work page 2021
-
[62]
Jiajun Tang, Yongjie Zhu, Haoyu Wang, Jun Hoong Chan, Si Li, and Boxin Shi
-
[63]
In European Conference on Computer Vision (ECCV)
Estimating spatially-varying lighting in urban scenes with disentangled representation. In European Conference on Computer Vision (ECCV) . Springer, 454–469
-
[64]
Jasper AI Team. 2024. Flux.1-dev: Upscaler ControlNet. https://huggingface.co/ jasperai/Flux.1-dev-Controlnet-Upscaler. Accessed 13 November 2024
work page 2024
-
[65]
Barron, Todd Zickler, and Pratul P
Dor Verbin, Ben Mildenhall, Peter Hedman, Jonathan T. Barron, Todd Zickler, and Pratul P. Srinivasan. 2024. Eclipse: Disambiguating illumination and mate- rials using unintended shadows. In Proceedings of Computer Vision and Pattern Recognition (CVPR). IEEE, 77–86
work page 2024
-
[66]
Marschner, Hongsong Li, and Kenneth E
Bruce Walter, Stephen R. Marschner, Hongsong Li, and Kenneth E. Torrance
-
[67]
In Proceedings of Eurographics Sympoisum on Rendering (EGSR)
Microfacet Models for Refraction Through Rough Surfaces. In Proceedings of Eurographics Sympoisum on Rendering (EGSR) . Eurographics Association, 195– 206
-
[68]
Guangcong Wang, Yinuo Yang, Chen Change Loy, and Ziwei Liu. 2022. Style- light: Hdr panorama generation for lighting estimation and editing. In European Conference on Computer Vision (ECCV) . Springer, 477–492
work page 2022
-
[69]
Lezhong Wang, Jeppe Revall Frisvad, Mark Bo Jensen, and Siavash Arjomand Bigdeli. 2024. StereoDiffusion: Training-Free Stereo Image Generation Using Latent Diffusion Models. InProceedings of Computer Vision and Pattern Recognition Workshop (CVPRW). IEEE, 7416–7425
work page 2024
-
[70]
Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021. NeuS: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021)
work page 2021
-
[71]
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. 2021. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of International Conference on Computer Vision (ICCV) . IEEE, 1905–1914
work page 2021
- [72]
-
[73]
Liwen Wu, Rui Zhu, Mustafa B Yaldiz, Yinhao Zhu, Hong Cai, Janarbek Matai, Fatih Porikli, Tzu-Mao Li, Manmohan Chandraker, and Ravi Ramamoorthi. 2023. Factorized inverse path tracing for efficient and accurate material-lighting es- timation. In Proceedings of International Conference on Computer Vision (ICCV) . IEEE, 3848–3858
work page 2023
-
[74]
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data. In Proceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 10371–10381
work page 2024
-
[75]
Yao Yao, Jingyang Zhang, Jingbo Liu, Yihang Qu, Tian Fang, David McKin- non, Yanghai Tsin, and Long Quan. 2022. NeILF: Neural incident light field for physically-based material estimation. In European Conference on Computer Vision (ECCV). Springer, 700–716
work page 2022
-
[76]
Yu-Ying Yeh, Koki Nagano, Sameh Khamis, Jan Kautz, Ming-Yu Liu, and Ting- Chun Wang. 2022. Learning to relight portrait images via a virtual light stage and synthetic-to-real adaptation. ACM Transactions on Graphics 41, 6 (2022), 231
work page 2022
-
[77]
Bohan Yu, Siqi Yang, Xuanning Cui, Siyan Dong, Baoquan Chen, and Boxin Shi
-
[78]
IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 8 (2023), 10129–10142
MILO: Multi-bounce inverse rendering for indoor scene with light-emitting objects. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 8 (2023), 10129–10142
work page 2023
-
[79]
Hong-Xing Yu, Samir Agarwala, Charles Herrmann, Richard Szeliski, Noah Snavely, Jiajun Wu, and Deqing Sun. 2023. Accidental light probes. InProceedings of Computer Vision and Pattern Recognition (CVPR) . IEEE, 12521–12530
work page 2023
-
[80]
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. 2024. Mip-splatting: Alias-free 3d gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 19447–19456
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.