Batch-Adaptive Causal Annotations
Pith reviewed 2026-05-23 02:42 UTC · model grok-4.3
The pith
A closed-form solution for optimal batch sampling probabilities minimizes the asymptotic variance of a doubly robust estimator for causal effects with missing outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
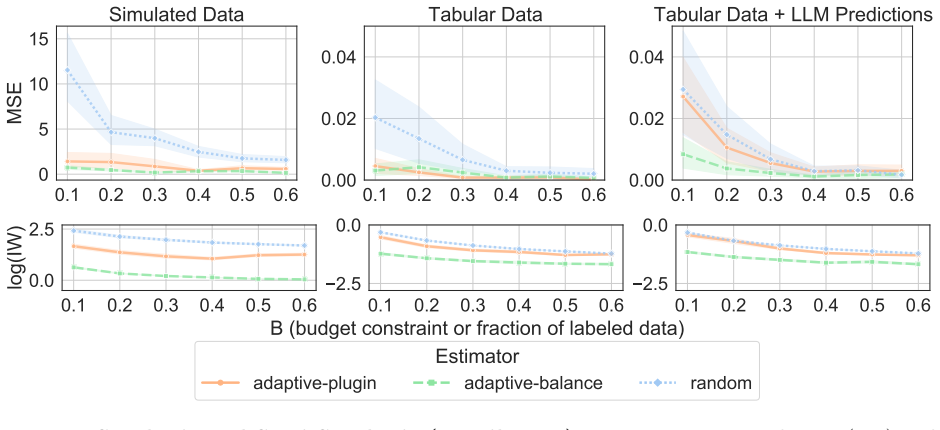
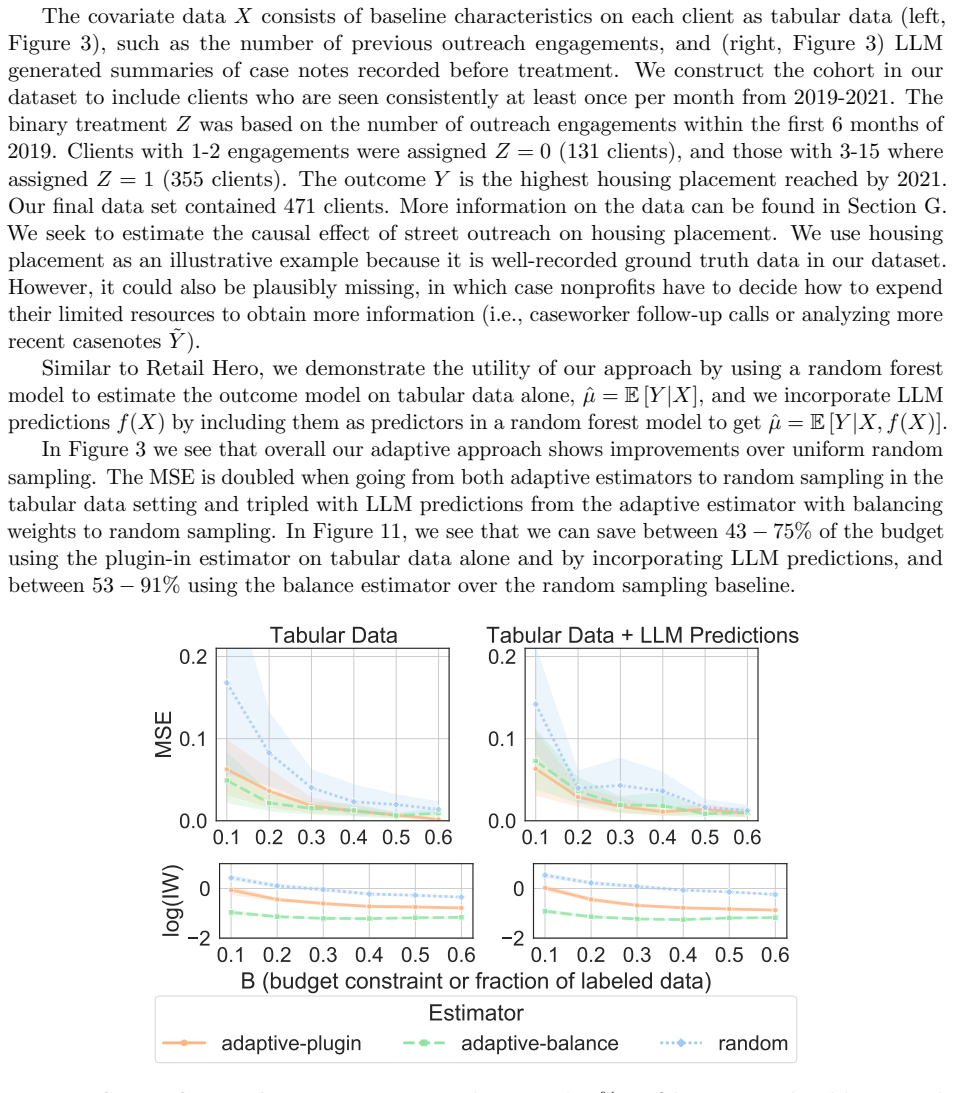
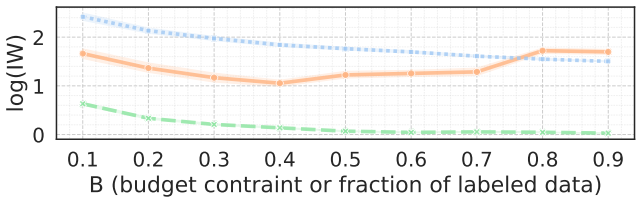
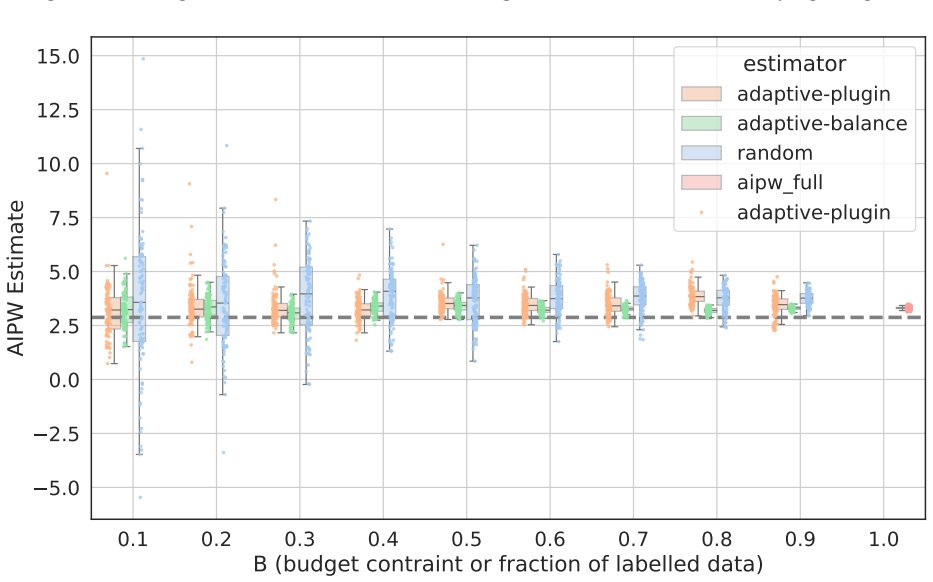
We derive a closed-form solution for the optimal batch sampling probability by minimizing the asymptotic variance of a doubly robust estimator for causal inference with missing outcomes. Motivated by partners in street outreach, the framework extends to costly annotations of unstructured data such as text or images. Across simulated and real-world datasets, including one of outreach interventions in homelessness services, the approach achieves substantially lower mean-squared error and recovers the AIPW estimate with fewer labels than existing baselines, matching confidence intervals obtained with 361 random samples using only 90 optimized samples.
What carries the argument
Closed-form optimal batch sampling probability obtained by minimizing the asymptotic variance of the doubly robust estimator.
If this is right
- The optimal probabilities yield lower mean-squared error for average treatment effect estimates at any fixed labeling budget.
- The same derivation applies when annotations involve unstructured inputs such as text or images in addition to structured records.
- In the homelessness services dataset the method recovers the target estimate while using only about one quarter the labels required by random selection.
- The savings arise directly from reduced variance rather than from changes to the underlying estimator.
Where Pith is reading between the lines
- The same variance-minimization idea could be applied to other missing-data estimators beyond doubly robust forms.
- If the closed-form expression depends on correctly specified models for the outcome regression and propensity score, misspecification would affect the realized efficiency gain.
- Sequential updating of the sampling probabilities across multiple annotation rounds might produce further reductions in required labels.
- The approach could extend to settings with multiple treatment arms or heterogeneous effects if the variance expression can be generalized accordingly.
Load-bearing premise
The asymptotic variance of the doubly robust estimator can be expressed in closed form and minimized analytically over the choice of batch sampling probabilities.
What would settle it
Empirical results in which the derived sampling probabilities produce higher mean-squared error than uniform random sampling for the same number of labels would contradict the optimality claim.
Figures







read the original abstract
Estimating the causal effects of interventions is crucial to policy and decision-making, yet outcome data are often missing or subject to non-standard measurement error. While ground-truth outcomes can sometimes be obtained through costly data annotation or follow-up, budget constraints typically allow only a fraction of the dataset to be labeled. We address this challenge by optimizing which data points should be sampled for outcome information in order to improve efficiency in average treatment effect estimation with missing outcomes. We derive a closed-form solution for the optimal batch sampling probability by minimizing the asymptotic variance of a doubly robust estimator for causal inference with missing outcomes. Motivated by our street outreach partners, we extend the framework to costly annotations of unstructured data, such as text or images in healthcare and social services. Across simulated and real-world datasets, including one of outreach interventions in homelessness services, our approach achieves substantially lower mean-squared error and recovers the AIPW estimate with fewer labels than existing baselines. In practice, we show that our method can match confidence intervals obtained with 361 random samples using only 90 optimized samples - saving 75% of the labeling budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to derive a closed-form expression for optimal batch sampling probabilities that minimizes the asymptotic variance of a doubly robust (AIPW-style) estimator for the average treatment effect when outcomes are missing or costly to annotate. It extends the framework to unstructured data (text/images) and reports empirical gains in MSE and label efficiency, including a 75% reduction in labeling budget to match full-sample confidence intervals on simulated data and a real homelessness-services outreach dataset.
Significance. If the closed-form derivation is valid under explicitly stated and verifiable assumptions on the nuisance functions, the approach would supply a practical, low-overhead method for adaptive annotation in causal studies with missing outcomes, directly addressing budget constraints in policy-relevant applications such as healthcare and social services. The reported label savings are quantitatively large and would be a notable contribution if supported by transparent implementation details and error bars.
major comments (2)
- [Derivation of optimal batch sampling probability (methods section)] The central claim of a closed-form solution for optimal sampling probabilities rests on minimizing the asymptotic variance of the doubly robust estimator. The manuscript must explicitly state the functional forms or fixed-vs-estimated status assumed for the outcome regression and propensity score (and any other nuisances) that permit analytic differentiation and closed-form solution rather than numerical optimization; without these, the derivation reduces to a standard semiparametric variance expression that generally does not admit a closed form.
- [Experiments and results (simulation and real-data sections)] Empirical results report a 75% label saving (361 random vs. 90 optimized samples) but provide no standard errors, confidence intervals on the MSE or coverage metrics, or details on how the baselines (including AIPW) were implemented with respect to nuisance estimation. This undermines assessment of whether the gains are statistically reliable or sensitive to implementation choices.
minor comments (2)
- [Methods] Notation for the sampling probabilities p_i and their appearance in the influence function or variance expression should be introduced with an explicit equation before the minimization step.
- [Abstract and §1] The abstract and introduction should clarify whether the nuisance functions are estimated once on the unlabeled data or re-estimated after each batch, as this affects both the validity of the closed-form claim and practical deployment.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and transparency.
read point-by-point responses
-
Referee: [Derivation of optimal batch sampling probability (methods section)] The central claim of a closed-form solution for optimal sampling probabilities rests on minimizing the asymptotic variance of the doubly robust estimator. The manuscript must explicitly state the functional forms or fixed-vs-estimated status assumed for the outcome regression and propensity score (and any other nuisances) that permit analytic differentiation and closed-form solution rather than numerical optimization; without these, the derivation reduces to a standard semiparametric variance expression that generally does not admit a closed form.
Authors: We will revise the methods section to explicitly state that the outcome regression and propensity score are treated as fixed (or estimated on an independent sample), which permits analytic differentiation of the asymptotic variance expression with respect to the batch sampling probabilities. This yields the closed-form optimum under the stated semiparametric model; we will also include the explicit variance formula being minimized to make the derivation fully verifiable. revision: yes
-
Referee: [Experiments and results (simulation and real-data sections)] Empirical results report a 75% label saving (361 random vs. 90 optimized samples) but provide no standard errors, confidence intervals on the MSE or coverage metrics, or details on how the baselines (including AIPW) were implemented with respect to nuisance estimation. This undermines assessment of whether the gains are statistically reliable or sensitive to implementation choices.
Authors: We will add standard errors and confidence intervals for all reported MSE and coverage metrics, obtained via repeated simulations or bootstrap resampling. We will also expand the implementation details in the main text and appendix to specify the exact nuisance estimators and cross-fitting procedures used for our method and all baselines, including AIPW, ensuring full reproducibility. revision: yes
Circularity Check
Derivation of closed-form optimal sampling probabilities is a standard analytic minimization with no reduction to inputs
full rationale
The central derivation minimizes the asymptotic variance of the doubly robust estimator with respect to batch sampling probabilities to obtain a closed-form optimum. This follows directly from standard semiparametric efficiency calculations in causal inference and does not rely on self-definition, fitted parameters relabeled as predictions, or load-bearing self-citations. The variance expression is taken from established theory rather than constructed from the paper's own outputs or evaluation data, making the result self-contained and independent.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Outcomes are missing at random conditional on observed covariates and treatment assignment.
- domain assumption The asymptotic variance of the doubly robust estimator admits a closed-form expression that can be minimized with respect to sampling probabilities.
Forward citations
Cited by 1 Pith paper
-
Auditing LLMs for Algorithmic Fairness in Casenote-Augmented Tabular Prediction
Fine-tuned LLMs augmented with casenote summaries improve accuracy and reduce multi-class error disparities in housing placement prediction compared to tabular baselines.
Reference graph
Works this paper leans on
-
[1]
Double machine learning for sample selection models
Michela Bia, Martin Huber, and Luk¨ as Laff¨ ers. Double machine learning for sample selection models. arXiv prepint arXiv:2012.00745,
-
[2]
Proximal causal inference with text data.arXiv preprint arXiv:2401.06687,
Jacob M Chen, Rohit Bhattacharya, and Katherine A Keith. Proximal causal inference with text data.arXiv preprint arXiv:2401.06687,
-
[3]
Kyle Colangelo and Ying-Ying Lee. Double debiased machine learning nonparametric inference with continuous treatments.arXiv preprint arXiv:2004.03036,
-
[4]
End-to-end causal effect estimation from unstructured natural language data
Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul Krishnan, and Chris J Maddison. End-to-end causal effect estimation from unstructured natural language data. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Maria Dimakopoulou, Zhimei Ren, and Zhengyuan Zhou. Online multi-armed bandits with adaptive inference.Advances in N...
work page 1939
-
[5]
Zijun Gao, Yanjun Han, Zhimei Ren, and Zhengqing Zhou
URL https://proceedings.neurips.cc/paper_files/paper/ 2023/file/d862f7f5445255090de13b825b880d59-Paper-Conference.pdf. Zijun Gao, Yanjun Han, Zhimei Ren, and Zhengqing Zhou. Batched multi-armed bandits problem. Advances in Neural Information Processing Systems, 32,
work page 2023
-
[6]
Zhijing Jin, Julius von K¨ ugelgen, Jingwei Ni, Tejas Vaidhya, Ayush Kaushal, Mrinmaya Sachan, and Bernhard Schoelkopf. Causal direction of data collection matters: Implications of causal and anticausal learning for nlp.arXiv preprint arXiv:2110.03618,
-
[7]
On Causal and Anticausal Learning
Bernhard Sch¨ olkopf, Dominik Janzing, Jonas Peters, Eleni Sgouritsa, Kun Zhang, and Joris Mooij. On causal and anticausal learning.arXiv preprint arXiv:1206.6471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Adaptive neyman allocation.arXiv preprint arXiv:2309.08808,
Jinglong Zhao. Adaptive neyman allocation.arXiv preprint arXiv:2309.08808,
-
[9]
Tijana Zrnic and Emmanuel J Cand` es. Active statistical inference.arXiv preprint arXiv:2403.03208,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
studies the long-term intervention effects of job training on lifetime earnings, by using only short-term outcomes (surrogates) such as yearly earnings. In this regime, the ground truth cannot be obtained at the time of analysis. In this paper, we focus a different regime where obtaining the ground truth from expert data annotators is feasible but budget-...
work page 2022
-
[11]
So the full variance term is Var[ψz −ψ z′] =E 1 ez(X)·π(z, X) ·[Y−µ z(X)] 2 +E 1 ez′(X)·π(z ′, X) ·[Y−µ z′(X)] 2 +E (µz(X)−µ z′(X)) 2 −E[µ z(X)−µ z′(X)] 2 =E 1 ez(X)·π(z, X) ·[Y−µ z(X)] 2 +E 1 ez′(X)·π(z ′, X) ·[Y−µ z′(X)] 2 + Var µz(X)−µ z′(X) Rewriting the bound from Hahn (1998), we get V≥E 1 ez(X)·π(z, X) ·[Y−µ z(X)] 2 +E 1 ez′(X)·π(z ′, X) ·[Y−µ z′(X)...
work page 1998
-
[12]
3]; it follows readily from following their proof of Thm
The objective function arises from the asymptotic variance expression in [Colangelo and Lee, 2020, Thm. 3]; it follows readily from following their proof of Thm. 3 with our analysis of the asymptotic variance as in Proposition
work page 2020
-
[13]
F Additional Lemmas F.1 Results appearing in other works, stated for completeness
Putting these results from Step 1 and Step 2 together, along with the fact that nt,k n → 1 K , gives the theorem. F Additional Lemmas F.1 Results appearing in other works, stated for completeness. Lemma 1(Conditional convergence implies unconditional convergence, from [Chernozhukov et al., 2018]).Lemma 6.1. (Conditional Convergence implies unconditional) ...
work page 2018
-
[14]
(b) Let {Am} be a sequence of positive constants
In particular, this occurs if E[∥X m∥q /ϵq m |Y m]→ P r 0for some q≥ 1, by Markov’s inequality. (b) Let {Am} be a sequence of positive constants. If ∥Xm∥ = OP (Am) condi- tional on Ym, namely, that for any ℓm → ∞, Pr (∥Xm∥> ℓ mAm |Y m)→ P r 0, then ∥Xm∥ = OP (Am) unconditionally, namely, that for anyℓ m → ∞,Pr (∥X m∥> ℓ mAm)→0. Lemma 2(Chebyshev’s inequal...
work page 2018
-
[15]
(4) 31 In the below, we drop thezargument. By the triangle inequality, boundedness of 1/ˆe(X)≤ν e, and ofσ 2(X)≤B σ2: p ˆσ2(X)/ˆe2(X)− p σ2(X)/e 2(X) 2 = p ˆσ2(X)/ˆe2(X)± p σ2(X)/ˆe2(X)− p σ2(X)/e 2(X) 2 ≤ν e p ˆσ2(X)− p σ2(X) 2 +B σ2 1 e(X) − 1 ˆe(X) 2 For the second term: Bσ2 1 e(X) − 1 ˆe(X) 2 ≤B σ2 1 e(X) − 1 ˆe(X) 2 ≤B σ2νe ∥e(X)−ˆe(X)∥ 2 since 1/e(X...
work page 2021
-
[16]
We sample each covariate X∈R 5 from a standard normal distribution, X∼ N (0, I5). Treatment Z is drawn with logistic probability γz(X) = (1 +e X2+X3+0.5). We defineσ 2 z(X) as follows: σ2 1(X) := max[1.3 + 0.4sin(X1),0] σ2 0(X) := max[3.5 + 0.3cos(X3),0]. Finally, the outcome models are defined as: Y(0) = 5 +X 1 −2X 2 +ϵ 0 Y(1) =Y(0) +θ 0 +ϵ 1, where ϵ0 ∼...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.